王者英雄皮肤壁纸
1.首先进入英雄资料页面https://pvp.qq.com/web201605/herolist.shtml
2.数据是直接加载的 所以找到每个英雄头像对应的li标签
3.找到里面的链接herodetail/538.shtml 通过字符串拼接就能让代码进入详情页

import requests
import os
from lxml import etree
import time
if not os.path.exists(r'王者skin'):
os.mkdir(r'王者skin') # 创文件夹
res = requests.get('https://pvp.qq.com/web201605/herolist.shtml')
res.encoding = 'gbk' # 解码
# print(res.text)
tree = etree.HTML(res.text)
li_list = tree.xpath('//*[@class="herolist-box"]/div[2]/ul[1]/li') # 找一个个英雄的li标签
# print(li_list)
for li in li_list:
desc_link = li.xpath('./a/@href')[0].split('.')[0].split('/')[1] # 取英雄对应的数字编号
# print(desc_link)
res1 = requests.get('https://pvp.qq.com/web201605/' + li.xpath('./a/@href')[0]) # 拿链接后拼接出网页
res1.encoding = 'gbk'
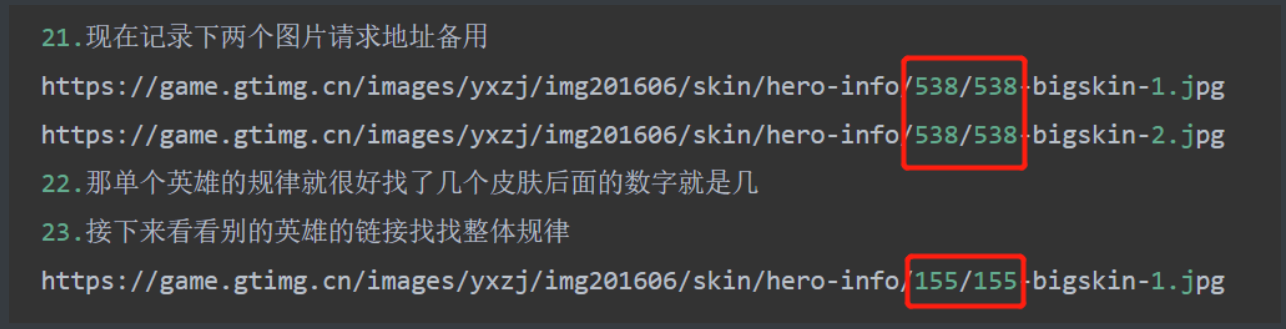
tree1 = etree.HTML(res1.text)
4.进入详情页之后就要找壁纸 首先看到的是背景板上的加载信息

5.首先想到就是拿这个背景但是一个英雄有好几个皮肤背景会动态变化 这怎么拿呢
6.就去研究一下控制它换背景的按钮 通过鼠标悬停会切换那找找看这个标签
7.里面除了小头像图片还有个链接

8.这个链接验证一下还真是高清图片链接
9.而且几个皮肤用li排列那岂不是直接找这个就行

10.实际上我用xpath找了好几遍没找到这个标签 转念一想这个莫不是动态加载
11.复制搂一眼还真是 链接找没有 源码看也找不到

12.既然没有那就只能去动态加载里面找了
13.找了一圈全是乱码或者是没实质东西的返回值

14.更气的是无论放到bejson在线转还是用notepad++去做解码 我把编码换了个便都没找到
15.那思路只能放宽去all里面找

16.all里面大海捞针啊 总归是功夫不负有心人找到了高清大图 但是这只有一张这怎么搞

17.那source里明明就是两个呀

18.好在有图片名字抱着试一试的心态在network里面通过ctrl+f搜索一下图片名字关键字bigskin
19.果然还是只有一个 那只能是通过本地js代码再触发的喽
20.尝试拿鼠标点一下别的皮肤小图终于找到了另一个图片

21.现在记录下两个图片请求地址备用
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/538/538-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/538/538-bigskin-2.jpg
22.那单个英雄的规律就很好找了几个皮肤后面的数字就是几
23.接下来看看别的英雄的链接找找整体规律
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/155/155-bigskin-1.jpg

24.不一样的部分也一目了然就是数字部分有两处不同 两处用到还是同一个数字
25.这个数字 是不是有点眼熟 之前操作的时候唯一出线过一个数字地方就是详情页链接
26.比对一下雀食是这部分数据那只要通过简单的字符串处理剥除数字即可
desc_link = li.xpath('./a/@href')[0].split('.')[0].split('/')[1] # 取英雄对应的数字编号
27.取出编号后拼接网址
url = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + '%s/%s-bigskin-%s.jpg' % (desc_link, desc_link, num) # 终极地址
28.拿到这个地址就完事大吉可是这边num参数去爬几张图片不知道一个英雄有几个皮肤根本无从下手啊
29.总不能每爬一个手动看一下吧 原本想着通过li标签有几个就有几个皮肤
但是li标签是动态加载的找不到的
30.欸回忆一下是不是之前在找里的时候有个li外面的ul标签不是动态加载的
这上面是不是有信息

31.没错这里有皮肤的信息而且每个皮肤名字后面有个特殊符号& 看了其他几个英雄规律一样那就可以通过这个入手
32.用xpath选出标签文本然后数里面&的个数就知道有几个皮肤了
skin_num = tree1.xpath('.//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0].count('&') # 有几个&就有几个皮肤
33.有了这个只需要拼接网站发送请求 数据永久化一条龙就没什么难度了

# 最后附上完整代码
import requests
import os
from lxml import etree
import time
if not os.path.exists(r'王者skin'):
os.mkdir(r'王者skin') # 创文件夹
res = requests.get('https://pvp.qq.com/web201605/herolist.shtml') # 访问初始网页
res.encoding = 'gbk' # 解码
# print(res.text)
tree = etree.HTML(res.text) # 用xpath解码
li_list = tree.xpath('//*[@class="herolist-box"]/div[2]/ul[1]/li') # 找一个个英雄的li标签
# print(li_list)
for li in li_list: # 取一个个英雄
desc_link = li.xpath('./a/@href')[0].split('.')[0].split('/')[1] # 取英雄对应的数字编号
# print(desc_link)
res1 = requests.get('https://pvp.qq.com/web201605/' + li.xpath('./a/@href')[0]) # 拿链接后拼接出网页 后面是链接
res1.encoding = 'gbk' # 解码
tree1 = etree.HTML(res1.text) # 解析
'''
详情页
https://pvp.qq.com/web201605/herodetail/506.shtml
目标链接
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/506/506-bigskin-1.jpg
https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/538/538-bigskin-1.jpg
前面的数字还好说 后面几个皮肤怎么找
'''
skin_num = tree1.xpath('.//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0].count(
'&') # 标签里有皮肤名字分隔开数数长度知道有几个皮肤
print(skin_num) # 拿皮肤数量这个想破脑袋
for num in range(1, skin_num + 1): # 通过前面的数量加1取到对应数值
url = 'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + '%s/%s-bigskin-%s.jpg' % (
desc_link, desc_link, num) # 终极地址
skin_name = tree1.xpath('.//ul[@class="pic-pf-list pic-pf-list3"]/@data-imgname')[0].split('|')[num - 1] # 分隔成列表拿名字再索引取值
print(skin_name) # 这个打印不去了还能看到在下哪张图
res2 = requests.get(url)
img = res2.content # 获取二进制返回值
file_path = os.path.join(r'王者skin', '%s.jpg' % skin_name) # 路径拼接
with open(file_path, 'wb') as f: # 永久化
f.write(img)
time.sleep(0.5)


