10/8
复习巩固
1.列举你所接触到的网站采取的防爬措施及解决方案(通用与自定义)
浏览器请求
增加请求头中浏览器信息
ip代理池
多找几个ip随机取用
cookie代理池
多注册几个cookie随机取用
图片防盗链
在请求头中加入referer伪装成所允许的网站发出请求
动态加载
向实现动态加载的网站发送请求
本地js代码加密
通过encrypt和decrypt关键字找到本地js代码加密的部分 打断点识别加密前情况
验证码
通过纯代码或第三方软件实现(不推荐)
自己人工操作一下
懒加载
通过判断数据所需位置增加判断
页面干扰项
通过判断内部内容 筛除干扰项
selenium识别
调用固定的防爬模块
2.列举爬虫中你所使用过的模块及作用
import requests # 用来向网页发送请求
import re # 正则 用来筛选页面上所需内容
from lxml import etree # xpath解析器用来解析页面内容 更方便的获取到所需数据
from bs4 import BeautifulSoup # bs4解析库 用来解析页面内容 更方便的获取到所需数据
from openpyxl import Workbook # 与excel联动用来做到数据持久化
from selenium import webdriver # 模拟浏览器操作
3.列举三个你认为比较复杂比较有趣的实战案例及过程
# 梨视频
1.首先观察页面数据加载 找到详情页链接
2.进入详情页后再次观察所需数据加载方式
3.这个数据是动态加载的那和之前的联系就断了
4.要想办法弄清前一个页面和动态加载网页以及element中真实地址之间的关系
5.观察发现真实地址是动态加载返还值中网页系统时间进行的替换
6.通过字符串的分隔拼接替换之后获取到最终网址
7.最后以二进制形式保存
8.通过请求体额外参数控制多页
# 贴吧图片
1.访问贴吧后观察网址 通过请求体额外参数控制搜索内容
2.找到具体贴吧后通过class属性筛选出一个个帖子的链接
3.发送二次请求获得到帖子内部数据
4.筛选出帖子内部图片
5.观察帖子内部翻页规律 通过请求体携带的数据控制翻页
6.对外部帖子汇总页翻页控制 如法炮制
# 京东商品
1.通过selenium控制浏览器打开并访问京东
2.找到搜索框并向其中输入想要的商品数据
3.进入商品详情页后观察规律找到所需数据
4.有数据会有懒加载现象那就通过判断 将懒加载的区分出来再继续
5.但是这时候会少数据 需要通过滚轮控制页面向下滑才能将数据全部加载
6.最后将数据插入表格
7.找到翻页标签 通过点击控制翻页
内容概要
- 爬虫框架Scrapy
- 非关系型数据库MongoDB
只要mysql没有忘记 MongoDB是非常轻松的
- MongoDB简介
- MongoDB下载安装
- MongoDB重要概念
- MongoDB基本操作
详细讲解
爬虫框架Scrapy
框架:别人提前给你搭建好了的基本架构 具备一定功能
Scrapy是网络爬虫中使用频率最高功能最完善的框架
# 下载Scraoy框架
'''mac本一般直接下载即可 但是windows电脑很可能报错'''
windows电脑如果下载报错并且没有典型的关键字特征那么就需要额外配置
1.pip3 install wheel
2.https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
找到和你电脑配对的twisted
3.下载好之后放哪里呢
直接通过 pip3 install 文件名
这样就能看到推荐你安装的地址
4.pip3 install pywin32
5.pip3 install scrapy
# 怎么验证scrapy是否下载好了
只要在终端直接输入scrapy即可

Scrapy基本使用
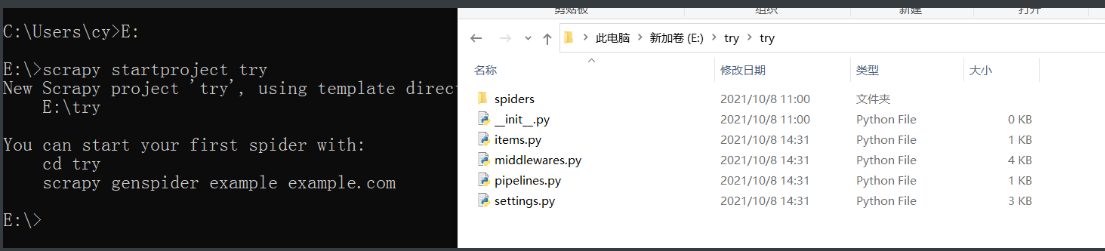
# 创建项目
scrapy startproject 项目名
'''自动生成一个内部含有多个py文件及文件夹的文件夹'''
# 创建爬虫文件
scrapy genspider jd www.jd.com
'''自动创建py文件并填写一定的代码方便统一管理'''
# 执行爬虫文件
scrapy runspider jd.com
scrapy crawl jd
Scrapy文件介绍
项目名文件夹
项目名同名的文件夹
spiders文件
存放爬虫项目文件
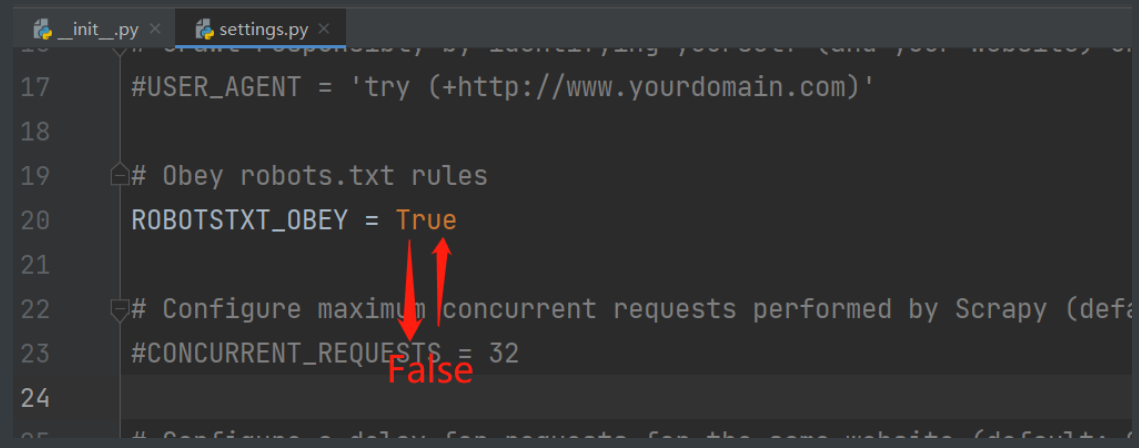
settings.py # 配置文件
'''里面有ROBOTS.TXT爬虫协议
如果要使用得把遵守协议那块改成False'''
items.py # 数据存储相关文件
middlewares.py # 中间件文件
'''在一个完整的操作流程中可以穿插多个小步骤'''
pipelines.py # 数据库存储相关文件
scrapy工作结构
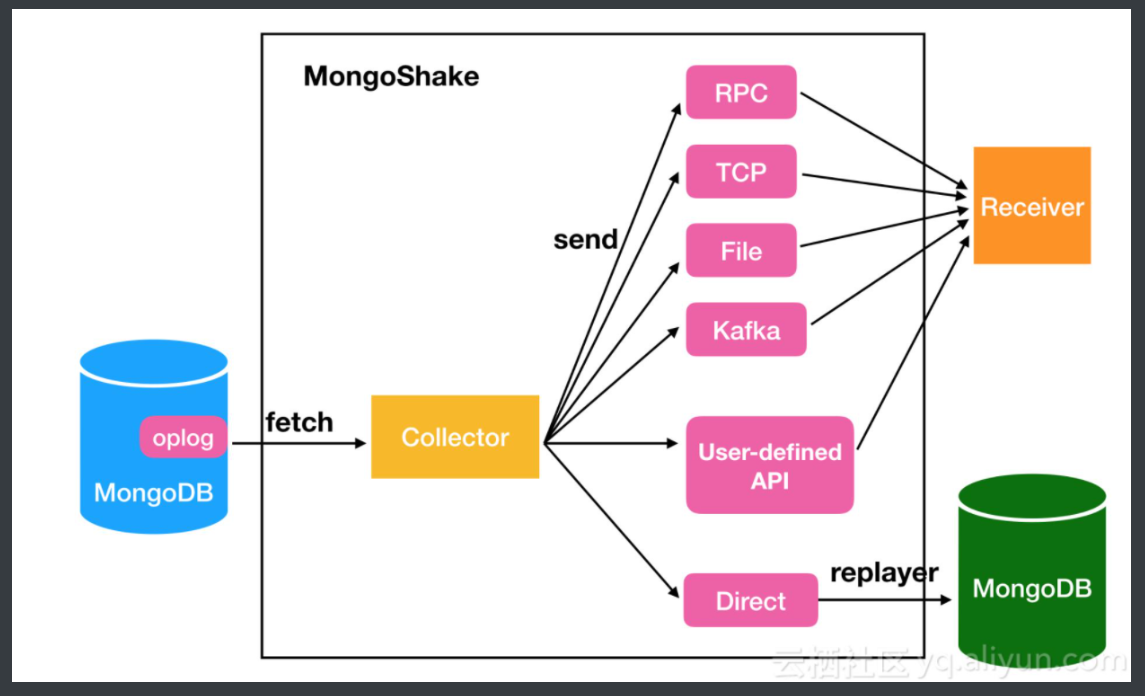
1.引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。
2.调度器(SCHEDULER)
用来接受引擎发过来的请求压入队列中并在引擎再次请求的时候返回可以想像成一个URL的优先级队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址
3.下载器(DOWLOADER)
用于下载网页内容并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
4.爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
5.项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库等操作
6.下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事
1. process a request just before it is sent to the Downloader (ie. right before Scrapy sends the request to the website);
2. change received response before passing it to a spider;
3. send a new Request instead of passing received response to a spider
4. pass response to a spider without fetching a web page
5.silently drop some requests.
7.爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)

MongoDB数据库
关系型数据库
MySQL、Oracle、PostgreSQL、MariaDB
# 有固定的表结构 而且可以建立外键
非关系型数据库
redis、mongoDB、memcache
# 没有固定的表结构 数据储存用K:V键值对的形式
非关系型数据库MongoDB
其数据储存的量和时间明显快过关系型数据库
MongoDB也是大数据最常用的数据库软件
'装逼知识点'MongoDB是最像关系型数据库的一款非关系型数据库
MongoDB可拓展性很强
'''
横向扩展与纵向扩展
以提升计算机性能为例
横向扩展:买来多台计算机组合使用(常用 企业)
纵向扩展:就在一台计算机上面不停的优化(个人)
'''
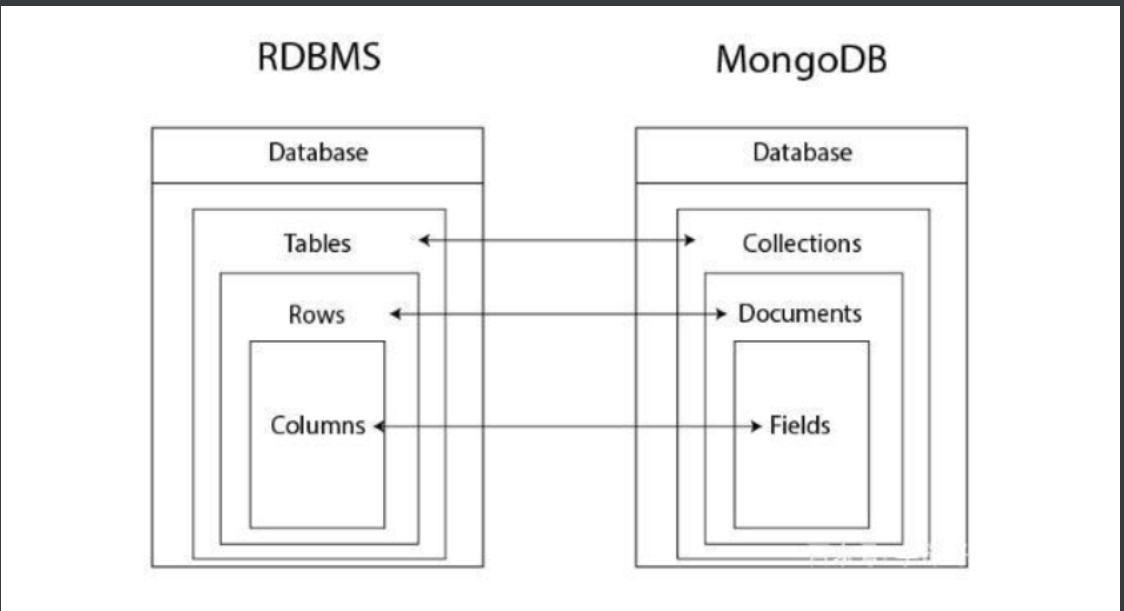
MongoDB重要概念
# 为了方便理解和记忆 可以继续使用MySQL的名字来称呼
database database 库
table collection 集合
row document 文档
column field 字段
MongoDB下载和安装
https://www.mongodb.com/try/download/community
不要用最新版本 下载msi文件即可
下载完之后会有一些文件
bin文件夹
'''里面存放一堆启动文件'''
mongod.exe 服务端
mongo.exe 客户端
data文件夹
'''里面存放数据相关文件'''
log文件夹
'''里面存放日志相关文件'''
启动准备
1.下载好按步骤安装
2.如果安装好的文件夹里没有data和log文件夹的话需要自己手动添加
3.在data文件里创建db文件夹(方便后续管理文件资源)
4.将启动文件所在的路径bin添加进环境变量
5.在文件夹bin同级的根目录下创建mongod.cfg
并在里面放入如下代码
systemLog:
destination: file
path: "D:\MongoDB\log\mongod.log"
logAppend: true
storage:
journal:
enabled: true
dbPath: "D:\MongoDB\data\db"
net:
bindIp: 0.0.0.0
port: 27017
setParameter:
enableLocalhostAuthBypass: false
前面路径可能会要改
6.系统服务制作
mongod --bind_ip 0.0.0.0 --port 27017 --logpath D:\MongoDB\log\mongod.log --logappend --dbpath D:\MongoDB\data\db --serviceName "MongoDB" --serviceDisplayName "MongoDB" --install --auth
'''auth即让服务端以校验用户身份的方式启动 不加则不校验'''
8.启动\关闭
net start MongoDB
net stop MongoDB
9.登录
mongo
基础命令
'''mongodb语句不需要使用分号结束'''
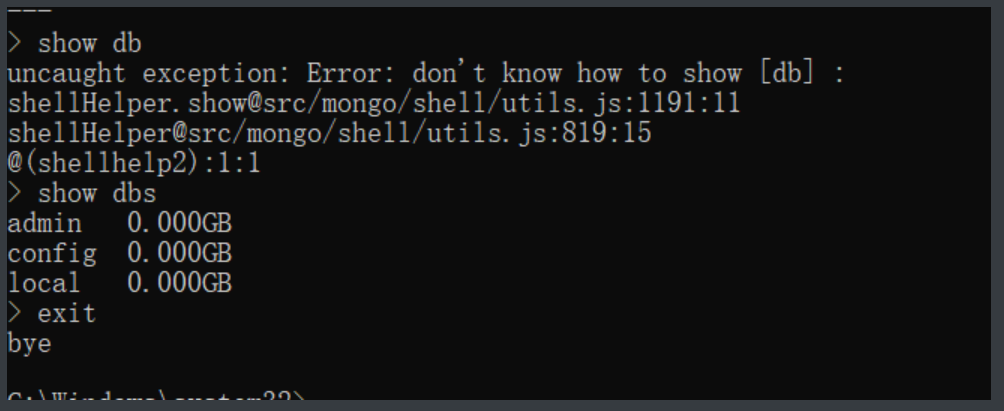
# 1.查看所有的数据库名词
show dbs # 相当于MySQL中show databases;
"""
mongodb默认有三个数据库
admin config local
"""
# 2.退出客户端
exit # exit();
quit() # quit();
补充
MongoDB不同于MySQL无需自己创建东西
直接指定就可以使用
但是一定要等真的用到了才会写进硬盘
在此之前都只是在内存里

库的增删改查
# 查看
show dbs
"""相当于MySQL中show databases;"""
# 新增
use db1 # 现在内存中自动创建 如果db1内写入了数据那么才会刷到硬盘中
"""相当于MySQL中create database db1;"""
# 修改
忽略
库没啥改的东西
# 删除
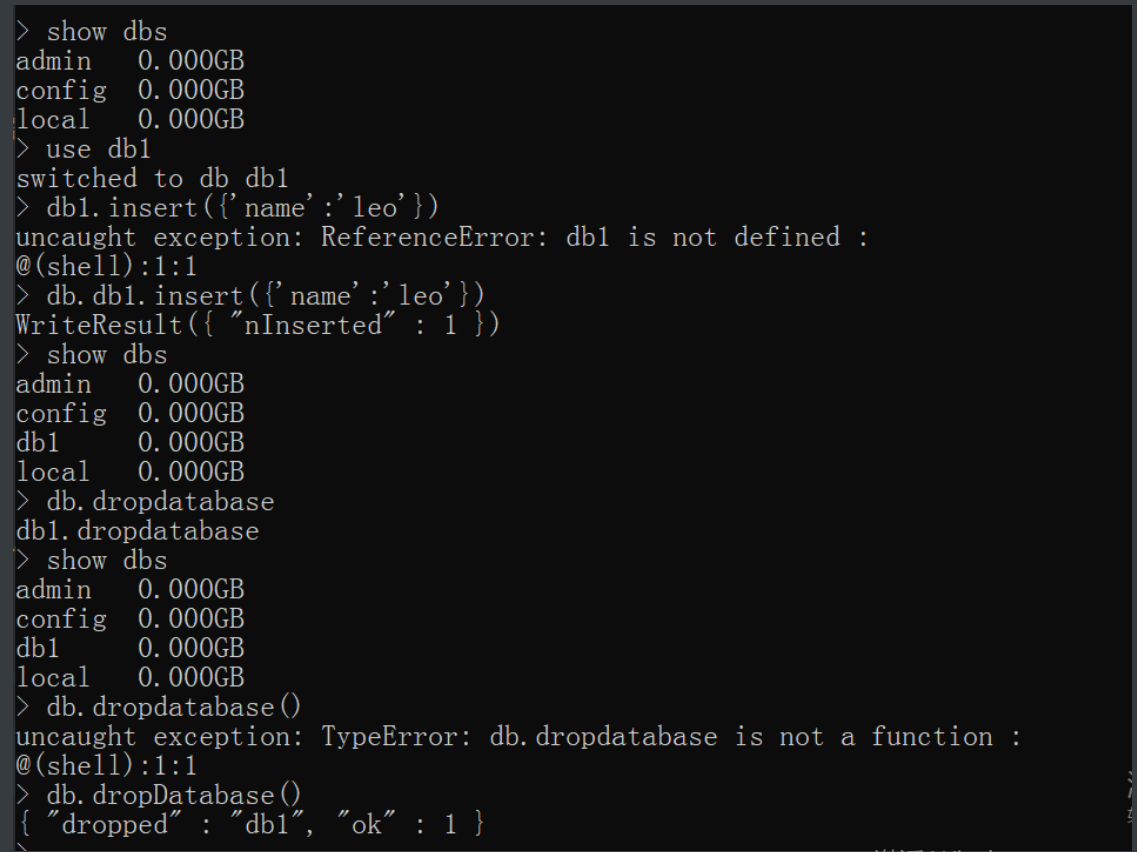
先插入数据 db.db1.insert({'name':'jason'})
db.dropDatabase() # db是关键字 当前在哪个库下执行就是删除哪个库
"""相当于MySQL中drop database db1;
但是这个区分大小写的要注意"""
针对集合的增删改查
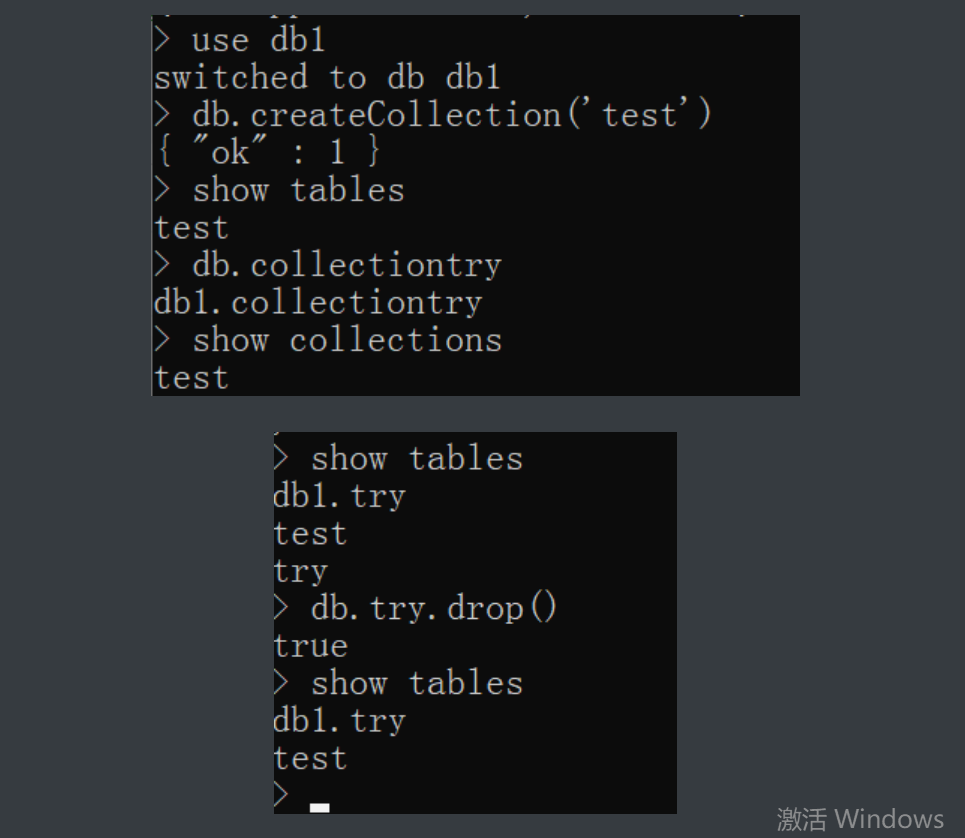
# 集合相当于MySQL中的表的概念
要想操作collection必须先有database
# 增
db.createCollection('表名')
db.集合名字 # 这个也是在内存中创建 不常用
# 查
show tables
show collections
# 改
忽略
本来就不具备表结构了改什么改
# 删
db.集合名字.drop()
针对文档的增删改查
# 增
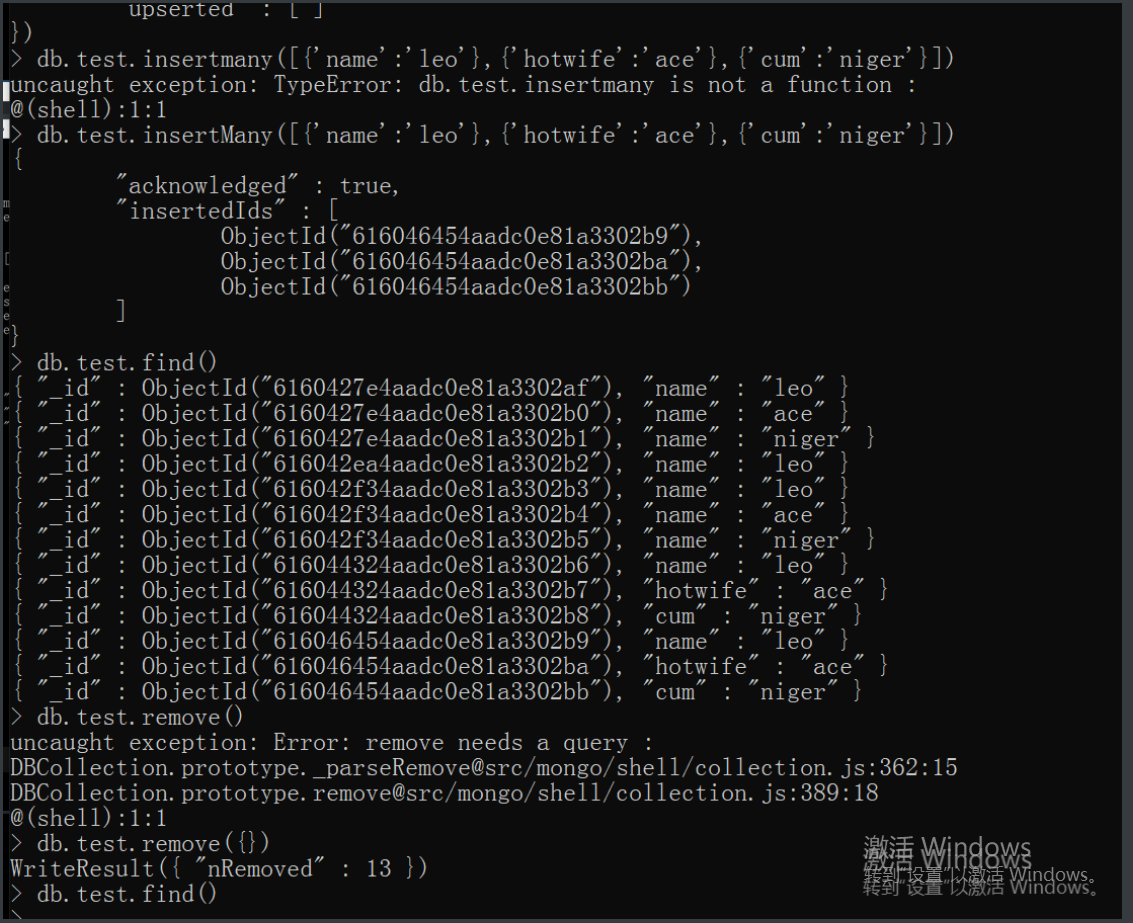
db.t1.insert({}) # 插入单条数据
db.t1.insertMany([{},{},{}]) # 插入多条数据
# 查
db.t1.find() # 相当mysql里select * from t1;
db.t1.find({'name':'leo'}) # 相当mysql里select * from t1 where name='jason';
# 改
db.t1.update({'name':'leo'},{$set:{'name':'leoNB'}}) # 修改
db.t1.update({'name':'leoNB'},{'name':'leo666'}) # 替换(少用)
# 删
db.t1.remove({}) # 相当mysql里delete from t1;
db.t1.remove({'name':'leo'})# 相当mysql里delete from t1 where name='leo';