
9/30
今日考题
1.阐述selenuim你所知道的操作
from selenium import webdriver
bro = webdriver.Chrome() # 指定浏览器驱动
bro.get("https://www.") # 访问网页
tag = bro.find_element_by_id # by后面是什么就用什么方式找
bro.find_element_by_partial_link_text 根据链接中文字找控件到标签 模糊查询 有这个字符即可
tag.get_attribute('src') # 获取标签属性
tag.text # 标签文本
tag.id # 标签id
tag.location # 标签位置
tag.tag_name # 标签名
browser.back() # 浏览器后退
browser.forward() # 浏览器前进
browser.get_cookie() # 获取cookie
browser.add_cookie({'k1':'xxx','k2':'yyy'}) # 设置cookie
bro.execute_script('window.scrollTo(0,200)') # 鼠标滚轮向下拖200
browser.execute_script('window.open()') # 开个新的标签页
browser.switch_to_window(browser.window_handles[1]) # 定位到第二个选项卡
browser.close() # 关闭当前选项卡
2.阐述红薯网小说爬取思路(尽可能详细 想象是在面试)
1.首先进到网页就发现大部分东西都被禁用了鼠标左键没法选中 右键点击没有反应
2.只能按f12呼出管理窗口 先 用程序发送以下请求看看有啥
3.结果是看到程序全部是动态加载的直接请求什么都拿不到的
4.那只能刷新一下网站开着检查 去fetch里面找找有什么能用的东西
5.观察到向某个网页里面发送请求之后返回两个很长很长的东西
虽然看不懂但是这么长还加密了 那必定是有猫腻
6.根据爬虫多年的经验就可以尝试着去source里面找找js代码里有没有解密的东西关键词一般都是decrypt
7.找了一下果然是有 但是一个解密完之后小说还是出现缺字的情况
另一个解密后是一段js代码
8.是不是缺失的文字部分被这个js代码控制了呢
9.我现在也只能这么猜想所以就自己构建一个html文件把东西塞进来 再导入刚才解密后的js文件
10.看到雀食这样小说就齐整了,只不过丢失的字在:befor标签的css属性里
11.那可以用js定位到所有的:befor标签 获取到css属性的值即缺失的文字
12.最后把缺失的文字插入到标签之间就大功告成
3.验证码破解思路有哪些
# 滑动验证码
滑动验证码可以通过selenium计算所需位置和其实位置的差值控制动作链
然后通过循环控制滑块一点点向目标位置移动
# 图片验证码
1.通过别人做的图像识别技术 完全用代码破解
软件:Tesseract-ocr
模块:pytesseract
2.通过花钱请第三方服务平台
3.构建人工智能去识别
复习巩固
- selenium其他操作
- 如何执行js脚本代码
# js也是一门编程语言
当你学会了python(任意一门编程语言)再去学js(其他语法)会发现上手很容易
bro.excute_script('window.scrollTo(0,200)')
- 动作链
# 主要就是为了应对滑动验证码
有一些页面是多层嵌套的 并且嵌套的界面可能是iframe标签
- 如何规避防爬
# selenium操作浏览器也可能被识别
彻底伪装成浏览器要加额外的配置
- 如何无界面操作
# 主要是为了节省资源
也是添加一些额外的配置即可
- 验证码破解思路
1.滑动验证码
1.可以通过selenium实现动作链
2.人工自己滑动
2.图片验证码
1.python模块图像识别
2.第三方打码平台
3.自己手动输入
4.人工智能
- b站视频爬取案例
# 有些视频 分为视频 音频 两个文件
- 红薯网小说爬取案例(重点)
# 要能脱稿说出完整思路
1.页面禁止鼠标左右键操作
2.页面数据全是动态加载
3.关键数据全部加密需要处理
4.查找和解密相关的js代码
5.获取解密之后的内容但是还是有所缺失
6.查找缺失相关的js代码
7.自己手动创建html文件引入相应的js代码
8.css防爬
内容概要
- 百度自动登录
- 爬取京东商品数据
- 知乎登录防爬措施
防爬策略已经修改了
但是不影响学习这个防爬策略
- 爬虫框架之Scrapy
框架:类似于房屋的钢筋结构(使用框架就相当于提前搭建好了结构 只需要往不同的结构中添加不同的内容即可产生不同的效果)
详细讲解
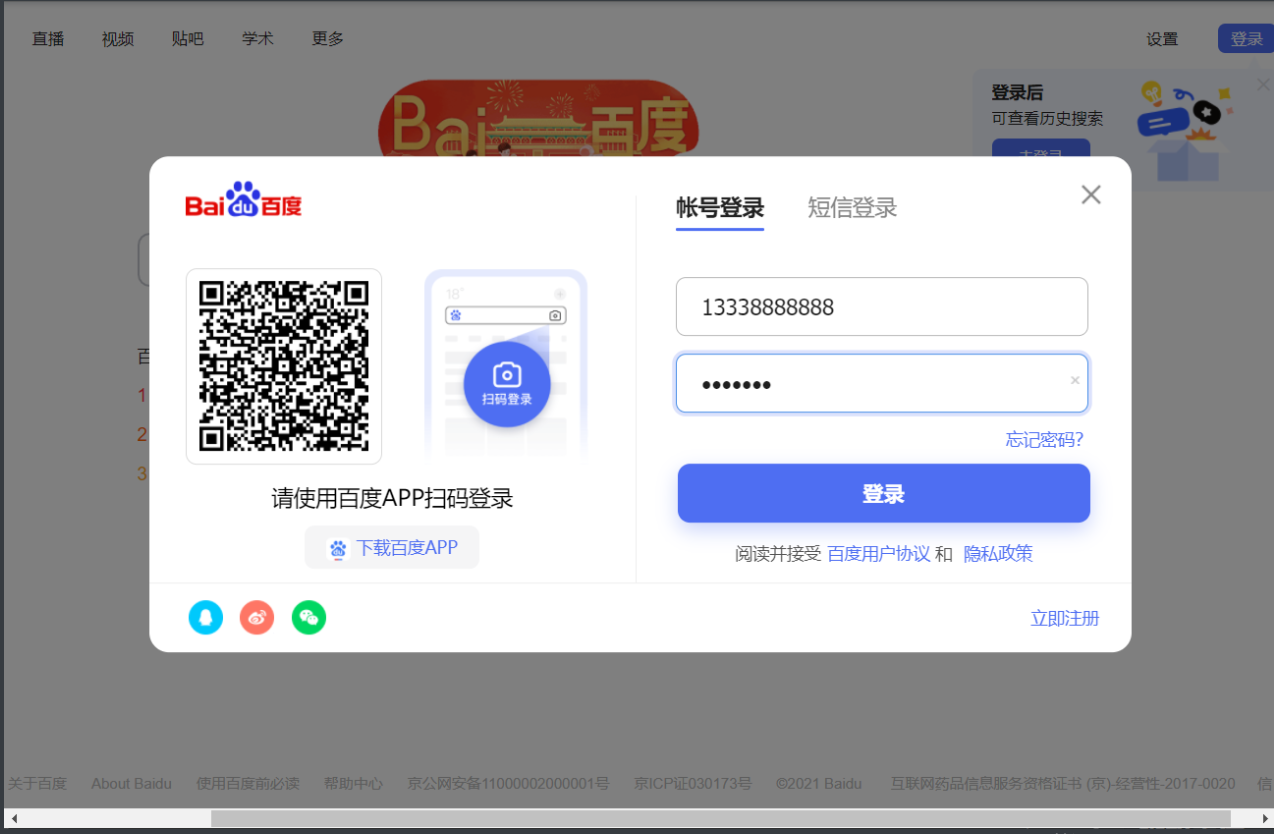
百度自动登录
from selenium import webdriver
import time
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.keys import Keys
# option = ChromeOptions()
# option.add_experimental_option('excludeSwitchers', ['enable-automation'])
bro = webdriver.Chrome() # 前面设置防爬 不过这里并不需要
bro.get('http://www.baidu.com') # 打开百度网页
login = bro.find_element_by_id('s-top-loginbtn')
# 通过id直接找到百度右上角登录
login.click() # 点击一下
time.sleep(2) # 这里补停一下太快的话会找不到页面
# 或者可以通过 bro.implicity_wait(10) # 最多等10秒 10秒内加载完就直接接着走
# 这个登录窗口不是通过iframe加载的那就直接找到输入框传值就行了
username = bro.find_element_by_id('TANGRAM__PSP_11__userName') # 有id就用id找这样是唯一的
password = bro.find_element_by_id('TANGRAM__PSP_11__password')
username.send_keys('13338888888') # 输入用户名
password.send_keys(input('输入密码')) # 输入密码
time.sleep(5)
password.send_keys(Keys.ENTER) # 回车键登录
time.sleep(5)
延时等待
有时候我们在访问网站数据的时候,加载需要一定时间
没有完全加载好的情况下代码继续向下执行及其容易报错
那如何精确等待 不浪费时间
bro.implicity_wait(10) # 最多等10秒 10秒内加载完就直接接着走
加载代码开头刚开始访问完网页就行
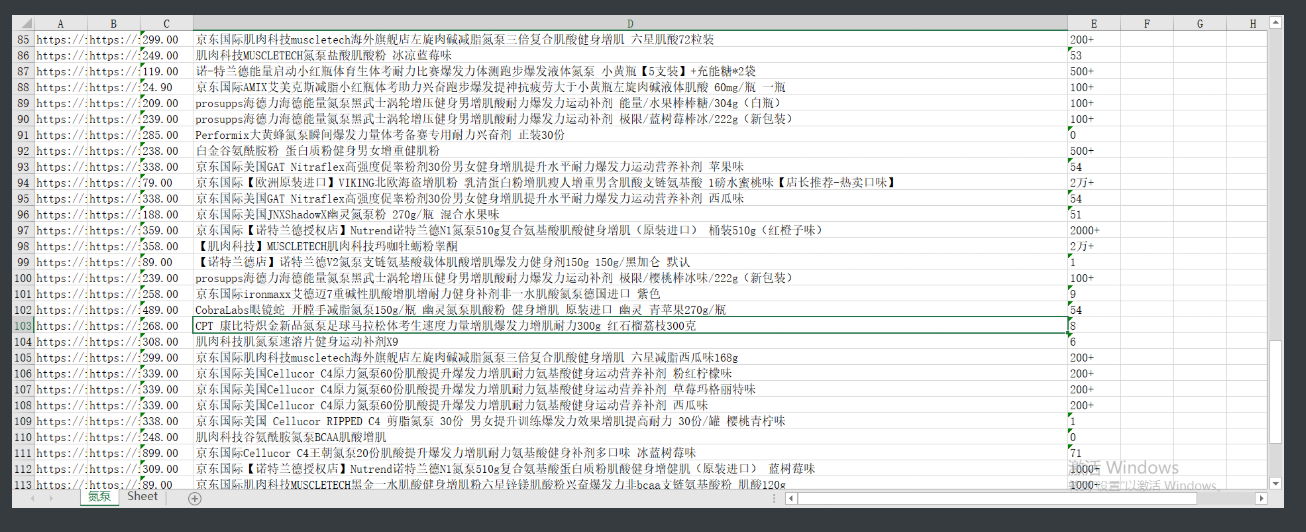
京东商品数据
from selenium import webdriver
import time
from selenium.webdriver.common.keys import Keys
from openpyxl import Workbook
bro = webdriver.Chrome() # 打开浏览器
bro.get('https://www.jd.com/') # 打开京东
bro.implicitly_wait(10) # 加载好马上执行后面的代码 没加载好就等10秒
input_tag = bro.find_element_by_id('key') # 找到那个输入框
good_name = input('请输入想要搜索的产品') # 自行输入想要爬取的商品
wb = Workbook() # 创建表格
wb1 = wb.create_sheet(good_name, 0) # 创建工作簿 放到最前面
wb1.append(['图片链接', '详情页链接', '价格', '详情', '订单数']) # 插入表头
input_tag.send_keys(good_name) # 向输入框输入想要的内容
input_tag.send_keys(Keys.ENTER) # 按回车进入
def get_goods(): # 定义成函数方便调用
for i in range(0, 15000, 1000): # 通过for循环获取向下滚动的距离
bro.execute_script('window.scrollTo(0,%s)' % i) # 访问到网页后先向下进行滚动 触发内部js代码加载出全部数据
time.sleep(0.5) # 滚一点停一下 假装是人在操作
good_tag_list = bro.find_elements_by_xpath('//*[@id="J_goodsList"]/ul/li') # 找到商品所属的li标签
for good_tag in good_tag_list: # 循环取出一个个标签
# print(good_tag)
img_link = good_tag.find_element_by_xpath(
'./div[1]/div[1]/a/img').get_attribute('src') # 取出标签中的src属性值
# print(img_link) # 这边打印之后发现会有一些数据缺失的情况
'''
通过不滚动屏幕直接找标签一点点定位到出问题的地方
发现图片加载的链接有懒加载的情况
即如果没有滚到这里或者太快掠过的话src属性被藏在data-lazy-img中
可以通过一个判断进行筛查
'''
if not img_link: # 如果有懒加载现象前面的img_link就会是none取反走下面的流程
img_link = 'https:' + good_tag.find_element_by_xpath(
'./div[1]/div[1]/a/img').get_attribute('data-lazy-img') # 取到懒加载里面的属性 并对不完整的信息拼接
# print(img_link) # 如果有值就不会走前面的判断 这样结果就完整没问题了
detail_page_link = good_tag.find_element_by_xpath('./div[1]/div[1]/a').get_attribute('href') # 详情页链接
# print(detail_link) # 每步打印看看 防止想前面那样有意外情况
# 最后再看的话如果有问题不好排查
price = good_tag.find_element_by_xpath('./div[1]/div[2]/strong/i').text # 价格数据
# print(price)
detail = good_tag.find_element_by_xpath('./div[1]/div[3]/a/em').text # 详情描述
# print(detail)
order_num = good_tag.find_element_by_xpath('./div[1]/div[4]/strong/a').text # 订单数
# print(order_num)
wb1.append([img_link, detail_page_link, price, detail, order_num]) # 将获取到的数据编成列表插入到表格里面
next_page = bro.find_element_by_xpath('//*[@id="J_bottomPage"]/span[1]/a[@class="pn-next"]') # 然后再找到每个页面的下一页按钮
# 注意这里最后 最好用class限定 以防出现最后几页前面标签变少了位置有问题的情况
next_page.click() # 点击下一页
get_goods() # 函数里面自己调用自己 就可以如法炮制继续爬数据
'''
但是这样做太绝了函数没法随时叫停
一停下来就报错就只能一直爬到结束位置
'''
try: # 所以放弃直接调用 而是将他放入异常捕获里
get_goods()
except BaseException as e: # 如果出现报错那就是爬虫停了
print('今天就爬到这里') # 提示结束
finally: # 无论以哪种方式结束都要走一下两个流程
'''
pycharm对底层进行了优化
为了节省资源 会将没有save的数据和页面爬取完的数据放在一个内存地址里面
实际上这两个数据虽然是一样的 但是最后需要去的地方并不同
虽然达到节约内存的效果
也会导致一旦关掉浏览器再保存表格的话 表格数据的丢失
这里就只能先保存再关闭浏览器
'''
wb.save('%s.xlsx' % good_name) # 将之前插入表格的数据保存起来
bro.close() # 关掉浏览器
知乎登录
1.在电脑端想要访问知乎就必须得要登录的
2.通过network看到发送登录的请求体数据为加密
加密的代码关键字:encrypt
解密的代码关键字:decrypt
3.那就去source搜索本地的js代码中的encrypt然后找到唯一的那个确定的加密代码后
4.对起加密作用的代码加上断点 观察内部请求体的真实数据
5.随后再分析其中的键值对代表的意义
...

