
9/29
今日考题
1.详述爬取城市名称思路(尽可能详细及细节)
1.首先来到我们所要爬取的网站观察加载方式
2.直接加载的话就请求访问 如果不行就考虑防爬加上请求头
3.先看一眼爬下来的数据有没有乱码或者别的什么情况 如果有考虑编码
4.没有就通过解析器解析
5.之后寻找页面规律 尝试通过解析库将所需内容爬下来
6.获取的时候可以顺带获取网页链接将其拼接成详情页网址
7.可是详情页无法检查 关键数据还是动态加载的所以就有些束手无策了
2.详述爬去猪八戒订单数据思路
1.首先打开网址 观察加载方式 是直接加载的那就直接发送请求
2.看一下获取到的文本数据 如果有问题考虑防爬和解码
3.解析后观察网页查找所需数据的规律 先是网页地址的搜索结果是额外参数控制
4.可以在params里面添加一个键值对来控制所需搜索内容
5.网页所需数据通过li布局在网页上 但是有些li则是广告
6.如果是以全局直接查找的思路并不是不行 可以通过先限定li的class属性来定位到所需数据的外层li
7.再通过解析一步步向内找到所需数据
8.最后将获取的数据添加进表格存储
3.聊聊selenuim
原本是一款用于测评的工具
可是能够直接操作浏览器 对于爬虫来说简直是如虎添翼
所以就被运用到爬虫领域
1.使用的时候要先下载模块之后还要下载浏览器对应的驱动才行
2.驱动有时候会不能用可能是版本不对 也可能下错浏览器的驱动了
3.驱动文件建议放在python解释器的scripts内就可以直接用了 是最方便的办法
4.全部搞定之后可以通过代码验证看看
from selenium import webdriver # 导入模块
import time # 一会儿停一下方便看效果
bro = webdriver.Chrome() # 指定操作的浏览器驱动
bro.get("http://www.bilibili.com") # 控制浏览器访问网站数据
time.sleep(3) # 停一下方便观察
bro.close() # 关闭浏览器
复习巩固
- xpath解析城市名
# xpath选择器支持多条件筛选
xpath('//div[@id="d1"] | //div[@class="c1"]')
# 中间通过|表示或条件即可
- xpath解析订单数据
# 针对数据处理要灵活使用python基础操作
.strip() \ .join()
# 对于数据处理的这些内置方法一定要熟练
- xpath解析贴吧数据
# 获取每个帖子的链接 之后访问该链接 最后在详情页中筛选所需数据
校验访问次数较为严苛 一定要设置时停
- selenium自动化测试工具
selenuim是一款自动化测试工具原本只在测试领域使用
但是由于该工具可以操作浏览器所以渐渐的在爬虫领域火热起来
在python如果需要使用则必须先下载模块
pip3 install selenuim
还需要针对不同的浏览器下载不同驱动文件
chromedriver.exe
该文件推荐放在python解释器文件夹内的scripts内
scripts路径也必须添加到系统环境变量
selenuim自带的查找标签的方法
find_element_by_id() # find()
find_elements_by_tag_name() # find_all()
内容概要
- selenium其他操作
- 图片验证码和滑动验证码破解思路
- 大型复杂爬虫案例讲解
1.b站视频
2.知乎登录
3.小说爬取
'''至少能说出个大概'''
详细讲解
selenium其他操作
tag.get_attribute('src') # 获取属性
tag.text # 获取文本内容
print(tag.id) # 获取标签ID
print(tag.location) # 获取标签位置
print(tag.tag_name) # 获取标签名称
print(tag.size) # 获取标签大小
browser.back() # 模拟浏览器后退
browser.forward() # 模拟浏览器前进
browser.get_cookies() # 获取cookie
browser.add_cookie({'k1':'xxx','k2':'yyy'}) # 设置cookie
# 运行js代码
from selenium import webdriver
import time
bro=webdriver.Chrome()
bro.get("http://www.baidu.com")
bro.execute_script('window.scrollTo(0,200)') # 鼠标滚轮移动
time.sleep(5)
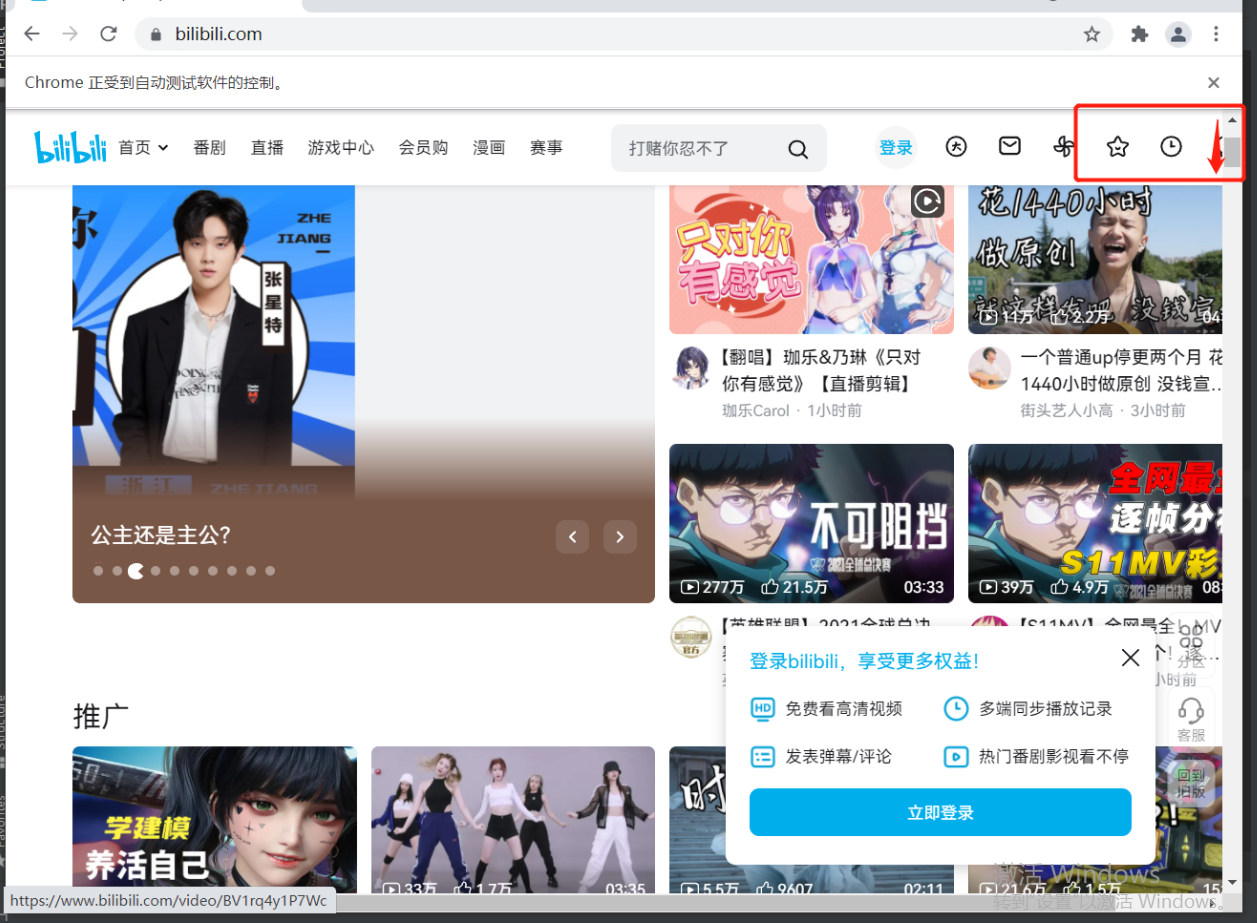
# 控制选项卡
import time
from selenium import webdriver
browser=webdriver.Chrome()
browser.get('https://www.baidu.com') # 打开百度
browser.execute_script('window.open()') # 开个新的标签页
print(browser.window_handles) # 获取所有的选项卡
browser.switch_to_window(browser.window_handles[1]) # 定位到第二个选项卡
browser.get('https://www.taobao.com') # 打开淘宝
time.sleep(3)
browser.switch_to_window(browser.window_handles[0]) # 定位去第一个选项卡
browser.get('https://www.sina.com.cn') # 打开新浪
browser.close() # 关闭当前选项卡
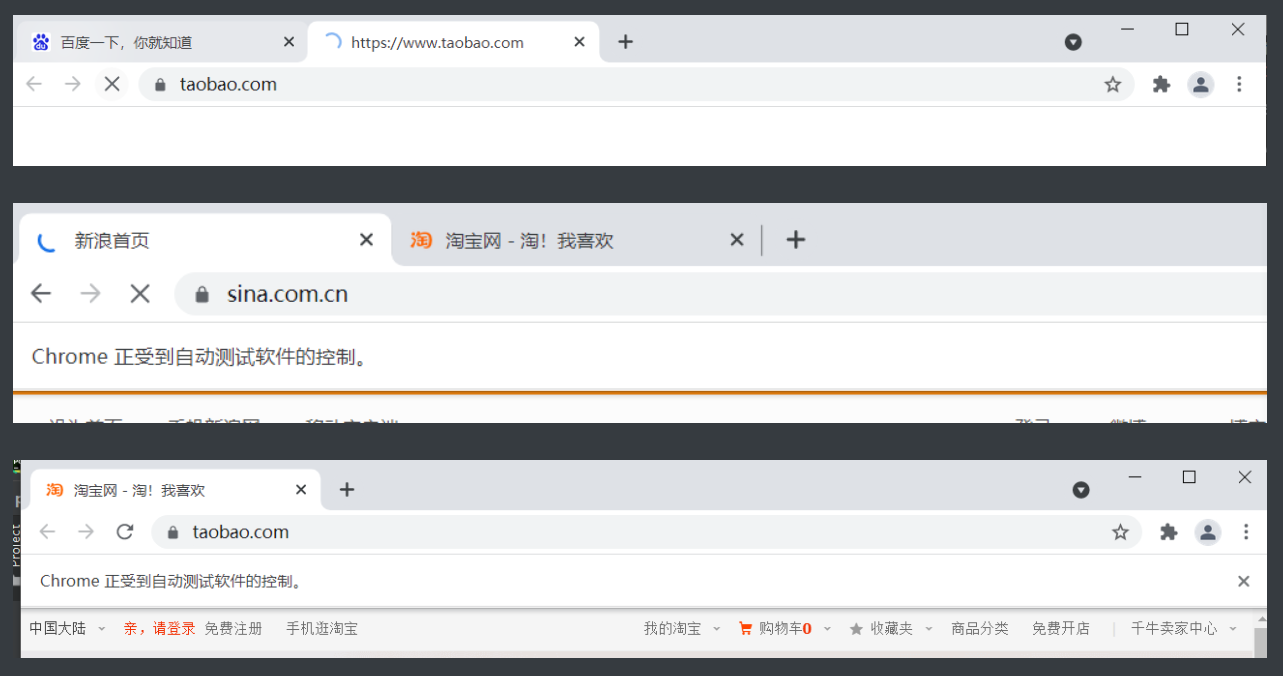
# 动作链(滑动验证码没有代码破解的必要 不如手动滑获取cookie即可)
# 动作链(页面上嵌套页面>>>iframe)
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
driver = webdriver.Chrome()
driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') # 一个可以查看效果的网页
driver.switch_to.frame('iframeResult') # 必须要指定iframe标签 不然找不到
sourse = driver.find_element_by_id('draggable')
target = driver.find_element_by_id('droppable')
# 方式一:基于同一个动作链串行执行(速度太快不合理)
# actions = ActionChains(driver) # 拿到动作链对象
# actions.drag_and_drop(sourse, target) # 把动作放到动作链中,准备串行执行
# actions.perform()
# 方式二:不同的动作链,每次移动的位移都不同
actions = ActionChains(driver)
actions.click_and_hold(sourse)
distance = target.location['x'] - sourse.location['x'] # 算出所需的位置差
track = 0
while track < distance: # 通过循环控移动到哪里
actions.move_by_offset(xoffset=2, yoffset=0).perform() #移动
track += 5 # 控制每次移动距离
time.sleep(0.5)
actions.release() #结束动作
driver.close()
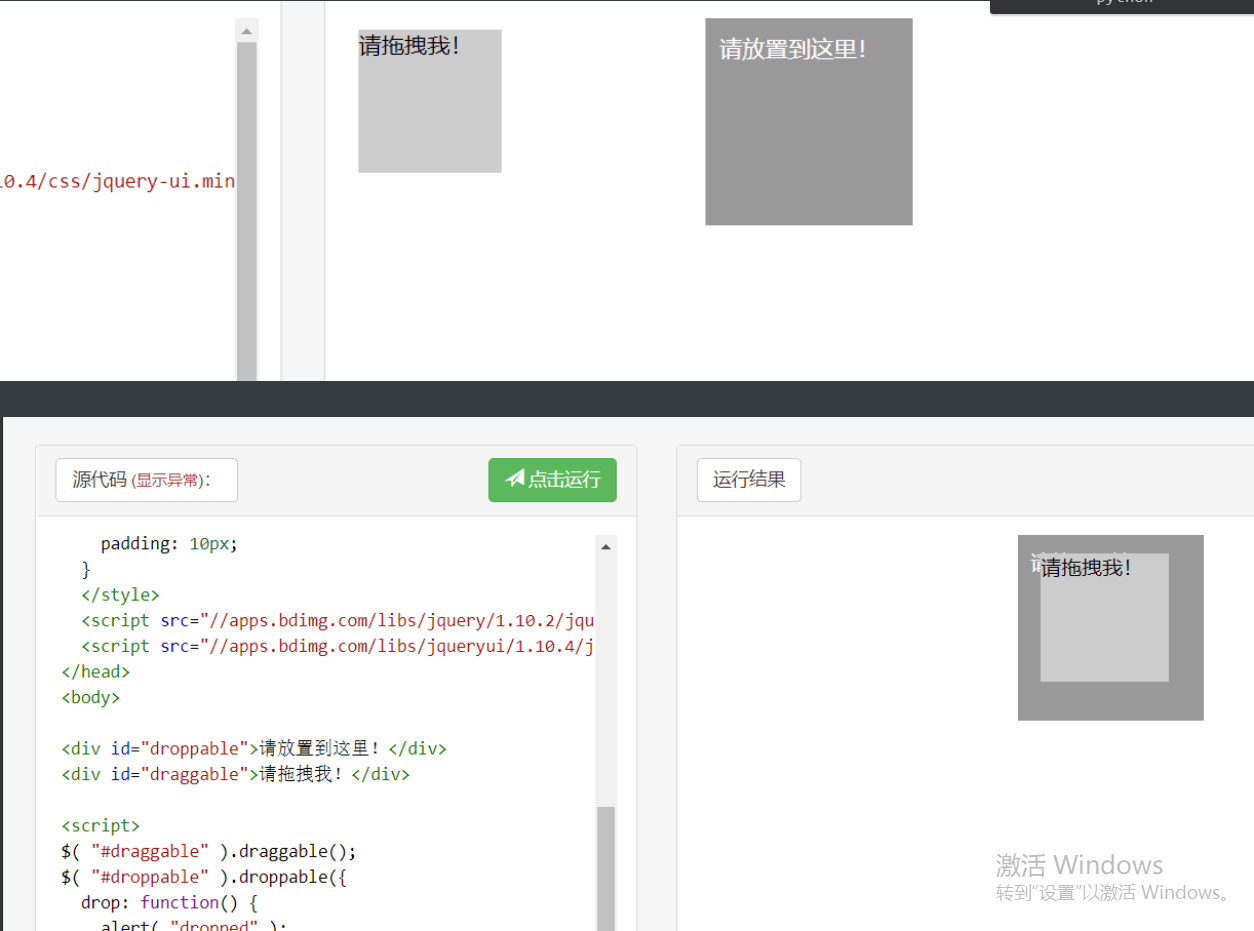
# 其实针对滑动验证码不推荐用程序破解
还不如自己手动划一下来的快
'''滑动验证码在拖动的时候不能太快
不然内部的检测机制会认为是程序操作'''
# 注意iframe标签这个东西相当于在原有网页的z轴上又构建了一个小网页
有完整的html代码有head有body
所以在找里面的标签的时候要加入
driver.switch_to.frame('iframeResult') # 必须要指定iframe标签
无界面操作
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
bro = webdriver.Chrome(chrome_options=chrome_options)
bro.get('http://scxk.nmpa.gov.cn:81/xk/')
# 如何获取页面html代码
print(bro.page_source)
'''可以去药品许可证界面尝试'''
# 上面的获取方法就相当于已经拿到浏览器完整获取的网页了动态加载也不怕
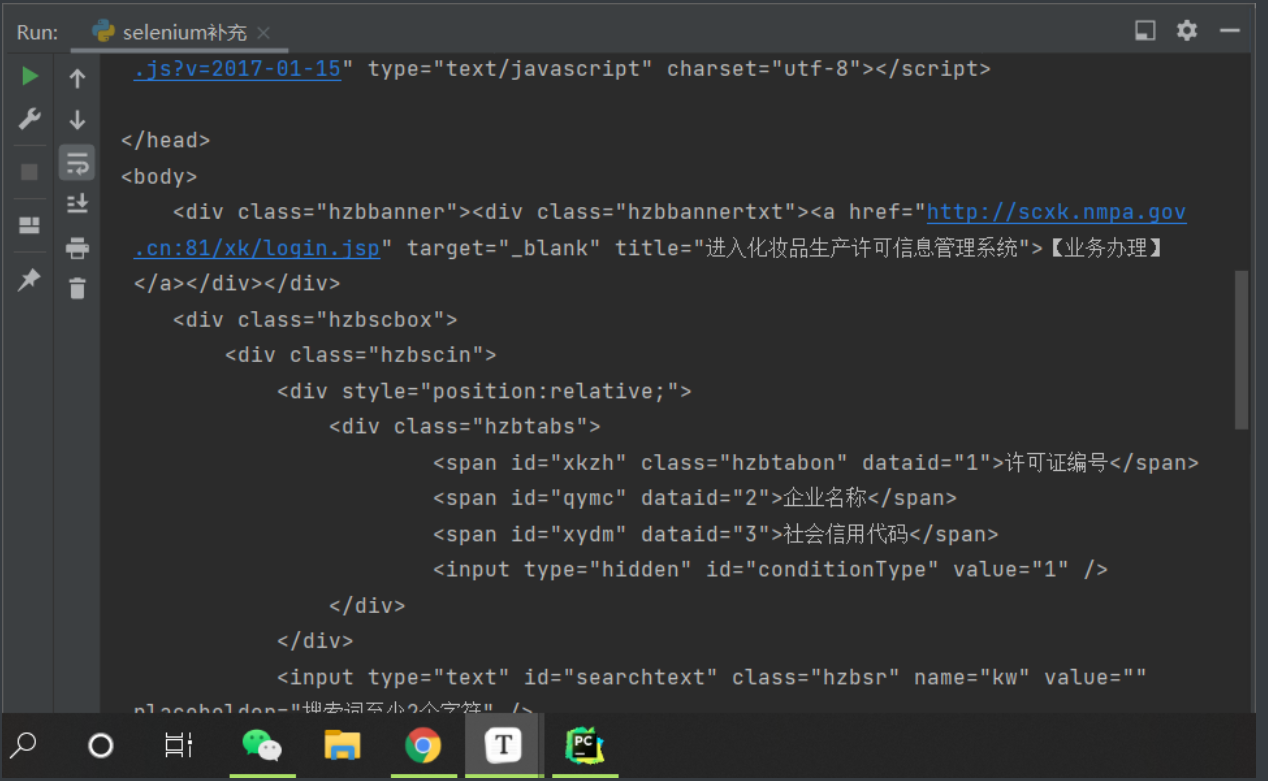
针对selenium防爬
# 很多程序是可以分辨出来当前浏览器是否被selenuim操作 我们可以在代码中添加如下配置即可避免被识别
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitchers',['enable-automation'])
bro = webdriver.Chrome(options=option)
cookie登录
import requests
from selenium import webdriver
import time
import json
# 使用selenium打开网址,然后让用户完成手工登录,再获取cookie
# url = 'https://account.cnblogs.com/signin?returnUrl=https%3A%2F%2Fwww.cnblogs.com%2F'
# driver = webdriver.Chrome()
# driver.get(url=url)
# time.sleep(30) # 预留时间让用户输入用户名和密码
'''登录进入之后cookie已经生成了'''
# driver.refresh() # 刷新页面
# c = driver.get_cookies() # 获取登录成功之后服务端发返回的cookie数据
# print(c) # 有时候会有大量的伪装cookie没关系全部保存来者不拒
# with open('xxx.txt', 'w') as f:
# json.dump(c, f)
'''上面就把登录所需的cookie保存下来了'''
cookies = {}
with open('xxx.txt', 'r') as f:
di = json.load(f)
# 获取cookie中的name和value,转化成requests可以使用的形式
for cookie in di:
cookies[cookie['name']] = cookie['value']
# # 使用该cookie完成请求
# response = requests.get(url='https://i-beta.cnblogs.com/api/user', cookies=cookies)
# response.encoding = response.apparent_encoding
# print(response.text)
"""
seleuinm拿cookie
requests拿cookie去模拟爬取数据
"""
图片验证码破解思路
思路1: 完全使用代码破解
图像识别技术
软件:Tesseract-ocr
模块:pytesseract
思路2: 打码平台
花钱买第三方服务
先使用代码识别如果不想其实还有一帮员工肉眼识别
思路3: 自己人工智能识别
这个难度也不小 得搞个视觉网络
b站视频案例
1.b站大部分视频是一分为二的
分为视频(只有画面没声音)和音频
https://www.cnblogs.com/xiaoyuanqujing/articles/12016934.html
https://www.cnblogs.com/xiaoyuanqujing/articles/12014416.html
至于怎么合到一起有专门的软件
红薯王小说案例
示范案例密码 xiaoyuanqujing@666
1.小说详情页面中鼠标左右键都禁用了
但是可以用f12调出控制台
2.小说文字不是直接加载
查看动态请求
从多条请求中找所需的
3.多次观察从请求中发现可疑数据
https://www.hongshu.com/bookajax.do
content:加密数据
other:加密数据
bid: 3052
jid: 3317
cid: 98805
4.寻找破解加密的办法
# 经验之谈
涉及到数据解密肯定需要写js代码
并且一般都会出现关键字decrypt
这里要充分反向思维 这么长的密文不可能平白无故发过来吧
迷惑项没必要搞这么长还要加密 所以这段加密的数据铁定有用
# 之后就要通过source里面去查找这个关键字然后再找哪些可能有关
文字主要内容的界面
utf8to16(hs_decrypt(base64decode(data.content), key))
上面content解密之后仍然存在数据缺失的情况
utf8to16(hs_decrypt(base64decode(data.other), key))
other解密之后是一段js代码
# 自然有理由怀疑缺失的部分是由js代码控制着的了
5.自己建一个html文件
将content内部拷贝进body
将js代码存在外部引入html文件夹
就能观察到完整效果了
https://www.cnblogs.com/xiaoyuanqujing/protected/articles/11868250.html
6.虽然内容全部出来了但是缺掉的字都在:befor标签的css属性里
通过js注入来解决
1.通过js定位到所有的:befor标签
2.然后,获取到css属性的值(缺失的文字)
3.把缺失的文字插入到标签之间(innerText)
selenium带cookie访问百度
from selenium import webdriver
import time
from selenium.webdriver import ChromeOptions
from selenium.webdriver.common.keys import Keys
# option = ChromeOptions()
# option.add_experimental_option('excludeSwitchers', ['enable-automation'])
bro = webdriver.Chrome() # 设置防爬
bro.get('http://www.baidu.com') # 打开百度网页
login = bro.find_elements_by_css_selector('a#s-top-loginbtn')[0] # 通过id直接找到百度右上角登录
login.click() # 点击一下
# 这个登录窗口不是通过iframe加载的那就直接找到输入框传值就行了
username = bro.find_element_by_id('TANGRAM__PSP_10__userName')
username.click()
username.send_keys('13331879807')
time.sleep(2)
password = bro.find_element_by_id('TANGRAM__PSP_10__password')
password.click()
password.send_keys('19981129yang')
time.sleep(3)
password.send_keys(Keys.ENTER)
time.sleep(5)

