9/27
今日考题
1.列举你所知道的防爬措施及解决方案
1.ip代理池
一个ip连续访问多次 会被检测到异常并封禁
通过构建一个ip代理池使用不同的ip访问
2.cookie代理池
一个cookie(即账户)短时间内访问多次 会被封禁
通过构建一个cookie代理池使用不同的cookie问
3.浏览器访问地址
需要校验请求发送方式 如果不是浏览器发送的会被拒绝
在请求头中携带浏览器键值对
4.图片防盗链
校验请求发送的地址 不是该网页所认可的地方发出的请求就会被拒绝
在请求头中加入referer键值对
5.页面干扰项
在网页中加入一些不符合规律的标签干扰爬取
通过if判断筛选掉
2.详述链家二手房数据爬取思路
1.首先找到网页发现网页加载规律 直接加载的
2.解析后找到包含所需数据的li标签
3.筛选出li标签的列表后循环取到每个房子的数据
4.通过bs4模块筛选到所需数据 这个网站页面复制不太方便所以正则不太好用
5.取到相应数据后对一些组合数据进行字符串的分割
6.对于这些数据中可能出现的缺失做上一点处理
7.使用openpyxl模块创建表格工作簿根据数据插入表头 # 这行代码在爬取前
8.将爬取到的数据汇集成列表形式整行插入
9.观察网页翻页规律 通过循环取值控制翻页
10.将翻页循环加入爬取前控制网页
3.详述汽车之家新闻数据爬取思路
1.首先找到网页发现网页加载规律 虽然滚到底部会有新的加载但是并没有和外界请求数据
# 这种情况就是直接写在页面上的 是通过网页内部js请求实现的加载
2.所以直接获取网页信息即可 然后还是筛选出包含信息的li标签列表
3.这时候不难发现有个别li标签并不包含所需数据
4.为了跳开这些数据就需要去增加一个if判断循环后取到的单个li中是否有所需标签
5.以第一个链接为例先正常通过bs4获取到所需链接标签
如果li为干扰项此处标签即a标签会筛选后会产生一个空值
6.对空值取反加上if判断后continue跳过整个li标签
7.因为在这步已经continue结束了这个li的干扰项后面就正常筛选即可
8.但是并不排除可能出现干扰项中的确有a标签的情况
9.如果有可以在出现报错后根据情况再加上和上面同理的if判断
10.之后观察翻页规律通过for循环控制访问的网站翻页爬取就到此结束
11.使用openpyxl模块将数据写入表格
复习巩固
- 爬取链家二手房数据
1.判断页面数据
2.直接发送请求获取html
3.解析之后获取数据
4.利用openpyxl写入表格
5.考虑多页
'''一般就两种情况
1.url有规律
2.通过请求体有规律的发送请求
'''
- 爬取汽车之家新闻数据
1.判断页面数据来源
汽车之家通过内部js动态加载
所以一开始拿数据的时候就已经拿到了后面加载的更多内容了
2.页面干扰项
页面上有些不符合规律的标签要把他筛掉
3.后面就和大部分爬取一样
4.解析筛选 写入 思考多页
内容概要
- 豆瓣换个方法
- Xpath解析器
- 爬取猪八戒外包网站
内容详细
Xpath解析器
'''
这个解析器可以做到一步到位
就是通过一行代码直接精确掌握到所在位置
'''
from lxml import etree # 这边名字要注意
import requests
'''T0 基本中的基本'''
res = requests.get('http://www.obzhi.com/')
html = etree.HTML(res.text) # 通过etree解析HTML格式的文本数据
all = html.xpath('//*') # 匹配所有的标签
head = html.xpath('//head') # 匹配所有的head标签 结果是个迭代器列表
son_a = html.xpath('//div/a') # 匹配div标签内部所有的儿子a标签 /代表儿子
a = html.xpath('//body//a') # 匹配div标签内容所有的后代a标签
a1 =html.xpath('//body//a[@href="image1.html"]') # 获取body内部所有的href=image1.html后代a 通过后面指定的属性查找
a2 = html.xpath('//body//a[@href="image1.html"]/..') # ..表示查找上一级父标签 和cmd指令里一样
a3 = html.xpath('//body//a[1]') # 取第一个a标签 这个1是真的从1开始取值
a4 = html.xpath('//body//a[1]/parent::*') # a3的父级标签 但是这个不常用/..直接能搞定
a5 = html.xpath('//body//a[@href="image1.html"]/text()') # 获取href为image1.html的a标签内文本
a6 = html.xpath('//body//a/text()') # 获取body内部所有后代a内部文本(一次性获取不需要循环)
a7 = html.xpath('//body//a/@href') # 获取body内部所有后代a标签href属性值 结果是个列表
a8 = html.xpath('//title/@id') # 获取title标签id属性值
a9 = html.xpath('//body//a[2]/@href') # 获取body后代a中第二个的href标签属性
'''当属性有多个class标签的时候
直接用@class=就不行了 =意味着完全一样
包含要用另一种方法'''
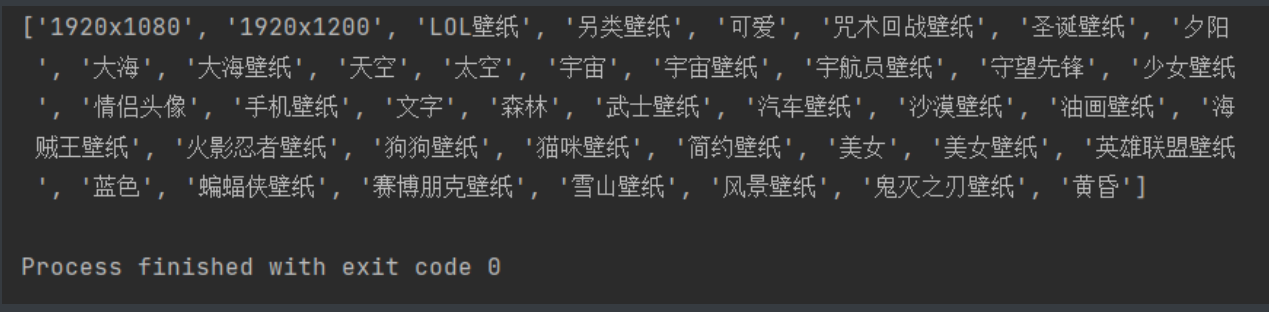
a10 = html.xpath('//body//a[contains(@class,"li")]/text()') # class属性中包含li的...标签
# 包含需要使用关键字contains
'''这个解析器内部匹配的时候甚至支持逻辑运算'''
a11 = html.xpath('//body//a[contains(@class,"li") or @name="items"]')
# 查找body标签内部所有class含有li或者name=items的a标签
a12 = html.xpath('//body//a[contains(@class,"li") and @name="items"]/text()')
# 查找body标签内部所有class含有li并且name=items的a标签的内部文本
'''Xpath解析器中不仅可以按数字顺序取值
还可以对顺序取值做出一些要求'''
a13 = html.xpath('//a[last()]/@href') # 取最后一个a标签的href
a14 = html.xpath('//a[position()<3]/@href') # 取位置顺序小于3(前两个)的a标签的href
# position()关键字 用于定位
a15 = html.xpath('//a[last()-2]/@href') # 取最后一个再向前数两个(倒数第三个)a标签的href
# 最后以a10的获取效果为例
print(a10)
Xpath了解部分
'''T3'''
# 11 节点轴选择
# ancestor:祖先节点
# 使用了* 获取所有祖先节点
a = html.xpath('//a/ancestor::*')
# # 获取祖先节点中的div
a = html.xpath('//a/ancestor::div')
# attribute:属性值
a = html.xpath('//a[1]/attribute::*') # 查找a标签内部所有的属性值
# child:直接子节点
a = html.xpath('//a[1]/child::*')
# descendant:所有子孙节点
a = html.xpath('//a[6]/descendant::*')
# following:当前节点之后所有节点
a = html.xpath('//a[1]/following::*')
a = html.xpath('//a[1]/following::*[1]/@href')
# following-sibling:当前节点之后同级节点
a = html.xpath('//a[1]/following-sibling::*')
a = html.xpath('//a[1]/following-sibling::a')
a = html.xpath('//a[1]/following-sibling::*[2]/text()')
a = html.xpath('//a[1]/following-sibling::*[2]/@href')
print(a)
豆瓣top250Xpath加cell插入表格
import requests
from openpyxl import Workbook
import time
from lxml import etree
wb = Workbook()
wb1 = wb.create_sheet('电影排行数据', 0)
# 先创建表头数据
wb1.append(['详情链接', '电影名称', '电影详情', '电影评分', '评价人数', '电影座右铭'])
def get_movie(n):
page = n*25
print('开始获取新的一页')
url = 'https://movie.douban.com/top250?start=%s&filter=' % page
# print(url)
res = requests.get(url,
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36"
}
)
x_html = etree.HTML(res.text)
li_list = x_html.xpath('//*[@id="content"]/div/div[1]/ol/li')
# print(li_list)
count = 2
for li in li_list:
a_link = li.xpath('./div/div[1]/a/@href')[0]
wb1.cell(row=page+count, column=1, value=a_link)
# print(a_link)
title = li.xpath('./div/div[1]/a/img/@alt')[0]
wb1.cell(row=page+count, column=2, value=title)
# print(title)
detail = li.xpath('./div/div[2]/div[2]/p[1]/text()')[0].strip()
wb1.cell(row=page+count, column=3, value=detail)
# print(detail)
score = li.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
wb1.cell(row=page+count, column=4, value=score)
# print(score)
comment_num = li.xpath('./div/div[2]/div[2]/div/span[4]/text()')[0]
wb1.cell(row=page+count, column=5, value=comment_num)
# print(comment_num)
short_nearly = li.xpath('./div/div[2]/div[2]/p[2]/span/text()')
short = short_nearly[0] if short_nearly else '暂无短评'
wb1.cell(row=page+count, column=6, value=short)
# print(short)
count = count+1
for i in range(10):
get_movie(i)
time.sleep(3)
wb.save(r'豆瓣top250.xlsx')

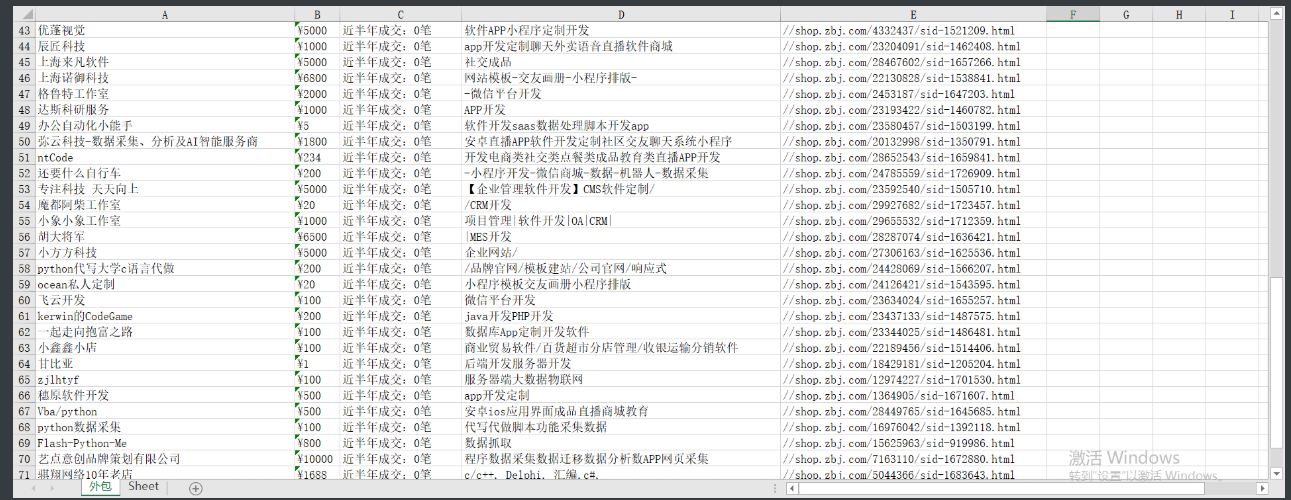
猪八戒网站爬取
import requests
from lxml import etree
from bs4 import BeautifulSoup
from openpyxl import Workbook
wb = Workbook()
wb1 = wb.create_sheet('外包', 0)
wb1.append(['公司名称','价格','成交数','业务范畴','详情链接'])
work = input('请输入你想要的业务').strip()
res = requests.get('https://shanghai.zbj.com/search/f/',
params={'kw': work})
x_html = etree.HTML(res.text)
soup = BeautifulSoup(res.text, 'lxml')
company_tag_list = soup.select('a.service-bottom-wrap.j_ocpc > div.service-shop.clearfix > p')
company_list = []
for company_tag in company_tag_list:
company = company_tag.text
company_list.append(company)
price_list = x_html.xpath('//*[@id="utopia_widget_76"]/a[2]/div[2]/div[1]/span[1]/text()')
# 直接通过网页提供的xpath路径找到所在位置
deal_num_list = x_html.xpath('//*[@id="utopia_widget_76"]/a[2]/div[2]/div[1]/span[2]/text()')
item_include_list = x_html.xpath('//*[@id="utopia_widget_76"]/a[2]/div[2]/div[2]/p/text()')
link_list = x_html.xpath('//*[@id="utopia_widget_76"]/a[2]/@href')
# print(link_list)
full_info_list = zip(company_list, price_list, deal_num_list, item_include_list,link_list)
for full_info in full_info_list:
# print(full_info)
wb1.append(list(full_info))
wb.save(r'八戒八戒.xlsx')