9/25
今日考题
1.详述梨视频多页爬取思路
先对网站进行一个初步分析,看看网站上的一个个视频的链接是怎么加载出来的。
可以看到这个是直接写在页面上的那就向页面发送get请求然后获取整个网页
随后分析里面a标签链接的规律 可以通过外层的div类属性先定位父级div然后找到这个div所属的儿子a
之后就能简单的拿到a标签指向的地址进行拼接后获得所需网址
之后再观察下一个网页我所需要爬取的视频是怎么加载出来的 发现这个是动态加载的
那之前拼接出来的网址就基本宣告报废了只能另寻线索
看一下动态请求发往哪里这个网站打开是什么
这时候又遇上了障碍 是防盗链的防爬措施 那也就知道了需要在get的请求头中加入referer参数
可是这样还是没法找到视频具体地址 只好再看看
通过elements可以找到视频链接的实际地址但是我没法找到这个请求
查看动态请求的response之后看到一个MP4
结尾的网址和真实地址十分接近 只是后面有一串不明所以的数字和视频地址那里固定组合加上视频id号不同
那只要找出这串数字的来历把他替换成固定组合不就能得到完整地址了嘛
仔细搜索也不难发现这串数字在response中对应systemtime取值后将其换成对应的id
得到完整网址之后发送get请求获取最终数据保存下来就行了
至此就完成了单页的爬取 现在来研究翻页
滚动到底部不难发现网页又刷新了视频这一看就是动态加载
所以去fetch中验证自己的猜想 果然是会向一个网站发送请求再加载
那这个网站取出将后面没有规律不可控的去掉能访问嘛
结果是可以的 所以只要找到前面参数的规律翻页的规则也就攻破了
参数是12的倍数那试试参数为0能不能访问
没有问题那就直接将动态获取参数带进params请求换掉第一个get请求发送的网址即可
2.操作excel表格的模块有哪些,挑一个讲讲主要功能
xlrd、wlwt模块
xlrd控制读文件 wlwt控制写文件
openpyxl模块
可以控制读写
from openpyxl import Workbook
wb = Workbook() # 创建新excel
wb1 = wb.create_sheet('工作簿名字',0) # 创建工作簿 后面数字代表位置
wb1.title = '新名字' # 修改工作簿名字
print(wb.sheetnames) # 看表格里所有工作簿名字
wb1['A1'] = 1 # 写入A1位置
wb1.cell(column=1, row=2, value=2) # 根据哪行哪列插入数据
wb1.append([1,2,3,4]) # 整行插入
wb1['A4'] = '=sum(A1+A2)' # 插公式
wb.save(r'表格名字.xlsx') # 最后保存的时候定义表名
wb = load_workbook(r'表格名字.xlsx', data_only=True)
wb1 = wb['里面某个工作簿名字']
print(wb1['A2'].value) # 获取规定位置数据
print(wb1.cell(row=1, column=1).value) # 根据行列读数据
for row in wb1.rows: # 整行读 结果是迭代器
for r in row: # 读每行信息 结果是列表
print(r.value) # 拿到最后一个个格子的信息
3.详述豆瓣电影top250爬取思路
首先明确所需信息是直接加载在页面上的那没什么好说的直接先将网页爬取下来解析
然后打开表格创建工作簿准备写入
通过正则爬取到所需数据的列表备用
对于短评会有些电影没有那就先通过选择器拿到一个个电影对应的li标签
再去判断短评特定的span标签是否再其中
在就通过正则获取
不在则自行定义后输入
做成列表
zip组合之后写入
复习巩固
- 梨视频多页爬取
梨视频多页数据是通过鼠标滚轮滚动到屏幕固定的位置之后自动刷新内容
页面不可能自动刷新数据而内部不存在请求
研究发现朝着内部动态请求的地址发送请求可以获取到html代码
并且也含有我们需要的详情页链接地址
- openpyxl模块
1.excel版本不同文件后缀名
.xls .xlsx
2.能够操作excel表格的模块
openpyxl xlrd wlwt
# 如何创建文件及工作簿
from openpyxl import WorkBook
wb = WorkBook()
wb1 = wb.create_sheet('工作簿')
wb.save(r'111.xlsx')
# 如何写入数据
wb1['A1'] = 111
wb1.cell(row=1,column=1,value=111)
wb1.append(['name','age','gender'])
# 如何读取数据
from openpyxl import load_workbook
wb = load_workbook(r'111.xlsx')
wb.sheet_names
wb1 = wb['工作簿']
'''记住核心功能 其他的可以百度查看文档'''
- 豆瓣电影top250
接下来详解
内容概要
- 豆瓣讲解
- 爬链家二手房并写入文件
- 爬汽车之家新闻数据
详细讲解
豆瓣top250
import requests
import re
import time
from bs4 import BeautifulSoup
from openpyxl import Workbook
'''
万变不离其宗第一步总归是观察网页 从第一页开始先不要想分页就先爬一页
1.看第一页的数据加载方式
2.是直接加载的那就可以直接下手爬网站了
'''
wb = Workbook() # 打开表格
wb1 = wb.create_sheet('豆瓣表格', 0) # 定义好工作簿
wb1.append(['电影名', '导演', '主演', '评分', '评价人数', '短评']) # 插入表头
def movie_rank(n):
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
res = requests.get(url,
headers=headers,
params={'start': n}) # 通过n控制页数
net = res.text # 转文本方便解析
soup = BeautifulSoup(net, 'lxml')
title_list = re.findall('<img width="100" alt="(.*?)" src=', net) # 正则爬电影名
direct_list = re.findall('导演: (.*?) ', net) # 正则爬导演
actor_list = re.findall(' 主演: (.*?) /...', net) # 正则爬主演
score_list = re.findall('property="v:average">(.*?)</span>', net) # 正则爬评分
comment_count_list = re.findall('<span>(.*?)人评价</span>', net) # 正则爬短评
li_list = soup.select('ol.grid_view>li') # 拿到短评所在标签外部li标签的列表缩小范围方便进一步操作
inq_list = [] # 定义空列表方便之后加
for li in li_list: # 取出一个个元素
li = str(li) # 把网页上的没有属性的东西转成字符串
if '<span class="inq">' in li: # 字符串包含运算
inq_part = re.findall('<span class="inq">(.*?)</span>', li) # 有就可以正则拿到短评
inq_list.append(inq_part[0]) # 拿到后取出元素写入
else:
inq_part = '暂无短评' # 没有自己加一个字段
inq_list.append(inq_part) # 也写入列表
full_info = zip(title_list, direct_list, actor_list, score_list, comment_count_list, inq_list) # 整合成一起
for i in full_info: # 拿出里面的组合
wb1.append(list(i)) # 转成列表写入
time.sleep(10) # 吸取被封ip的教训停久点
for n in (0, 225, 25): # 翻页规律控制
movie_rank(n) # 把实参给函数
wb.save(r'豆瓣top250.xlsx') # 别忘了最后保存
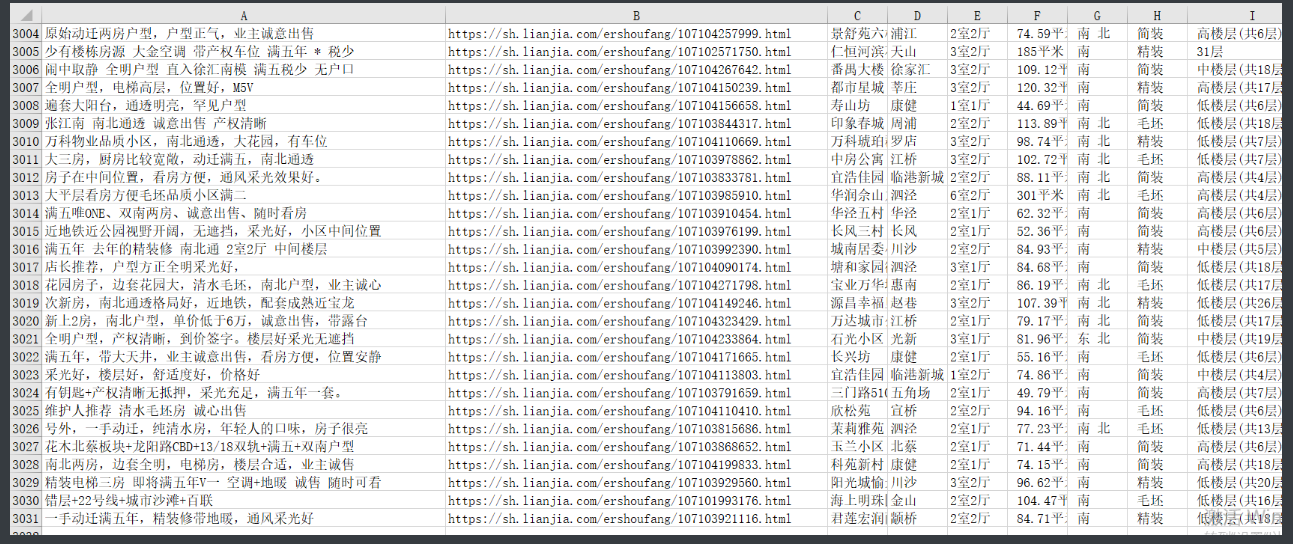
爬链家二手房
import time
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
'''由于这个网站的网页源码排版看起来十分不友好
所以只能放弃正则通过bs4解析器爬取'''
wb = Workbook() # 开excel
wb1 = wb.create_sheet('二手房数据', 0)
# 先定义表头
wb1.append(['房屋名称', '详情链接', '小区名称', '区域名称', '房型', '面积', '朝向', '装修', '楼层', '竣工时间', '房屋属性', '关注人数', '发布时间', '总价', '单价'])
for n in range(0, 101): # 翻页
res = requests.get('https://sh.lianjia.com/ershoufang/pg%s/' % n) # 访问网页
# print(res.text)
soup = BeautifulSoup(res.text, 'lxml') # 解析
li_list = soup.select('ul.sellListContent>li.clear') # 通过外层选择到内部一个个li标签
for li in li_list: # 一一取出方便后续操作
a_tag = li.select('div.title>a')[0] # 选出a标签
# print(a_tag)
title = a_tag.text # 拿到文本为标题
link = a_tag['href'] # 拿到href标签为链接
# print(title, link)
location = li.select('div.positionInfo>a') # 选取li内部特定div标签下的儿子a
# print(location,len(location))
if len(location) == 2: # 由于有些数据不全在分割的时候要做一些处理
estate = location[0].text.strip() # 当有两个元素分开赋值
section = location[1].text.strip()
elif len(location) == 1: # 只有一个元素就赋值成一样的
estate = section = location[0].text
else: # 如果没有就自行定义
estate = section = '暂无信息'
# print(estate, section)
detail = li.select('div.houseInfo')[0].text # 获取到详细小信息
des = detail.split('|') # 分隔开
room = des[0] # 前4个一定有的就正常一一赋值
area = des[1]
towards = des[2]
decoration = des[3]
floor = des[4]
# print(len(des))
if len(des) == 7: # 针对后三个的情况特殊处理
completed = des[5] # 7个元素就是齐的
kind = des[6] # 正常赋值
# print(completed,kind)
if len(des) == 6: # 少一个就赋值一样的
completed = kind = des[5]
else: # 少两个就输入空
completed = kind = None
followInfo = li.find(name='div', attrs={'class': 'followInfo'}).text # 更具条件找到一个div 偶尔用用find不能冷落某个方法
focus_count, publish_time = followInfo.split('/') # 解压赋值掉
# print(focus_count, publish_time)
# break
full_price = li.select('div.totalPrice')[0].text # 和前面一样拿总价
part_price = li.select('div.unitPrice')[0].text # 再拿每平方米价格
wb1.append(
[title, link, estate, section, room, area, towards, decoration, floor, completed, kind, focus_count.strip(),
publish_time.strip(), full_price, part_price]) # 加进表格
time.sleep(1)
wb.save(r'二手房数据改.xlsx')
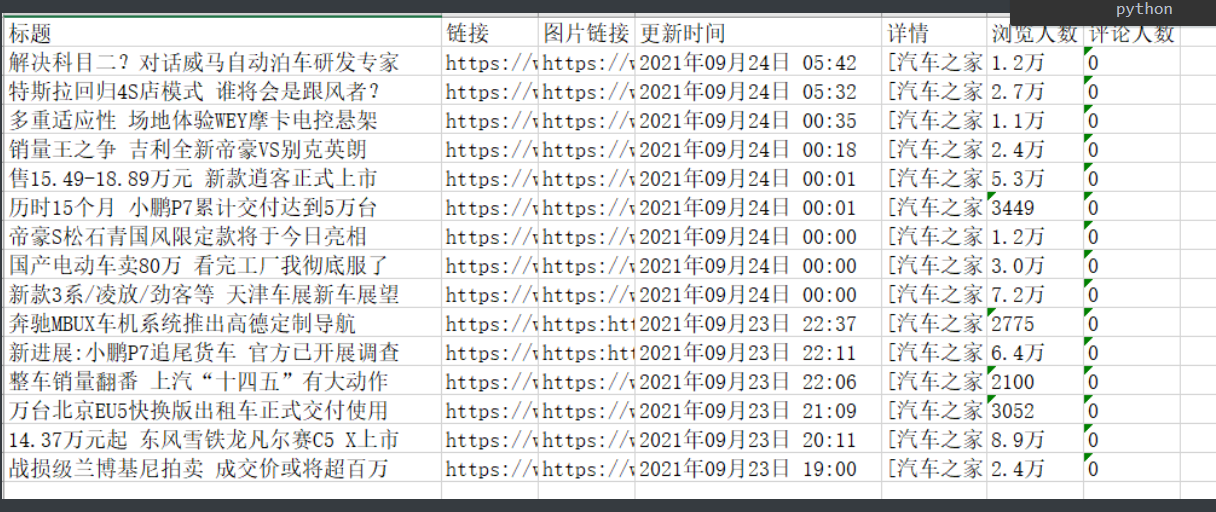
汽车之家新闻
明确获取新闻数据
新闻标题 新闻链接 新闻图标 发布时间 新闻简介
1.网页加载的方式虽然下滑到底会有新加载但是并没有请求从网站发出
这种也算动态加载吧 但是没有别的请求发出 是通过写好的js请求实现的
对于这种加载方式就直接把它看作是直接写在页面上的就好了
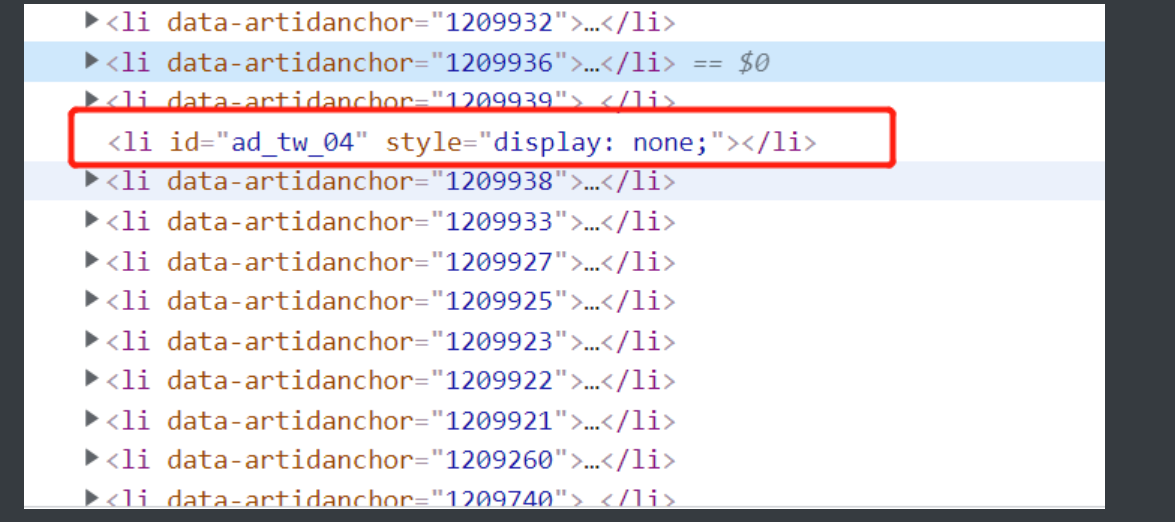
2.页面干扰
就是在正常的网页布局一面加了些没用的东西游离在常规规律之外
让你爬起来没这么舒服 但是这个解决方菲也很简单 只要加上一个if判断就能避开
import requests
from bs4 import BeautifulSoup
from openpyxl import Workbook
wb = Workbook()
wb1 = wb.create_sheet(r'汽车之家新闻', 0) # 创建工作簿
wb1.append(['标题', '链接', '图片链接', '更新时间', '详情', '浏览人数', '评论人数']) # 插入表头
def net_page(n): # 用来控制想要的页数 不过如果想要全爬下来就直接用for循环就行
url = 'https://www.autohome.com.cn/all/%s/' % n
return url # 把具体网址反出去
url = net_page(input('请输入想要查看的页码')) # 调用函数控制网页
res = requests.get(url,
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'})
res.encoding = 'gbk' # 查看网页编码后改成和网页一致
soup = BeautifulSoup(res.text, 'lxml') # 解析
li_list = soup.select('div#auto-channel-lazyload-article li') # 按照li标签分割出来 清晰思路
# print(li_list)
for li in li_list: # for循环取到一个个li
a_tag = li.find('a') # 找到第一个a标签
if not a_tag: # 有页面干扰项所以要做个判定如果里面没有a标签那a_tag的返回结果为空
continue # 通过取反然后直接跳过这个标签继续循环
link = 'https:' + a_tag.get('href') # 拼接标签里的网站获得详情页网址
res1 = requests.get(link,
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'})
# print(res1.text) # 这里就可以获得到详情页数据
'''
由于最后数据是准备放入表格的所以并没有去爬取大段的文字
但是实际上能够访问到详情页的数据
别的数据需求也只需要筛选即可难度不大
'''
soup1 = BeautifulSoup(res1.text, 'lxml') # 解析详情页
title = soup1.select('div#articlewrap>h1')[0].text # 象征性的拿一下详情页标题
# print(title)
img_link = 'https:' + li.select('div.article-pic>img')[0].get('src')
# print(img_link)
# img_get = requests.get(img_link, headers={
# 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'})
publish_time = soup1.select('div.article-info>span.time')[0].text # 时间拿详情页的比较好 外部是动态计算得到的直接取值比较麻烦
# print(publish_time)
detail = li.find('p').text # 找到预览目录页的详情小字段
view_count = li.select('span.fn-right>em')[0].text # 获取浏览人数
comment_count = li.select('span.fn-right>em')[1].text # 获取评论数量
# print(view_count,comment_count)
# print([title, link, img_link, publish_time, detail, view_count, comment_count])
wb1.append([title.strip(), link, img_link, publish_time.strip(), detail, view_count, comment_count]) # 将他们插入表格
wb.save(r'汽车之家.xlsx') # 保存表格