
9/23
今日考题(想象在回答面试官)
1.详述糗图百科爬取过程
首先呢,打开丑图百科的网站之后,我们先仔细看一下那个网站上面的图片是怎么加载。
因为我们要通过这个加载方式来决定我们的爬取策。
如果我没有记错的话,丑图百科,它是直接将这个图片写死,在这个网页上面的,所以我们直接从网页上面爬取,需要用到的就是request模块和BS4模块。
前期准备工作做好之后,就可以直接把整个网页扒下来,然后用bs4模块进行解析。
接下来就是去寻找那些img标签有什么共同点,然后尝试着把这些标签筛选出来。
当时我做的时候用的是标签它自带的一个分类属性。
通过分类找到这个标签之后,再将标签里面所链接的网址给筛选出来。
标签里面的网址不是完整的,所以要在下一步爬取之前进行一个手动的网址拼接。
筛选完之后,向这个网址发送请求,就可以获得到图片的二进制数据,然后将它保存到本地。
2.详述优美图库高清大图过程
啊,首先我是先打开优美图库,然后去看我所需要的这些图片,它到底是怎么样加载的方式?
加载方式,我记得是直接写在这个网页上面的,所以比较方便,直接可以用request模块将整个网页的数据全部先爬下。
先把爬取下来的整个网页数据进行一个规定的编码,用UTF8。
然后就要去找这些图片,它是什么样的一个规律。
当时这个规律并不难发现,他是用的一个个无序的列表方式,把图片布局在页面上的。
随后就可以通过这个无序列表外面的div去定位到列表位置,然后再通过这个列表定位到里面唯一的一个a标签。
获得到a标签之后,就是非常简单的一个取值,拿到它上面的href参数,拼接后获得完整网址。
进到这个网址之后就可以点进去,然后再重复前面的分析,看他是怎么加载。
你这边发现他的高清大图也是直接加载在网页上面。
那就直接向网页发送请求,爬下整个网页再考虑下一步
现在网页爬取完之后,我是习惯还会进行一次编码的限制,然后再去找图片标签的规律。
之后用CSS选择器就可以很简单的找到这个图片标签所在的位置。
最后取出图片标签所链接的网页地址,向这个网页发送一个请求,存储他返回的二进制数据就可以获得图片。
3.详述梨视频爬取过程
先对网站进行一个初步分析,看看网站上的一个个视频的链接是怎么加载出来的。
可以看到这个是直接写在页面上的那就向页面发送get请求然后获取整个网页
随后分析里面a标签链接的规律 可以通过外层的div类属性先定位父级div然后找到这个div所属的儿子a
之后就能简单的拿到a标签指向的地址进行拼接后获得所需网址
之后再观察下一个网页我所需要爬取的视频是怎么加载出来的 发现这个是动态加载的
那之前拼接出来的网址就基本宣告报废了只能另寻线索
看一下动态请求发往哪里这个网站打开是什么
这时候又遇上了障碍 是防盗链的防爬措施 那也就知道了需要在get的请求头中加入referer参数
可是这样还是没法找到视频具体地址 只好再看看
通过elements可以找到视频链接的实际地址但是我没法找到这个请求
查看动态请求的response之后看到一个MP4
结尾的网址和真实地址十分接近 只是后面有一串不明所以的数字和视频地址那里固定组合加上视频id号不同
那只要找出这串数字的来历把他替换成固定组合不就能得到完整地址了嘛
仔细搜索也不难发现这串数字在response中对应systemtime取值后将其换成对应的id
得到完整网址之后发送get请求获取最终数据保存下来就行了
ps:回答一定要有逻辑和连贯性并能够阐述一些难点或者规律点增加可信性!
复习巩固
爬虫项目为主
- 爬糗图百科图片
数据是直接在页面上加载的 利用bs4模块查找标签特性即可
这个案例就是个开胃小菜没啥难度
在查找标签的时候有两种策略
1.指名道姓的查找
待查找的标签本身就具备很强的辨识度
比如有明确的一个class
2.先整体再局部
待查找的标签本身没有很强的辨识度 并且很多地方都有相似的标签
那就一步步从外层开始查找
- 爬优美图库高清大图
注意所谓的高清大图是详细页面中的图片不是首页的小图片
"""
1.先朝主页发送请求
2.筛选出详细页面的地址
3.朝详细页面发送请求获取高清大图的地址
4.朝高清大图发送请求下载图片
"""
# 写爬虫的时候思路一定要清晰
注意使用解析工具解析到数据之后的数据类型到底是什么
以免数据操作的内置方法无法使用而报错
- 爬梨视频视频数据
1.首页爬取某个分类下的视频
2.分类下数据是直接加载的
3.通过解析工具获取视频详情页数据
4.详情页视频数据为动态加载的
5.研究动态加载的地址 发现返回了一个大字典 里面包含关键性数据
systemTime
srcUrl
6.研究srcurl发现直接请求无效 利用浏览器加载视频页比对地址
7.两者地址之间差距不大 只有一个systemTime的差距
8.利用视频id与systemsTime完成字符串替换操作
'''之后会单独出一个博客讲这个复杂案例'''
内容概要
- 作业讲解
- python操作表格
- 爬二手房数据写入表格
- 爬汽车之家新闻数据写入表格
- 爬豆瓣 Top250 数据写入表格
详细讲解
梨视频多页数据爬取思路
import requests
from bs4 import BeautifulSoup
import os
import time
if not os.path.exists(r'犁视频'): # 如果存储文件夹不存在
os.mkdir(r'犁视频') # 就创建一个
def pear_video(n):
# base_url = 'https://www.pearvideo.com/' # 实际网页是拼接而成的所以把前半部分先放好
res = requests.get('https://www.pearvideo.com/category_loading.jsp',
params={'reqType': 5,
'categoryId': 10,
'start': n}) # 先向这个网页发送请求
res.encoding = 'utf-8' # 设置编码好习惯
soup = BeautifulSoup(res.text, 'lxml') # 解析
a_tag_list = soup.select('div.vervideo-bd>a') # css选择器找得到这类div的儿子a
for a in a_tag_list: # 取出a
url_2nd = a.attrs.get('href') # 拿到href后面的链接
# url = base_url + url_2nd # 拼接起来就能进入下一个网站
# print(url_2nd) # video_1742218
headers = {'Referer': 'https://www.pearvideo.com/%s' % url_2nd} # 先定义好防爬的请求头
cont_id = url_2nd.split('_')[-1] # 分割取到所需字符
res1 = requests.get('https://www.pearvideo.com/videoStatus.jsp',
headers=headers,
params={'contId': cont_id}) # 向动态加载内部网页发送请求
almost_url = res1.json().get('videoInfo')['videos']['srcUrl'] # 通过字典取值拿到返回的网址数据 两种取值方法都试试
sys_time = res1.json()['systemTime'] # 拿到得到网址中想要替换掉的字符串
# 这样搞定了前面还鱼龙混杂的问题 现在只需要专心解决后面的那串数字怎么替换即可
'''
得到网址
https://video.pearvideo.com/mp4/third/20210922/1632319265938-15498275-115401-hd.mp4
最终目标
https://video.pearvideo.com/mp4/third/20210922/cont-1742218-15498275-115401-hd.mp4
两次替换之后
https://video.pearvideo.com/mp4/third/20210922/cont-1742218-15498275-115401-hd.mp4
'''
# 在网页的response里出现过这个数字 是系统时间
final_url = almost_url.replace(sys_time, 'cont-%s' % cont_id) # 通过字符串替换得到最终网址
# print(final_url)
# break
res2 = requests.get(final_url) # 发送请求
name = cont_id + '.mp4' # 给文件名加上后缀
media_add = os.path.join(r'犁视频', name) # 拼接文件路径
with open(media_add, 'wb') as f: # 以二进制写模式打开
f.write(res2.content) # 直接二进制写入
print('%s下好啦' % name) # 加个完成提示
time.sleep(1) # 做人给网站留点余地
for n in range(0, 60, 12):
pear_video(n)
openpyxl模块
1.excel 文件后缀名根据版本不同后缀名有区别
03版本之前:.xls
03版本之后:.xlsx
2.在python能够操作excel表格的模块有很多
openpyxl模块
最近几年比较流行的模块
该模块可以操作03版本的之后的文件
针对03版本之前的兼容性可能不太好
xlrd、wlwt模块
xlrd控制读文件 wlwt控制写文件
该模块可以操作任何版本的excel文件
3.装逼冷知识: excel的本质并不是一个文件
其本质更接近一个网站
可以通过把excel文件的后缀名改成.zip一个压缩文件后再点开观察
4.了解完这些就可以麻溜的装模块了
pip3 install openpyxl
openpyxl创建文件
from openpyxl更多方法 import Workbook
# 1.创建一个对象
wb = Workbook()
# 2.保存文件
wb.save(r'刚刚创建的excel文件.xlsx')
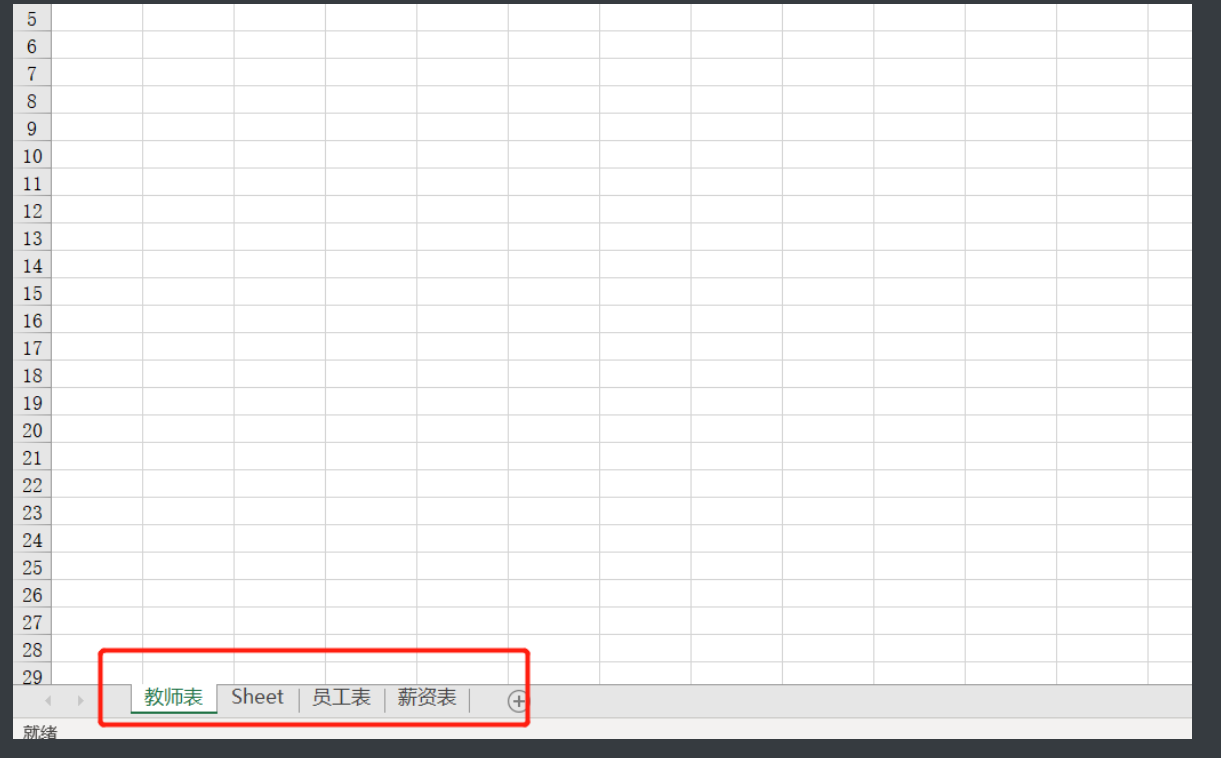
# 3.创建多个工作簿
wb.create_sheet(r'员工表')
wb.create_sheet(r'薪资表')
# 4.还可以指定工作簿发位置
w3 = wb.create_sheet(r'老师表', 0) # 放最前面
# 5.w3这个返回值就代表你生成的工作簿了 自然可以进一步操作
w3.title = '教师表' # 比如改名字
print(wb.sheetnames) # 查看工作簿名称
w3.sheet_properties.tabColor = "1072BA" # 还有花里胡哨的修改工作簿名称样式
wb.save(r'练习1.xlsx') # 最后一定要保存
openpyxl写数据
from openpyxl import Workbook
wb = Workbook() # 还是想之前一样先打开文件
wb1 = wb.create_sheet('员工表', 0) # 做一个表出来
# 6.如何写数据
# 方法1
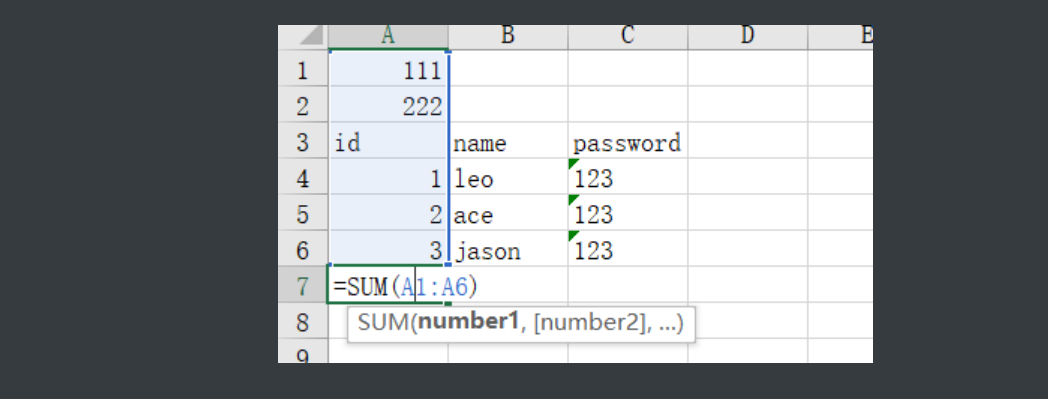
wb1['A1'] = 111 # 直接指定坐标写入
# 方法2
wb1.cell(column=1, row=2, value=222) # 根据行和列指定插入
# 方法3
wb1.append(['id', 'name', 'password'])
# 有时候如果没有输入要给一个空数据 不然格式会乱
wb1.append([1, 'leo', '123'])
wb1.append([2, 'ace', '123'])
wb1.append([3, 'jason', '123']) # 按行录入数据
# 计算公式怎么写
wb1['A7'] = '=sum(A1:A6)' # 后面公式就和excel里面一样
wb.save(r'练习2.xlsx') # 别忘了最后保存
openpyxl读数据
from openpyxl import load_workbook
# 1.指定要读取的表格文件
# wb = load_workbook(r'练习2.xlsx')
wb = load_workbook(r'练习2.xlsx', data_only=True)
# 2.一般这里都要娄一眼工作簿名称方便操作
print(wb.sheetnames) # ['员工表', 'Sheet']
# 然后要找到你要进行操作的哪个工作簿
wb1 = wb['员工表'] # 从现在以后wb1就指代员工表工作簿了
# 数据读取方法1
print(wb1['A1'].value) # 获取普通数据
print(wb1['A7'].value) # 获取公式如果不进行操作获取到的是公式是什么
'''
要获得公式结果得在表格读取的时候加一个参数
wb = load_workbook(r'练习2.xlsx', data_only=True)
'''
# 数据读取方法2
print(wb1.cell(row=2, column=1).value) # 也就是通过指定位置读取
# 数据读取方法3
print(wb1.rows) # 读取整行信息结果是个迭代器
for row in wb1.rows:
print(row) # (<Cell '员工表'.A1>, <Cell '员工表'.B1>, <Cell '员工表'.C1>)
# 前面得到的是每行数据的单元格列表
for r in row: # 取出里面的一个个单元格数据
print(r.value) # 然后再用value读具体值
# 下面按列读取也是同理
for col in wb1.columns:
for c in col:
print(c.value)
# 获取最大的行数和列数
print(wb1.max_row) # 7
print(wb1.max_column) # 3
openpyxl结合网络爬虫
豆瓣案例top250案例
import requests
import re
import time
from bs4 import BeautifulSoup
from openpyxl import Workbook
'''
万变不离其宗第一步总归是观察网页 从第一页开始先不要想分页就先爬一页
1.看第一页的数据加载方式
2.是直接加载的那就可以直接下手爬网站了
'''
wb = Workbook() # 打开表格
wb1 = wb.create_sheet('豆瓣表格', 0) # 定义好工作簿
wb1.append(['电影名', '导演', '主演', '评分', '评价人数', '短评']) # 插入表头
def movie_rank(n):
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'}
res = requests.get(url,
headers=headers,
params={'start': n}) # 通过n控制页数
net = res.text # 转文本方便解析
soup = BeautifulSoup(net, 'lxml')
title_list = re.findall('<img width="100" alt="(.*?)" src=', net) # 正则爬电影名
direct_list = re.findall('导演: (.*?) ', net) # 正则爬导演
actor_list = re.findall(' 主演: (.*?) /...', net) # 正则爬主演
score_list = re.findall('property="v:average">(.*?)</span>', net) # 正则爬评分
comment_count_list = re.findall('<span>(.*?)人评价</span>', net) # 正则爬短评
li_list = soup.select('ol.grid_view>li') # 拿到短评所在标签外部li标签的列表缩小范围方便进一步操作
inq_list = [] # 定义空列表方便之后加
for li in li_list: # 取出一个个元素
li = str(li) # 把网页上的没有属性的东西转成字符串
if '<span class="inq">' in li: # 字符串包含运算
inq_part = re.findall('<span class="inq">(.*?)</span>', li) # 有就可以正则拿到短评
inq_list.append(inq_part[0]) # 拿到后取出元素写入
else:
inq_part = '暂无短评' # 没有自己加一个字段
inq_list.append(inq_part) # 也写入列表
full_info = zip(title_list, direct_list, actor_list, score_list, comment_count_list, inq_list) # 整合成一起
for i in full_info: # 拿出里面的组合
wb1.append(list(i)) # 转成列表写入
time.sleep(10) # 吸取被封ip的教训停久点
for n in (0, 225, 25): # 翻页规律控制
movie_rank(n) # 把实参给函数
wb.save(r'豆瓣top250.xlsx') # 别忘了最后保存


