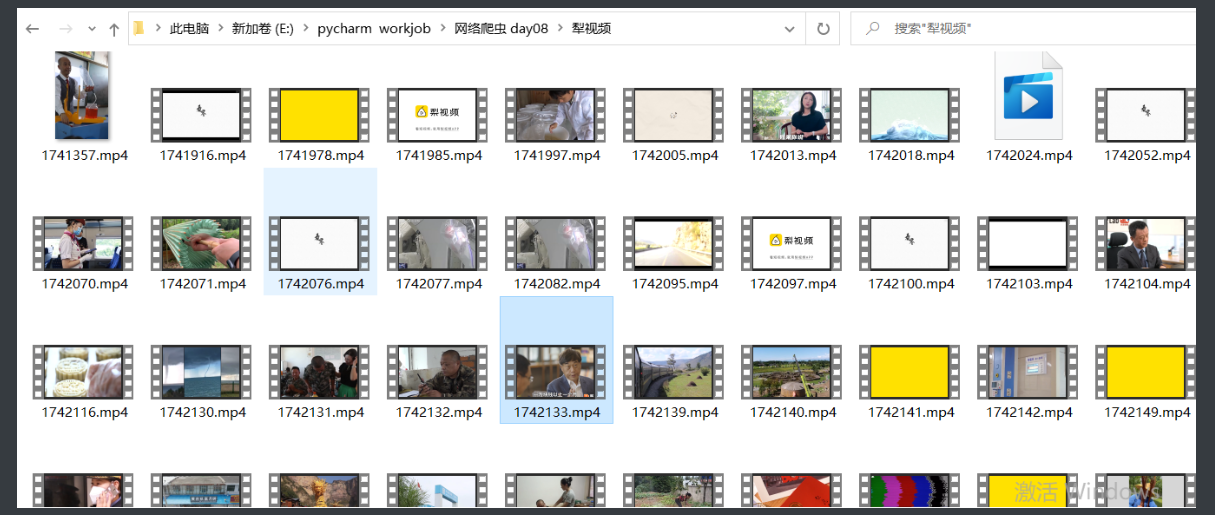
爬犁视频
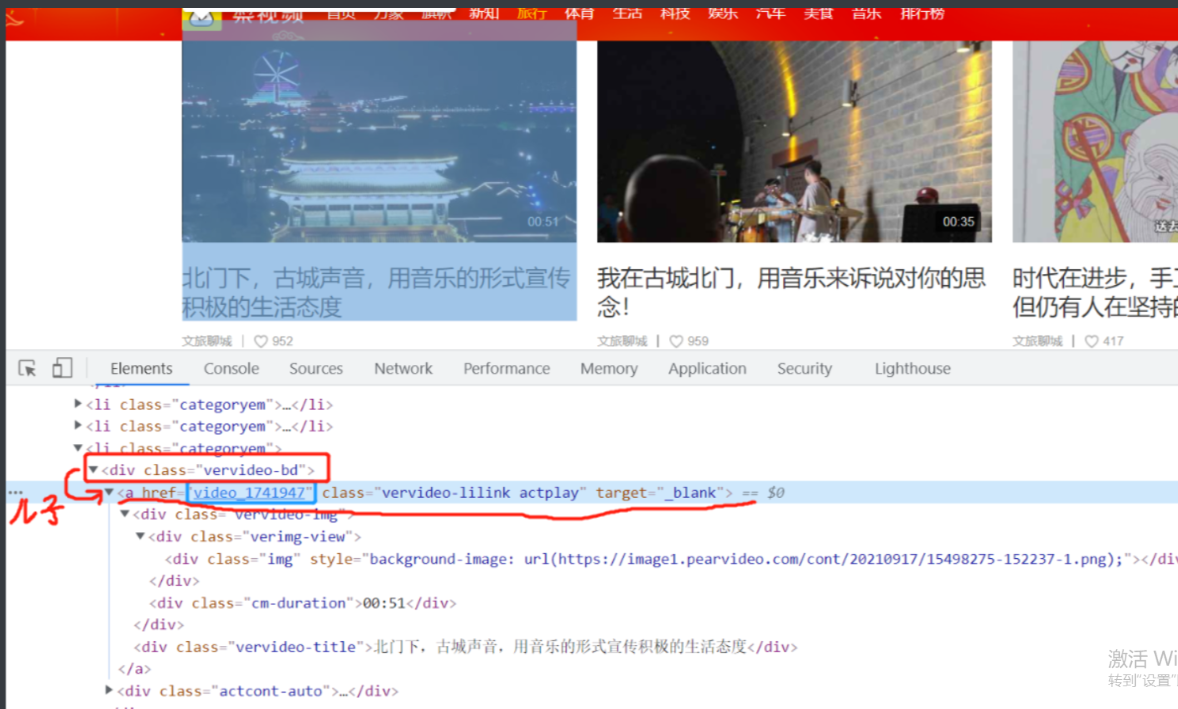
1.首先还是先分析所需的网站看到我们需要点进的链接如何加载
2.发现这个部分是直接写在网站上的那就简单了,可以通过你喜欢的方法找到所需标签
3.然后再分析a标签规律尝试取到其中的链接
4.进一步检查他的转跳窗口地址并没有给全那就手动加上前面部分
import requests
from bs4 import BeautifulSoup
base_url = 'https://www.pearvideo.com/' # 实际网页是拼接而成的所以把前半部分先放好
res = requests.get('https://www.pearvideo.com/category_130') # 先向这个网页发送请求
res.encoding = 'utf-8' # 设置编码好习惯
soup = BeautifulSoup(res.text, 'lxml') # 解析
a_tag_list = soup.select('div.vervideo-bd>a') # css选择器找得到这类div的儿子a
for a in a_tag_list: # 取出a
url_2nd = a.attrs.get('href') # 拿到href后面的链接
url = base_url + url_2nd # 拼接起来就能进入下一个网站
# 这时候已经拿到进入下一个网站的地址
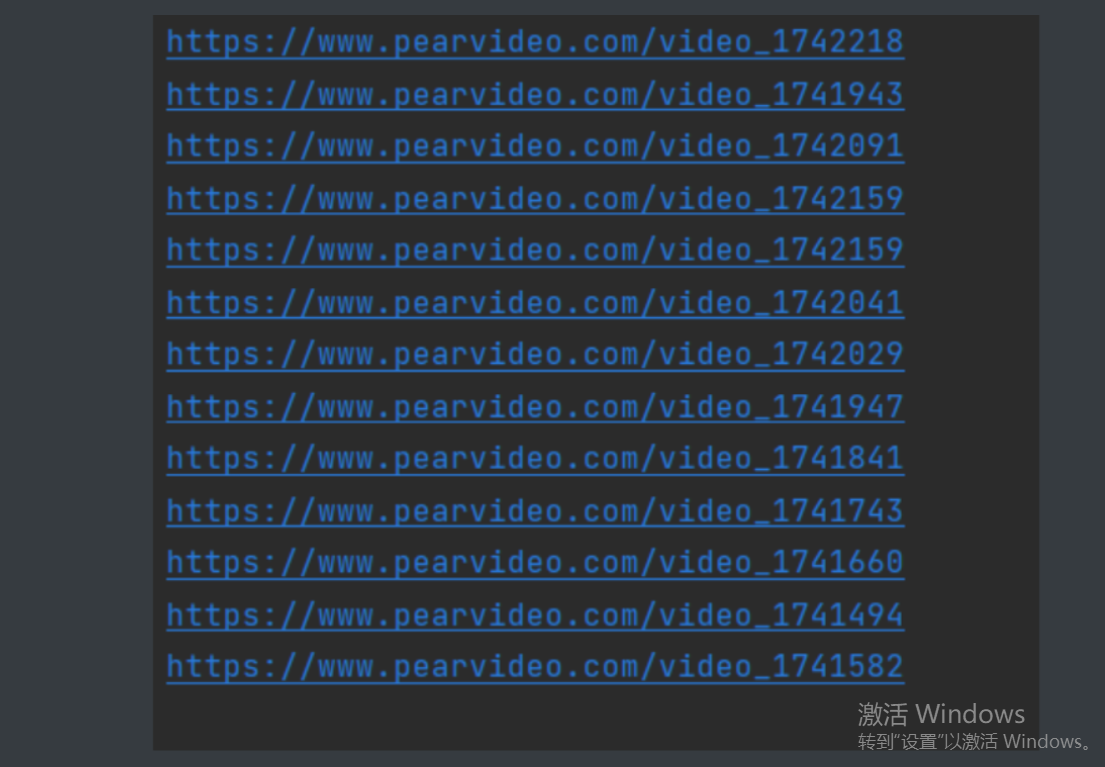
1.与先前一样分析加载方式发现 坏了这个视频页面源码找不到
2.赶紧fetch看看 确认了是动态加载的
3.动态加载的时候向这个网站发的请求
https://www.pearvideo.com/videoStatus.jsp?contId=1742218&mrd=0.5511860380506843
4.但是我直接点进去打不开啊
5.明明是往这个网页发送的请求我用浏览器请求怎么打不开呢
刚才遇上的情况就是这个防爬措施造成的
简单来说就是
'''
我会检查一下是哪里向我发送请求
一定得是要我许可的网站请求我才会返回数据给他
记录从何而来的键叫做referer
那破解办法也就不言而喻
即书写请求头的时候带上这个referer键就行
'''
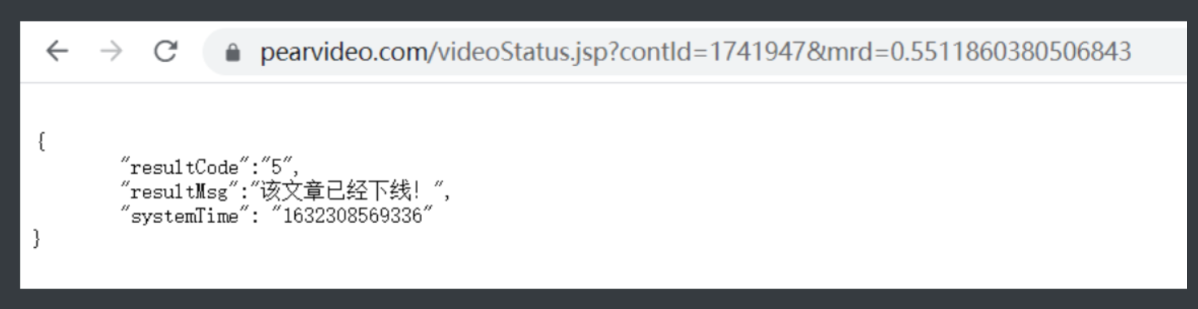
1.知道这边被防爬也没事那我可以看看这个请求到底请求的是什么东西
如果请求的不是视频对我来说也没有用
2.点开response看到返回的其实是一堆键值对数据那说明真正的视频网站另在别处
3.不过这个返回数据中有个看起来很有用到东西比较是MP4
结尾
大胆猜测和视频有关将其取出备用 https://video.pearvideo.com/mp4/third/20210922/1632319265938-15498275-115401-hd.mp4

1.刚才找到了一个非常有可能有用的网站那自然还要想办法通过代码请求到这个网址
2.通过向www.pearvideo.com/videoStatus.jsp发送get请求再携带参数就可以达到网页动态加载请求的效果了
3.而参数恰好是之前拼接网址时候用的视频id
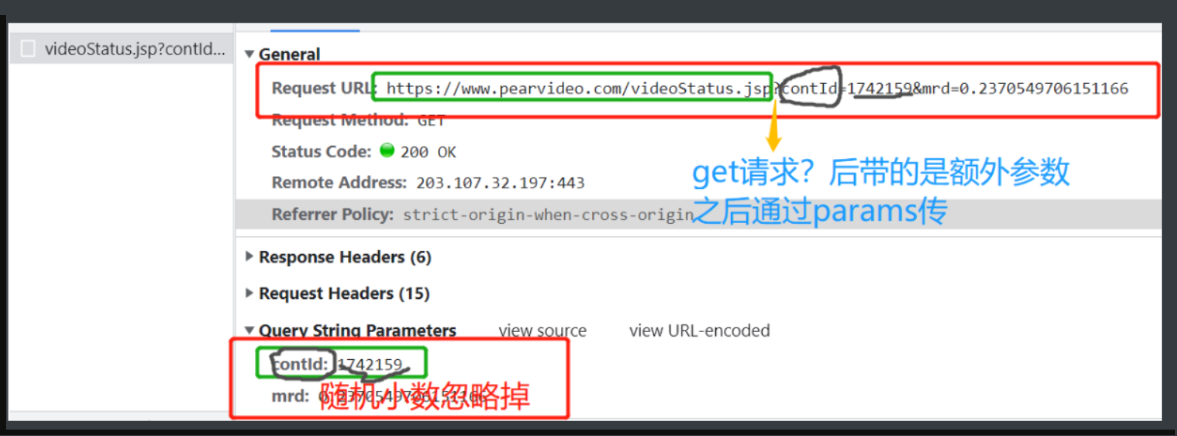
1.经过刚刚那些分析 动态请求里返回出来的网址会不会就是视频网址呢
2.是不是为了防爬才特地做了乱七八糟的字典伪装起来呢
3.那就把那个网址复制打开看看
4.结果是404请求资源不存在
5.这时候甚至设想这个404是网页的展示效果实际是被别的防爬措施阻止了
6.经过检查网页后发现地址的确是没能获取到资源
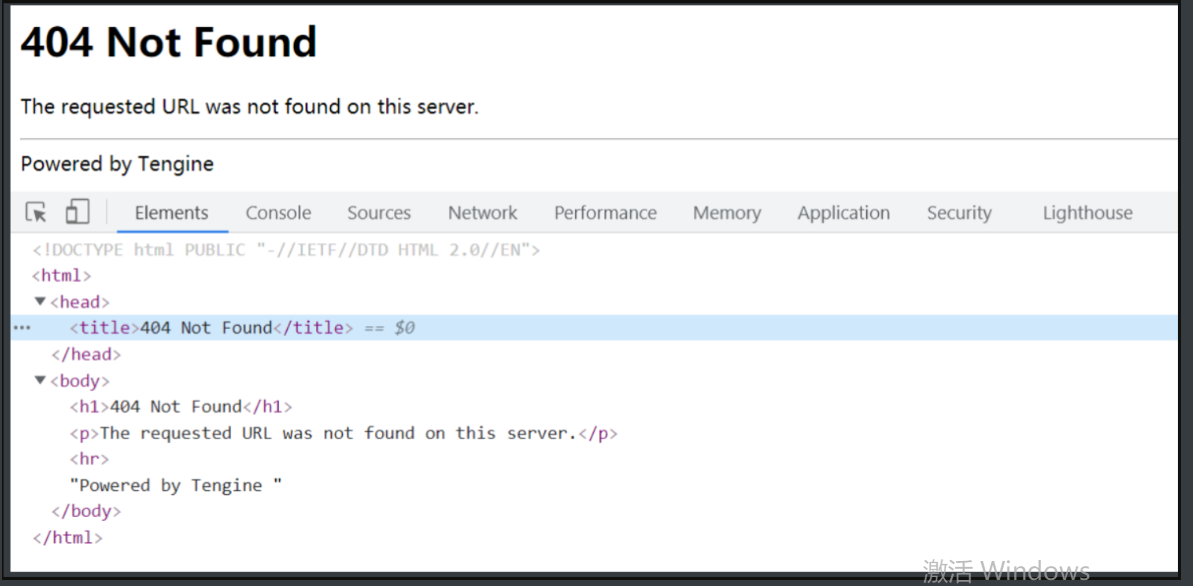
1.现在我们手头所有的线索都断了 没有一个可以与视频的真实地址有关联
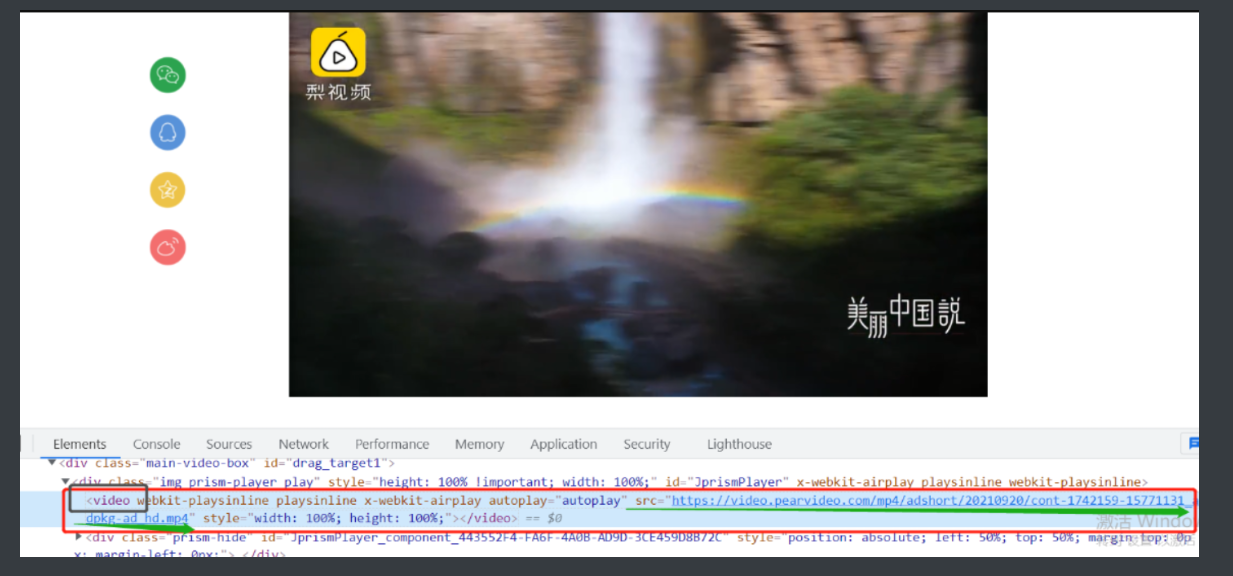
2.那只能另辟蹊径 去elements里面看一下
3.可算是找到了对应的网址
拿出来记录一下 https://video.pearvideo.com/mp4/third/20210922/cont-1742218-15498275-115401-hd.mp4
1.可是这只是在elements里面找到的实际是动态加载的
2.怎么想办法弄到这个网址就变成了现在的关键
3.整理一下现在手头有点网址和信息放在一起观察一下
首先是a标签里的不完整链接
video_1742218
动态加载时候请求的网址返回的链接
https://video.pearvideo.com/mp4/third/20210922/1632319265938-15498275-115401-hd.mp4
真实视频所在地址
https://video.pearvideo.com/mp4/third/20210922/cont-1742218-15498275-115401-hd.mp4
对其比对后不难发现只要将一部分字符替换成cont-一串video后面的数字就可以拿到最终目标了

1.现在最后的问题就是那串长长的数字要找到来头精确获取到才能替换呀
2.冷静下来捋捋思路 有什么地方可能会有这个数据
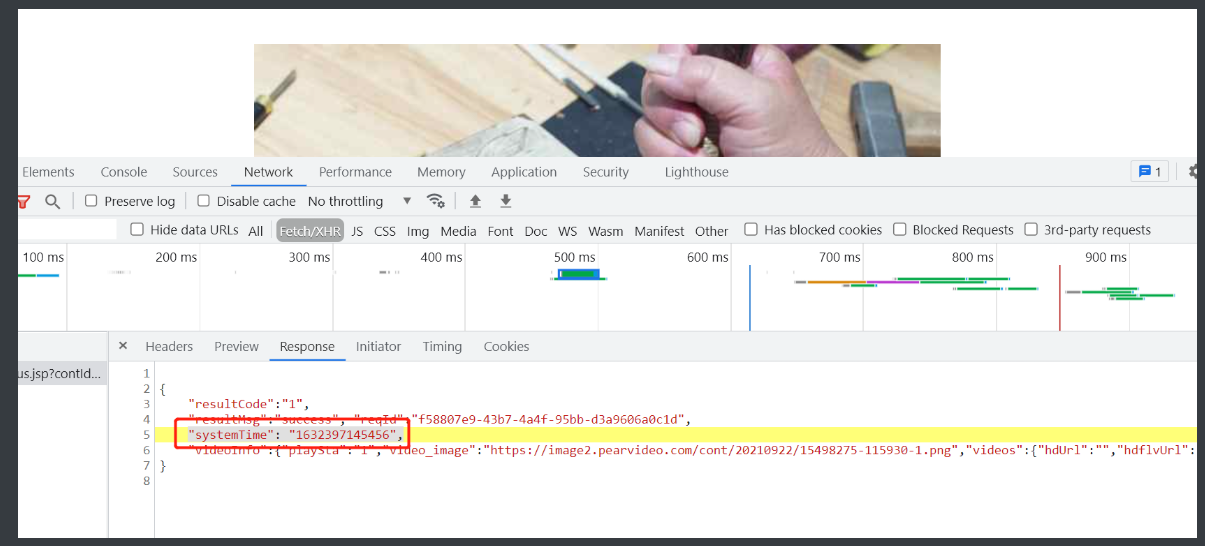
3.既然最接近答案的网址是在动态加载的网页在response回复出来的
那有没有可能玄机也藏在那一大堆键值对里呢
4.果然找到了 里面systemTime对应的就是这个数字
"systemTime": "1632397145456"
1.既然知道了需要替换的字符和要替换成什么网站就自然能够拼接了
2.最后发送请求再将返回数据以二进制保存就告一段落
3.现在就可以来分析分页问题了
4.页面别的数据一开始没有加载出来而是要滚到最下面再加载的
5.那肯定得有动态加载喽去fetch里面看看
6.一看果然啊就是动态加载后面参数还挺多但是不关键先不管
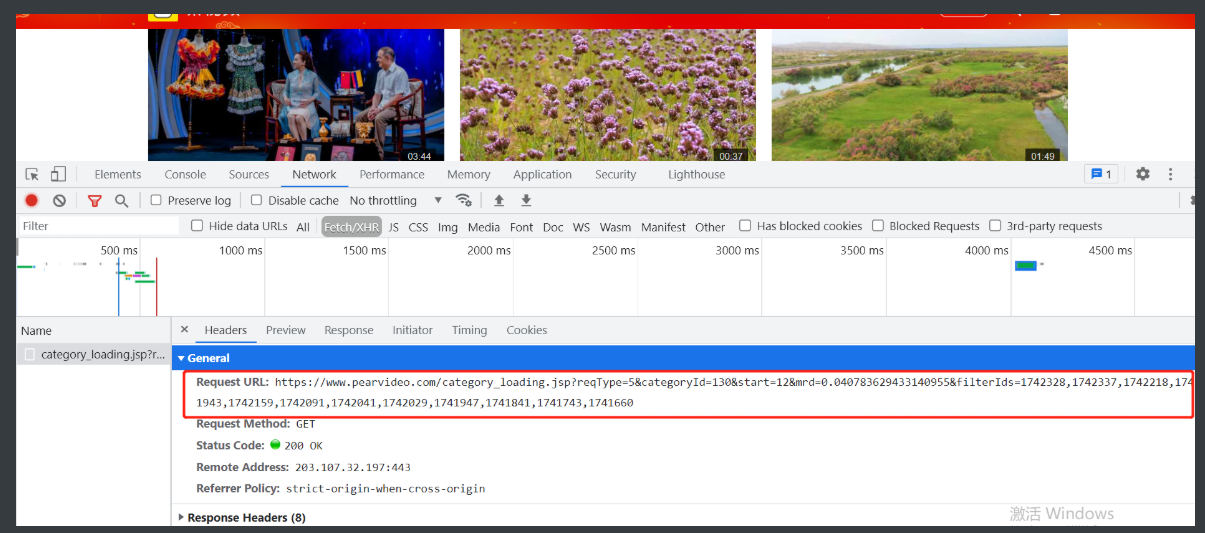
1.动态加载请求的网址一眼就将后面随机数和视频id去掉再请求一次
2.请求成功并且返回一个简陋的页面不过功能还是很全的

1.经过之前的分析我们知道第一层网站只要拿到video后面的id号就行了
2.所以分页不影响爬取
3.大胆猜测分页规律就是这个start参数控制并且每12个一分
4.一般第一页比较特殊改成0试试

1.既然0没问题那页面规律也就找到了
2.一会儿写代码在params里面加入一个动态参数就行
3.高级一点可以把爬取做成函数动态参数设为一个函数
4.开始整代码
import requests
from bs4 import BeautifulSoup
import os
import time
if not os.path.exists(r'犁视频'): # 如果存储文件夹不存在
os.mkdir(r'犁视频') # 就创建一个
def pear_video(n):
# base_url = 'https://www.pearvideo.com/' # 实际网页是拼接而成的所以把前半部分先放好
res = requests.get('https://www.pearvideo.com/category_loading.jsp',
params={'reqType': 5,
'categoryId': 10,
'start': n}) # 先向这个网页发送请求
res.encoding = 'utf-8' # 设置编码好习惯
soup = BeautifulSoup(res.text, 'lxml') # 解析
a_tag_list = soup.select('div.vervideo-bd>a') # css选择器找得到这类div的儿子a
for a in a_tag_list: # 取出a
url_2nd = a.attrs.get('href') # 拿到href后面的链接
# url = base_url + url_2nd # 拼接起来就能进入下一个网站
# print(url_2nd) # video_1742218
headers = {'Referer': 'https://www.pearvideo.com/%s' % url_2nd} # 先定义好防爬的请求头
cont_id = url_2nd.split('_')[-1] # 分割取到所需字符
res1 = requests.get('https://www.pearvideo.com/videoStatus.jsp',
headers=headers,
params={'contId': cont_id}) # 向动态加载内部网页发送请求
almost_url = res1.json().get('videoInfo')['videos']['srcUrl'] # 通过字典取值拿到返回的网址数据 两种取值方法都试试
sys_time = res1.json()['systemTime'] # 拿到得到网址中想要替换掉的字符串
# 这样搞定了前面还鱼龙混杂的问题 现在只需要专心解决后面的那串数字怎么替换即可
'''
得到网址
https://video.pearvideo.com/mp4/third/20210922/1632319265938-15498275-115401-hd.mp4
最终目标
https://video.pearvideo.com/mp4/third/20210922/cont-1742218-15498275-115401-hd.mp4
替换之后
https://video.pearvideo.com/mp4/third/20210922/cont-1742218-15498275-115401-hd.mp4
'''
# 在网页的response里出现过这个数字 是系统时间
final_url = almost_url.replace(sys_time, 'cont-%s' % cont_id) # 通过字符串替换得到最终网址
# print(final_url)
# break
res2 = requests.get(final_url) # 发送请求
name = cont_id + '.mp4' # 给文件名加上后缀
media_add = os.path.join(r'犁视频', name) # 拼接文件路径
with open(media_add, 'wb') as f: # 以二进制写模式打开
f.write(res2.content) # 直接二进制写入
print('%s下好啦' % name) # 加个完成提示
time.sleep(1) # 做人给网站留点余地
for n in range(0, 60, 12):
pear_video(n)