
9/22
今日考题
1.用于数据解析的技术有哪些,各自有何主要特征
python标准库
优点 容错率高 直接内置
缺点 对于python2.7和3.3前不好用
lxml HTML解析器
优点 速度快 容错强
缺点 要装C语言库
lxml XML解析器
优点 唯一支持XML的一款
缺点 要装C语言库
html5lib解析器
优点 容错无敌
缺点 速度慢
2.详细描述红牛分公司数据爬取流程
1.首先找到想要爬取的网站
2.然后分析所需信息
3.将所需信息和网页源码比对
4.数据直接做在网页上的那就直接通过requests模块向网页提出请求
5.获取到所有数据后观察数据想办法就获取到我们所需的具体文本
6.找出规律后通过re模块正则 或者是 bs4的BeautifulSoup获取到标签所需要的数据
7.将获取的数据通过循环取值一一有序取出整理在一起即可
3.详细描述北京新发地蔬菜价格表爬取流程
1.首先找到数据所在网页查看所需数据与网页源码比对
2.发现没有那数据就是动态加载的
3.打开network中fetch重新进入网页观察
4.看到是有一个请求向另一个网页提交
5.查看这个请求的response验证是否能获取数据
6.验证想法后观察post请求的请求体尝试找出其中规律
7.通过requests模块向网页发送带有请求体的post请求获取返回的数据
8.由于基于网络传输的数据大都为json格式 观察后将其反序列化
9.随后通过数据类型的操作方法简单筛选所需数据
10.整理后展示
复习巩固
- 爬取北京新发地蔬菜信息
1.数据加载方式
2.分页展示数据寻找规律
3.多页爬取设置时间间隔
- 爬虫解析库bs4模块
帮助我们去html或者xml文档中筛选出特定数据
模块下载
pip3 install beautifulSoup4
pip3 install lxml
常用功能
find()
name 标签名
attrs 字典的形式表示所有的标签属性
findall()
select()
"""
css选择器
.c1 查找class=c1的标签
#d1 查找id=d1的标签
div>span 查找div内部所有的儿子span
#d1 .c1 查找id=d1内部所有class=c1的后代标签
"""
- 爬取红牛分公司数据
1.页面数据直接加载
2.那直接整个网页爬下来bs4读取
2.用标签方法获取重要数据
4.组织数据(展示 存储)
组织数据可以用zip内置方法
将多个列表元素按循序一一对应像拉链一样啮合起来
内容概要
- 正则淦红牛
- 爬取糗图图片数据
- 爬取优美图库高清图片
- 爬取梨视频视频数据
- openpyxl模块
专门用于操作excel表格
也是很多操作excel模块的内部模块
详细讲解
正则解析红牛分公司数据
import requests
import re
res = requests.get('http://www.redbull.com.cn/about/branch')
info = res.text
name = re.findall("<h2>(.*?)</h2>", info) # 正则解析分公司名称
add = re.findall("<p class='mapIco'>(.*?)</p>", info) # 正则解析分公司地址
mail = re.findall("<p class='mailIco'>(.*?)</p>", info) # 正则解析分公司邮编
tele = re.findall("<p class='telIco'>(.*?)</p>", info) # 正则解析分公司电话
'''通过正则拿到标签里数据 结果是个列表 那刚刚好前面提了一嘴zip就可以用起来'''
# for i in range(len(name)): # 先还是拿for循环热热身
# print("""
# 名字:%s
# 地址:%s
# 邮编:%s
# 电话:%s
# """ % (name[i], add[i], mail[i], tele[i]))
full_info = zip(name, add, mail, tele) # 获得一个串联好的迭代器
# for i in full_info: # 可以通过for取值
# print(i)
print(list(full_info)) # 高端一点可以用内置方法list
'''list最后生成一个列表加元组的格式'''

爬糗图图片数据
1.首先确定爬取的图片数据已经直接出现在这个网站上了
https://www.qiushibaike.com/imgrank/
2.那接下来看加载方式检查源码之后看看图片链接有没有
3.结果是直接写在网页上的那就简单了通过正则或者是解析找到img标签
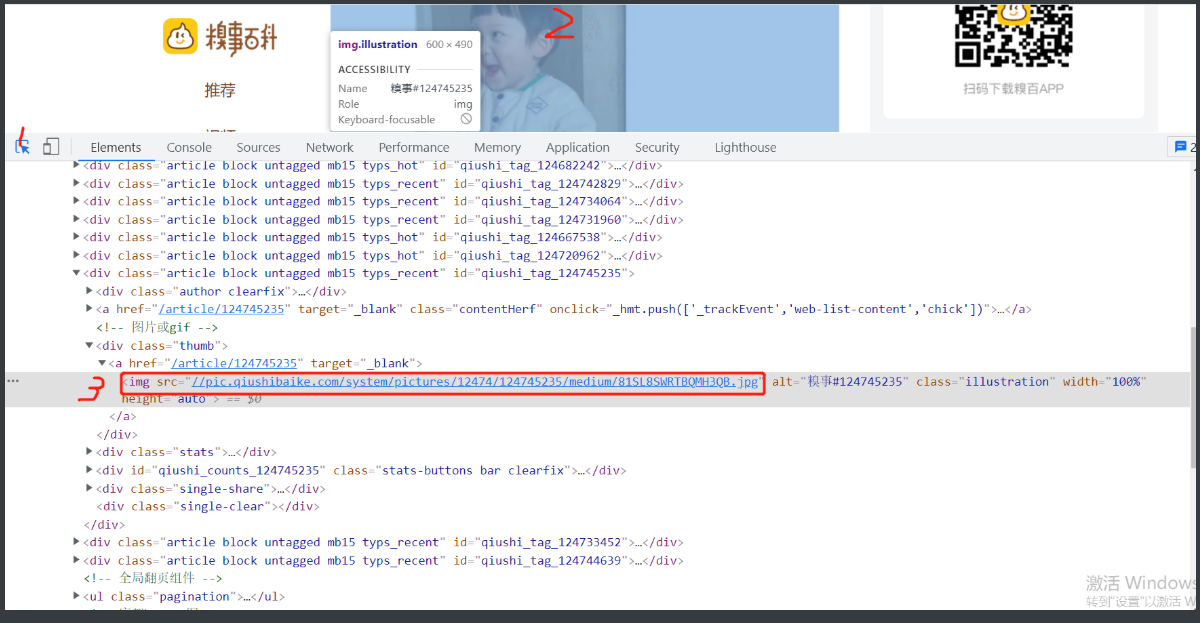
4.打开检查简单定位,寻找标签规律
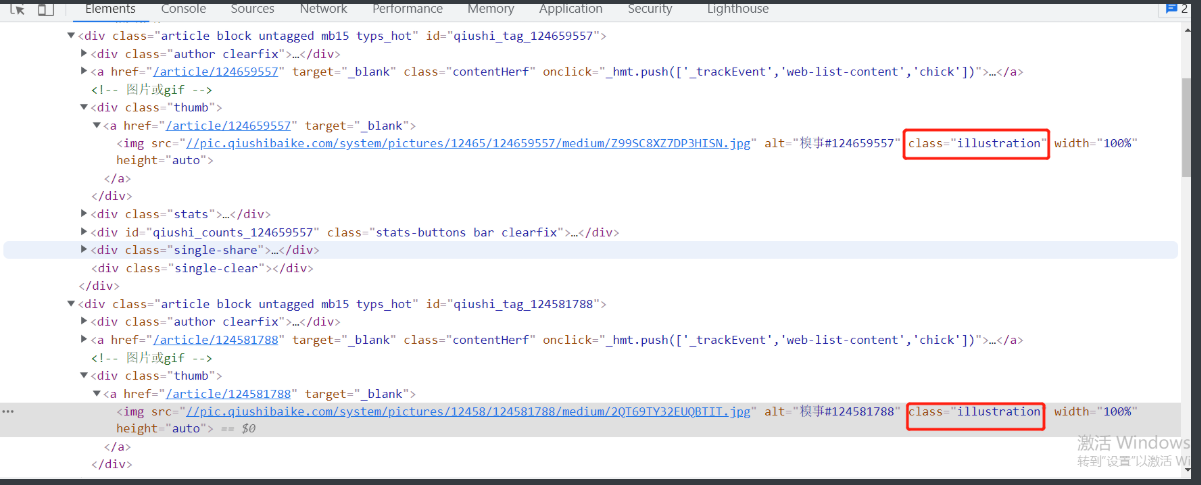
5.说来巧这个img都有个class标签里面似乎还一样
6.那不如大胆猜测这个就是糗图的分类
# 开始写代码
import requests
from bs4 import BeautifulSoup
import os
import time
if not os.path.exists(r'funny_pic'):
os.mkdir(r'funny_pic') # 先自动能创建文件夹
res = requests.get('https://www.qiushibaike.com/imgrank/',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'})
soup = BeautifulSoup(res.text, 'lxml') # 发送请求并解析
tag_img = soup.select('.illustration') # 找到图片标签前class分类名
# print(tag_img)
for i in tag_img: # 循环取值取出整个标签
img_add = i.attrs.get('src') # 获取图片标签链接到的网站
name = i.attrs.get('alt') # 随便再拿个断点的名字保存时做文件名
# print(name)
img = requests.get('https:' + img_add,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'})
img_data = img.content # 将获取图片网站返回的数据以二进制直接整理
pic_path = os.path.join(r'funny_pic', name) # 创建储存的文件路径
# print(pic_add)
with open(pic_path, 'wb') as f: # 通过二进制的方式打开
f.write(img_data)
time.sleep(1) # 缓解一下服务器压力
'''
这个筛选不同于红牛案例
用bs4比较方便
找到img标签里的链接就基本万事大吉了
'''
爬取优美图库
1.首先还是先分析网页 我们要的图片不在这个网站上但是通过这个网页上的图片进入
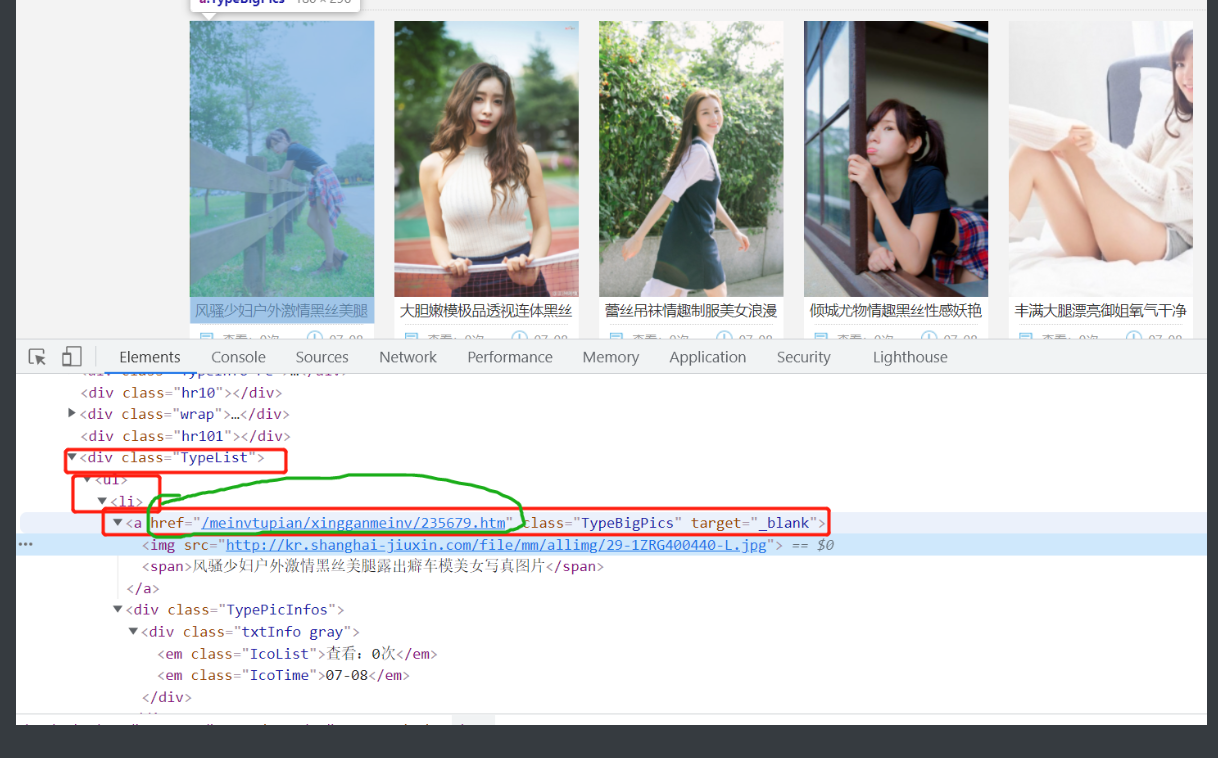
2.确认好图片是直接加载在网页上的 随后就是要去分析图片标签的规律
3.这次从最简单的思想方法开始 一步步定位到这个链接
import requests
from bs4 import BeautifulSoup
import os
import time
if not os.path.exists(r'图库'): # 判断如果存储的文件夹不存在
os.mkdir(r'图库') # 就创建一个
res = requests.get('https://www.umei.cc/meinvtupian/xingganmeinv/')
res.encoding = 'utf-8' # 由于之后要用bs4解析所以先规定好解码方式
soup = BeautifulSoup(res.text, 'lxml') # 解析一下
a_list = soup.select('div.TypeList li a') # 用css选择器一步到位直接把所有a标签拎出来
for i in a_list:
add = i.attrs.get('href') # 这时候就已经拿到了图片里的链接
url = 'https://www.umei.cc' + add # 通过字符串的拼接获得完整的地址
'''现在看着打开之后的网页再次分析图片怎么加载的
这个还是直接在网页加载的 那就直接向网页发送请求'''
res1 = requests.get(url)
res1.encoding = 'utf-8' # 统一字符编码好习惯
soup1 = BeautifulSoup(res1.text, 'lxml')
img_tag = soup1.select('div.ImageBody img') # css选择器找到所需图片标签
pic_name = soup1.select('div.ArticleTitle strong') # 搞个标题一会儿存数据用
title = pic_name[0].text + '.jpg' # 拼上后缀容易打开
for s in img_tag: # 拿出img标签
src = s.get('src') # 取出网址
res2 = requests.get(src) # 向最终网站发送请求
pic_path = os.path.join(r'图库', title) # 合成路径储存
with open(pic_path, 'wb') as f: # 用二进制写入储存
f.write(res2.content)
print('%s下载成功'% title) # 提示下好了不然看终端傻等
time.sleep(1) # 做个都道德的人给别人服务器歇一下
'''
代码看起来不多难点在于整个思维过程要连贯缜密
'''
爬犁视频
1.首先还是先分析所需的网站看到我们需要点进的链接直接做在网络上
2.进一步检查他的转跳窗口地址并没有给全那就手动加上前面部分
3.然后再分析a标签规律尝试取到其中的链接
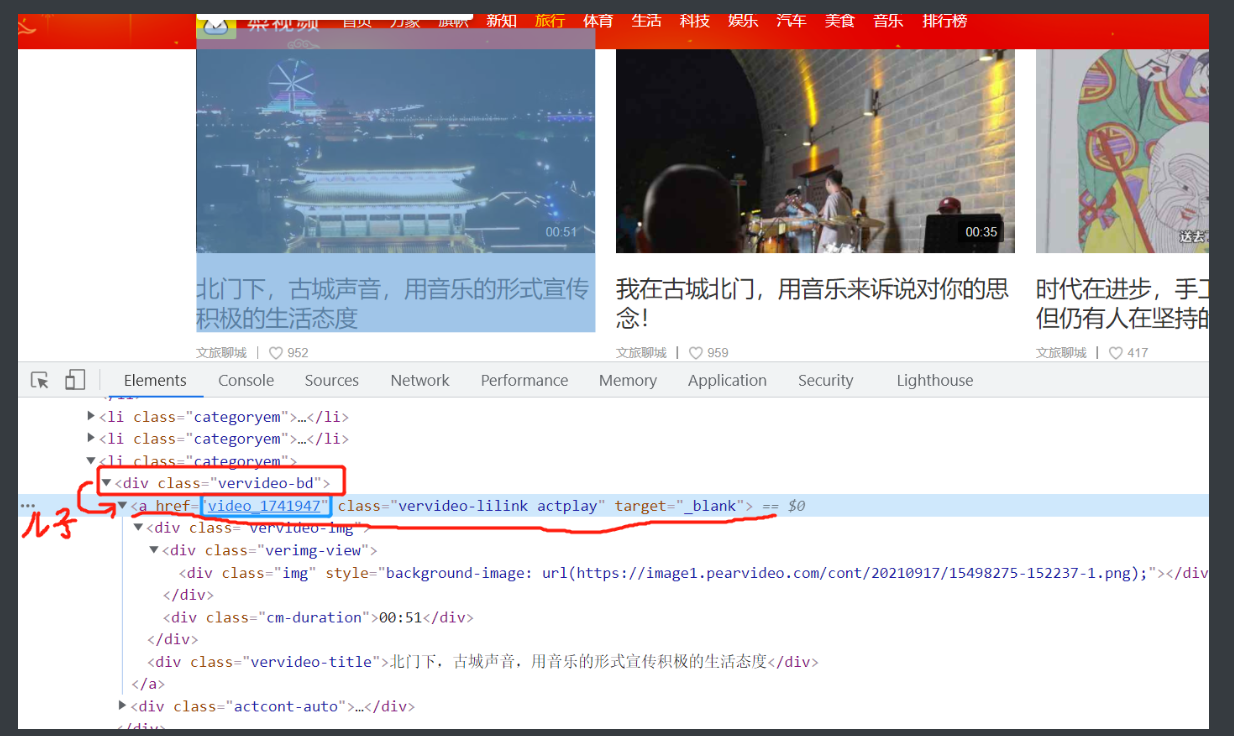
import requests
from bs4 import BeautifulSoup
import os
import time
if not os.path.exists(r'犁视频'): # 如果存储文件夹不存在
os.mkdir(r'犁视频') # 就创建一个
base_url = 'https://www.pearvideo.com/' # 实际网页是拼接而成的所以把前半部分先放好
res = requests.get('https://www.pearvideo.com/category_130') # 先向这个网页发送请求
res.encoding = 'utf-8' # 设置编码好习惯
soup = BeautifulSoup(res.text, 'lxml') # 解析
a_tag_list = soup.select('div.vervideo-bd>a') # css选择器找得到这类div的儿子a
for a in a_tag_list: # 取出a
url_2nd = a.attrs.get('href') # 拿到href后面的链接
url = base_url + url_2nd # 拼接起来就能进入下一个网站
# 这时候已经拿到进入下一个网站的地址
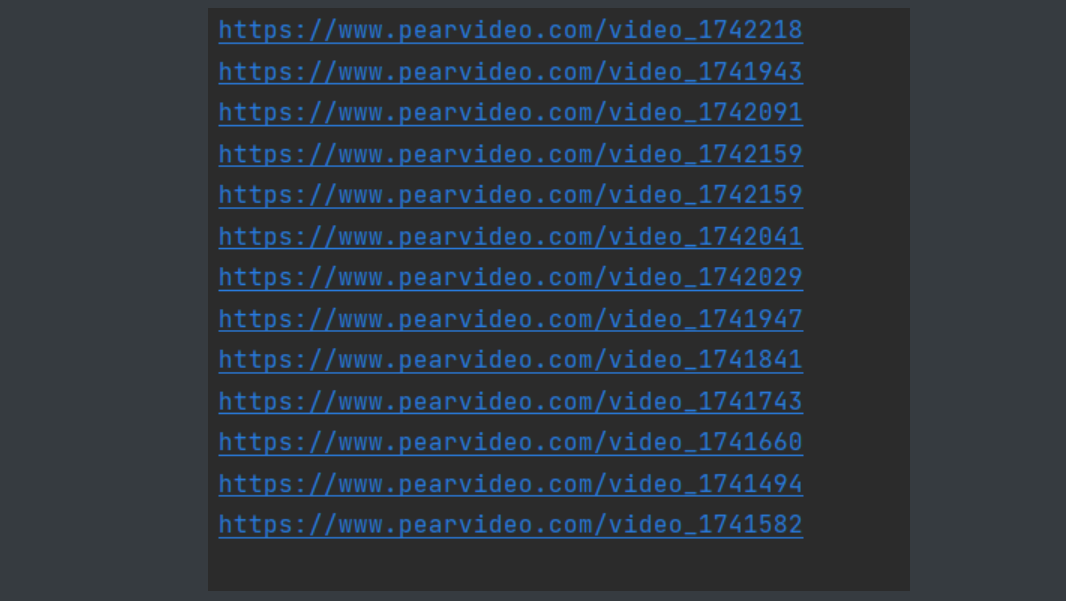
4.继续重复上述步骤发现 坏了这个视频是动态加载的
5.赶紧fetch看看怎么操作
6.向这个网站发的请求
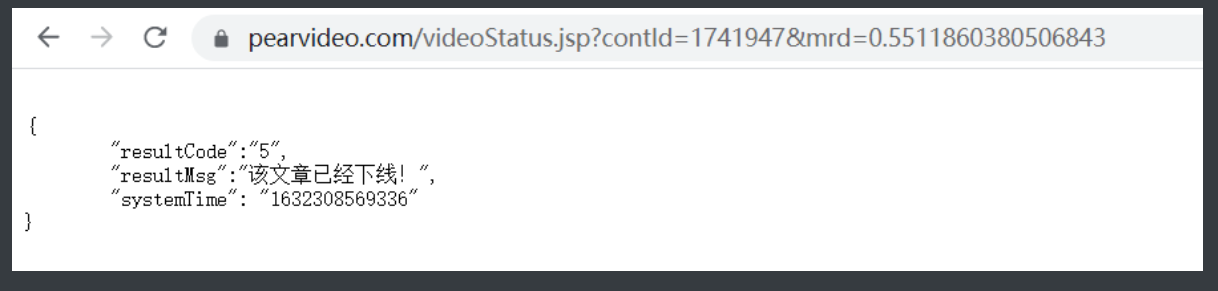
https://www.pearvideo.com/videoStatus.jsp?contId=1741947&mrd=0.5511860380506843
7.但是我直接点进去打不开啊
8.明明是往这个网页发送的请求我用浏览器请求怎么打不开呢
防爬之防盗链
刚才遇上的情况就是这个防爬措施造成的
简单来说就是我会检查一下是哪里向我发送请求
一定得是要我认可的网站请求我才会返回数据给他
那么记录从何而来的键叫做referer
破解办法也就不言而喻
再书写请求头的时候带上这个referer键就行
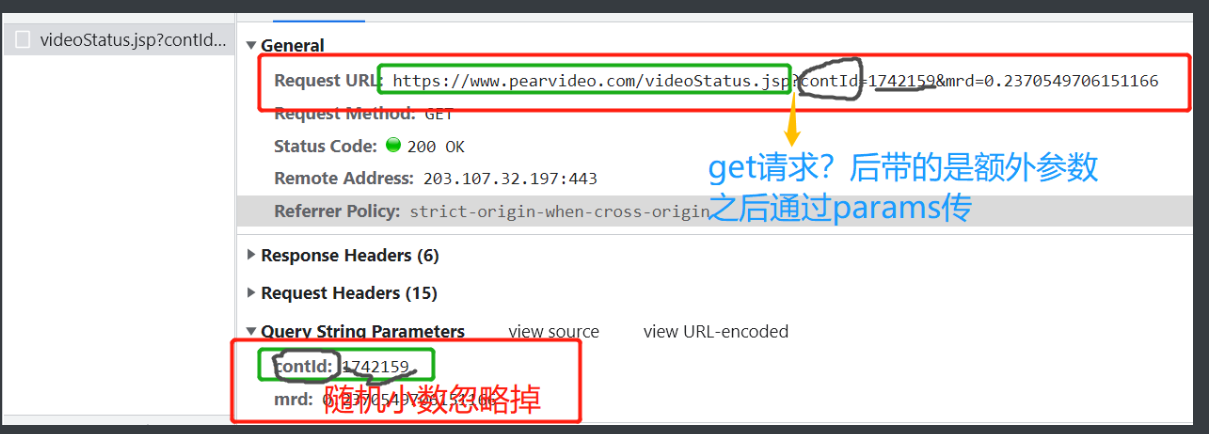
9.知道这个防爬也还不够啊还得继续观察
10.仔细观察前面两图中标注部分,向网站发送请求的但是返回出来的数据不是视频却是能动态加载出视频这没道理啊
11.只能再去fetch里面找找端倪

12.找到个https://video.pearvideo.com/mp4/adshort/20210920/1632316074600-15771131_adpkg-ad_hd.mp4
13.这可是MP4结尾总该有点反应把 复制访问试一下
好家伙直接404
14.一开始怕可能是防盗链措施特地伪装一个404但检查一下看来就是没有
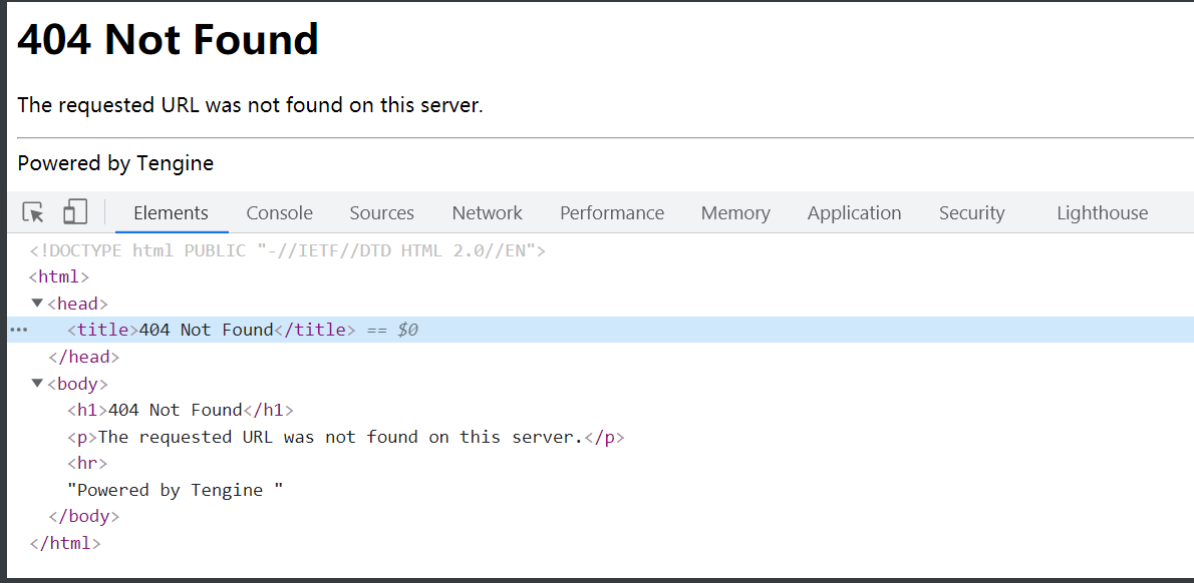
15.通过网页检查找到这个视频标签<video src="https://video.pearvideo.com/mp4/adshort/20210920/cont-1742159-15771131_adpkg-ad_hd.mp4" ></video>点进去确认了这是真实的视屏链接
https://video.pearvideo.com/mp4/adshort/20210920/cont-1742159-15771131_adpkg-ad_hd.mp4
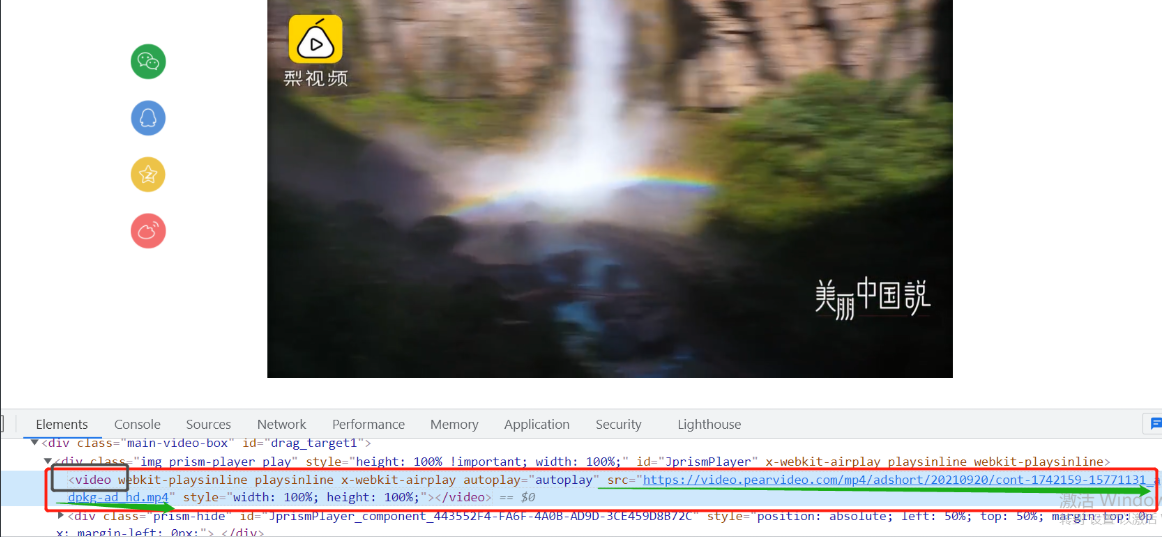
16.那把这个网址复制出来请求一下看来是没问题那最后就是要爬到这个网络的数据喽
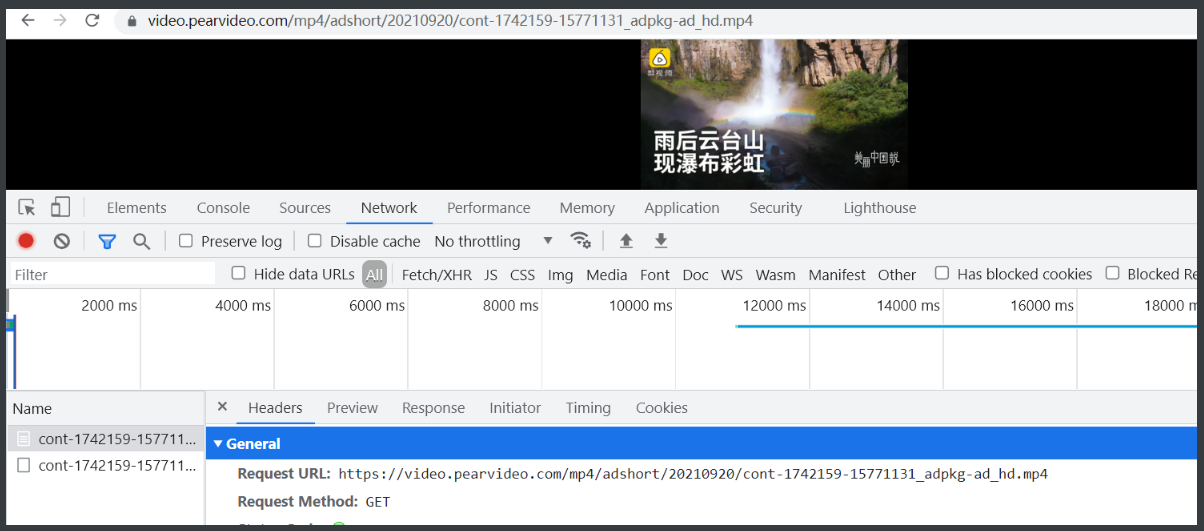
17.可是这个网站我也没办法通过解析页面拿到呀这个是动态加载的
18.整理一下手头现有的情报
最终目标网站:
https://video.pearvideo.com/mp4/adshort/20210920/cont-1742159-15771131_adpkg-ad_hd.mp4
动态加载请求网站:
https://www.pearvideo.com/videoStatus.jsp?contId=1741947&mrd=0.5511860380506843
请求返回的网站:
https://video.pearvideo.com/mp4/third/20210922/1632320019660-15498275-115401-hd.mp4
前面拿到的二段网址:
video_1742218
import requests
from bs4 import BeautifulSoup
import os
import time
if not os.path.exists(r'犁视频'): # 如果存储文件夹不存在
os.mkdir(r'犁视频') # 就创建一个
base_url = 'https://www.pearvideo.com/' # 实际网页是拼接而成的所以把前半部分先放好
res = requests.get('https://www.pearvideo.com/category_130') # 先向这个网页发送请求
res.encoding = 'utf-8' # 设置编码好习惯
soup = BeautifulSoup(res.text, 'lxml') # 解析
a_tag_list = soup.select('div.vervideo-bd>a') # css选择器找得到这类div的儿子a
for a in a_tag_list: # 取出a
url_2nd = a.attrs.get('href') # 拿到href后面的链接
# url = base_url + url_2nd # 拼接起来就能进入下一个网站
# print(url_2nd) # video_1742218
headers = {'Referer': 'https://www.pearvideo.com/%s' % url_2nd} # 先定义好防爬的请求头
cont_id = url_2nd.split('_')[-1] # 分割取到所需字符
res1 = requests.get('https://www.pearvideo.com/videoStatus.jsp',
headers=headers,
params={'contId': cont_id}) # 向动态加载内部网页发送请求
almost_url = res1.json().get('videoInfo')['videos']['srcUrl'] # 通过字典取值拿到返回的网址数据 两种取值方法都试试
sys_time = res1.json()['systemTime'] # 拿到得到网址中想要替换掉的字符串
# https://video.pearvideo.com/mp4/third/20210922/1632319782254-15498275-115401-hd.mp4
if 'third' in almost_url: # 用字符串成员运算判断网址是不是前面还有不同
almost_url = almost_url.replace('third', 'adshort') # 有不同就规划成一样的
# 这样搞定了前面还鱼龙混杂的问题 现在只需要专心解决后面的那串数字怎么替换即可
'''
得到网址
https://video.pearvideo.com/mp4/adshort/20210922/1632319265938-15498275-115401-hd.mp4
最终目标
https://video.pearvideo.com/mp4/adshort/20210920/cont-1742159-15771131_adpkg-ad_hd.mp4
https://video.pearvideo.com/mp4/adshort/20210922/cont-1742218-15498275-115401-hd.mp4
'''
# 在网页的response里出现过这个数字 是系统时间
final_url = almost_url.replace(sys_time, 'cont-%s' % cont_id) # 通过字符串替换得到最终网址
res2 = requests.get(final_url) # 发送请求
name = cont_id + '.mp4' # 给文件名加上后缀
media_add = os.path.join(r'犁视频', name) # 拼接文件路径
with open(media_add,'wb')as f: # 以二进制写模式打开
f.write(res2.content) # 直接二进制写入
print('%s下好啦'%name) # 加个完成提示
time.sleep(1) # 做人给网站留点余地
'''还有点小问题明天再解决'''

