
第六周内容回顾
本周主要内容就是爬虫
以例题来回顾复习知识点再合适不过
html常见标签
<a>链接标签</a>
<p>这行的文字内容</p>
<h1>一级标题</h1>
<u>下划线</u>
<s>删除线</s>
<i>我倒了</i>
<b>变粗!</b>
<img/图片连接> 插入图片
<hr> 水平线
<br> 换行符
<img src='图片标签'/>
<ul>
<li>这是</li>
<li>列表</li>
<li>标签</li>
</ul>
<!--下面是表格标签-->
<table>
<thead>
<tr>
<th>这里是</th>
<th>表头</th>
</tr>
</thead>
<!--下面是表格标签-->
<tbody>
<tr>
<td>这里是</td>
<td>表单部分</td>
</tr>
</tbody>
</table>
<!--表单标签-->
<form>
<input type=''> <!--获取用户输入 type控制类型-->
</form>
标签重要属性
有id属性 相当于标签的身份证
有class属性 相当于标签的分类
块级标签比如<div></div>里可以无限嵌套
正则表达式
字符组:
[0-9] # 匹配数字
[a-z] # 匹配小写英文字母
[0-9a-zA-Z] # 匹配数字和英文字母
符号:
. # 匹配任意字符一次
^ # 匹配开头
$ # 匹配结尾
\d # 匹配数字
a|b # 匹配a或b
[...] # 匹配中括号内字符
[^...] # 匹配除中括号内字符外全部字符
量词:
* # 重复0或多次
+ # 重复1或多次
? # 重复0或1次
{n} # 重复n次
{n,} # 重复n次或多次
{n,m} # 重复n次到m次
'''默认贪婪匹配 后面加?变成最短匹配'''
re模块
import re
res = re.findall('正则语句',待匹配文本) # 返回一个匹配到所有结果的列表
res1 = re.finditer('正则语句',待匹配文本) # 返回一个不占内存的迭代器
for i in res1:
print(i) # 只有主动索要才会产生数据
print(i.group())
res3 = re.search('正则语句',待匹配文本) # 匹配到一个符合条件的就结束
res4 = re.match('正则语句',待匹配文本) # 从头开始匹配 头部不符合就停
cookie
cookie: 浏览器记下访问网页时候的K:V键值对数据下次访问的时候直接用
eg: 记录用户名密码下次登陆就不用再输入
session: 浏览器在收到用户名密码后返回一段随机字符 这样就防止密码泄露
同时由于字符串要通过K:V键值对记录所以还是要通过cookie工作
requests模块和别的放入例题
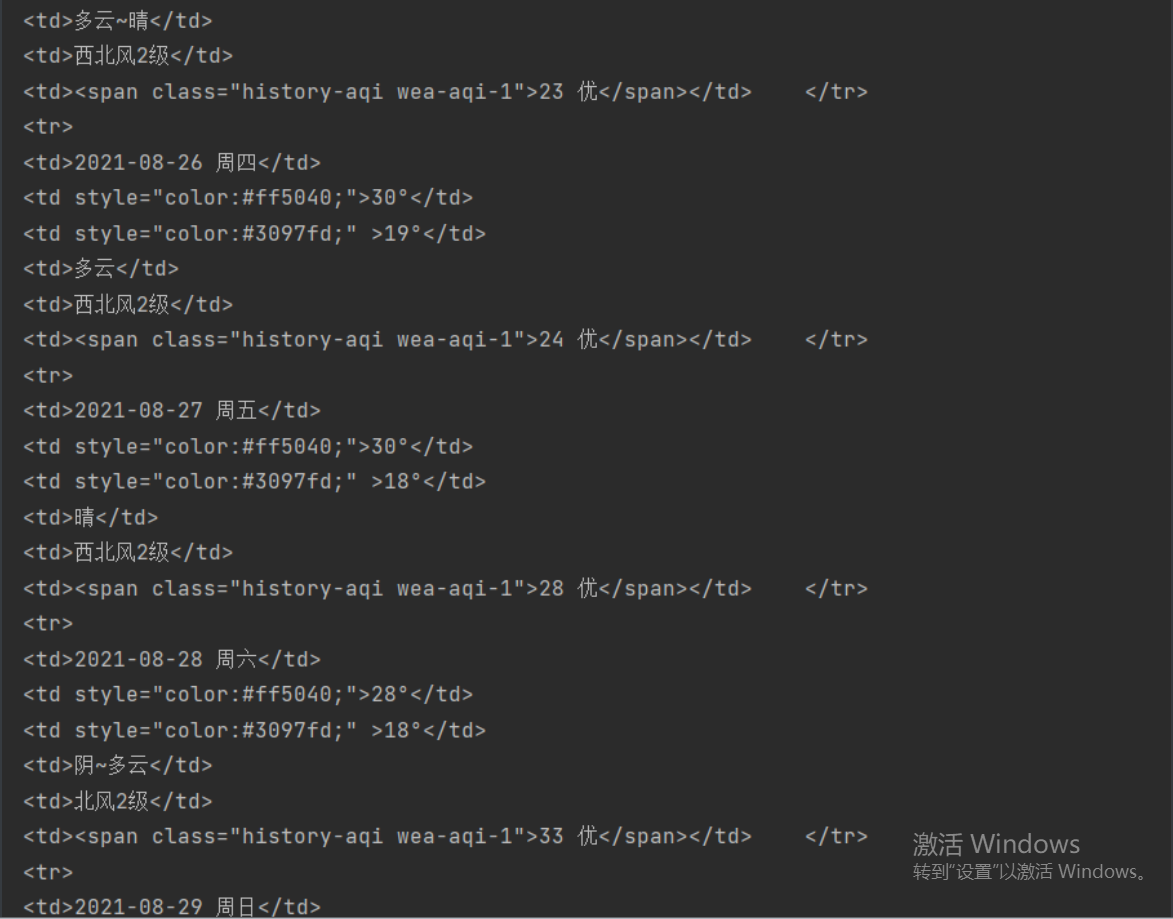
爬天气数据
import requests # 1.导入模块
import json
month_like = input('请输入查询天气的月份') # 找规律找到网站之间每月天气的规律
url = 'http://tianqi.2345.com/Pc/GetHistory?areaInfo%5BareaId%5D=54511&areaInfo%5BareaType%5D=2&date%5Byear%5D=2021&date%5Bmonth%5D='
url = url + month_like
res = requests.get(url)
weather = res.json()
print(weather.get('data'))
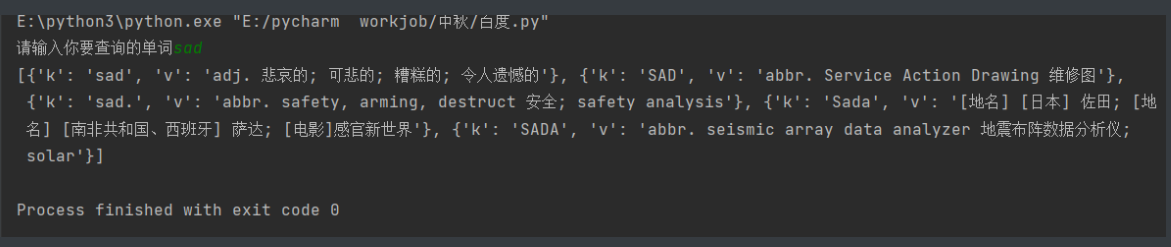
百度翻译
import requests
url = 'https://fanyi.baidu.com/sug'
word = input('请输入你要查询的单词')
res = requests.post(url,
data={'kw': word},
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'})
trans_list = res.json().get('data')
print(trans_list)
药品许可证
import requests
import json
import os
import time
if not os.path.exists(r'company_info'):
os.mkdir(r'company_info')
url1 = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
for p in range(1, 300):
res1 = requests.post(url1,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'},
data={
'on': 'true',
'page': p,
'pageSize': 15,
'productName': '',
'conditionType': 1,
'applyname': '',
'applysn': ''
}
)
company_list = res1.json().get('list')
for i in company_list:
id = i.get('ID')
url2 = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
res2 = requests.post(url2,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'},
data={'id': id}
)
company_detail = res2.json()
time.sleep(1)
name = company_detail.get('epsName')
info_add = os.path.join(r'company_info', name)
with open(info_add, 'w', encoding='utf8') as f:
json.dump(company_detail, f)
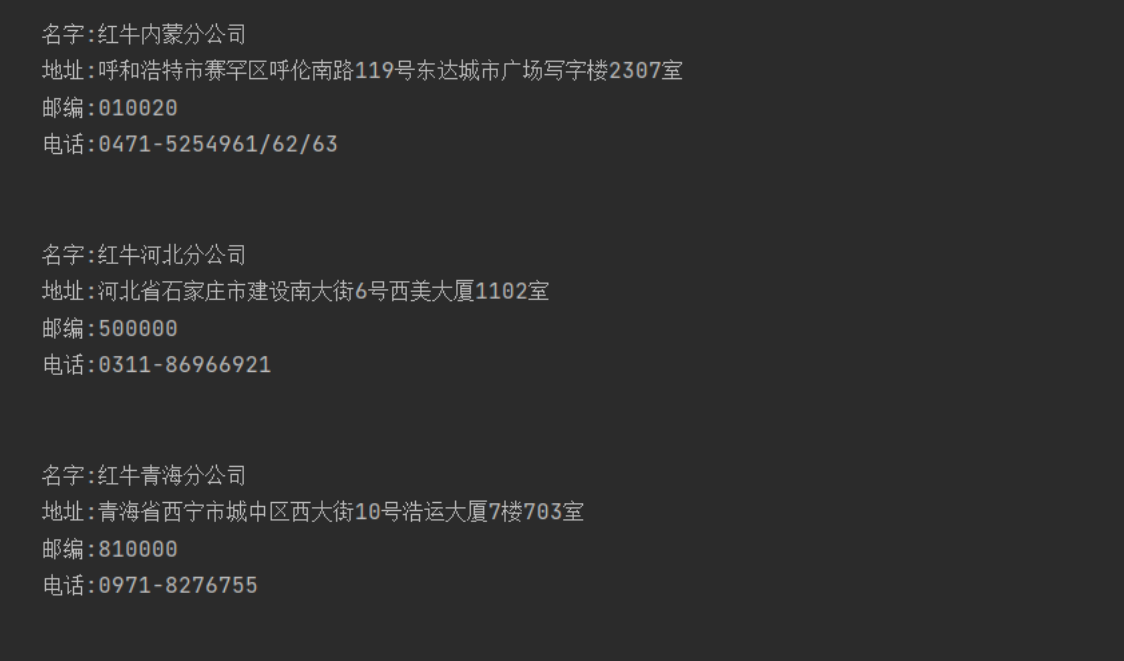
红牛正则解决
import requests
import re
res = requests.get('http://www.redbull.com.cn/about/branch')
info = res.text
name = re.findall("<h2>(.*?)</h2>", info)
add = re.findall("<p class='mapIco'>(.*?)</p>", info)
mail = re.findall("<p class='mailIco'>(.*?)</p>", info)
tele = re.findall("<p class='telIco'>(.*?)</p>", info)
'''通过正则拿到标签里数据'''
for i in range(len(name)):
print("""
名字:%s
地址:%s
邮编:%s
电话:%s
""" % (name[i], add[i], mail[i], tele[i]))
搞笑图片
import requests
from bs4 import BeautifulSoup
import os
import time
if not os.path.exists(r'funny_pic'):
os.mkdir(r'funny_pic')
res = requests.get('https://www.qiushibaike.com/imgrank/',
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'})
soup = BeautifulSoup(res.text, 'lxml')
tag_img = soup.select('.illustration')
# print(tag_img)
for i in tag_img:
img_add = i.attrs.get('src')
name = i.attrs.get('alt')
# print(name)
img = requests.get('https:' + img_add,
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36'})
img_data = img.content
pic_add = os.path.join(r'funny_pic', name)
# print(pic_add)
with open(pic_add, 'wb') as f:
f.write(img_data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号