9/18
今日考题
1.目前你所了解的网页加载数据特征有哪些
1.一种比较简单的将所有信息都写在网页上 向当前网页发送请求就能获取到全部数据
2.另一种是当前网站只加载一个框架别的数据都是通过后期动态加载的
需要通过network+fetch去查找发送请求的网站
2.详细描述昨日三个网站爬取数据详细步骤
# 天气网站
1.首先打开网站看第一页数据 雀食是写在当前网址的
2.点击翻页发现别的页数 数据变动但是网址并没有变
3.打开network查看怎么回事
4.点翻页后出现了一个post请求的数据交互
5.把response内容取出看一下 验证是否是这个天气数据
6.确认是的开始向查看请求体中页数对应的参数和规律
7.明白规律后用代码向网页发送请求 页数参数用for循环取值
# 百度翻译
1.一样用浏览器查看源码比对数据
2.翻译结果并不在网页源码中(要动态变化怎么可能直接做死)
3.network查看数据请求发生了什么
4.看到每输入一个字符会有3到5个请求向不同的网址发出
5.点response看返回的都是啥
6.看到是不同区域翻译或者是例句结果
7.拿出最使用的单词翻译sug找到网址
8.用代码模拟浏览器发送请求 请求体中让用户自行输入想要翻译的单词
# 药品
1.打开网站看源码 发现所要的公司链接信息不在上面
2.打开network重新加载网页 看到有一个偷偷摸摸的post请求
3.虽然八九不离十但还是复制response看一下返回结果
4.验证自己的想法后先将这部分爬下来
5.点进链接看到详情页
6.比对详情页信息和源码
7.又是没直接写在网页上这每个人进来的链接都不一样还要动态加载委实有些严谨不愧是政府网站
8.如法炮制找到交互的网站 同时多开几个看看是不是都是向这个网站发送请求
9.但是在请求体里面有个id数据好长一串 不知道是什么
10.那我们手头只有之前爬到的目录信息去比对
11.巧了里面还真有个id 比对一下还真对上了
12.循环取出之前爬取到的id放进第二个请求里面去
13.通过id爬取到所对应公司的详细信息
14.通过字典取值拿到想要的
15.随便自行保存
复习巩固
- 网页数据加载方式
1.发送请求能直接加载到页面
筛选数据的时候直接去页面筛选
2.核心数据由内部动态加载
研究一下内部动态请求 获取到数据来源再解析
- 爬取天气数据
历史天气数据完全来自于内部动态请求
network请求筛选
fetch/xhr选项找到问题本质
- 爬取百度翻译
有很多核心数据的获取可能内部发送的是post请求
通过控制请求体数据来表明索要核心数据的特征
- 爬取药品许可证
涉及到请求要两次 主要是有足够的耐心和清晰的思路
还要有发现规律的想法
- 分页与数据存储思路
分页其实就是通过参数或者网址上的一些有规律的变化实现的
爬取分页数据的时候就是要去留意这些规律
存储的方法各式各样
没有什么统一规定的存储方法
只要基本功扎实活学活用什么方法都行
eg: 文件操作 数据库
内容概要
- 蔬菜价格爬取
- 爬虫解析库bs4模块
去页面上筛选需要的数据
- 爬取红牛分公司数据
1.用正则表达式筛选
2.借助于bs4模块筛选
详细讲解
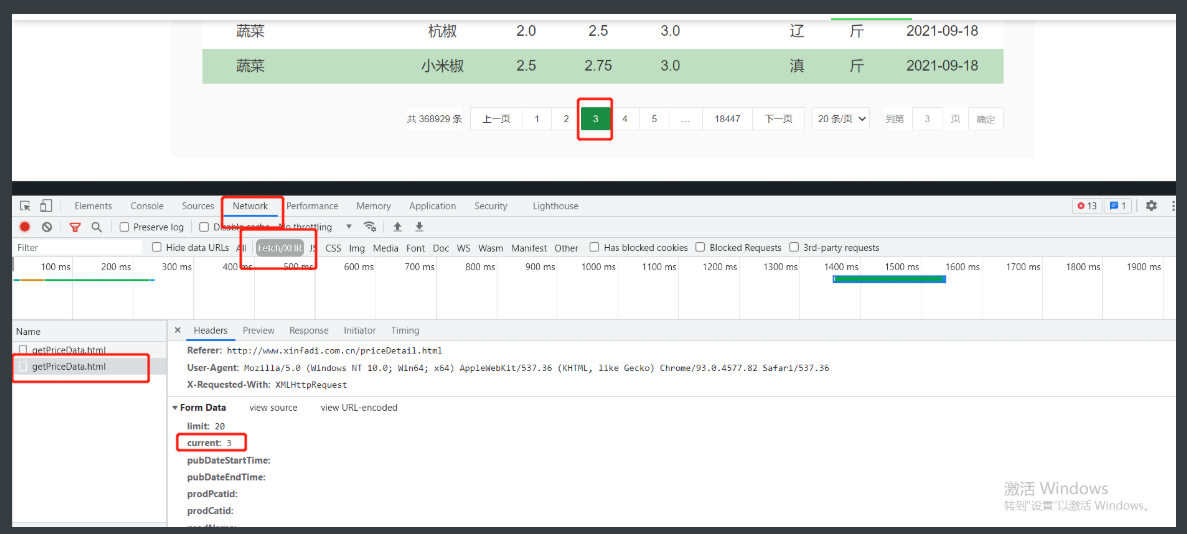
爬取蔬菜价格
# 爬取北京新发地蔬菜相关数据
1.首先明确我们要爬取的东西现在已经显示出来了
2.那么就要看他的加载方式
3.通过查看源码和复制查找简单比对知道是动态加载的
4.之后就通过network去内部查看
5.也就正好发现了一个post请求
6.看到这个请求先看response验证一下是不是所需数据
7.确认的确是那就要研究post中最关键的请求体数据
8.找到页码规律其实是请求体中一个参数控制的就可以开始书写代码了
import requests
import time
def get_price_data(n):
res = requests.post('http://www.xinfadi.com.cn/getPriceData.html',
data={
"limit": '',
"current": n,
"pubDateStartTime": '',
"pubDateEndTime": '',
"prodPcatid": '',
"prodCatid": '',
"prodName": '',
}
)
data_list = res.json().get('list')
for d in data_list:
pro_name = d.get('prodName')
low_price = d.get('lowPrice')
high_price = d.get('highPrice')
avg_price = d.get('avgPrice')
pub_date = d.get('pubDate')
source_place = d.get('place')
print("""
蔬菜名称:%s
最低价:%s
最高价:%s
平均价:%s
上市时间:%s
原产地:%s
""" % (pro_name, low_price, high_price, avg_price, pub_date, source_place))
time.sleep(1)
"""涉及到多页数据爬取的时候 最好不要太频繁 可以自己主动设置延迟"""
for i in range(1, 100):
time.sleep(1)
get_price_data(i)
# 这部分将爬取功能封装成函数 整体结果更加清晰
# 在显示数据的时候做了一点排版
# 还加入了一点暂停时间给网页缓冲的机会
爬虫解析库bs4模块
全名: Beautiful Soup4
是一个从HTML或XML文件中提取数据的python库,它能通过转换器实现惯用文档的导航,查找,修改文档的方式,Beautiful Soup会帮你节省数小时甚至数天的工作
模块下载
pip3 install beautifulsoup4
# 为了让一些功能更好的实现
下载配套解析器
pip3 install lxml
'''
一个强大的第三方模块经常会要下载好几个配套的模块才能使用
因为这个大模块里有许多功能也是直接调用了其他模块的
这样就省的自己再写 避免重复劳动 提高效率
python的调包侠称号真的很贴切 也反映出python的强大
'''
bs4模块使用
from bs4 import BeautifulSoup
# 构造一个网页数据
html_doc = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="title c1">
<b>The Dormouse's story</b>
</p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister c1" id="link1">Elsie</a>
<a href="http://example.com/lacie" class="sister c2" id="link2">Lacie</a>
<a href="http://example.com/tillie" class="sister c3" id="link3">Tillie</a>
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
</html>
"""
# 然后还要构建一个解析器 推荐使用lxml
soup = BeautifulSoup(html_doc, 'lxml')
# 接下来是内置方法
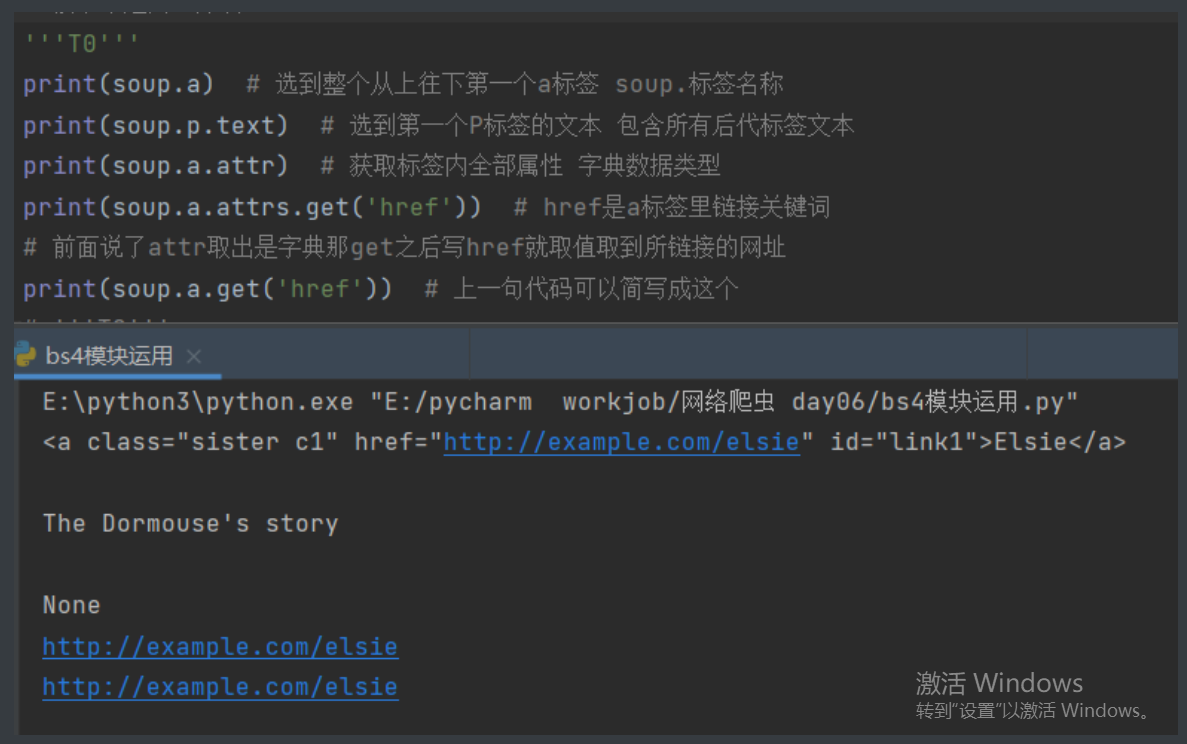
'''T0'''
print(soup.a) # 选到整个从上往下第一个a标签 soup.标签名称
print(soup.p.text) # 选到第一个P标签的文本 包含所有后代标签文本
print(soup.a.attr) # 获取标签内全部属性 字典数据类型
print(soup.a.attrs.get('href')) # href是a标签里链接关键词
# 前面说了attr取出是字典那get之后写href就取值取到所链接的网址
print(soup.a.get('href')) # 上一句代码可以简写成这个
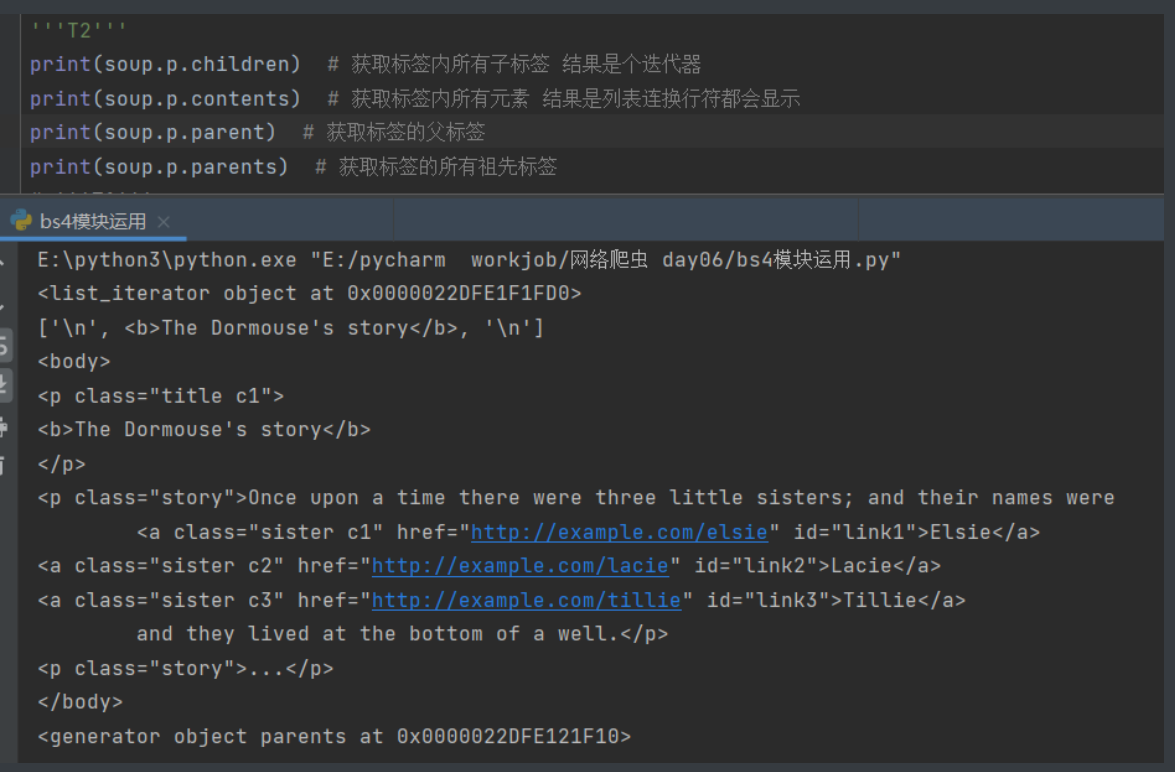
'''T2'''
print(soup.p.children) # 获取标签内所有子标签 结果是个迭代器
print(soup.p.contents) # 获取标签内所有元素 结果是列表连换行符都会显示
print(soup.p.parent) # 获取标签的父标签
print(soup.p.parents) # 获取标签的所有祖先标签
'''T1'''
# find方法 找到一个就结束 结果是一个标签对象
print(soup.find(name='a')) # 找指定标签名的标签 默认只找符合条件的第一个
print(soup.find(name='a', id='link2')) # 查找某个特定属性的标签 只找一个
print(soup.find(name='p', class_='title')) # class和类里的关键字冲突了 所以加一个下划线来区分
print(soup.find(name='p', attrs={'class': 'title'})) # 也可以在条件里直接用attr参数避免冲突
print(soup.find(attrs={'class': 'c1'})) # name参数可以不写表示查找所有符合后面条件的标签
# find_all方法 查找所有符合条件的标签 返回结果是个列表
print(soup.findAll('a')) # name字段可以不写
print(soup.find_all('a')) # 这两个方法是一样的 结果是一个列表
# select方法 用css选择器 返回结果是个列表
'''
1.标签选择器
直接书写标签名即可
2.id选择器
#d1 相当于写了 id='d1'
3.class选择器
.c1 相当于写了 class=c1
4.儿子选择器(大于号) 选择器可以混合使用
div>p 查找div标签内部所有的儿子p
5.后代选择器(空格) 选择器可以混合使用
div p 查找div标签内部所有的后代p
'''
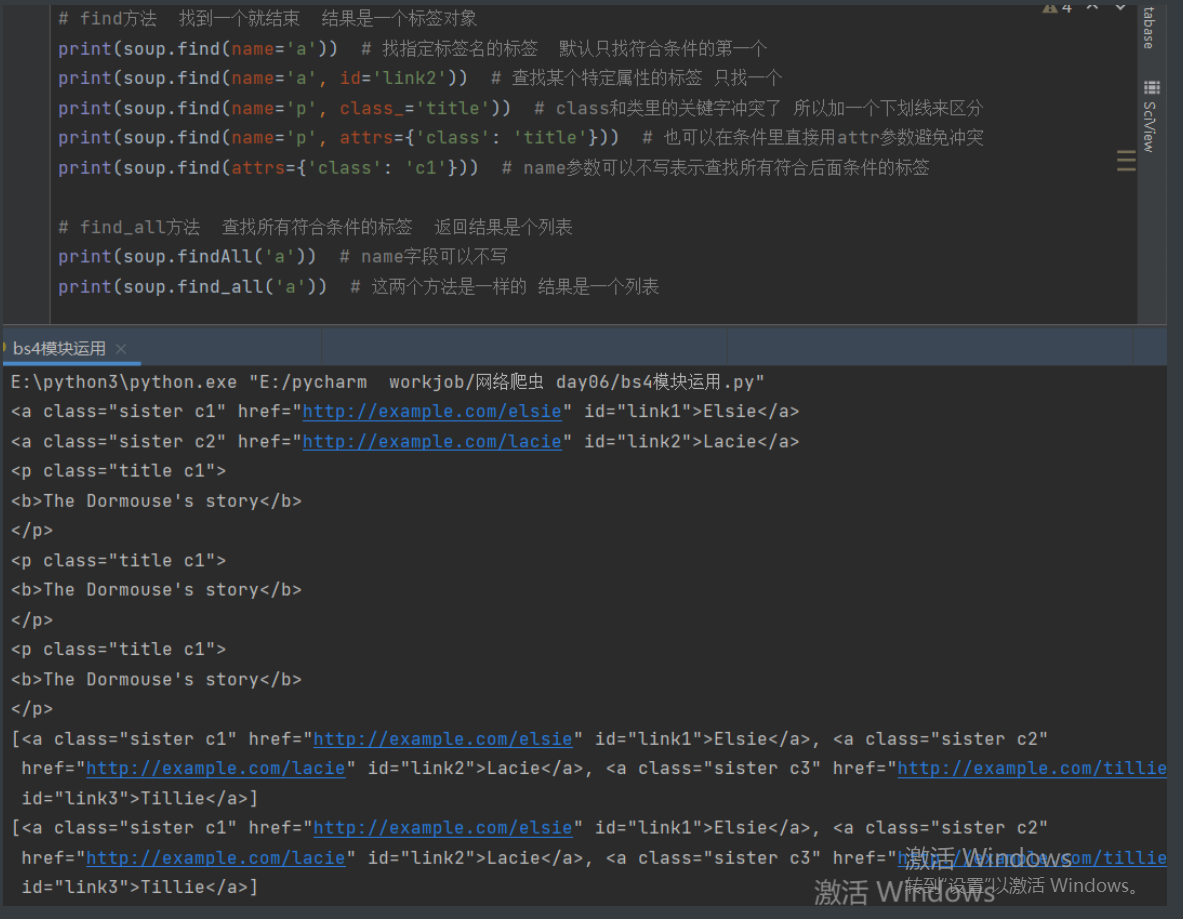
print(soup.select('.title')) # 查找class含有title的标签
print(soup.select('.sister span')) # 查看class含有sister标签内所有的后代span
print(soup.select('#link1')) # 查找id为link1的标签
print(soup.select('#link1 span')) # 查找id等于link1标签内部所有的后代span
print(soup.select('#list-2 .element')) # 查找id等于list-2标签内部所有class为element的标签
# 遇到上面这种不要急一个个看先前面是id等于list-2然后空格就是找之前定位的标签的后代再看.element
# 一步步分析得出结果
print(soup.select('#list-2')[0].select('.element')) # 完整的分开写应该是这样
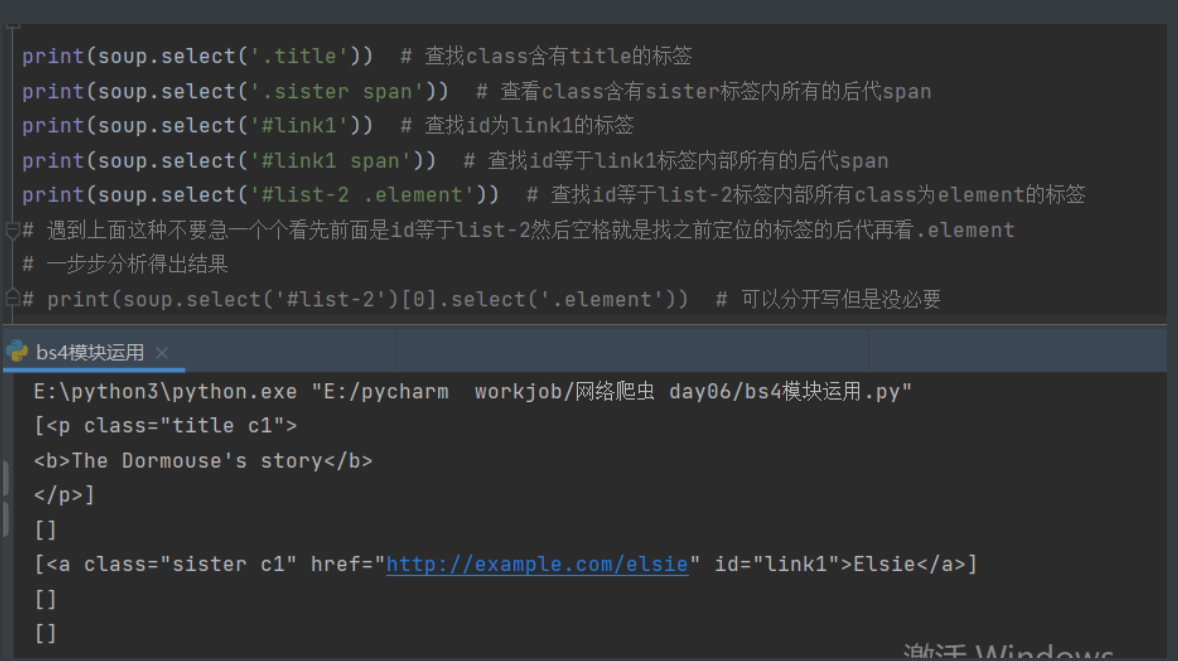
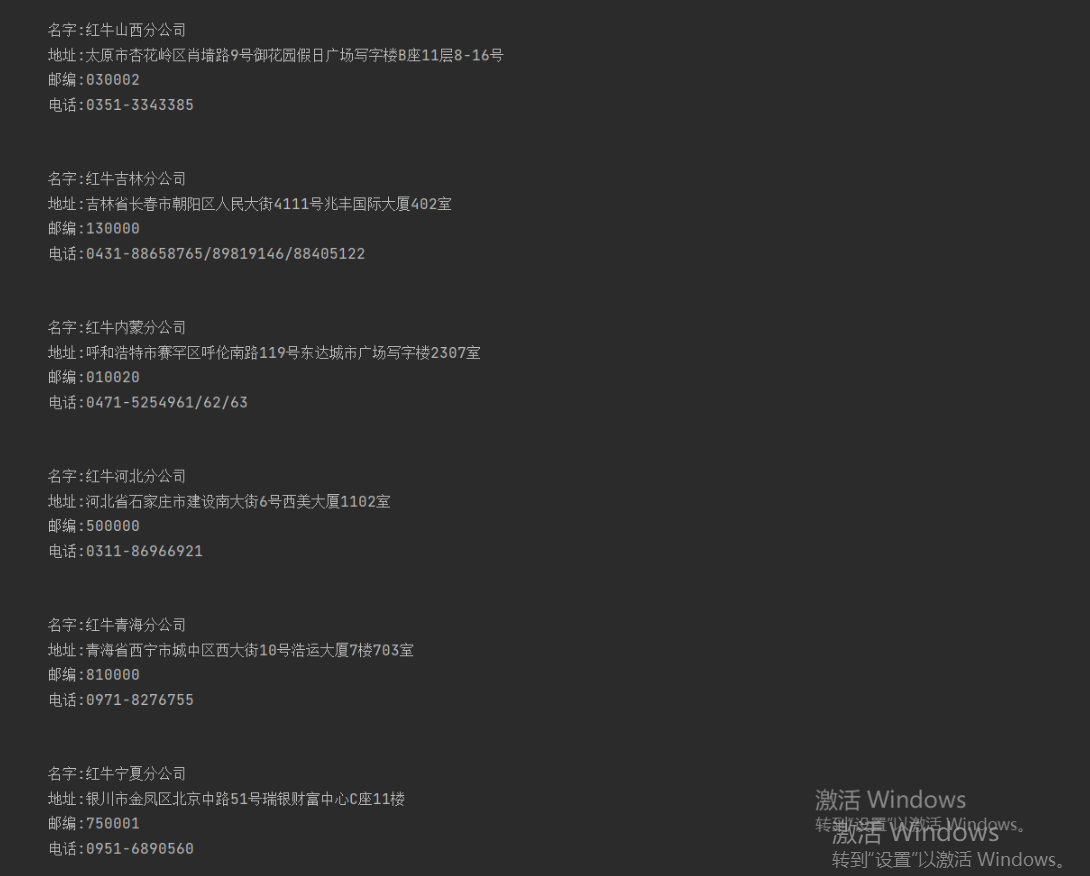
红牛分公司数据
import requests
from bs4 import BeautifulSoup
'''
分析后发现数据都是直接写在网页上的
那就好说了先全部爬下来
'''
res = requests.get('http://www.redbull.com.cn/about/branch')
soup = BeautifulSoup(res.text, 'lxml')
# 现在soup就是解析好的网页文本数据了
'''然后我们继续观察看到h2似乎全是公司名称'''
h2_tag_list = soup.find_all('h2') # 找到所有h2标签对象
# for i in h2_tag_list:
# print(i.text)
# 上述两行可以用列表生成式简化成
title_list = [i.text for i in h2_tag_list] # 这样看起来高端了许多
# 什么你和我说列表生成式忘了?滚去复习啊抛盖
p_tag_list = soup.select('li>p') # 用css选择器把剩下的刨出来
# for i in tag_list:
# print(i.text)
detail_list = [i.text for i in p_tag_list]
# print(detail_list)
for i in range(len(title_list)):
print("""
公司名称:%s
公司详情:%s
""" % (title_list[i], detail_list[i * 3: i * 3 + 3]))
正则爬红牛
import requests
import re
res = requests.get('http://www.redbull.com.cn/about/branch')
info = res.text
name = re.findall("<h2>(.*?)</h2>", info)
add = re.findall("<p class='mapIco'>(.*?)</p>", info)
mail = re.findall("<p class='mailIco'>(.*?)</p>", info)
tele = re.findall("<p class='telIco'>(.*?)</p>", info)
'''通过正则拿到标签里数据'''
for i in range(len(name)):
print("""
名字:%s
地址:%s
邮编:%s
电话:%s
""" % (name[i], add[i], mail[i], tele[i]))