
9/16
今日考题
1.re模块下常见方法及各自特点
re.finadall # 最普通的返回匹配到的所有结果的列表
re.finditer # 返回包含所有结果的迭代器
for i in re.finditer # 迭代器可以借由for循环取值
i.group # 取值完.group可以获取到结果
re.search # 匹配到一个结果就停止
re.match # 从开头匹配开头不符合就停止
2.python如何下载第三方模块,如何提升下载速度,常见的报错有哪些
1.cmd窗口
输入pip3 install requests
2.pycharm左下角terminal
输入pip3 install requests
# 这两种方法都可以在后面加上
-i 国内的镜像源
3.pycharm通过setting里面点击下载
常见报错
1.timeout这类网络问题等待或者重试
2.工具版本问题输入推荐输入的指令更新即可
3.比较复杂和环境问题或别的疑难杂症 百度解决
3.requests爬取到的对象有哪些常见方法
假设res = requests.get('某网站')
res.status_code # 获取响应状态码
res.encoding # 把获取到的数据编码 毕竟网络传输只能是二进制
res.text # 获取爬下来的文本
res.content # 获取爬下来文本的bytes类型文本
4.聊聊HTTP协议
# 四大特性
1.基于请求响应
你不操作网页不会自己乱动
2.基于TCP、IP作用与应用层的协议
3.无状态
4.无连接
3和4可以一起理解为网页响应完之后就和请求方完全没有瓜葛
甚至连之前请求的记忆都没
# 数据请求格式
请求首行(请求方法 网站地址)
请求头(K:V)
请求体(get没 post塞敏感数据)
响应首行(响应状态码 协议版本)
响应头(K:V)
响应体(浏览器给用户看的数据)
# 响应状态码
1XX类 收到请求在处理
2XX 最常见200 请求成功
3XX 重定向 你要去A我由于某些原因把你转去B
4XX 常见403请求不符合条件 404地址不存在
5XX 服务器有问题
还有工资自己定义的状态码一般1000开头
复习巩固
- re模块常用方法
re.findall() # 全局匹配符合条件的数据 列表结果
re.finditer() # 全局匹配结果是迭代器
re.search() # 匹配到一个符合条件的结果就结束
re.match() # 从头开始匹配 不符合直接返回None
- requests模块简介
能够模拟发送网络请求>>>不支持执行js代码
还有个叫request-html
是书写requests模块的作者后续开发的
功能强大并且支持js代码
pip3 install requests
- 网络请求方法
URL:统一资源定位符
get方法
向别人所要数据
post方法
向别人提交数据
有时候为了携带一些敏感数据也会做成post
- HTTP协议
规定了浏览器和服务端之间数据交互的格式及网络请求相关的其他标准
1.四大特性
2.数据格式
3.响应状态码
- requests其他参数
# url
requests.get(url='网址')
# params get请求携带的额外参数
requests.get(url,params={})
# headers 请求头数据
request.get(url,headers={})
'''
防爬措施
1.校验当前请求是否由浏览器发出
请求头里添加"User-Agent":"..."
'''
内容概要
- cookie与session
- 代码模拟用户登录
- json格式数据
- ip代理池(高级防爬)
- requests其他方法
- 实战环节
详细讲解
cookie和session
# cookie与session的由来专门用来解决http协议无状态的特点
http协议无状态 >>> 不保存用户端状态
'''早期的网址不需要保存用户状态 所有人来访问都是相同数据'''
随着时代发展越来越多的网站需要保存用户状态
1.cookie:保存在客户端浏览器上的'键值对数据'
用户第一次登录成功后会保存用户名和密码
之后访问网站都会自带用户名和密码
2.session:保存在服务端上的用户相关数据
用户第一次登录后客服端会返回一串随机字符串
服务端保存随机字符串和用户名的对应关系
客户端保存这个随机字符串,之后访问该网站都带着这个随机字符串
# cookie和session的关系:session需要依赖cookie
cookie可以保存键值对数据
session想要保存数据到浏览器还是要借由cookie
所以只要涉及用户登录都要用cookie
ps:浏览器可以拒绝保存数据
cookie实战
"""
浏览器network选项中 请求体对应的关键字是Form Data
"""
通过network找到网页在点击登录的时候和哪个网站在提交数据
那个网站就是负责数据校验的
以华华手机为例
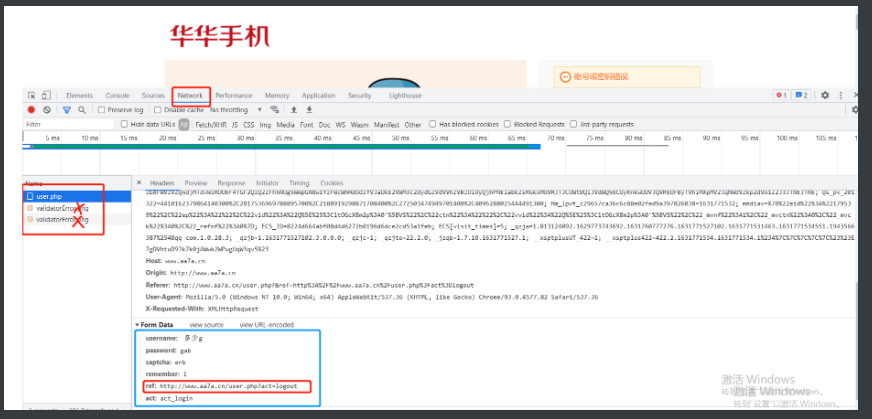
登录提交数据的网址就是 http://www.aa7a.cn/user.php
接下来设置请求数据的格式 按照蓝色框框照抄就完事了
username:3244@qq.com
password:123
captcha:sfvv
remember:1
ref:http://www.aa7a.cn/user.php?act=logout
act: act_login
'''写爬虫之前一定要先用浏览器多研究研究要爬的网站'''
# 1.研究登录数据提交给后端的url地址 前面做好了
# 2.研究登录post请求携带的请求体数据格式 刚刚完成
# 3.模拟发送post请求 终于开始搞代码了
import requests
res = requests.post('http://www.aa7a.cn/user.php',
data={
"username": "1943566387@qq.com",
"password": "123123",
"captcha": "d5fb",
"remember": 1,
"ref": "http://www.aa7a.cn/user.php?act=logout",
"act": "act_login"
} # 前面说了的东西放进来第三个是验证码
)
# 之后就要想办法拿到cookie数据也就是返回出来的那段随机字符串
# 这个在模块中已经写好了直接调用就i行
user_cookie = res.cookies.get_dict()
# 顺手写入文件
with open(r'user_cookie', 'w', encoding='utf8') as f:
json.dump(user_dict, f)
'''
用户名和密码错误的情况下获得的返回值
{'ECS[visit_times]': '1', 'ECS_ID': 'e0e476cf945b956dd081685f39fcfd263eff3b6f'}
一切正确的情况下返回值则是 {
'ECS[password]': '4a5e6ce9d1aba9de9b31abdf303bbdc2',
'ECS[user_id]': '19432',
'ECS[username]': '19456%387qq.com',
'ECS[visit_times]': '1',
'ECS_ID': 'c975d236d710113524804ce69b184d875629e4a47'
}
'''
# 然后再尝试用获取到的cookie访问网站
res1 = requests.get('http://www.aa7a.cn/',
cookies = user_cookie
)
# 这样就算完成了但是实际上并没法登陆上
if '1943566387@qq.com' in res1.text:
print('登录上了')
else:
print('cookie有问题')
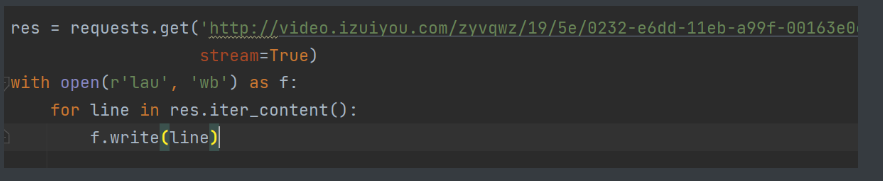
获取大数据
加入stream参数能一点点的取值
比如下个很大的视频直接写入到文件里是做不到的
import requests
res = requests.get('https://www.Prohub.com/BBC.mp4',
stream=True)
with open('b.mp4','wb') as f:
for line in res.iter_content(): # 一行一行读取内容
f.write(line) # 然后一行行的写入 防止内存爆炸
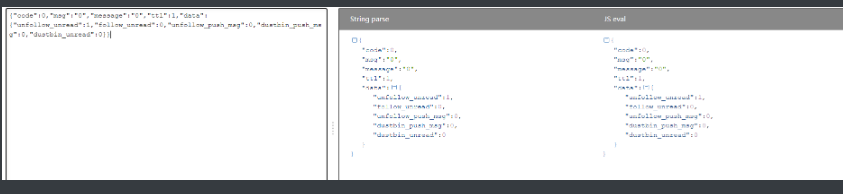
json格式
json格式的数据有一个非常显著的特征 >>> 引号肯定的双引号
在网络爬虫领域 其实内部有很多数据都是采用的json格式
# 前后端数据交互一般使用的都是json格式
import requests
res = requests.get('https://api.vc.bilibili.com/session_svr/v1/session_svr/single_unread?unread_type=0&build=0&mobi_app=web')
print(res.json()) # 可以直接将json格式字符串转换成python对应的数据类型
SSL相关报错
苹果电脑比较常见这种问题
百度之后加上两行代码即可
IP代理池(防爬)
有很多网站针对客户端的IP地址也存在防爬措施
eg:比如一分钟之内同一个IP地址访问该网站的次数不能超过30次超过了就封禁该IP地址
针对这种情况怎么办?
可以去搜索IP代理池
里面有很多ip地址从免费的里面选几个用上就行
# 代理池的意义 先把请求发送到好多IP地址的池里
# 然后池子里的IP帮忙发送去爬网站的请求 毕竟封IP很常见
import requests
proxies={
'http':'145.56.210.65:8800',
'http':'168.75.183.64:8880',
'http':'125.175.12.26:8008',
}
respone=requests.get('https://www.12306.cn',
proxies=proxies)
Cookie代理池
很多网站针对cookie也会有防爬措施 和封IP同理
eg:比如一分钟之内同一个cookie访问该网站的次数不能超过30次超过了就封禁该cookie
解决思路和上面一样
但是cookie池得自己建比如自己注册好多账号
然后放到文件里去随便选
可以前面加个random或者爬一次换一个cookie
respone=requests.get('https://www.12306.cn',
cookies={})
遇上的防爬
5chaKGWy
shkBNsPb
4oQMyHPC
e13UzwfQ
资源碎片化一点点提交然后最后的网站链接加密了

