9/15
今日考题
1.尽可能多的列举你所知道的html标签及各自作用
<a>链接标签</a>
<p>这行的文字内容</p>
<h1>一级标题</h1>
<u>下划线</u>
<s>删除线</s>
<i>我倒了</i>
<b>变粗!</b>
<img/图片连接> 插入图片
<hr> 水平线
<br> 换行符
<img src='图片标签'/>
<ul>
<li>这是</li>
<li>列表</li>
<li>标签</li>
</ul>
<!--下面是表格标签-->
<table>
<thead>
<tr>
<th>这里是</th>
<th>表头</th>
</tr>
</thead>
<!--下面是表格标签-->
<tbody>
<tr>
<td>这里是</td>
<td>表单部分</td>
</tr>
</tbody>
</table>
<!--表单标签-->
<form>
<input type=''> <!--获取用户输入 type控制类型-->
</form>
2.标签有哪些重要的特性及嵌套关系
有id属性 相当于标签的身份证
有class属性 相当于标签的分类
块级标签比如<div></div>里可以无限嵌套
里面一级的标签就是儿子再里面一级就是儿子
简而言之就是和人认亲戚是一个道理
只不过有时候会有好几个爸爸
3.什么是正则表达式,分别列举几个字符组,符号,量词
正则表达式就是通过一些特殊符号的组合去匹配大段文本中我们所需的数据
字符组:
[0-9] # 匹配数字
[a-z] # 匹配小写英文字母
[0-9a-zA-Z] # 匹配数字和英文字母
符号:
. # 匹配任意字符一次
^ # 匹配开头
$ # 匹配结尾
\d # 匹配数字
a|b # 匹配a或b
[...] # 匹配中括号内字符
[^...] # 匹配除中括号内字符外全部字符
量词:
* # 重复0或多次
+ # 重复1或多次
? # 重复0或1次
{n} # 重复n次
{n,} # 重复n次或多次
{n,m} # 重复n次到m次
'''量词使用的时候默认往次数多的去匹配称为贪婪原则
在量词后加?可以让其尽可能少的匹配'''
复习巩固
- 特殊符号
# 浏览器上肉眼看到的事物不一定是真的很多是借由一些符号的组合显示出来的
- 常用标签
<a href="网页链接">链接标签</a>
<img src='图片标签'>
<div>
布局标签
</div>
<span>布局标签(不常用)</span>
- 列表标签
<ul>
<li></li>
</ul>
- 表格标签
<table>
<thead>
<tr>
<th></th>
</tr>
</thead>
<tbody>
<tr>
<td></td>
</tr>
</tbody>
</table>
- 表单标签
<form>
<input type=''>
<!---->
</form>
- 标签特性
由于在同一个页面上会出现很多相同名称的标签
所以为了区分有了一下两个特性
id
class
标签嵌套层级关系
父级标签
儿子 后代 兄弟 ...
- 正则表达式
'''用一些特殊符号的组合去打断字符中筛选出符合条件的文本内容'''
1.字符组
[a-z]
2.符号
.
\d
^
$
|
()
[^...]
3.量词
*
+
?
{n,}
{n,m}
'''贪婪匹配原则和规避方法'''
- 内置re模块
import re
re.findall(正则表达式,待匹配的数据)
内容概要
- re模块
- 爬虫入门模块requests
- 网络请求的方式
- requests模块实战演练
- cookie与session
详细讲解
re模块
import re
s = 'brgvanleofdfljbnkadfn leo'
res = re.findall('l.*?o',s) # 返回一个匹配到所有结果的列表
res1 = re.finditer('l.*?o',s) # 返回一个不占内存的迭代器
print(res)
print(res1)
for i in res1: # finditer取到是个迭代器
print(i) # 只有主动索要才会产生数据
print(i.group())
res3 = re.search('l.*?o',s) # 匹配到一个符合条件的就结束
res4 = re.match('l.*?o',s) # 从头开始匹配 头部不符合就停
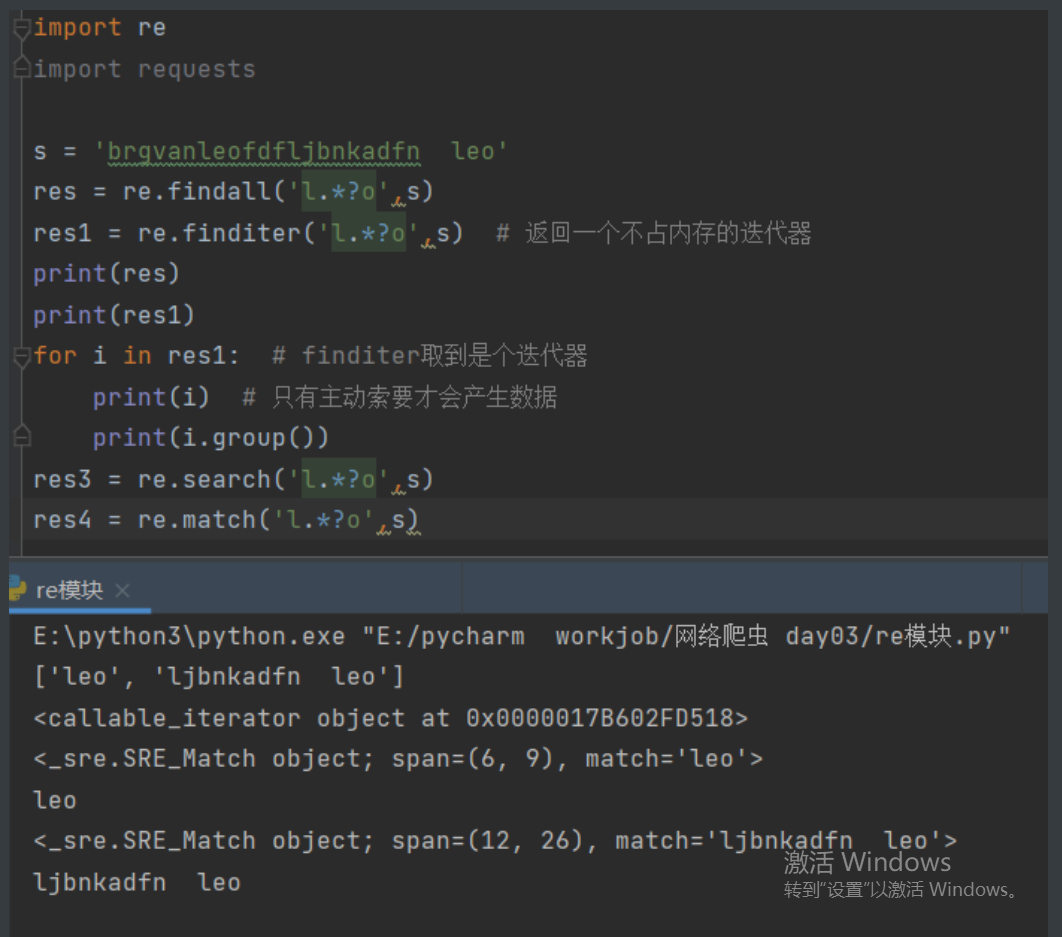
import re
b = 'www.bilibili.com'
res = re.findall('www.(bilibili).com', b)
print(res) # findall分组优先展示 会优先展示括号里的内容
res1 = re.findall('www.(?:bilibili).com', b)
print(res1) # 通过在左括号后面加上?:可以取消优先展示
res2 = re.findall('www.(?:bilibili|baidu).com', b)
print(res2)
爬虫模块requests
# 作用
可以模拟浏览器发送网络请求获取数据
# 下载
1.提到下载模块就要想相关知识
2.切换源 -i
3.报错处理等
# 导入模块
import requests
有提示说明装好啦

网络请求方法
网络方法有很多 多到8种 但是重点掌握2种
# get请求
向别人要数据
eg:浏览器输入b站网址回车其实就是在发送get请求 即向b站服务器索要网站首页
get请求也可以携带额外的数据 但是数据有限制最多2-4KB 并且直接写在网址后面
格式是url?xxx=yyy=nnn=mmm
# post请求
向别人提交数据
eg:搜索数据的时候要在搜索框输入内容发送post请求将数据提交给远程服务器
post请求也可以携带额外数据 并且大小没有限制
一般来说敏感数据都是由post请求携带的
数据放于请求体中
'''请求体下面就讲'''
HTTP协议
# 规定了浏览器和服务端之间数据交互的方式
1.四大特性
1.基于请求相应
不给请求服务器不会给你跳乱七八糟数据
2.基于TCP、IP作用与应用层之的协议
3.无状态
纵使见她千百遍 我都待她如初见
4.无连接
数据交互完之后就没有任何联系了
2.数据请求格式
2.1请求数据格式
请求首行(放请求方法 地址...)
请求头(一堆K:V键值对)
(这里必须有一个空行)
请求体(get请求没有请求体 post有里面放敏感数据)
2.2响应数据格式
响应首行(响应状态码 协议版本...)
响应头(一堆K:V键值对)
(这里必须有一个空行)
响应体(一般里面都是浏览器展示给用户看的数据)
3.响应状态码
# 通过数字来表达一串意思
1XX:服务端已经成功接收到了你的数据正在处理 你可以继续提交或者等待
2XX:200 请求成功服务端发送了响应 最常见的
3XX:重定向(原本想访问A但是转跳去B)
比如淘宝没登陆想购买会转跳去登录
4XX:403请求不符合条件 404请求资源不存在
5XX:服务器内部错误
'''
公司有时候还会自己自定义响应状态码
因为HTTP的状态码太少不够用 一般都是1000开头
10001
10002
参考网址:聚合数据
'''
requests模块基本使用
# 发送网络请求的方式
import requests
requests.get(url) # 发送get请求
requests.post(url) # 发送post请求
# 简单的get请求获取页面
import requests
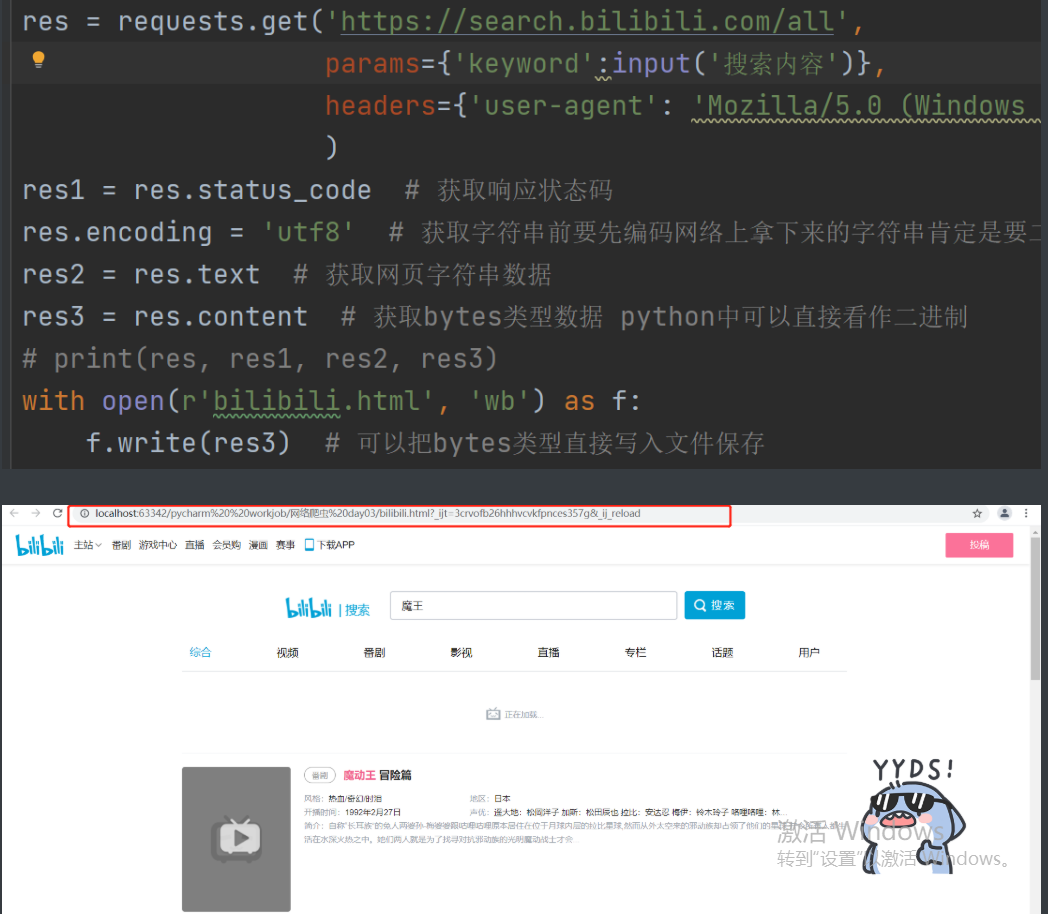
res = requests.get('https://www.bilibili.com/v/anime/serial/#/all/default/0/1/')
res1 = res.status_code # 获取响应状态码
res.encoding = 'utf8' # 获取字符串前要先编码网络上拿下来的字符串肯定是要二进制才能传输的
res2 = res.text # 获取网页字符串数据
res3 = res.content # 获取bytes类型数据 python中可以直接看作二进制
# print(res, res1, res2, res3)
with open(r'bilibili.html', 'wb') as f:
f.write(res3) # 可以把bytes类型直接写入文件保存
# 携带参数的get请求
requests.get(url,params={})
里面放上K:V键值对模拟携带的参数
# 携带请求头数据的请求
requests.get(url,headers={})
防爬措施
有种很常见的防爬措施就是看这个请求是否是浏览器发出的
这个办法的核心在于请求头里的user-agent键值对
只要请求头里含有这个键值对就表示这是个浏览器没有就代表不是
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36
配合requests.get(url,headers={})就可以伪装成浏览器了