
9/14
今日考题
1.详细写出pymysql结合mysql实现注册登录逻辑思路
1.先导入模块,连接上mysql服务端
2.用while循环做出登录注册大致结构
3.注册
1.获取用户名密码
2.通过用户名去数据库中拿数据并fetchall获取结果
3.有结果即布尔值为True 提示用户名已经被注册
4.布尔值为False即没有结果则将 获取的用户名和密码写入数据库
5.注册结束
4.登录
1.获取用户名密码
2.通过用户名去数据库中拿数据并fetchall获取结果
3.布尔值为False即没有这个用户名提示去注册
4.有结果即布尔值为True则接着向下走
5.fetchall的结果为列表加字典的组合
6.通过索引取值和字典里的索引取值拿到用户密码
7.比对获取的密码和输入的密码是否一致
8.一致提示登录成功
9.不一致提示密码错误
2.互联网是什么,上网的本质是什么,网络爬虫的目的
互联网就是无数台计算机相互连接在了一起
上网本质就是向另一台电脑请求下载他上面的数据到本地
网络爬虫是为了模拟出上网的请求,然后从互联网上把所需要的数据自动下载下来
3.前端与后端如何理解,前端三剑客分别是哪些各自有什么作用
前端 是所有和用户打交道的界面
后端 则是在其背后运行的代码 用户看不懂的那些东西
前端三剑客
HTML 制作网页的主体 相当于人的骨架
CSS 制作网页样式 相当于人的皮肤
javaScript 制作一些动态的事件 相当于化妆
4.截止目前为止你都了解哪些标签及作用
<a>这里放提示</a> <!--超链接-->
<p>这行的文字内容</p>
<h1>一级标题</h1> <!--h后面数字最小到6数字越小等级越低-->
<u>下划线</u>
<s>删除线</s>
<i>我倒了</i>
<b>变粗!</b>
<img/图片连接> 插入图片
<hr> 水平线
<br> 换行符
复习巩固
- pymysql注册登录
# 注册部分逻辑
1.获取用户名密码
2.查询用户名是否存在的sql语句
3.基于pymysql模块查询数据
4.如果存在则报用户名已存在无法注册
5.如果不存在则定义插入数据的sql语句并执行
# 登录逻辑
1.获取用户名密码
2.查询用户名是否存在的sql语句
3.基于pymysql模块查询数据
4.如果存在则取出该用户所有数据
5.如果不存在则报用户名不存在无法登录
6.比对密码是否正确
7.提示登录成功或者密码错误
'''拓展 定义一个函数 用于自动创建表
获取用户想要创建的表字段'''
- 网上获取数据途径
# 白嫖类
# 付费类
# 第三方机构
- 互联网以及上网本质
互联网就是由网络设备与一台台计算机连接而成的
互联网建立的目的就是为了数据的远程共享
上网的本质其实就是在基于互联网访问其他计算机上面的数据
- 爬虫分类
网络爬虫其实就是模拟浏览器发送请求获取数据并对数据进行'解析保存'
通用爬虫与聚集爬虫 两类爬虫
# 为什么要学习爬虫
数据就是互联网上做有价值的东西
爬虫可以帮助我们更加快速的获取到更加具体的数据内容
- 前端HTML
# 浏览器展示给用户看的花里胡哨的界面内部本质其实就是一堆HTML代码
网页文件的后缀名一般都是.html结尾
HTML文件基本结构
<html>
<head></head>
<body></body>
</html>
head内常见标签
title
link
style
script
meta
body内基本标签
h1~h6
p
u i s b
hr br
"""
标签的分类
1.双标签
<a></a>
2.自闭和标签
<img/>
有些标签与标签之间可以无限制的相互嵌套
"""
内容概要
- 特殊符号
- 常用标签
- 列表标签
- 表格标签
- 表单标签
- 正则表达式
爬虫就是从网页一堆数据中筛选出符号我们要求的数据
这正好是是正则表达式可以实现的功能
详细讲解
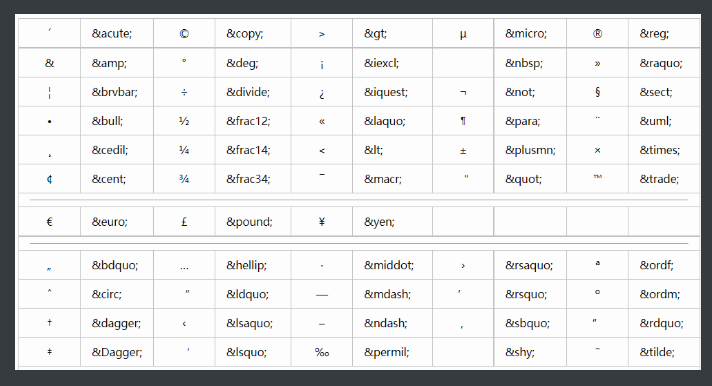
特殊符号
空格
> >
< <
& &
¥ ¥
版权 ©
注册 ®
常用标签
<a href='https://www.baidu.com'>百度</a>
href参数
1.放网址点击可以直接跳转
2.锚点功能
放其他标签的id值点击就可以跳转到对应的标签位置 #id值是自己赋给指令的
3.链接标签位置可以直接插图片标签
<img src='suck.jpg'/>
src参数
1.可以放网络图片的地址
2.也可以放本地图片的地址
title参数
鼠标悬浮在图片上之后可以展示的文字信息
alt参数
图片由于某些原因加载不出来的时候可以提示的文字信息
width、height参数
调节图片的长宽 默认调节一个就可以 另外一个等比例缩放
如果两个都调节那么可能会出现图片失真的情况

列表标签
<ul>
<li>小李</li>
<li>小明</li>
<li>小红</li>
</ul>
"""在网页上看似有规则排列的横向或者竖向依次排列的内容基本都是用列表标签完成的"""
表格标签
'''涉及到多条相同格式数据展示的时候可以考虑使用表格标签(类似于excel)'''
<table>
<thead>
<tr> # 一个tr就代表一行
<th>序号</th> # th加粗的文本
<th>姓名</th>
<th>年龄</th>
</tr>
</thead> # 表头(字段名称)
<tbody>
<tr>
<td>1</td> # td普通文本
<td>jason</td>
<td>18</td>
</tr>
</tbody> # 表单(数据部分)
</table>

表单标签
"""涉及到用户数据的获取一般都要用到表单标签
该标签可以接受用户的数据并发送给后端服务器"""
获取用户数据的标签最为常见的就是input
并且获取用户数据的标签最好都要有一个name属性
用来表示该数据到底是用户的什么数据
input标签
type参数
text 普通文本
password 密文展示
email 邮箱格式
date 日期格式
radio 单选
checkbox 多选
file 文件
submit 提交(触发form表单提交数据的动作)
reset 重置按钮
button 普通按钮
select标签 下拉框
option子标签
textarea标签
大段文本
# 补充
1.获取用户数据的标签都应该有name属性
2.针对file和select都可以变为多个选项 multiple
标签属性
<a id='' class=''></a>
上述id、class等都称之为a标签的属性
"""标签两大核心属性"""
1.id值
类似与标签的身份证号码 在同一个html文件里 id不能重复
2.class值
类似于标签的群号码 多个标签可以属于一个群体 多个标签也属于多个群体
<a class='c1'></a>
<a class='c1 c2'></a>
eg:
<p class='c1'></p>
<a class='c1'></a>
<div class='c1'></div>
一个标签可以含有多个class值
<span class='c1 c2 c3'></span>
"""标签还可以自定义任意的属性"""
<a username='leo' pwd=123></a>
"""标签之间的关系描述"""
<div>只要是div内部的标签都可以称之为是div的后代
<a>上一级div的儿子</a>
<p>上一级div的儿子
<span>上一级p的儿子上上一级div的孙子</span>
</p>
<div>上一级div的儿
<a>上一级div的儿子上上一级div的孙子</a>
</div>
<span>上一级div的儿子</span>
</div>
正则导入
# 纯python实现获取手机号的限定
# 1.获取用户手机号
phone = input('请输入手机号>>>:').strip()
# 2.先判断长度是否是11位
if len(phone) == 11:
# 3.再判断是否是纯数字
if phone.isdigit():
# 4.最后判断开头是否是13 15 17 18
if phone.startswith('13') or phone.startswith('15') or phone.startswith('17') or phone.startswith('18'):
print('获取验证码')
else:
print('手机号有误')
else:
print('手机号必须是纯数字')
else:
print('手机号必须是11位')
'''这样确实能够实现目的但是代码太长了
用正则表达式的话代码量一下子就骤减'''
###############################################
import re
phone_number = input('please input your phone number : ')
if re.match('^(13|14|15|18)[0-9]{9}$',phone_number):
print('获取验证码')
else:
print('手机号不正确')
# 注意: 当需要匹配的内容很精确不要思维定势直接输入即可
eg:
待匹配的文本 leoacedbnaebjeabmeab
要匹配的文本ace
直接match后面括号里写上ace即可
正则表达式字符组
# 字符组在匹配内容的时候是单个单个字符挨个匹配
[0123456789] 匹配0到9之间的任意一个数字
[0-9] 可以简写成
[a-z] 匹配小写字母a到z之间的任意一个字母
[A-Z] 匹配大写字母A到Z之间的任意一个字母
[0-9a-zA-Z] 匹配数字或者小写字母或者大写字母
正则表达式符号
# 符号在匹配内容的时候是单个单个字符挨个匹配
. 匹配除换行符以外的任意字符
\d 匹配数字
^ 匹配字符串的开始
$ 匹配字符串的结尾
a|b 匹配字符a或字符b
() 给正则表达式分组 本身没有任何意义
[...] 匹配字符组中的字符
[^...] 对中括号中字符取取反
正则表达式之量词
# 跟在正则表达式的后面可以一次性匹配多个字符
'''量词必须跟在正则表达式后面 不能单独出现使用'''
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
"""正则表达式默认情况下都是贪婪匹配:
尽可能多的匹配"""
所以上述情况不做限定的话都会无限次重复前面一个要求去匹配
# 小练习
正则 待匹配的文本 结果
海. 海燕海娇海东 三个结果 海燕、海娇、海东
^海. 海燕海娇海东 一个结果 海燕
海.$ 海燕海娇海东 一个结果 海东
海.* 海燕海娇海东 一个结果 海燕海娇海东
贪婪匹配
"""贪婪匹配与非贪婪匹配"""
<.*> <script>leo</script>
结果: <script>leo</script>
右侧尽可能多的匹配大括号最后一个才停止
# 将贪婪匹配变成非贪婪匹配只需要在量词后面加一个问号即可
<.*?> <script>leo</script>
结果: 匹配到两个结果<script>和</script>
右侧遇到一个大括号就停止匹配
取消转义
\n 匹配的是换行符
\\n 匹配的是\n
\\\\n 匹配的是\\n
#因为前两个\都有特殊含义所以要两个\去转义
re模块
# 如果想在python代码中使用正则表达式需要借助于内置模块re
import re
text = '<script>leo</script>'
res = re.findall('<.*?>',text) # 前面放正则表达式 后面放文本
print(res)

