9/13
今日考题
1.尽可能多的列举你所使用过的模块及作用
json 能够转换成固定格式
将数据能够以什么形式存入就以什么形式取出
并且可以跨系统运行
os 能操作系统
mkdir # 创建文件夹
path.join # 拼接路径
hashlib 加密
time 时间
random 随机模块
random.randint(0,9) # 从0到9中随机取值
pymysql 第三方模块 用于操作mysql
execute # 执行sql语句
fetchall # 获取执行结果
fetchone # 获取执行结果中第一项
2.sql注入如何产生又如何避免
由于一些特殊符号和字段的组合引起一些超出常识的现象
称为sql注入
只需要将所要获取的数据放在execute后面填充即可
3.什么是事务,有哪些特性
事务就是数据库的一系列操作集合整合之后并被定义为事务
特性有ACID
A 原子性
事务无法无法分割 整个一连串操作就是一个整体 要么同时成功要么同时失败
C 一致性
事务必须至始至终保持一致 例如转账后双方金额总和
I 独立性
事务与事务之间相互独立互不干扰
D 持久性
事务一旦执行确认就不再可逆
4.概括数据库设计三大范式
第一范式: 数据无法再被继续分割
第二范式: 表结构要清晰
第三范式: 一个表所有数据之间要有明确直接的关系
5.什么是索引,有哪些优缺点,MySQL中可以充当索引的有哪些各自有何特点
索引就类似书的目录
优点 可以加快查询速度 缺点 就是增加写入的时间
mysql中可以充当索引的有
primary key 主键 # 加快索引效率 mysql默认一定会有主键 一般用作id
unique 唯一键 # 加快索引 同时限定唯一
index key 索引键 # 加快索引
'''记得区分与foreign key 和索引没关系'''
复习巩固
- pymysql补充
# 获取执行结果的三个方法
fetchone()
fetchmany()
fetchall()
- sql注入
在mysql中注释
1. #
2. --
有时候输入特殊符号会造成sql语句运行时出现问题
只需要放入execute(sql(数据,数据))
- 用户管理
可以设置不同用户的权限
进入公司后会拿到自己的账户
所以有些操作不能实现不用大惊小怪
- 事务
通过start transaction;
开始事务
commit之后事务结束并被确认
rollback回到事务开始前的状态
- 索引
索引在计算机内部是一个数据结构(b树 b*树 b+树 红黑树...)
在MySQL中索引的表现形式就是"键"
primary key
unique key
index key
# 优点
创建索引后搜索会大幅加快
# 缺点
索引多了之后写入效率会降低
- 各种理论知识
视图
将sql语句的查询结果变成虚拟表保存
触发器
达到某条件后自动触发发功能
某张表增、删、改的前后六个阶段都可以作为触发的前提
流程控制
和python中的if和while基本一样
语句上稍有不同
内置函数
mysql内部提供的数据操作方法
内容概要
- 登陆注册联动mysql
- 获取数据途径
- 爬虫及分类
- 网页组成之HTML
详细讲解
登陆注册联动mysql
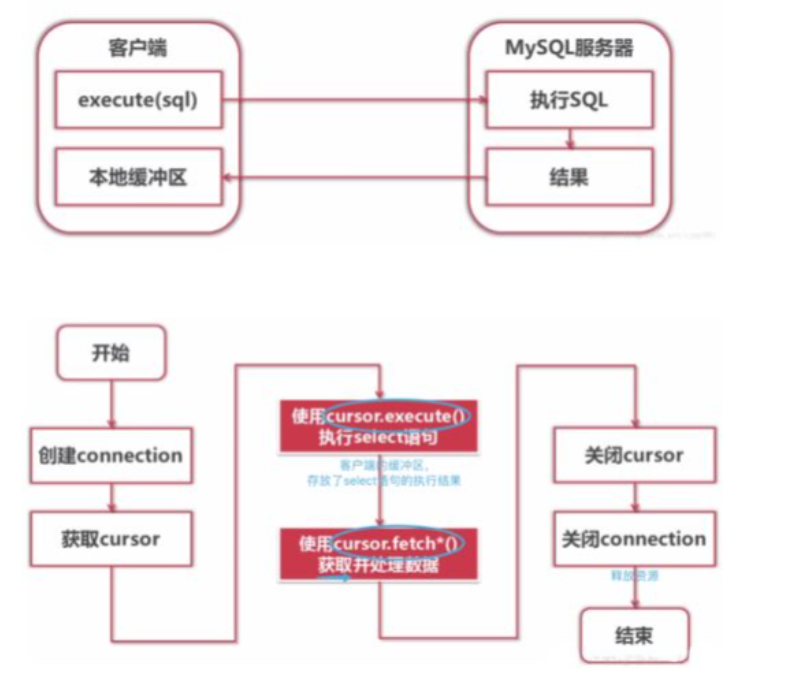
# 基于pymysql模块操作MySQL实现用户注册登录
'''简易版本(必会)'''
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='123',
db='db8',
charset='utf8',
autocommit=True
)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
def register():
# 1.获取用户数据
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 2.校验用户名是否已存在
sql = 'select * from userinfo where name=%s'
cursor.execute(sql, username)
res = cursor.fetchall()
if res:
print('用户名已存在')
else:
sql = 'insert into userinfo(name,password) values(%s,%s)'
cursor.execute(sql, (username, password))
print('%s注册成功' % username)
def login():
# 1.获取用户名和密码
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 2.检验是否存在当前用户
sql = 'select * from userinfo where name=%s'
cursor.execute(sql, username)
res = cursor.fetchall() # [{}]
if res: # 用户名存在
# 校验密码是否正确
user_dict = res[0]
if str(user_dict.get('password')) == password:
print('登录成功')
else:
print("密码错误")
else:
print('用户名不存在')
func_dict = {'1': register, '2': login}
while True:
print("""
1.注册
2.登录
""")
choice = input('choice>>>:').strip()
if choice in func_dict:
func_name = func_dict.get(choice)
func_name()
else:
print('命令不存在')
'''封装版本'''
import pymysql
def get_link():
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
passwd='123',
db='db8',
charset='utf8',
autocommit=True
)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
return cursor
def auth_user(cursor):
# 1.获取用户数据
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 2.校验用户名是否已存在
sql = 'select * from userinfo where name=%s'
cursor.execute(sql, username)
res = cursor.fetchall()
return username, password, res
def register(cursor):
username, password, res = auth_user(cursor)
if res:
print('用户名已存在')
else:
sql = 'insert into userinfo(name,password) values(%s,%s)'
cursor.execute(sql, (username, password))
print('%s注册成功' % username)
def login(cursor):
username, password, res = auth_user(cursor)
if res: # 用户名存在
# 校验密码是否正确
user_dict = res[0]
if str(user_dict.get('password')) == password:
print('登录成功')
else:
print("密码错误")
else:
print('用户名不存在')
func_dict = {'1': register, '2': login}
cursor = get_link()
while True:
print("""
1.注册
2.登录
""")
choice = input('choice>>>:').strip()
if choice in func_dict:
func_name = func_dict.get(choice)
func_name(cursor)
else:
print('命令不存在')
常见的数据收集网站
- 白嫖类(我的最爱)
百度指数:https://index.baidu.com/v2/index.html#/
用来看百度上的数据
比如一个词被搜索的频率 搜这个词还会搜什么等
新浪指数:https://data.weibo.com/index
新浪数据的汇总
用来搜各种各样的事件
国家数据:http://www.gov.cn/shuju/index.htm
就是国内的各式各样数据
GDP啦 人口啦什么的
世界银行:https://data.worldbank.org.cn/
国外网站比较客观
查看金融数据
纳斯达克:https://www.nasdaq.com/zh/market-activity
查看股票相关的数据
水太深别多想
联合国:http://data.un.org/
联合国数据
- 付费类
国内
艾瑞咨询:https://www.iresearch.com.cn/
国际
埃森哲:https://www.accenture.com/cn-zh
麦肯锡:https://www.mckinsey.com.cn/
第三方平台
数据堂:https://www.datatang.com/
贵阳大数据:http://gbdex.bdgstore.cn/
# 这种付费类的数据其实就是人工帮你再整合一下没啥花头
'''自己有实力完全能通过白嫖之后自己整理省钱'''
网络爬虫理论基础
# 了解爬虫之前要先进步了解互联网
1.什么是互联网?
简单来说互联网就是把成千上万的计算机都连在一起
像是一张巨大的网一样
2.互联网建立的核心目的?
目的就是为了能够让数据再各计算机之间共享
不然只能拿着u盘去别人电脑上拷贝
3.什么是上网?
上网其实就是从用户电脑发送请求给想要实现数据交互的目标计算
然后将目标计算机的数据下载到本地的过程
# 现在再来看看爬虫技术
4.爬虫要做什么?
爬虫就是通过代码来模拟网络请求获取数据并解析数据后保存下来
5.爬虫技术的价值?
互联网最有价值的就是数据,那我们可以把互联网看成一张巨大的蜘蛛网
所需的数据就是这张网上以及放置好的猎物,爬虫则是这张网上的小蜘蛛
小蜘蛛沿着蜘蛛网抓回自己想要的猎物
这样就能免费拿到最有价值的数据
'''爬虫学的好 牢饭吃到饱'''
这句话实际上很能体现出爬虫的价值

爬虫的分类
# 通用爬虫
搜索引擎用的爬虫系统
尽可能把互联网所有的网页下载放到本地服务器形成备份,再对这些网页做相关处理(提取关键字、去掉广告)最后给用户提供检索结果
1.搜索引擎如何获取一个网站URL
1.主动向搜索引擎提交网址
网址收录:https://ziyuan.baidu.com/site/index
2.在其他网址设置网站外链
3.与DNS服务商合作(DNS即域名解析技术)
简便获取ip地址:ping URL -t
2.通用爬虫并不是万物皆可爬需要遵循robots协议
协议内会指明可以爬取网页的那些部分(...百度快照...)
'''该协议一般只有大型搜索引擎会遵循'''
3.通用爬虫工作流程
爬取网页 存储数据 内容处理 提供检索及排名服务
排名:
1.PageRank值
根据网站的流量(点击、浏览、人气)统计
2.竞价排名
钞能力懂吧
# 聚焦爬虫
程序员写出来 为了爬取特定内容的爬虫
当然不能太老实 不然什么数据都获取不到

网页组成
'''
浏览器请求数据展示的界面其实内部对应就是一堆HTML代码
爬虫程序其实就是对这堆HTML代码做数据筛选
写好爬虫程序的第一步就是熟悉HTML代码基本组成
'''
HTML: 也是一种编程语言 超文本标记语言
鼠标右键检查可以看到源码
前端和后端
前端
所有用户看到的用上的都是前端范畴
只要是和用户打交道的都是 前端
后端
程序员编写的运行在程序内部不直接和用户打交道的程序代码
一般都是指程序员写的代码
# 前端三剑客
HTML 网页的骨架
CSS 网页的样式
JavaScript(JS) 网页的动态效果

HTML基本组成
网页文件后缀.html
# HTML语法结构
<html>
<head>
书写的一般都是给浏览器看的
比如样式颜色
</head>
<body>
书写的就是浏览器要展示给用户看的
</body>
</html>
# head内常见标签 爬虫不会爬这些了解即可
title 定义网页标题
style 内部直接书写css代码
link 引入外部css文件
script 内部可以直接书写js代码也可以引入外部js文件
meta 定义网页源信息 就是别人通过搜索什么能找到这个网页
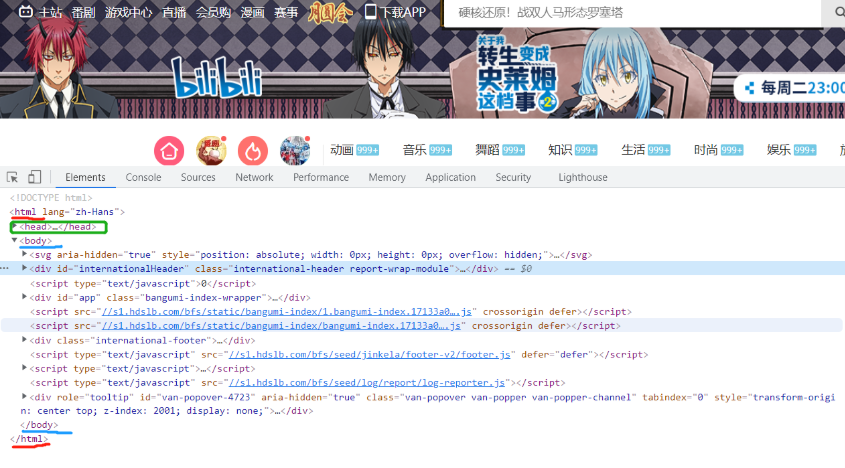
body内常见标签
# 双标签:
有两个组成一个完整的标签
<a></a> 超链接
<p></p> 行标签
<h1></h1> 一级标题数字不同等级越低最小到6
<u></u> 下划线
<s></s> 删除线
<i></i> 倾斜
<b></b> 加粗
# 单标签 又叫自闭和标签
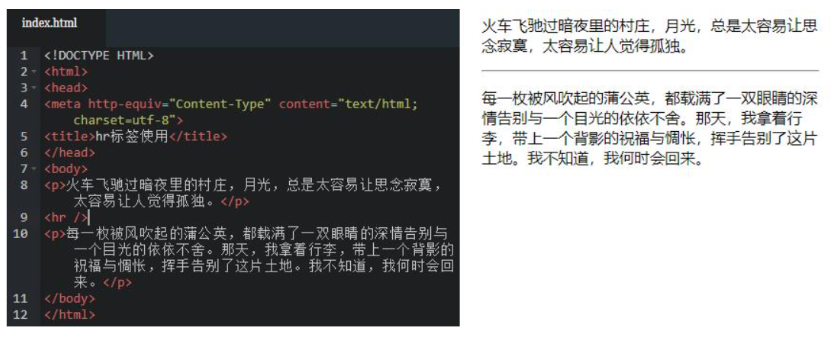
<img/> 插入图片
<hr> 水平线
<br> 换行符