8/19
今日考题
1.函数的种类有哪些
1.无参函数 2.有参函数 3.空函数
2.函数返回值特点
默认返回是none # 也就是说和函数外的程序没有交互关系
经过return可以返还到函数外 return后面是什么就返还什么不写也是none # 变量名 = 函数名() 就可以拿到返还值
3.函数参数种类及特征
位置参数:规定几个就几个 不能多也不能少
关键字参数: 给形参根据 关键字 = 变量 的方式传参数,无所谓位置,但是不能出现现在位置参数前面
默认参数: 直接在定义阶段就赋值赋好,默认就是所赋的值,但是后面调用如果重新输入可以修改
可变长参数: 位置参数通过*接收,多的信息会变成元组赋值给后面 关键字参数通过**接收,多的元素会变成字典赋值
4.列举几个常见内置函数
abs 绝对值
bin oct hex 二进制 八进制 十六进制
callable 是否可调用
chr 对应ascii码里的数字
format 字符串格式化输出
max min sum 最大 最小 合计
复习巩固
- 函数定义和调用的注意事项
函数在执行阶段只检测语法不执行代码
函数的调用需要函数名加括号 如果需要参数则额外给参数
函数名可以简单理解为变量名 指向内存空间中函数体代码所在
- 函数的种类
无参函数
有参函数
空函数
- 函数的返回值
关键字return
1.可以返回 返回值
2.结束函数的运行
1.函数体代码没有return默认返回none 代码管代码跑和返回值无关
2.函数体代码有return那么后面有什么就返回什么
3.如果后面跟了多个值则组织成元组的形式返回
- 函数的参数
'''
形式参数
函数定义阶段括号内写的变量名 简称形参 类似于变量名
实际参数
函数调用阶段括号内写的值 简称实参 类似于变量的值
函数调用阶段形参和实参临时绑定 函数运行结束立即断开
'''
1.位置参数
按照位置一一传值 多一个不行少一个也不行
2.关键字参数
指名道姓的传 可以打破位置顺序 但是不能在位置参数前
3.默认参数
函数定义阶段就给形参赋值好
调用阶段如果不传就用默认的 传了则使用自己的
4.可变长参数
在形参中使用*和**来接收多余的位置参数和关键词参数
* 通过组成元组接收位置参数
** 通过组成字典接收关键字参数
从而赋值给后面的变量名
'''
在实参中*可以打散列表或元组 把他们组成位置参数
在实参中**可以打散字典 把他们组成关键字参数
'''
- 函数的实战演练
前期不熟练的时候请参考一下步骤封装
1.先写功能主体代码
2.定义函数将主体代码缩进
3.查看主体所需数据 在形参中指定出来
4.后续调用传入指定数据即可
- 常见的内置函数
abs bin oct hex max min sum chr callable 等
- 函数封装自做精进版
def sign():
name = input('请输入注册的用户名>>>:').strip()
pwd = input('请输入您想要的密码>>>:').strip()
return name, pwd
def check(name):
with open(r'users.txt', 'r', encoding='utf8') as f:
for line in f: # 3.这边读取就做好了
# 4.接下来就要把每行的数据拖出来拆分比对
if name == line.split('|')[0]: # 5.分割成列表之后取第一个数据循环比对
return False
# 先定义函数做注册部分
def register():
# 1.首先肯定获取用户名密码
name, pwd = sign()
# 2.获取之后要先去比对文本数据肯定先要以只读打开
check(name)
if check(name) is False:
print('用户名已存在')
return
# 6.写入信息
with open(r'users.txt', 'a', encoding='utf8') as g:
# 7.打开后写入
g.write('%s|%s|\n' % (name, pwd)) # 所有数据之间用|分开方便分割
print('%s注册成功' % name) # 提示注册成功
# 7.这边注册就结束了
# 然后做登录部分的封装
def login():
# 8.登录那还是一样先获取用户名密码
name, pwd = sign()
# 9.获取之后去一一比对
with open(r'users.txt', 'r', encoding='utf8') as h:
for line in h: # 先一行行读取leo|123|\n
# 10.然后拿出前两项比对
if name == line.split('|')[0] and pwd == line.split('|')[1]:
print('登录成功')
return # 登录上了就结束函数
print('用户名或密码错误')
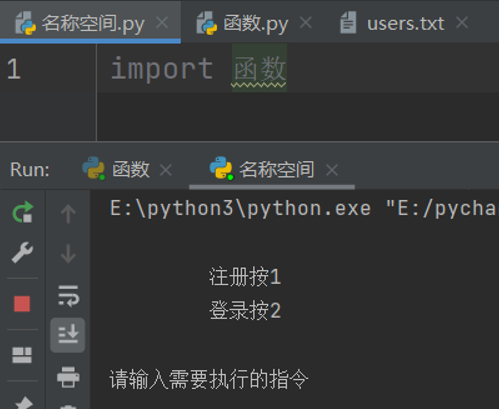
while True:
print(
'''
注册按1
登录按2
'''
)
start = input('请输入需要执行的指令')
if start == '1':
register()
elif start == '2':
login()
else:
print('您输入的指令有误')
内容概要
- 函数名称空间与作用域
- 匿名函数与列表生成式等知识补充(重要)
- 模块
白嫖别人的劳动成果 B站用户狂喜
- 常见内置模块
详细讲解
名称空间与作用域
名称空间
存放变量与值绑定关系
1.内置名称空间
python解释器启动立刻创建 结束立刻销毁
2.全局名称空间
伴随python
3.局部名称空间
# 加载顺序: 内置名称空间 > 全局名称空间 > 局部名称空间
总归构建整体的时候是要从打到小的
'''作用域'''
顾名思义就是作用所能覆盖的区域
全局作用域
内置姓名空间 全局名称空间
局部作用域
局部名称空间
作用域的查找顺序是要先明确你当前的所在位置
然后从你所在位置一步步向外找
顺序只能是先找 局部名称空间 >> 全局名称空间 >> 内置名称空间
# 如果想在局部修改全局名称空间中的名字对应的值可以使用global关键字
count = 1
def index():
global count
count += 1
index()
这段代码可以说是典型案例
这里面count += 1这段就等价于count = count + 1
那局部名称空间已经构建好了但是这边count加一所要加的原来的count变量名在这个局部之外
所以如果没有global的介入就会报错
小练习
name = 'jack'
def func1():
name = 'jason'
def func2():
name = 'kevin'
def func3():
name = 'tony'
func1()
func2()
func3()
print(name) # 分别打出 jason kevin tony
# 这个比较简单 就是在构建局部名称空间的时候构建了三个同级的名称空间 然后他们在函数里被调用直接就能在他们本身的局部找到
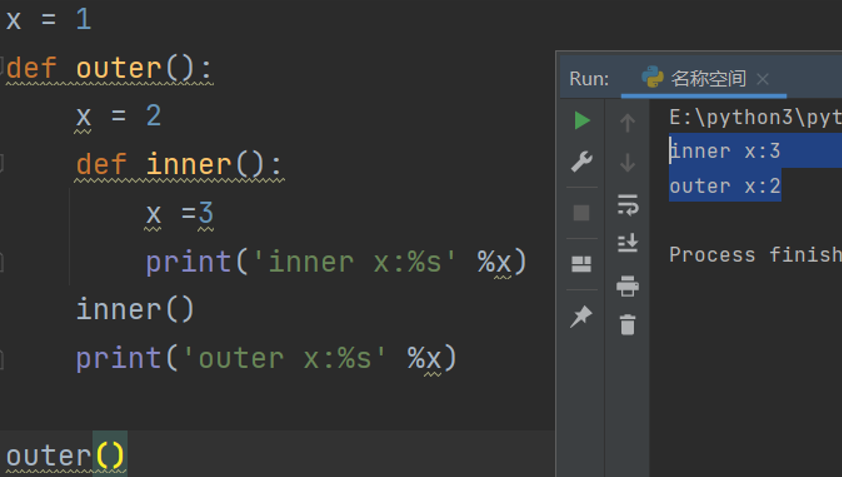
x=1 # 1
def outer(): # 2
x=2 # 4
def inner(): # 5
x=3 # 8
print('inner x:%s' %x) # 9
inner() # 6
print('outer x:%s' %x) # 7
outer() # 3
# 这部分比较复杂,不过别着急先看代码运行的过程
输出顺序是先输出9再输出7,但是代码名称空间的顺序是按照标号的顺序走的
所以前一个x是出现在outer这个局部内的局部inner所赋值的三
后一个是outer中赋值的2
答案是:
inner x:3
outer x:2
匿名函数
匿名函数
即没有函数名的函数
语法结构
lanbda 形参:返回值
# 匿名函数一般不单独使用 需要结合内置函数/自定义函数等一起使用
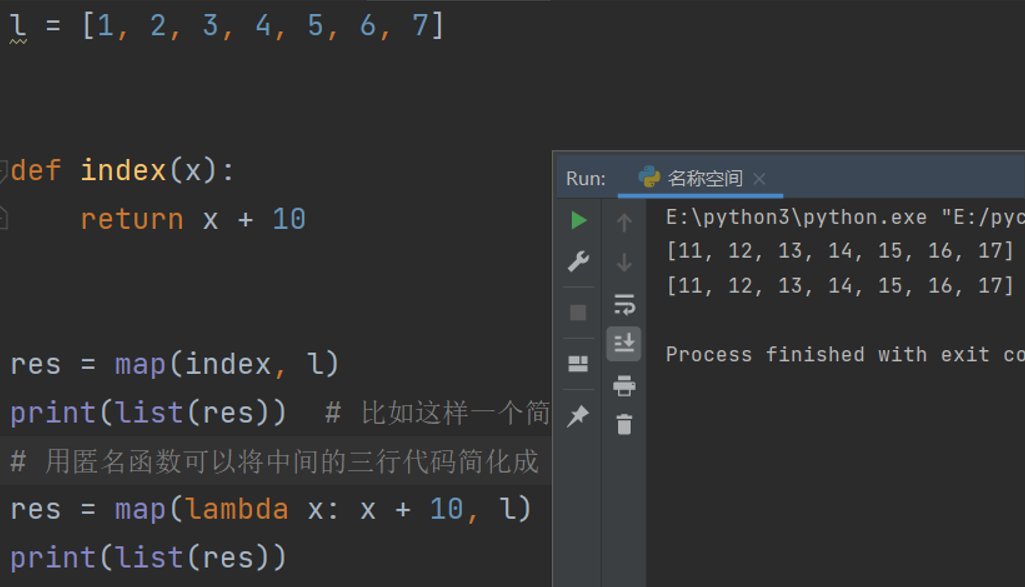
l = [1, 2, 3, 4, 5, 6, 7]
def index(x):
return x + 10
res = map(index,l)
print(list(res)) # 比如这样一个简单的列表里元素加10
# 用匿名函数可以将中间的三行代码简化成
res = map(lambda x: x + 10, l)
列表生成式
l1 = [11, 22, 33, 44, 55, 66, 77, 88]
# 要求:将列表中每个元素加1
# 最基础的办法就用for循环嘛
new_list = []
for i in l1:
new_list.append(i+1)
print(new_list)
# 列表生成器可以简化这部分代码
new_list = [i + 1 for i in l1]
'''
先写for i in l1把原列表的元素循环取出
然后前面加i + 1 说明放进新列表的是取出来的i加了1的
'''
name_list = ['jason', 'kevin', 'tony', 'oscar']
# 要求:将列表每个元素后面加上_NB的后缀
# 一样先是基础的for循环
new_list = []
for name in name_list:
new_list.append(name + '_NB')
print(new_list)
# 然后用列表生成器简化
new_list = [i + '_NB' for i in name_list]
# 那再复杂一点
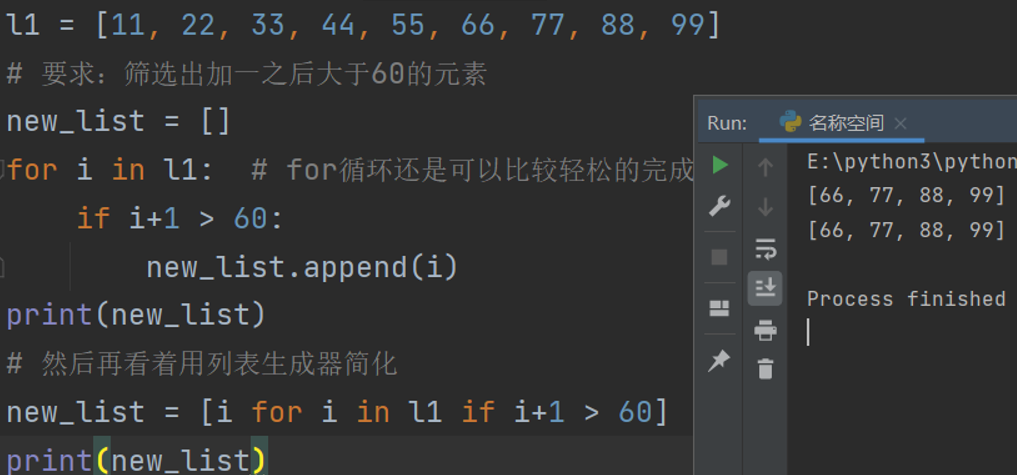
l1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
# 要求:筛选出加一之后大于60的元素
new_list = []
for i in l1: # for循环还是可以比较轻松的完成
if i+1 > 60:
new_list.append(i)
print(new_list)
# 然后再看着用列表生成器简化
new_list = [i for i in l1 if i+1 > 60]
print(new_list)
补充
当if子代码只有一行的情况下可以把if的子代码放到与if同行
不过不推荐使用别人看起来的时候逻辑可能看混
比如:
name = 'leo'
if name == 'leo':print('right')
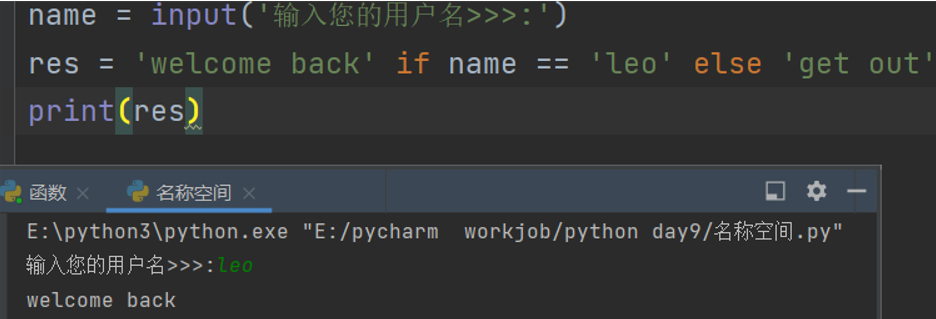
三元表达式
name = input('输入您的用户名>>>:')
if name == 'leo':
print('welcome back')
else:
print('get out')
# 像上述这种if判断结果仅有两种的情况推荐使用三元表达式
# 后面四行代码直接拦腰缩短
name = input('输入您的用户名>>>:')
res = 'welcome back' if name == 'leo' else 'get out'
print(res)
# 三元表达式的语法结构
A if 条件 else B
当if后面的条件为True的时候使用A
为False使用else后面的B
模块的入门
# 什么是模块与包
具有一定功能的代码集合
可以是py文件 也可以是多个py文件组成的文件夹(包)
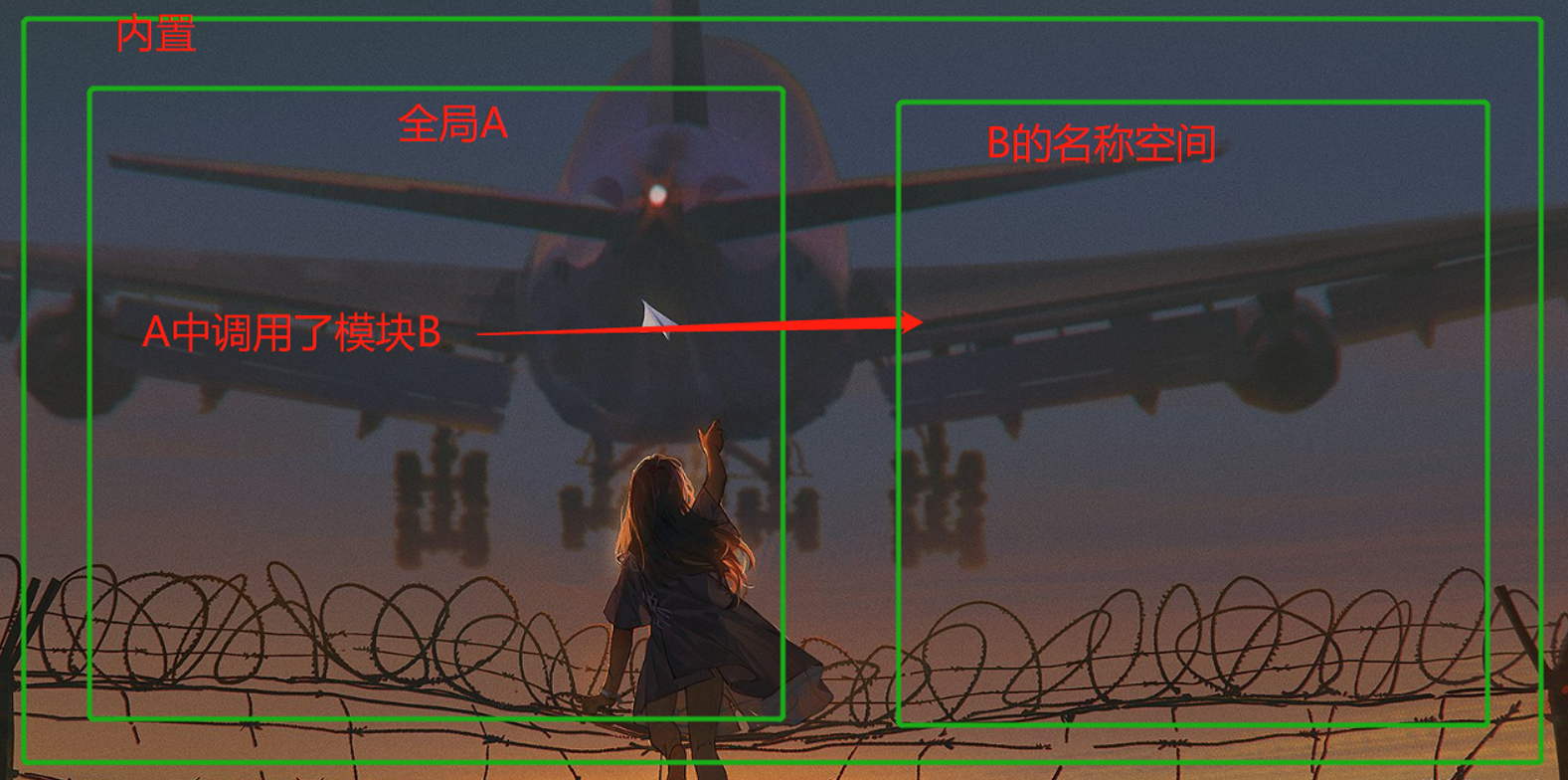
# 导入模块的本质
会执行模块内代码并且产生一个该模块的名称空间
将代码执行过程中的名字存放在该名称空间中
然后给导入模块的语句一个模块名 该模块指向模块的命名空间
模块使用
经过上面的图解大概也对模块有了个基本的认识
那也就不难理解'重复导入相同模块为什么只会执行一次'
# 都划分好地方了再运行你还要再划分python解释器大爷直接不同意给你优化了
import 模块名
可以通过模块名点出所有的名字
用函数名.就能拿到提示
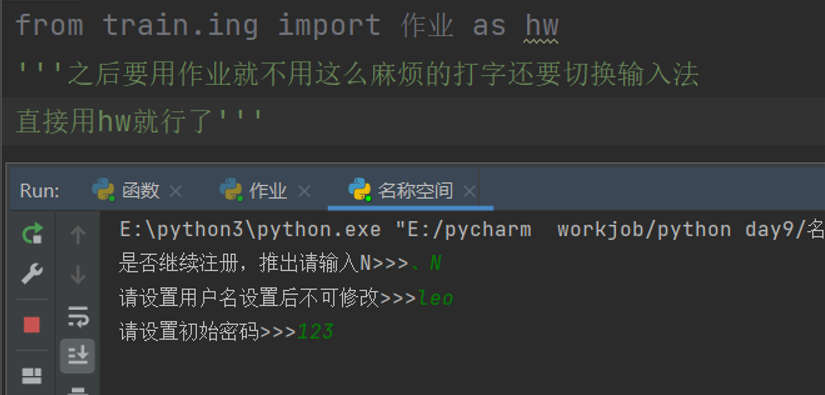
from 模块名 import 子名1,子名2
只能指名道姓的使用import后导入的子名并且还存在冲突的风险
# 那from就没用了嘛?
from最大的用处在于可以取到不在同一路径下的文件
# 这两种调用方式都可以接as给调用的程序起别名方便找到
import 函数 as func
内置模块之时间
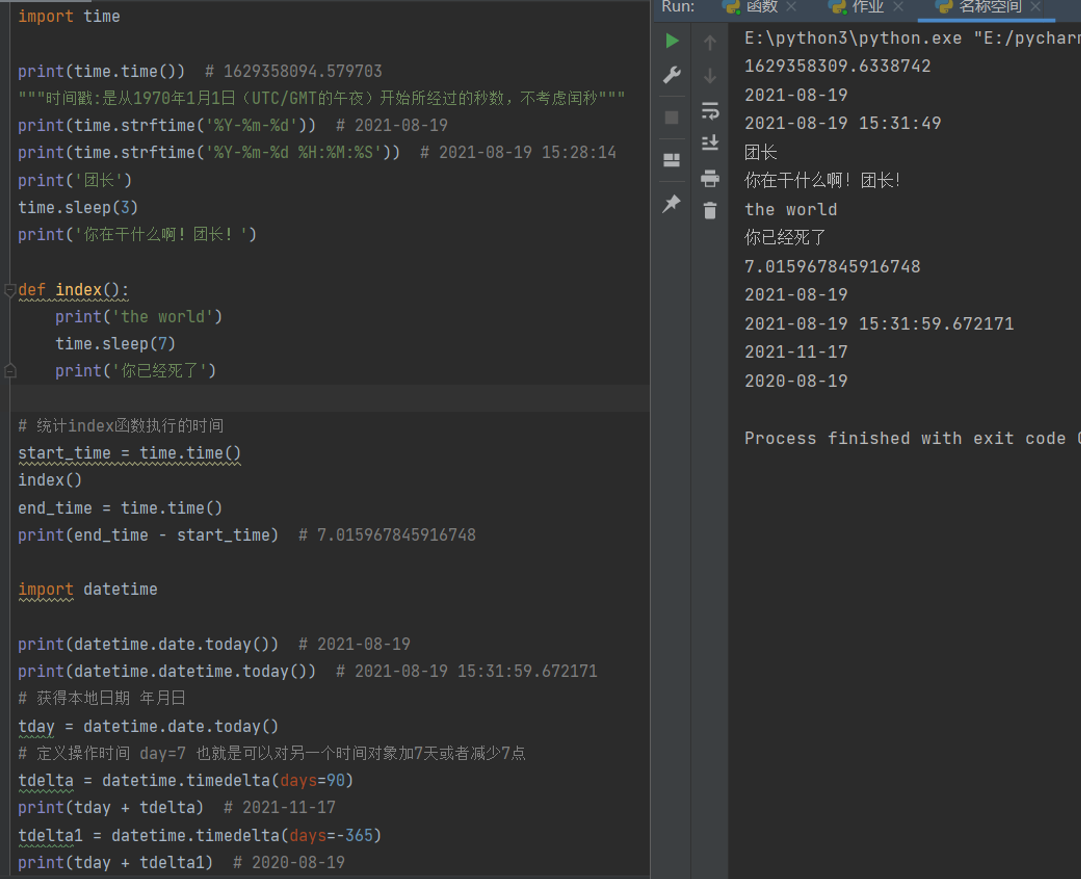
import time
print(time.time()) # 1629358094.579703
"""时间戳:是从1970年1月1日(UTC/GMT的午夜)开始所经过的秒数,不考虑闰秒"""
print(time.strftime('%Y-%m-%d')) # 2021-08-19
print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2021-08-19 15:28:14
print('团长')
time.sleep(3)
print('你在干什么啊!团长!')
def index():
print('the world')
time.sleep(7)
print('你已经死了')
# 统计index函数执行的时间
start_time = time.time()
index()
end_time = time.time()
print(end_time - start_time) # 7.015967845916748
import datetime
print(datetime.date.today()) # 2021-08-19
print(datetime.datetime.today()) # 2021-08-19 15:31:59.672171
# 获得本地日期 年月日
tday = datetime.date.today()
# 定义操作时间 day=7 也就是可以对另一个时间对象加7天或者减少7点
tdelta = datetime.timedelta(days=90)
print(tday + tdelta) # 2021-11-17
tdelta1 = datetime.timedelta(days=-365)
print(tday + tdelta1) # 2020-08-19