
8/17
今日考题
1.阐述字符编码由来及发展史
计算机内部只有高低电频两种状态经过人为定义也只看得懂二进制
那要把人才能看懂的语言翻译成对应的二进制数的'密码本'就是字符编码
美国发明的计算机那第一种字符编码由美国发明讲述英文和数字与二进制数的对应关系
之后各国编码群雄割据
最后天下一统unicode万国码的出现让所有语言通用>>>经过优化变成现在用的utf8
2.编码与解码理论,python代码如何实现
.encode # 编码
.decode # 解码
3.文件操作语法结构及读写模型,操作模式细节
大模式分为t模式 #只能对文本进行操作
和b模式 # 一切都能操作
两大类下都有三种
r只读 w只写 a只加
在t模式下操作
with open(r'文件所在路径','需要打开的模式',encode='utf8') as f:
# 路径前面的r是为了防止路径中的\与字母的组合引起计算机误会而找不到文件反正加上就行
在b模式下操作代码更简单但是打开后是看不懂的
with open(r'文件路径','操作模式结尾跟上b不加默认是t') as f:
复习巩固
- 字符编码文件
计算机只能识别二进制数据,而用户在使用计算机输入文本的时候却可以展示各种国家的文字
人类字符 转化 二进制数字
# 字符编码
内部记录了人类字符与数字之间的对应关系
# 国内电脑默认的字符编码是GBK
# 字符编码的发展史
1.一家独大
ASCII码 记录了英文字符和数字的对应关系
8bit(1bytes) 对应一个字符
# 所有英文符号加起来不超过127种7bit就能表示128种了
那为什么要用8bit呢
多一位备用
单位换算更方便
2.群雄割据
GBK码
记录了英文中文对应数字的关系
英文字符还是用8bit表示
16bit(2bytes) 表示中文字符
# 有生僻字需要更多的bit来表示
有时候要用到3bytes甚至4bytes
3.天下一统
unicode码(万国码)
兼容万国,所有字符全部16bit(2bytes)起步表示
但是这样会让英文字符的存储空间翻倍 效率变低
utf8(unicode优化版本)
英文采用8bit来存储
中文用24bit(3bytes)存储
# 结论
1.目前所有的文本文件默认的编码都是utf8
2.解决乱码的核心就是以什么编码编的后续就以什么编码解
- 编码与解码
编码 人类字符转计算机二进制
# 在python中只有字符串类型可以编码
''.encode('utf8') # bytes类型直接看成二进制即可
ps :如果字符串是纯英文和数字可以简写
b'hello world'
解码 二进制转人类字符
# bytes类型才能解码
b'hello world'.decode('utf8')
"""
数据基于网络传输格式只能是二进制
如果我们想把数据基于网络发送出去 那么必须先对这个数据进行编码
"""
- 文件操作基本语法
with open(r文件路径,模式,编码) as 变量名:
子代码块
# 打开多个文件可以简写
with open(文件路径,模式,编码) as 变量名1,open(文件路径,模式,编码) as 变量名2:
子代码块
- 文件操作读写模式
r
就是read只读不写 文件路径不存在直接报错
路径存在则打开并且光标在文件开头
w
即write 文件路径不存在会去自动创建
文件存在会清空原文件内容再写入 # 注意会清空原文件
a
即append添加写 文件路径不存在也会自动创建
存在的话光标直接移动到文件末尾 # 注意是末尾但是不会换行的
- 文件操作的操作模式
t模式 只能操作文本 然后参数要加编码的那个
b模式 二进制操作模式 什么都能操作但是打开的话看不懂
内容概要
- 作业讲解
- 文件操作补充
- 函数(很重要)
函数定义
函数参数
详细讲解
作业讲解
1.利用文件操作编写一个简易的文件拷贝系统
让用户输入需要拷贝的文件路径
然后再获取即将拷贝到哪儿的路径
老师的代码
#1.获取文件路径
source_file_path = input('source_path>>>:').strip()
# 2.在获取目标地址路径
target_file_path = input('target_path>>>:').strip()
# 3.打开源文件读取内容
# 4.创建新文件并写入内容
with open(r'%s' % source_file_path, 'rb') as read_f, open(r'%s' % target_file_path, 'wb') as write_f:
# 循环读取文件内容避免出现内存溢出的情况
for line in read_f:
write_f.write(line)
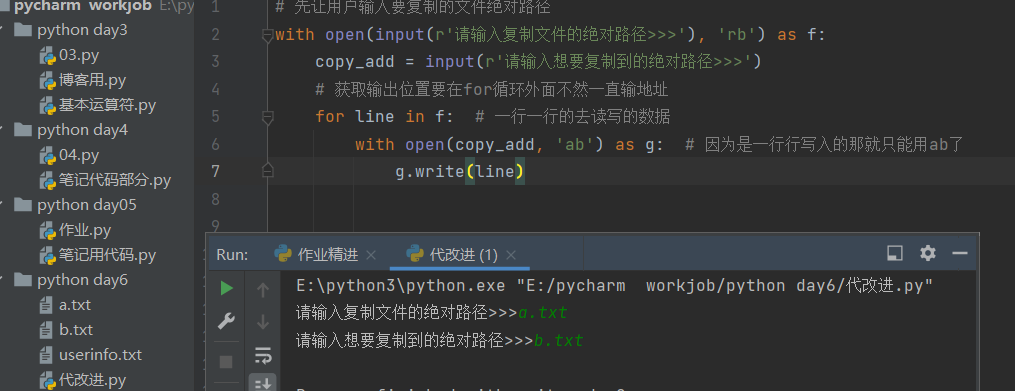
我自己做的(由于比较简单没什么多说的)
# 先让用户输入要复制的文件绝对路径
with open(input(r'请输入复制文件的绝对路径>>>'), 'rb') as f:
copy_add = input(r'请输入想要复制到的绝对路径>>>')
# 获取输出位置要在for循环外面不然一直输地址
for line in f: # 一行一行的去读写的数据
with open(copy_add, 'ab') as g: # 因为是一行行写入的那就只能用ab了
g.write(line)
第二题
2.利用文件操作完成用户的注册 登录
userinfo.txt
基本要求
用户注册获取用户名和密码然后写入文件 jason|123
登录获取用户名和密码之后去文件中比对
# 上述操作完成一次就算成功
拔高练习
用户注册可以多次注册并且校验用户名是否重复
登录需要逐行比对
前一天花了好久自己想的
# 9.注册界面要循环而且不是取值别多想先怼上定式
while True: # 10.然后整个注册界面肯定是子代码先缩进
# 11.先设定一个参数用作叫停循环
register = input('是否继续注册,推出请输入N>>>')
if register == 'N': # 12.输入为N停止循环
break # 13.直接退出注册往下去登录
else: # 14.别的情况都要注册
# 1.反正肯定是要先获取用户数据的
user_name = input('请设置用户名设置后不可修改>>>').strip()
password = input('请设置初始密码>>>').strip()
# 15.现在要和前面注册的做个比对 和密码比对时候方法一致
with open(r'userinfo.txt', 'r', encoding='utf8') as h:
for line in h:
user_list1 = line.split('|')
if user_list1[0] == user_name:
print('用户名已存在请重新输入')
break
# 2.获取之后用一个文件保存既然之后要多次注册就要能加进去所以用ab做
with open(r'userinfo.txt', 'ab') as f:
f.write(user_name.encode() + '|'.encode() + password.encode())
f.write('|\n'.encode()) # 3.加换行符这样后面输入的就能逐行找
# 4.这样用户名密码就注册好了 下一步要登录也是先获取用户名密码
user_name_log = input('请输入登录用户名>>>')
password_log = input('请输入登录密码>>>')
# 5.下一步要比对文件里的数据首先要一行一行取值
with open(r'userinfo.txt', 'r', encoding='utf8') as g:
for line in g: # 6.取值完要单拿出用户名
user_list2 = line.split('|') # 7.把取到的字符串按|分隔成列表
if user_list2[0] == user_name_log and user_list2[1] == password_log: # 8.比对两者都一致
# 前面两步可以用解压赋值加分裂一步完成
print('登录成功')
break
else: # 注意这里缩进的位置是和for循环平齐的这样for结束之后才运行这个else
print('用户名或密码错误')
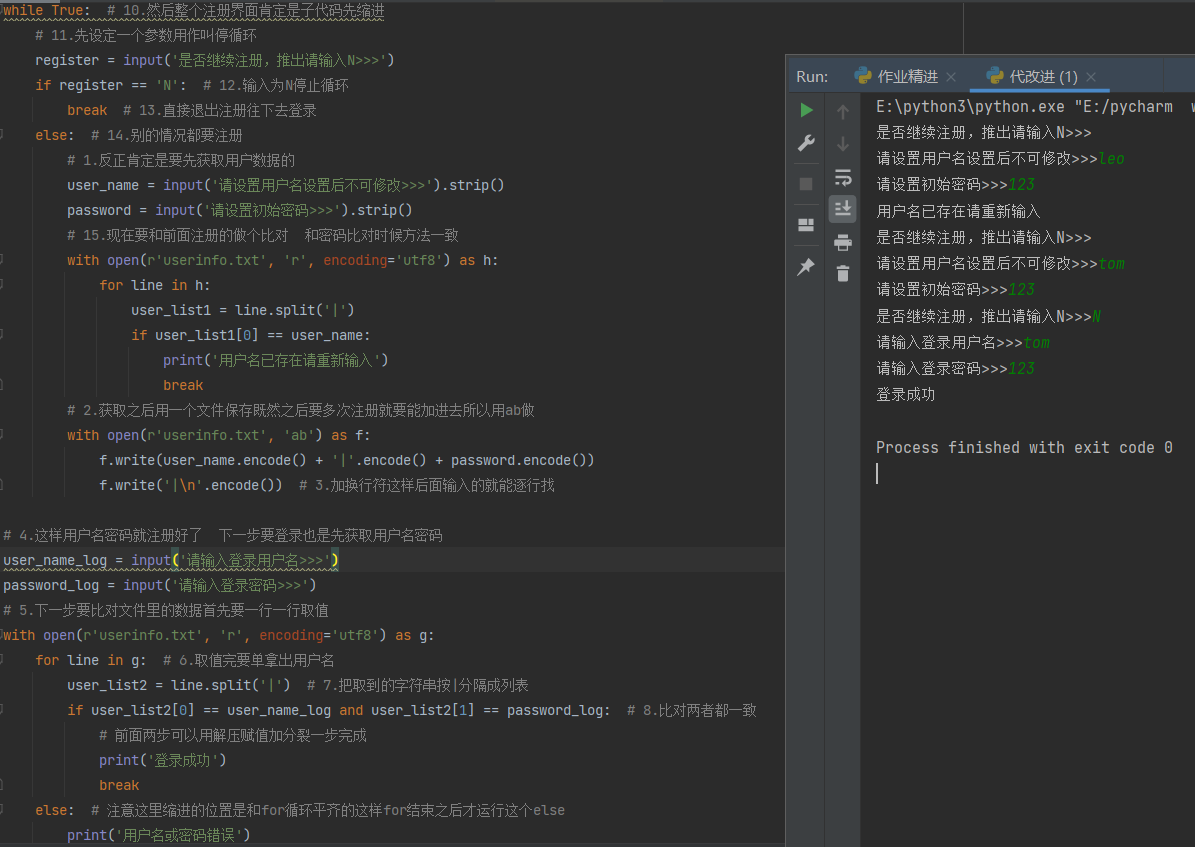
老师课上的操作
#简易版本
while True:
print("""
1.注册
2.登录
""")
choice = input('请选择想要执行的功能>>>:').strip()
if choice == '1':
# 注册功能
# 1.获取用户用户名和密码
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 2.打开文件直接写入
with open(r'userinfo.txt', 'w', encoding='utf8') as f:
f.write('%s|%s' % (username, password))
print('%s注册成功' % username)
elif choice == '2':
# 登录功能
# 1.获取用户用户名和密码
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 2.读取文件内容比对用户名和密码是否正确
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
# 由于目前文件内容就一行 可以直接使用read方法
data = f.read() # jason|123
# 切割字符串 获取正确的用户名和密码
real_name, real_pwd = data.split('|')
# 先切割字符串得到一个列表['jason','123'] 在解压赋值给两个变量real_name real_pwd
# 比对信息是否正确
if real_name == username and real_pwd == password:
print('登录成功')
else:
print('用户名或密码错误')
else:
print('输入不合法 暂时没有该功能')
################################################################################################
# 1.获取用户名和密码
flag = True
while flag:
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 2.先读取文件内容 校验用户名是否重复
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
# 循环读取每一行用户数据
for line in f: # 'jason|123' 'kevin|123'
# 解析出用户名
real_name = line.split("|")[0]
# 判断用户名是否重复
if real_name == username:
print('用户名已存在')
# for也可以结合break和continue作用与while一致
# 结束整个注册功能
flag = False
if flag:
# 如果for循环正常执行完毕没有被break 说明用户名没有冲突
with open(r'userinfo.txt', 'a', encoding='utf8') as f:
f.write('%s|%s\n' % (username, password))
print('%s注册成功' % username)
# 登录
# 1.获取用户名和密码
username = input('username>>>:').strip()
password = input('password>>>:').strip()
# 2.读取文件内容 循环获取一行行用户数据
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
for line in f:
real_name, real_pwd = line.split("|")
if username == real_name and password == real_pwd.strip('\n'):
print('登录成功')
break
else: # for循环没有被break打断的情况下正常执行完毕之后就会执行else
print('用户名或密码错误')
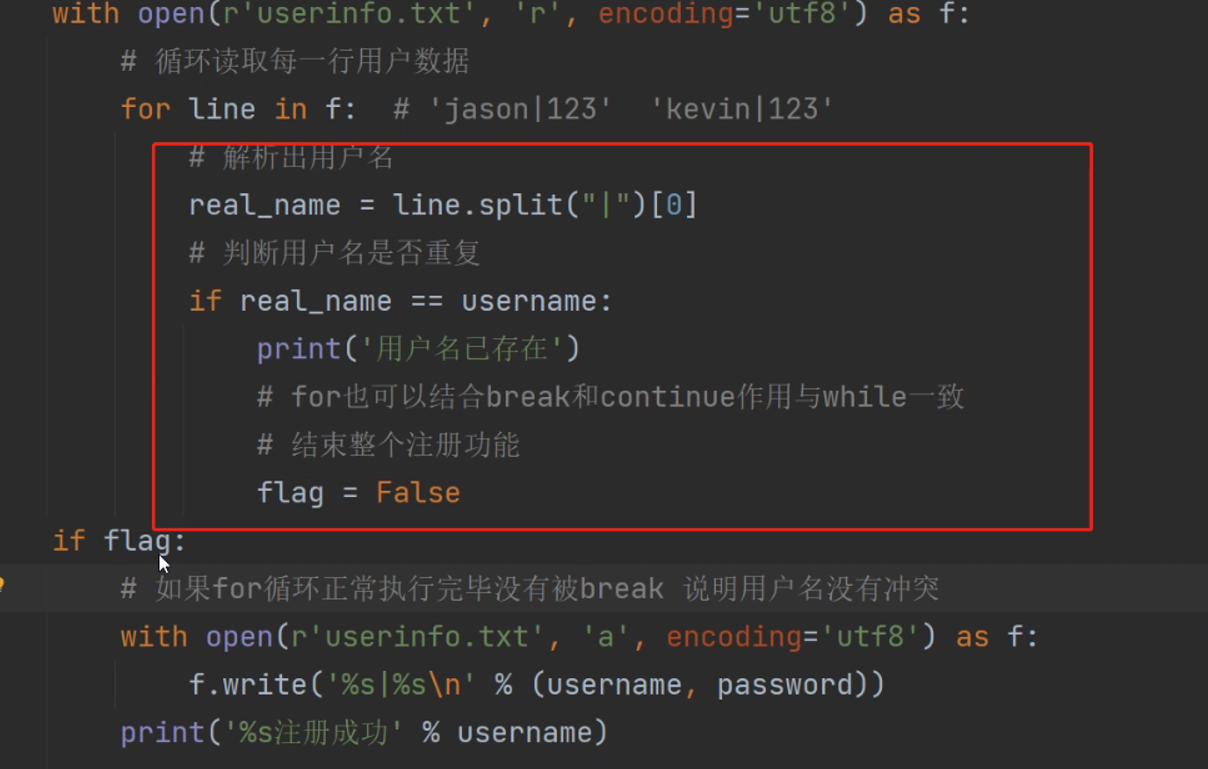
根据老师的思路再重新打一次
flag = True
while flag:
# 1.首先肯定获取用户名密码
reg_name = input('请输入注册的用户名>>>:').strip()
reg_pwd = input('请输入您想要的密码>>>:').strip()
# 2.获取之后要先去比对文本数据肯定先要以只读打开
with open(r'users.txt', 'r', encoding='utf8') as f:
for line in f: # 3.这边读取就做好了
# 4.接下来就要把每行的数据拖出来拆分比对
if reg_name == line.split('|')[0]: # 5.分割成列表之后取第一个数据循环比对
print('用户名已存在') # 这边老师讲的是重复就直接退出
# 具体怎么循环再说现在来看写入的功能
flag = False # 加了来跳出循环
if flag:
# 6.写入信息
with open(r'users.txt', 'a', encoding='utf8') as g:
# 7.打开后写入
g.write('%s|%s|\n' % (reg_name, reg_pwd)) # 所有数据之间用|分开方便分割
print('%s注册成功' % (reg_name)) # 提示注册成功
# 7.这边注册就结束了
# 8.登录那还是一样先获取用户名密码
user_name = input('请输入您的用户名>>>:')
password = input('请输入密码>>>:')
# 9.获取之后去一一比对
with open(r'users.txt','r',encoding='utf8') as h:
for line in h: # 先一行行读取leo|123|\n
# 10.然后拿出前两项比对
if user_name == line.split('|')[0] and password == line.split('|')[1]:
print('登录成功')
break # 这个break打断循环也能让后面的else跟着不用再跑过去
# 11.1其他情况就是有东西不对,那也就是等整个for循环跑完都没遇到对应上是数据
# 11.2既然要等for跑完再说那么这个else就应该写在for循环的外面,和他同级
else:
print('用户名或密码错误')
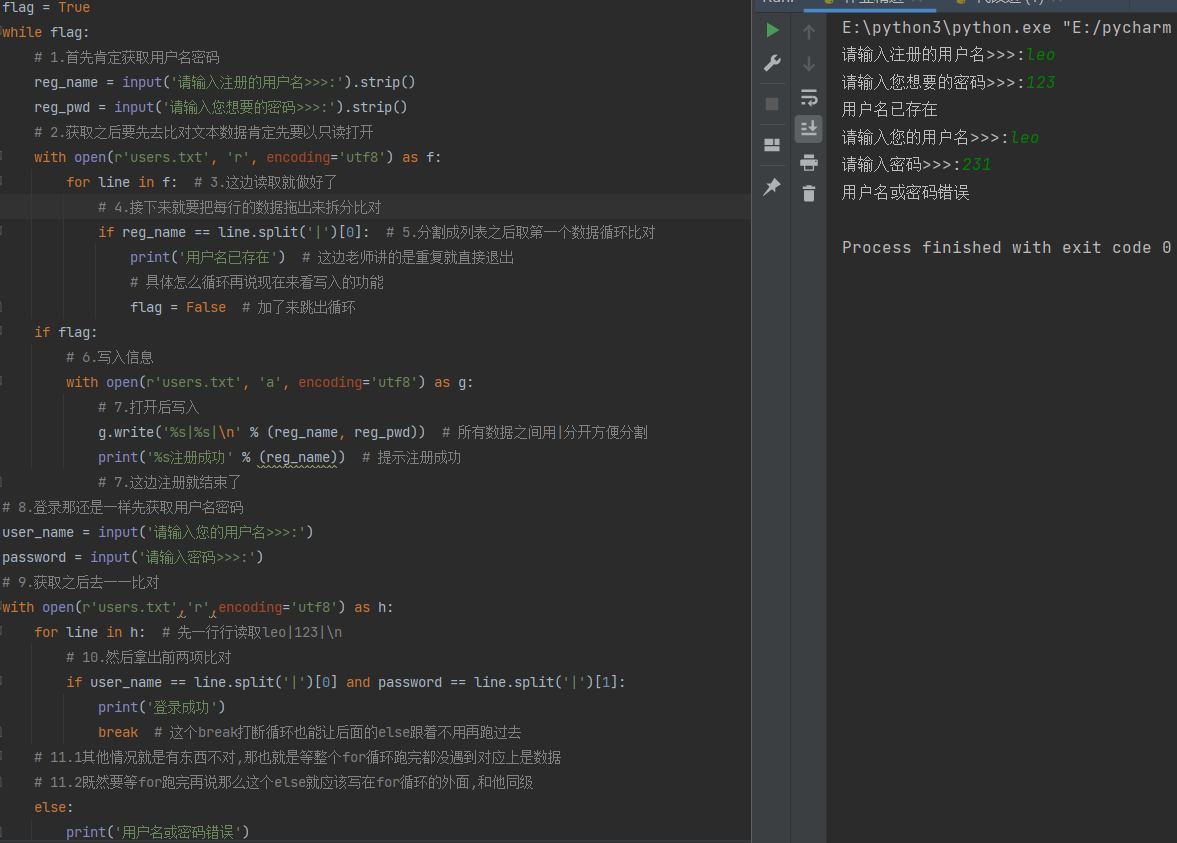
文件操作补充
# 关键词补充
with open(r'users.txt', 'r', encoding='utf8') as f:
# f.flush() # 将内存里数据刷进硬盘 相当于ctrl + s
# f.writable() # 是否可写 输出是布尔值
# f.readable() # 是否可读 输出是布尔值
f.writelines() # 括号内放任何元素(比如列表) 元素会被一个个拿出来依次写入一行里
光标移动
'''
.seek方法可以控制光标移动
seek(offset,whence)
offset用来控制移动的位数
whence是操作模式,只有三个参数
0: 文件开头 t,b模式通用
1: 当前位置 b模式才行
2: 文件末尾 b模式才行
'''
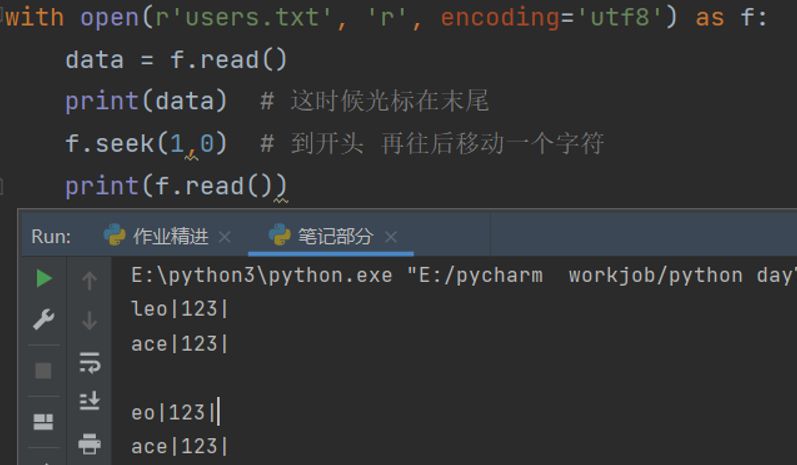
with open(r'users.txt', 'r', encoding='utf8') as f:
data = f.read()
print(data) # 这时候光标在末尾
f.seek(1,0) # 到开头 再往后移动一个字符
print(f.read())
# 下面是在二进制模式下操作
with open(r'users.txt', 'rb') as f:
data = f.read(10) # 这边数字代表光标读几个bytes
print(data.decode('utf8'))
f.seek(-5,2) # 从末尾向前移动3个bytes
print(f.read().decode('utf8'))
# 二进制模式下记得遇上一些中文或者特殊符号移动光标的数字要当心,别把字符从中间分割了
文件修改
# 文件修改 目前能用的方法
with open(r'users.txt', 'r', encoding='utf8') as f:
data = f.read()
with open(r'users.txt.txt', 'w', encoding='utf8') as f:
f.write(data.replace('leo', 'ace'))
# 本质是全部读出来然后再把源文件清空后重新写入
'''
方法二现在先了解之后会学
'''
import os
with open(r'a.txt','r',encoding='utf8') as f,open(r'a.txt.backend','w',encoding='utf8') as f1: # 打开两个文件
for line in f: # 一行行读源文件
f1.write(line.replace('tony','jason')) # 把源文件里面要修改的部分一行行改好写入另一个文件
os.remove(r'a.txt') # 把源文件删掉
os.rename(r'a.txt.backend',r'a.txt') # 把准备好的另一个文件重命名成源文件的样子
函数
函数就相当于是工具
提前定义好之后后续可以反复使用,避免了代码冗余的情况 类似于网页制作里面的模板,反正就是很方便
函数语法结构
def 函数名(参数1,参数2):
'''函数注释这个很重要哦,要解释函数干嘛用的'''
函数体代码
return 函数的返回值
'''
1.def 定义函数的关键字
2.函数名 和变量名一样的命名要求和规范
3.参数 使用前可以接收外部传入的参数
4.函数注释 就是写给函数的说明书
5.函数体代码 函数的主要逻辑 是函数的核心部分
6.return 执行完函数之后可以给调用者一个反馈结果
'''
# 函数切记要先定义好才能用
函数练习
注册功能封装
def register():
# 9.注册界面要循环而且不是取值别多想先怼上定式
while True: # 10.然后整个注册界面肯定是子代码先缩进
# 11.先设定一个参数用作叫停循环
reg = input('是否继续注册,推出请输入N>>>')
if reg == 'N': # 12.输入为N停止循环
break # 13.直接退出注册往下去登录
else: # 14.别的情况都要注册
# 1.反正肯定是要先获取用户数据的
user_name = input('请设置用户名设置后不可修改>>>').strip()
password = input('请设置初始密码>>>').strip()
# 15.现在要和前面注册的做个比对 和密码比对时候方法一致
with open(r'userinfo.txt', 'r', encoding='utf8') as h:
for line in h:
user_list1 = line.split('|')
if user_list1[0] == user_name:
print('用户名已存在请重新输入')
break
# 2.获取之后用一个文件保存既然之后要多次注册就要能加进去所以用ab做
with open(r'userinfo.txt', 'ab') as f:
f.write(user_name.encode() + '|'.encode() + password.encode())
f.write('|\n'.encode()) # 3.加换行符这样后面输入的就能逐行找
'''
用于用户注册的函数
1.要先创建userinfo.txt的文件用来储存用户注册信息
2.输入的信息会比对保证用户名不重复
'''
登录功能封装
def sign_in():
# 4.这样用户名密码就注册好了 下一步要登录也是先获取用户名密码
user_name_log = input('请输入登录用户名>>>')
password_log = input('请输入登录密码>>>')
# 5.下一步要比对文件里的数据首先要一行一行取值
with open(r'userinfo.txt', 'r', encoding='utf8') as g:
for line in g: # 6.取值完要单拿出用户名
user_list2 = line.split('|') # 7.把取到的字符串按|分隔成列表
if user_list2[0] == user_name_log and user_list2[1] == password_log: # 8.比对两者都一致
# 前面两步可以用解压赋值加分裂一步完成
print('登录成功')
break
else: # 注意这里缩进的位置是和for循环平齐的这样for结束之后才运行这个else
print('用户名或密码错误')
'''
用于用户的登录
1.要和前面的注册配合使用
2.确保注册数据和登录核对数据在同一文件
'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号