
8/16
今日考题
1.for循环语法结构及适用场景,range三种用法
1.for I in range : #所有容器类都可放range的位置
用来循环取值
2.列举python常见数据类型及尽可能多的内置方法
整型
bin() # 转二进制
oct() # 转八进制
hex() # 转十六进制
int() 转十进制
浮点型
float(11) # 11.0 没啥好用的
字符串
len() # 记长度(字符个数)
[0,10,2] # 从第一个元素取到第10个步长为2(数两个拿一个)
.strip # 去掉指定字符前面加l或者r可以去掉左边右边
.split('|',maxsplit=3) # 按|分割 ,最多分3次
.upper # 全大写 加is前缀判断是否全大写
.lower # 全小写 加is前缀判断是否全小写
.isdigit # 判断是否全数字
.count # 数出现次数
.replace('a','b',3) # 把a换成b 换3个
'|'jion(l) # 用|把l里面元素连起来
用加号也能实现
列表
.len
[]
.append # 在末尾加一个元素
insert(0,'a') # 在第一个位置加个
.pop # 从原列表弹出元素,会返还一个值
.extend # 扩展列表
.sort # 升序排列
.sort(reverse=True) # 降序排列
字典
.len
.get # 没有的元素返回none
d['name']='leo' # 有这个K:V键值对就改变值 没有就添加这对
.pop
.keys # 取K
.values # 取V
.items # 都要
集合
& # 交集
| #并集
- # 某集合去掉和另一个集合的交集
^ # 并集去掉交集
> # 父集
< # 子集
复习巩固
- 作业讲解和拔高
# 1.先写注释
"""
2.再写主体功能
3.最后再补全额外的操作
"""
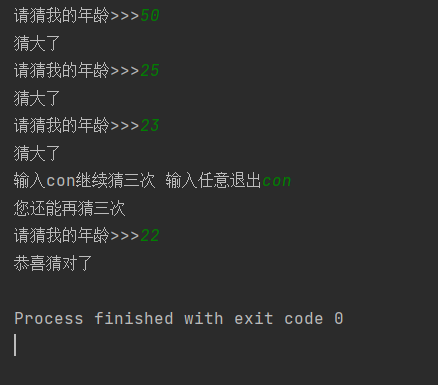
再脱稿完成一次完整的猜年龄游戏
- 猜年龄游戏脱稿独立优化完整版
# 6.加一个参数去控制猜的次数
hp = 3
# 1.猜数字么必然有一个循环要一直猜,别多想先while
while True:
# 7.先判断有没有资格猜
if hp > 0: # 有资格猜运行下面的子代码
# 2.循环里面第一步是每次猜的值
age = input('请猜我的年龄>>>')
# 3.有了输入年龄就要判断比较,但是输入的是字符串要转整型,就要做第一步判断
if age.isdigit() == True:
age = int(age) # 4.转换完之后就可以进行数字的比较了
if age > 22:
print('猜大了')
hp -= 1 # 8.猜错扣血
elif age < 22:
print('猜小了')
hp -= 1
else:
print('恭喜猜对了')
break # 5.比较出结果就停止循环了,那要加限定次数就得再加个参数
else:
print('年龄只能是纯数字')
else:
answer = input('输入con继续猜三次 输入任意退出>>>')
# 判断是否要继续
if answer == 'con':
print('您还能再猜三次')
hp += 3 # 加上血
else:
print('谢谢参与')
break
效果还是不错的虽然很简单的程序但是看到自己的进步
- 流程控制for循环
for循环能做的while都能做
但是for循环简单方便很多
for 变量名 in 可迭代对象
循环体代码
range 方法
顾头不顾尾
默认从0开始
最后一个参数表示等差数列
- 数据类型内置方法
"""
句点符(.) 快速查看当前对象的属性和方法
"""
整型int
int()
1.类型转换
2.其他进制数转十进制数
浮点型float
float()
字符串str
索引取值
切片操作
间隔步长
统计长度
strip()
split()
upper()
lower()
isupper()
islower()
join()
isdigit()
...
列表list
索引取值
切片操作
间隔步长
统计长度
append()
insert()
extend()
pop()
remove()
sort()
...
元组tuple
索引取值
切片操作
间隔步长
统计长度
字典dict
按key取值
统计长度
d[key] = value
...
集合set
去重与关系运算
布尔值bool
对与错
内容概要
- 作业分析
- 字符编码
理论居多 结论很少 学习简单
- 文件操作
代码操作文件
- 登录注册功能
稍微有点难度
详细讲解
作业分析
l = [1, 22, 33, 22, 11, 22, 66, 55, 77, 99]
# 对列表元素进行去重
# 拔高: 去重之后保持原来的顺序(不要惯性思维)
l = [11, 22, 33, 22, 11, 22, 66, 55, 77, 99]
# 1.将列表转换成集合
s1 = set(l)
# 2.由于集合内部不允许出现重复的元素 会自动去重
l1 = list(s1)
print(l1)
"""集合内元素是无序的"""
# 1.先定义一个空列表
new_list = []
# 2.循环获取列表中每一个元素
for num in l:
# 3.判断当前元素在不在新的列表内
if num not in new_list:
# 4.如果元素不在列表内 说明该元素是第一次出现 应该添加到列表中
new_list.append(num)
# else:
# 5.如果元素已经存在 说明该元素重复了 应该取出
print(new_list)
# 3.关系运算
# 有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons = {'jason', 'egon', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
# 1. 求出即报名python又报名linux课程的学员名字集合
print(pythons & linuxs)
# 2. 求出所有报名的学生名字集合
print(pythons | linuxs)
# 3. 求出只报名python课程的学员名字
print(pythons - linuxs)
# 4. 求出没有同时这两门课程的学员名字集合
print(pythons ^ linuxs)
这个作业之前我就已经完成的不错了
我的成果
'''
第一题
'''
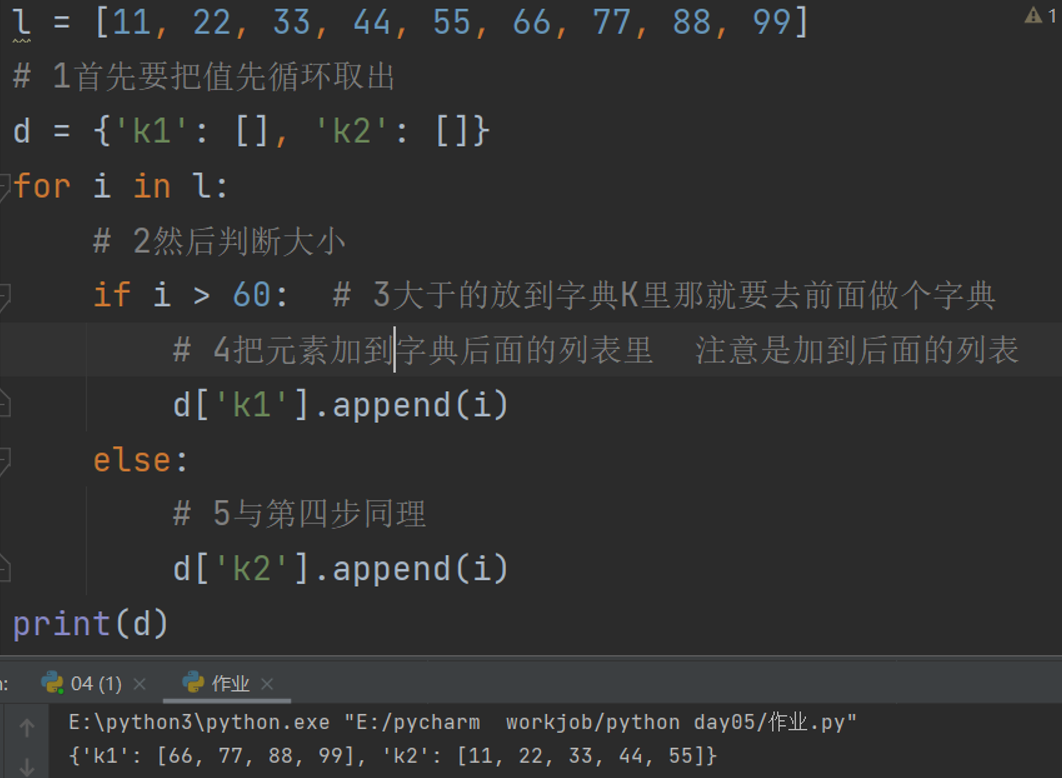
l = [11, 22, 33, 44, 55, 66, 77, 88, 99]
# 1首先要把值先循环取出
d = {'k1': [], 'k2': []}
for i in l:
# 2然后判断大小
if i > 60: # 3大于的放到字典K里那就要去前面做个字典
# 4把元素加到字典后面的列表里 注意是加到后面的列表
d['k1'].append(i)
else:
# 5与第四步同理
d['k2'].append(i)
print(d)
'''
第二题
'''
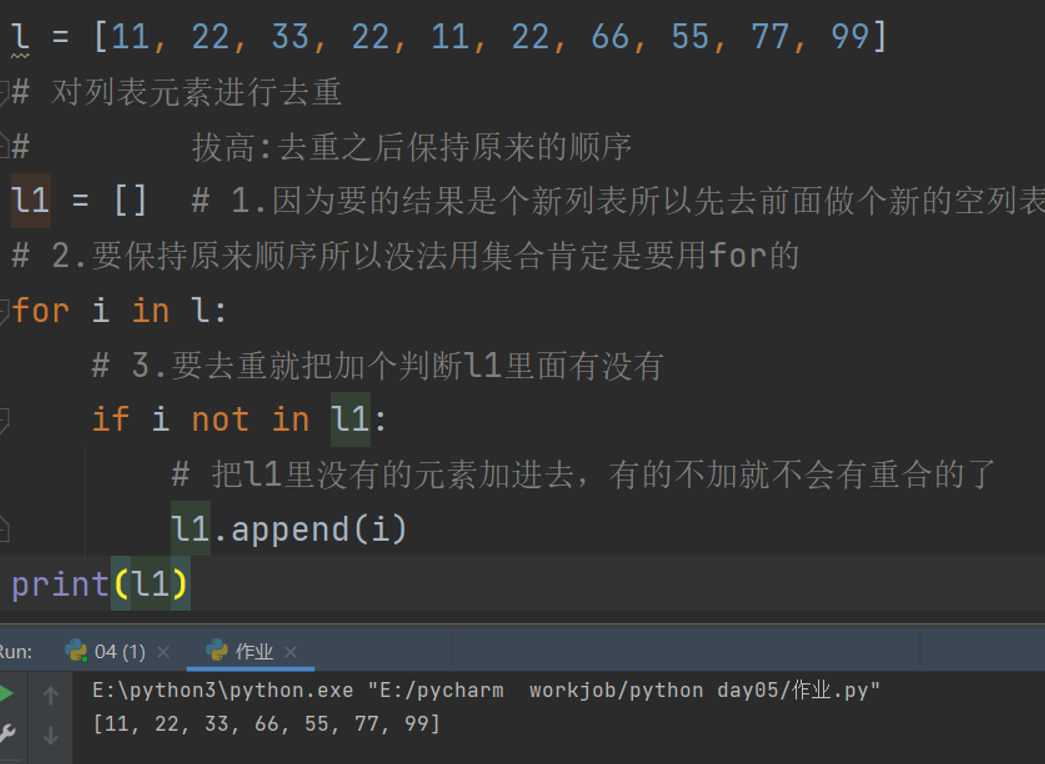
l = [11, 22, 33, 22, 11, 22, 66, 55, 77, 99]
# 对列表元素进行去重
# 拔高:去重之后保持原来的顺序
l1 = [] # 1.因为要的结果是个新列表所以先去前面做个新的空列表
# 2.要保持原来顺序所以没法用集合肯定是要用for的
for i in l:
# 3.要去重就把加个判断l1里面有没有
if i not in l1:
# 把l1里没有的元素加进去,有的不加就不会有重合的了
l1.append(i)
print(l1)
'''
第三题
=
'''
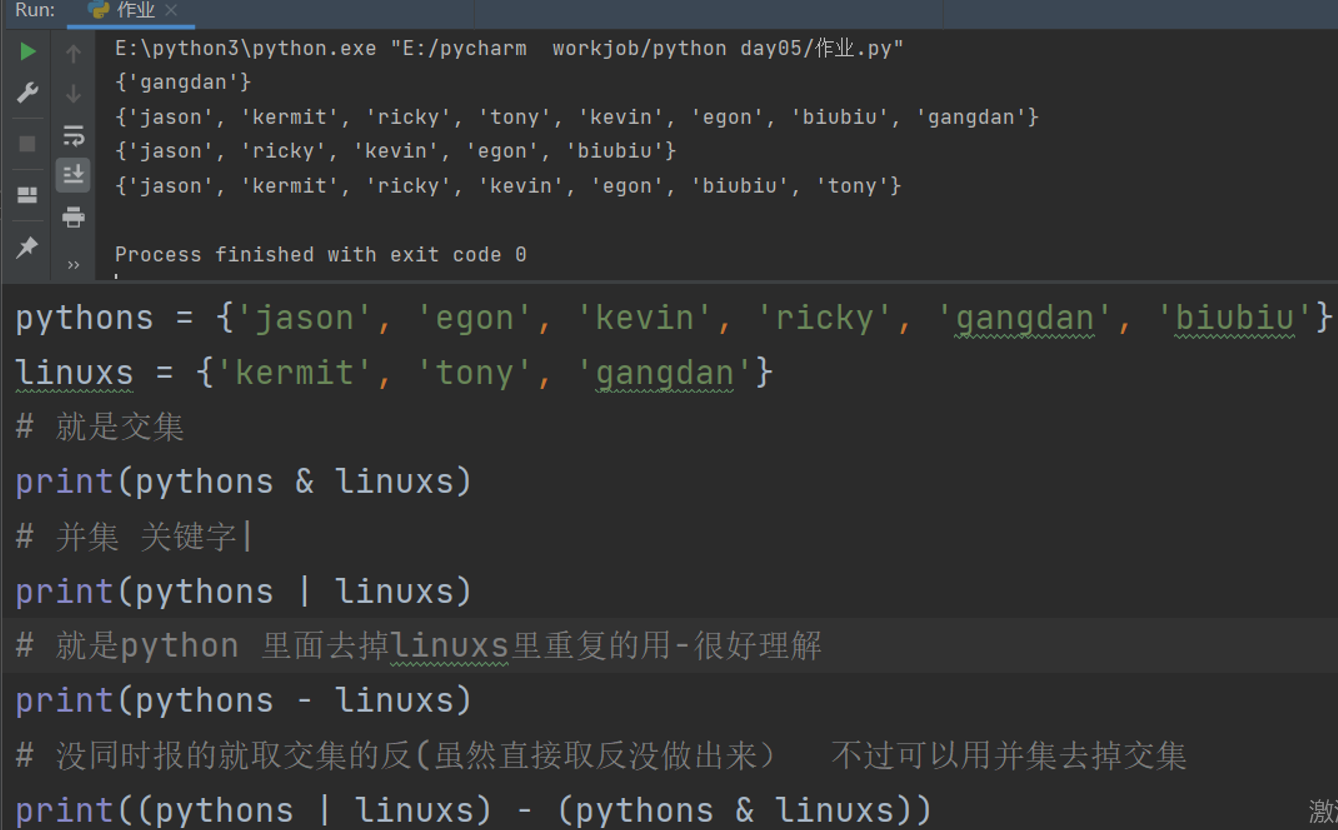
pythons = {'jason', 'egon', 'kevin', 'ricky', 'gangdan', 'biubiu'}
linuxs = {'kermit', 'tony', 'gangdan'}
# 就是交集
print(pythons & linuxs)
# 并集 关键字|
print(pythons | linuxs)
# 就是python 里面去掉linuxs里重复的用-很好理解
print(pythons - linuxs)
# 没同时报的就取交集的反(虽然直接取反没做出来) 不过可以用并集去掉交集
print((pythons | linuxs) - (pythons & linuxs))
print(pythons ^ linuxs)
字符编码
'''
计算机基于电工作只有高低电频两种状态
也就是说计算机只认识两种状态 人为的酒吧这两种状态定义为0和1
人类的字符与数字之间存在对应关系
相当于发电报彼此携带的密码本一样
'''
1.一家独大
计算机是美国人发明的 想让计算机认识英文
ASCII码
内部记录了英文与数字的对应关系
2.群雄割据
中国人
GBK码
内部记录了英文 中文与数字的对应关系
韩国人
Euc_kr码
内部记录了英文 韩文与数字的对应关系
日本人
shift_JIS码
内部记录了英文 日文与数字的对应关系
3.天下一统
unicode码(万国码)
内部记录了各个国家文字与数字的对应关系
utf8(万国码优化版本)
目前默认使用该编码
# 以后文本文件出现乱码就直接改字符编码
编码和解码
# 编码
按照指定的编码本将人类的字符编程成计算机能够识别的二进制数据
# 解码
按照指定的编码本将计算机的二进制数据解析成人类能够读懂的字符
'关键是用代码怎么实现'
res ='试试python怎么编码解码'
print(res.encode('gbk')) # 编码了 关键字.encode
r1 = res.encode('gbk')
print(r1.decode('gbk')) # 解码了 关键字.decode
文件操作
with open(文件路径,读写模式,字符编码) as 变量名:
前面的with的子代码
# 第二种(不推荐使用)
变量名 = open(文件路径,读写模式,字符编码)
一系列操作
变量名.colse()
读写模式
r 只读模式
1.文件路径不存在会直接报错
2.文件存在则打开,可读取文件内容
光标在文件开头
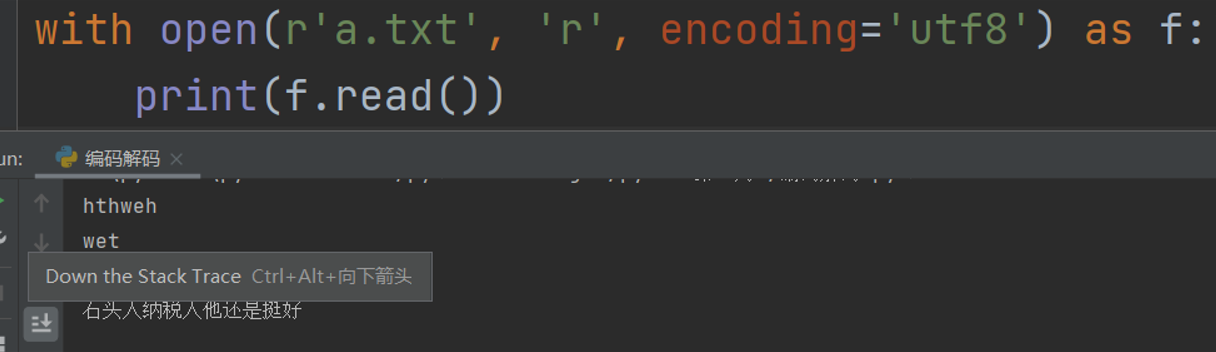
with open(r'a.txt', 'r', encoding='utf8') as f:
print(f.read()) # 一次性读取文件内容
w 只写模式
1.文件路径不存在会自动创建
2.文件路径存在会先清空该文件内容然后再写入
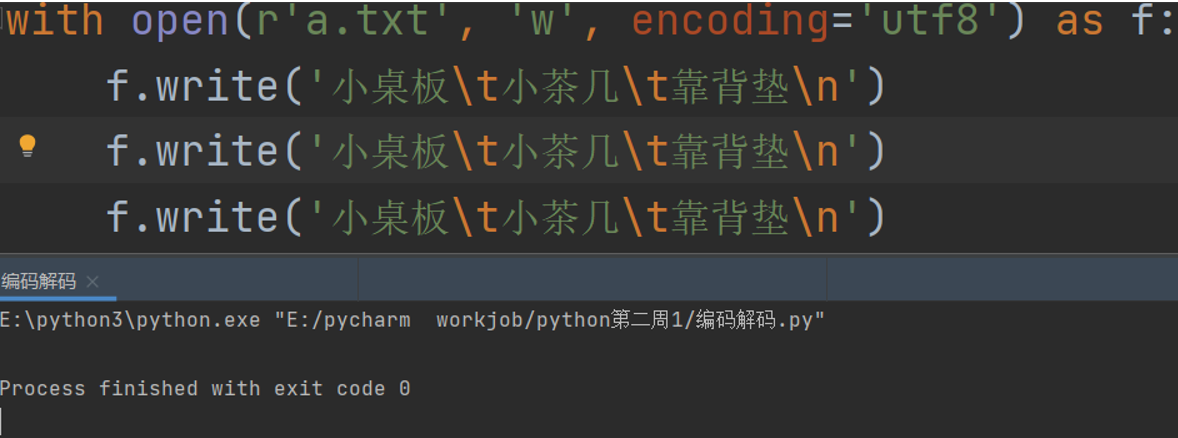
with open(r'a.txt', 'w', encoding='utf8') as f:
f.write('小桌板\t小茶几\t靠背垫\n')
a 只追加模式
1.文件路径不存在会自动创建
2.文件路径存在光标会移动到文件末尾
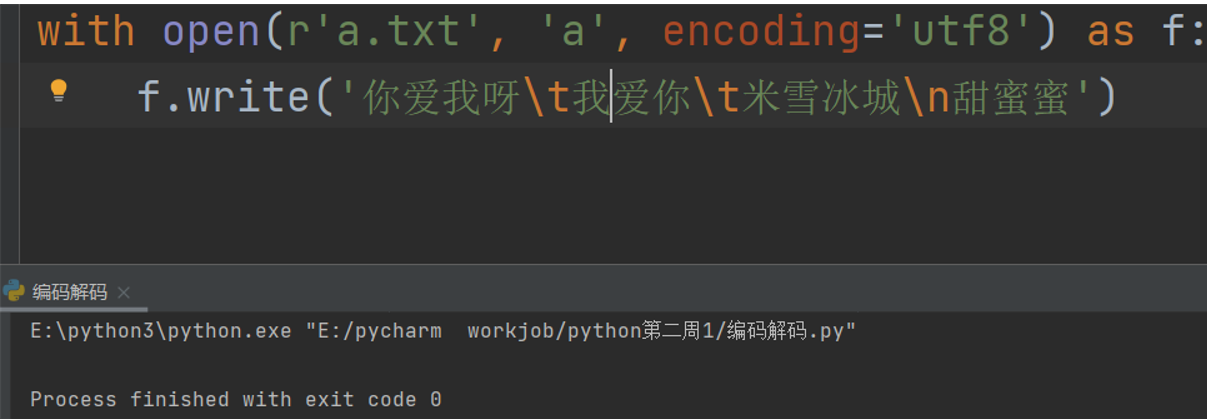
with open(r'a.txt', 'a', encoding='utf8') as f:
f.write('你爱我呀\t我爱你\t米雪冰城\n甜蜜蜜')
# 补充知识 读取优化
之前介绍了.read是一次性全部读取如果文件超级大内存有爆的风险
就优化出了这个操作
with open(r'a.txt', 'r', encoding='utf8') as f:
for line in f: # 一行行的读取文件内容内存就不会爆了
操作模式
t模式
文本模式(也是上述三种读写模式的默认模式)
rt
wt
at
1.该模式下只能操作文本文件
2.该模式下必须指定encoding参数
3.读写都是以字符串为单位

b模式
二进制模式
rb
with open(input(r'请输入复制文件的绝对路径>>>'), 'rb') as f:
wb
ab
1.该模式可以操作任意类型的文件
2.该模式下不需要指定encoding参数
3.读写都是以bytes(二进制)为单位
用b模式可以完成一些简单的操作比如复制
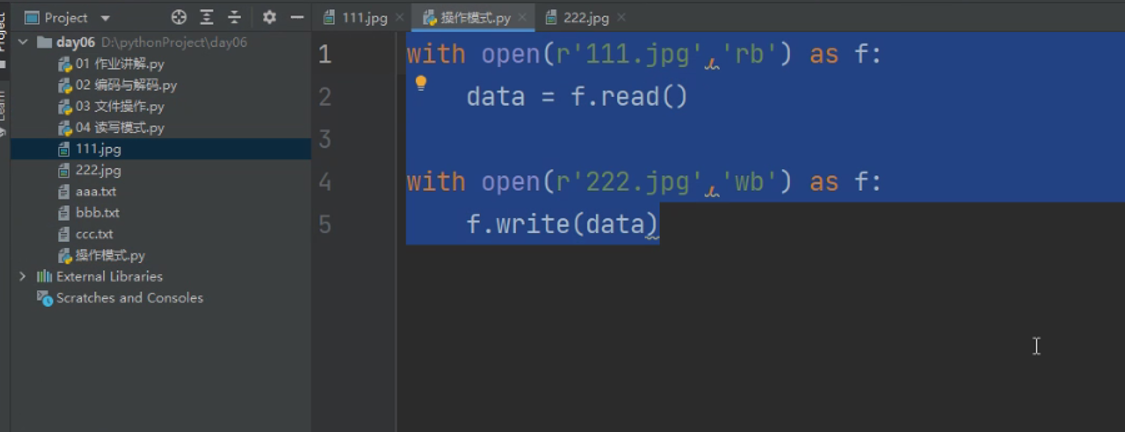
还可以用b模式完成t模式一样的文本编写

作业
1.完成今日博客
2.利用文件操作编写一个简易的文件拷贝系统
让用户输入需要拷贝的文件路径
然后再获取即将拷贝到哪儿的路径
# 先让用户输入要复制的文件绝对路径
with open(input(r'请输入复制文件的绝对路径>>>'), 'rb') as f:
copy_add = input(r'请输入想要复制到的绝对路径>>>')
# 获取输出位置要在for循环外面不然一直输地址
for line in f: # 一行一行的去读写的数据
with open(copy_add, 'ab') as g: # 因为是一行行写入的那就只能用ab了
g.write(line)
3.利用文件操作完成用户的注册 登录
userinfo.txt
基本要求
用户注册获取用户名和密码然后写入文件 jason|123
登录获取用户名和密码之后去文件中比对
# 上述操作完成一次就算成功
拔高练习
用户注册可以多次注册并且校验用户名是否重复
登录需要逐行比对

