8/13
今日考题
1.诠释逻辑运算符,成员运算符,身份运算符各自详细
逻辑运算符
与 and 链接的条件要同时满足
或 or 链接的条件只要满足一个
非 not 取条件的反 我超勇的啦 --not-> 我超逊的啦
成员运算符 in
判断个体是否在某群体内
list = [1,2,3,4]
sth = 1
print(sth in list) # True
身份运算符
No1 = 123456
No2 = 123456
No1 == No2 # True 两个等号代表数学里的等号
No1 is No2 # False is来看两者的内存地址是否一样,有些情况经过优化也可能一样
2.程序执行流程有几种,尝试书写各自语法结构,注意事项
顺序结构
没啥说的 最基本的部分只要从上到下顺序执行就是
分支结构
顺序结构中添加了条件从而让下一步结果出现分叉
循环结构
被某条件限制要重复之前的顺序 循环往复
graph LR
A[分支结构]-->B[目前是顺序结构]
B --> C[条件1]
C -->D[结果1]
C --> E[条件2]
E -->F[结果2]
E -->G[结果3]
graph LR
A-->B
B --> C[由于某些条件返回A]
C -->A
C -->D{这就是循环结构}
复习巩固
-
逻辑运算符
数学运算和逻辑运算的区别? 数学运算就是数字之间的数学计算 逻辑运算是对一个事物的判断 eg: 今天练不练腿 出门撑不撑伞 与 and 链接多个条件必须全部满足 或 or 链接多个条件只要有一个满足 非 not 取反操作 """ 补充: 在python中所有数据类型内部都可以转换成布尔值 布尔值为False的 0 None 空字符串 空列表 空字典 其他均为True """ -
成员运算符
判断个体在不在全体内 in not in -
身份运算
id() #返回一串数字 可以看成是内存地址 is # 判断两个变量指向的值内存地址是否一致 == # 判断两个变量指向的值是否相等 """ 值相等内存地址可能不相等 内存地址相等值一定相等 """ ps:python内部有内存优化机制 -
流程运算
控制事物的执行流程 顺序结构 分支结构 循环结构 # 前面的问答里有示意图 -
if 判断
""" python中通过代码的缩进表示代码之间的从属关系 推荐使用四个空格 并不是所有代码都可以拥有子代码 同属于一个关键字的多行子代码要保持相同缩进量 ps:如果代码末尾出现冒号 那下一行代码必定缩进 """ 1. if... if条件: 条件成立执行子代码 2. if...else if条件: 条件成立执行子代码 else: 条件不成立执行子代码 3. if...elif...elif...else if 条件1: 条件1成立执行子代码 elif 条件2: 条件1不成立条件2成立执行子代码 ... else: 条件不成立执行子代码 # if elif else 连用只能执行一个 -
while 循环
while 条件 : 循环体代码1 循环体代码2 循环体代码3 每次执行完循环体代码后会再判断条件是否成立 成立则继续循环执行 不成立则退出循环 while + break 结束本层循环 本层即上一辈的while while + continue 结束本次循环 -
作业复盘
""" 前期涉及到编程相关的问题不要着急写代码 可以先写中文思路(注释) 再不行画个流程图 """ 1.利用if判断实现用户的登录功能 获取用户的用户名和密码 然后判断是否跟后台设定的用户名密码相同 # 先获取用户名和密码数据 user_name = input('您的用户名:') passport = input('您的密码:') if user_name == 'leo' and passport == '112233': print('welcome back leo') # 如果两个都和预设的对上了 输出这个 else: print('passport or user_name error') # 其他情况就是 用户名或者密码有问题 2.利用if判断编写身份识别系统 获取用户的用户名 根据用户名的不同打印不同的身份 eg: jason 管理员 tony 经理 kevin 主管 tom、jerry 专员 其他人员 普通员工 拔高:循环起来并添加自动结束命令 while True: name = input('请输入姓名') # 获取用户名 if name == 'jason': # 判断用户名对应的关系 print('管理员') elif name == 'tony': print('经理') elif name == 'kevin': print('主管') elif name == 'tom' or name == 'jerry': print('专员') elif name == 'end': # 额外加一个用于结束的判断 break else: print('普通员工') 利用while循环编写猜年龄的游戏 只有猜对了才结束程序 否则一直循环猜 拔高: 三次机会 再拔高 三次之后问是否继续 hp = 3 # 设置一个血量值来限定猜的次数 由于第一遍走是2.第二遍是1 while True: # 循环别管先给个True 别再while里面做限定条件不然之后不好改 if hp > 0: # 判断次数要放最前面来看有没有猜的资格 age = input('请猜年龄') # 获取猜的数据 age = int(age) # 把input拿到的字符串转成整型 方便比大小 if age > 22: # 判断大小 print('猜大了') hp -= 1 # 猜错扣一次血 elif age < 22: # 判断大小 print('猜小了') hp -= 1 # 猜错扣一次血 else: # 除了猜大或者猜小 就只有完全猜对了 print('恭喜你回答正确') break else: # 血没了的情况 print('您已经尝试三次是否还要继续') choose = input('继续Y 退出Q') if choose == 'Y': # 用==看输入内容是否和我们做判定的需要的一支 hp += 3 # 要继续加3点血回到本层循环 if choose == 'Q': break # 刚开始接触编程肯定不习惯(先抄代码,多敲 之后再模仿写 加入自己的想法)
内容概要
- 循环结构之for 循环(简单)
- 数据类型的内置方法(重要)
- 字符编码
- 文件操作(代码操作文件读写)
详细讲解
几乎全是记忆内容图片比较少比较无趣但是务必多级多练百炼成钢
循环结构之for 循环(简单)
for循环能实现的操作while都能实现
但是for循环的语法结构要简单很多
cp_list = ['loe', 'ace', 'love', 'peace', 'sex']
num = 0 # 用while做循环取值
while num < 5:
print('>>>', cp_list[num])
num += 1
# 可以看出while太复杂了,而且还要知道列表里元素数量很不方便
# 这里就要介绍循环取值的王for循环
for word in cp_list:
print('>>>', word)
# 短短两行就解决了非常方便
res = 'hello world!'
# 当值没有明确的类别时 变量名会取i、k、j、item等
for i in res:
print(i) # 会一个个字符打出来
my_dict = {'name': 'leo', 'age': '18', 'height': "160", 'weight': '150'}
for k in my_dict: # 取字典里的值只能取到key 对应的value无法直接获取
print(k) # name age height weight
"""
for循环特别擅长应用再循环取值方面
for 变量名 in 可迭代对象(字符串 列表 字典 元组):
for循环体代码
for循环不用添加结束命令 取值结束会自动结束
"""
"""
容器类型
内部能够存放多个元素的数据类型都可以称之为容器类型
列表 字典 元组
for循环针对容器类都可以循环取值
在此基础上对字符串也可以循环取值
"""
range的用法
配合for很好用,因为range的本质是个迭代器
for i in range(0, 10):
print(i) # 后面的括号范围有个要点‘顾头不顾尾’ 所以结果是0到9
for i in range(5): #一个参数默认从0开始
#两个参数的前面讲过了注意重点 顾头不顾尾
for i in range(0,250,25) # 三个参数最后一个是间隔 相当于产生一个等差数列
print(i) # 0 25 50 ... 225
数据类型内置方法
补充
如何查看数据类型拥有的方法
用句点符
数据类型.
在pycharm里面会有提示
整型 int
# 整型 int
int()
1.数据类型的转换
2.实现进制之间的转换
n = '11'
print(int(n)) # 正确
n1 = '11.11'
print(int(n1)) # 报错 小数点整型无法转
n2 = 'jason'
print(int(n2)) # 报错 数字以外根本无法转换
# 将十进制转化成二进制再复制结果转回来
print(bin(50)) # 0b110010
print(int(0b110010)) # 50
# 将十进制转化成八进制再复制结果转回来
print(oct(55)) # 0o67
print(int(0o67)) # 55
# 将十进制转化成十六进制再复制结果转回来
print(hex(43)) # 0x2b
print(int(0x2b)) # 43
"""
以后如果看到数字前面
ob开头就是二进制数
0o开头则是八进制数
0x开头则是十六进制数
"""
# 其他机制转十进制
print(int('0b1100100', 2)) # 100
print(int('0o144', 8)) # 100
print(int('0x64', 16)) # 100
浮点型 float
# 浮点型 float
n1 = '11'
print(float(n1)) # 11.0
n2 = '11.11'
print(float(n2)) # 11.11
n3 = 'leo'
print(float(n3)) # 报错
字符串 str
# 字符串 str
# 1.统计字符个数
res = 'ACE with lover'
print(len(res)) # 14
# 2.索引取值
print(res[0]) # A
# 3.切片取值
print(res[3:8]) # with 和之前一样遵循顾头不顾尾的原则
# 4.步长 在前面的基础上再加一个参数表示间隔
print(res[0:12:3]) # A tl 注意中间的空格,也算作字符的
# 5. 移除字符串首位指定的字符
user_name = '&&&Y&ACE&Y&&'
print(user_name.strip('&')) # Y&ACE&Y 注意strip只能添加一个参数
print(user_name.lstrip('&')) # Y&ACE&Y&& 清楚左边固定元素
print(user_name.rstrip('&')) # &&&Y&ACE&Y 清除右边固定元素
# 一直清除到有不是预设的元素为止 比如前面的例子到Y就会停
# 这个功能最大的作用就是清除字符串首位的空格
name = ' ACE '
print(len(name)) # 16 空格算字符
print(len(name.strip())) # 3 去掉空格
vip_user = input('vip>>>:').strip()
if vip_user == 'ACE':
print('welcome home')
else:
print('fuck off') # 这个登录界面中无论前后输多少空格都能成功识别出来
# 6.按照指定的字符切割数据
data = 'leo|18|16.5|ace|16|black'
print(data.split('|')) # ['leo', '18', '16.5', 'ace', '16', 'black'] # split就是分裂的意思
print(data.split('|', maxsplit=1)) # ['leo', '18|16.5|ace|16|black'] # 最多分割一个
print(data.rsplit('|', maxsplit=1)) # ['leo|18|16.5|ace|16', 'black'] # 加个r就是右边开始
# 7.大小写转换
check_code = '3A8x'
print(check_code.upper()) # 3A8X 把字母全转大写
print(check_code.lower()) # 3a8x 把字母全转小写
"""图片验证码之所以不需要校验大小写 内部就是统一转大小写再比对"""
print(check_code.isupper()) # 判断字符串是否是纯大写 False
print(check_code.islower()) # 判断字符串是否是纯小写 False
# 8.判断字符串是否是纯数字
print('1231654'.isdigit()) # True
print('ga6rg55'.isdigit()) # False
# 9.统计字符出现次数
article = 'l wana be your slaver slaver slaver slaver slaver slaver forever'
print(article.count('slaver')) # 6
# 10.替换指定字符
print(article.replace('slaver', 'lover')) # l wana be your lover lover lover lover lover lover forever
print(article.replace('slaver', 'lover', 3)) # l wana be your lover lover lover slaver slaver slaver forever
# 加的参数意味着换几个
# 11.按照指定的字符拼接字符串
l = ['leo', 'ace', 'love', 'sex', 'forever']
print('/'.join(l)) # leo/ace/love/sex/forever
hate = 'hot and wet'
like = 'fall'
prefer = 'muscle'
print(hate+' '+like+'|'+prefer) # hot and wet fall|muscle 空格也能加记得在引号里打上
列表 list
# print(list())里面只能转换支持for循环的数据类型
# 1.统计元素个数
l1 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(len(l1)) # 9
# 2.索引取值
print(l1[0]) # 1
# 3.切片操作
print(l1[0:4]) # [1, 2, 3, 4]
# 4.增加步长参数
print(l1[0:4:2]) # [1, 3]
# 5.添加元素
# 5.1尾部添加元素
l1.append('leo')
print(l1) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 'leo']
# 无论添加的元素是什么都只会被当成列表的一个元素
l1.append([1, 2, 3, 4])
print(l1) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 'leo', [1, 2, 3, 4]]
# 5.2指定位置插入元素
l1.insert(0, 'leo') # 前一个是位置后一个是元素
l1.insert(2, [11, 22]) # 无论加什么元素都只会当成列表里的一个元素
print(l1) # ['leo', 1, [11, 22], 2, 3, 4, 5, 6, 7, 8, 9, 'leo', [1, 2, 3, 4]]
# 5.3扩展列表
l1.extend(['a', 'b', 'c']) # 把每个元素一一添加进列表
print(l1) # ['leo', 1, [11, 22], 2, 3, 4, 5, 6, 7, 8, 9, 'leo', [1, 2, 3, 4], 'a', 'b', 'c']
"""
如果不让你使用extend也完成扩展列表的操作 如何实现?
for i in [111,222,333,444]:
l1.append(i)
"""
# 6.删除元素
# 6.1通用删除操作
del l1[0] # 删除第一个元素
print(l1)
# 6.2弹出元素
bob = l1.pop(1) # 不同于del的是pop之后那个元素还在
print(l1, bob) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 'leo', [1, 2, 3, 4], 'a', 'b', 'c'] [11, 22]
# 6.3删除元素
word = l1.remove(3) # remove和delet一样是不会保留元素的
print(l1, word) # [1, 2, 4, 5, 6, 7, 8, 9, 'leo', [1, 2, 3, 4], 'a', 'b', 'c'] None
# 7.统计元素出现的次数
l2 = [11, 222, 33, 22, 33, 11, 11, 11, 22, 22, 33, 44, 44]
print(l2.count(11)) # 4
# 8.排序
l3 = [55, 44, 22, 33, 11, 99, 77, 88]
l3.sort() # 默认是升序 sort排序
print(l3) # [11, 22, 33, 44, 55, 77, 88, 99]
l3.sort(reverse=True) # 倒序 reverse颠倒
print(l3) # [99, 88, 77, 55, 44, 33, 22, 11]
字典dict
# 字典dict
字典内元素也是无序的
user_dict = {'username': 'leo', 'pwd': 123, 'hobby': 'bodybuilding'}
# 1.统计长度(键值对的个数)
print(len(user_dict)) # 3
# 2.按键取值
print(user_dict['username']) # leo
print(user_dict['xxx']) # 键不存在会直接报错
print(user_dict.get('username')) # leo
print(user_dict.get('xxx')) # None 键不存在不会报错返回None
# 3.设置值(重点)
user_dict['username'] = 'ACE'
'''键存在则修改'''
print(user_dict) # {'username': 'ACE', 'pwd': 123, 'hobby': 'bodybuilding'}
user_dict['age'] = 18
'''键不存在则新建'''
print(user_dict) # {'username': 'leo', 'pwd': 123, 'hobby': 'bodybuilding', 'age': 18}
# 4.删除值(键值对是一个整体会一起删除)
res = user_dict.pop('username') # 和前面列表一样用pop
print(user_dict, res) # {'pwd': 123, 'hobby': 'bodybuilding', 'age': 18} leo
#5.三个小方法
print(user_dict.keys()) # 取键值对K:V的K dict_keys(['pwd', 'hobby', 'age'])
print(user_dict.values()) # 取键值对K:V的V dict_values([123, 'bodybuilding', 18])
print(user_dict.items()) # 取一整条键值对 dict_items([('pwd', 123), ('hobby', 'bodybuilding'), ('age', 18)])
集合(了解)
集合内元素是无序的
1.去重
集合内不允许出现重复的元素,会自动去重
2.关系运算
交叉并集(交集)
eg: 共同好友
f1 = {'jason', 'tony', 'kevin', 'jack'}
f2 = {'jason', 'tom', 'jerry', 'tony'}
# 1.求两个人共同好友
print(f1 & f2) # {'tony', 'jason'}
# 2.求f1独有的好友
print(f1 - f2) # {'jack', 'kevin'}
# 3.求f2独有的好友
print(f2 - f1) # {'tom', 'jerry'}
# 4.求两个人所有的好友
print(f1 | f2) # {'jason', 'jerry', 'tony', 'jack', 'tom', 'kevin'}
# 5.求两个人各自的好友
print(f1 ^ f2) # {'kevin', 'jack', 'tom', 'jerry'}
# 6.父集 子集
print(f1 > f2)
print(f1 < f2)
作业
1.今日博客
2.周日下午/晚上自我总复习
一定要脱稿自己写 写不出来的忘了的 快速看笔记和视频然后继续脱稿写
3.数据类型相关练习题
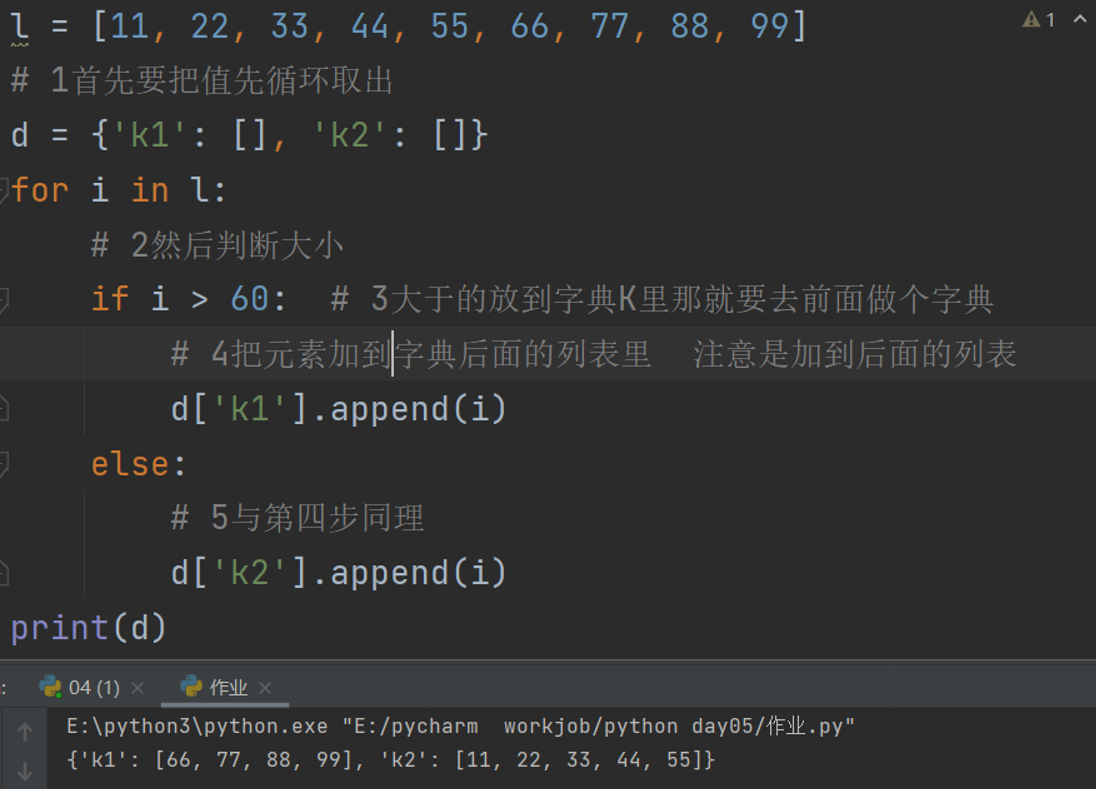
1.l = [11,22,33,44,55,66,77,88,99]
将列表中大于60的存入字典k1键对应的列表中
小于60的存入字典k2键对应的列表中
d = {'k1':[],'k2':[]}
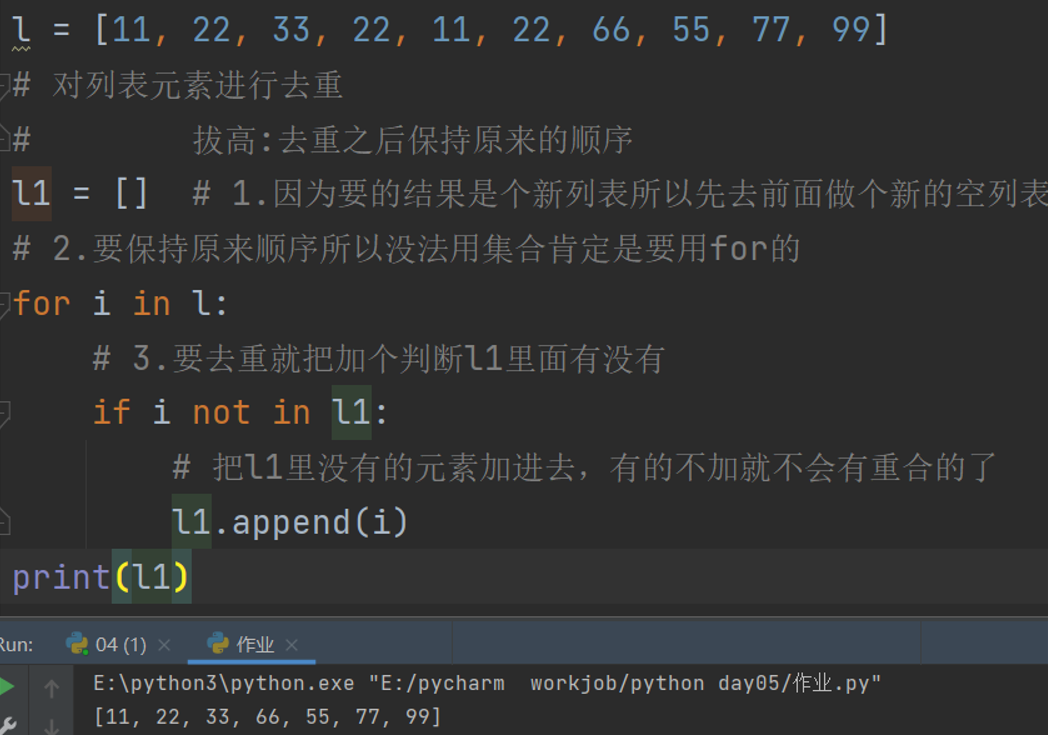
2.l = [11,22,33,22,11,22,66,55,77,99]
对列表元素进行去重
拔高:去重之后保持原来的顺序(不要惯性思维)
3.关系运算
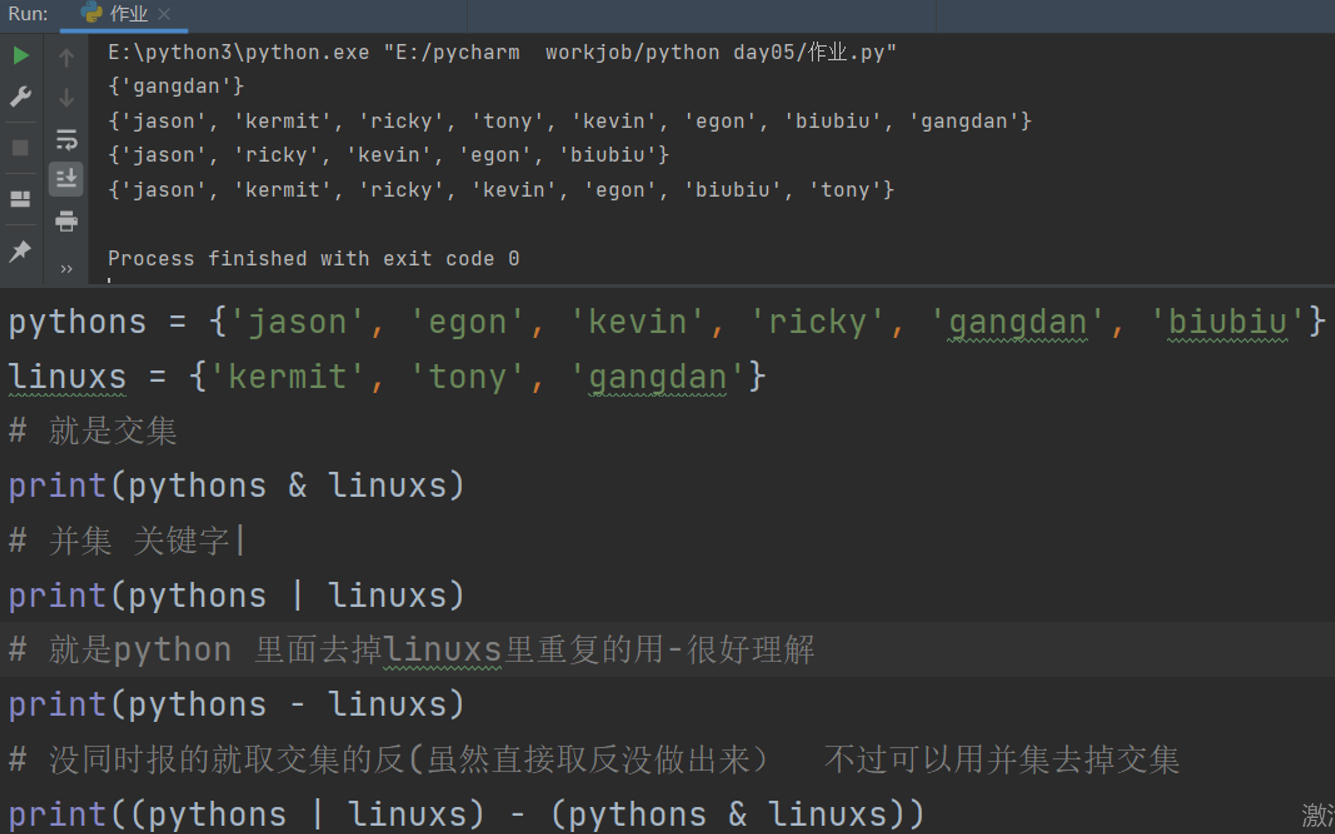
有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
pythons={'jason','egon','kevin','ricky','gangdan','biubiu'}
linuxs={'kermit','tony','gangdan'}
1. 求出即报名python又报名linux课程的学员名字集合
2. 求出所有报名的学生名字集合
3. 求出只报名python课程的学员名字
4. 求出没有同时这两门课程的学员名字集合