基于双向图注意网络的层次邻居传播的关系预测
原文
Hierarchical Neighbor Propagation With Bidirectional Graph Attention Network for Relation Prediction
出版
- IEEE/ACM Transactions on Audio, Speech and Language Processing
- Volume 29
- 2021
- pp 1762–1773
- https://doi.org/10.1109/TASLP.2021.3079812
申明
版权归原文作者及出版单位所有,如有侵权请联系删除
摘要
图注意网络(GAT)自2018年起开始成为主流神经网络架构,在各种自然语言处理(NLP)任务中取得了显著的性能提升。虽然GAT作为知识图关系预测的一种成功方法已经达到了最先进的水平,但现有模型仍然存在以下两个方面的局限性:(1)现有模型只考虑给定实体的入方向的邻居,而忽略了出方向的丰富邻居信息;(2)现有模型仅使用k跳输出学习多跳嵌入,导致在图注意步骤丢失大量早期嵌入信息(如单跳)。在本研究中,我们提出了一种新的双向图注意网络(BiGAT)来学习分层邻居传播。在我们提出的BiGAT中,引入了一个入方向和一个出方向GAT,在传播双向邻域信息之前捕获足够的邻域信息,从而分层学习多跳特征嵌入。在4个公开的数据集上进行的实验表明,与其他先进的方法相比,BiGAT取得了竞争的结果。
文章贡献
- 针对KGE任务,提出了一种新的BiGAT模型。提出的BiGAT能够从每个实体的入方向和出方向捕获多跳邻居信息,这使模型能够利用更丰富的全局上下文信息。
- 我们利用注意力机制将每个BiGAT层的分层跳跃嵌入信息组合成一个统一的表示,使模型具有更强的鲁棒性,避免了早期嵌入信息丢失的问题。
- 我们在四个公开的基准数据集上进行了广泛的实验:WN18RR、FB15k-237、NELL-995和Kinship。实验结果表明,在MRR评价指标下,BiGAT方法获得了最佳的性能,在所有数据集上与其他先进的方法相比具有竞争力。
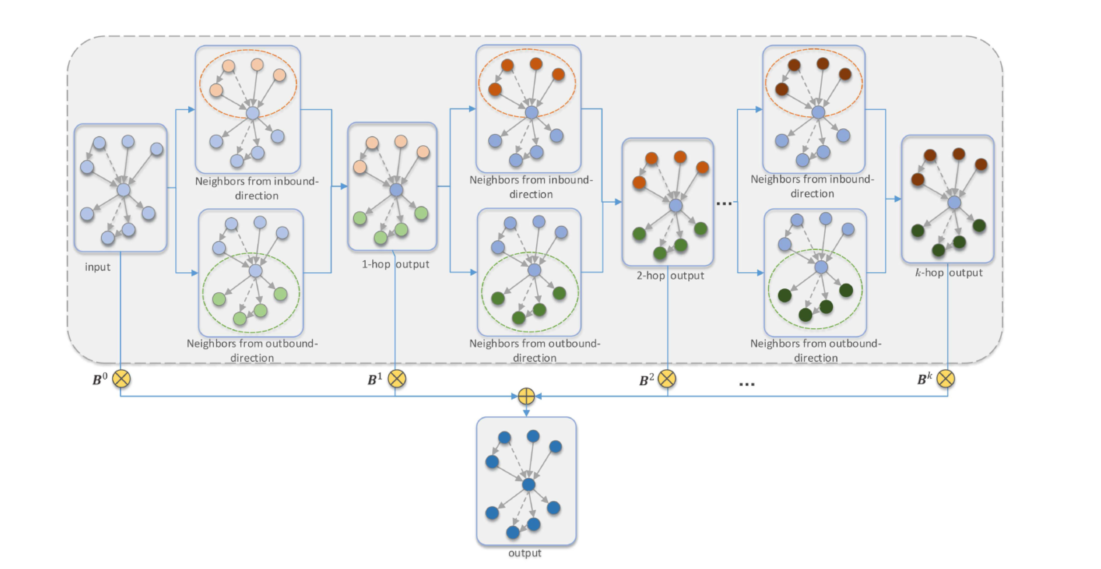
模型
双向嵌入传播
对于一个实体节点ei,我们通过如下方式计算其对应的出方向的三元组的表征:
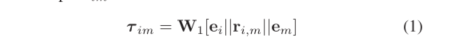
其中W1是出方向的投影向量, ||表示连接符号。
同理,对于入方向的三元组,其表征如下:
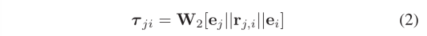
对于每一个出方向的三元组,其对应的注意力权重计算公式如下:
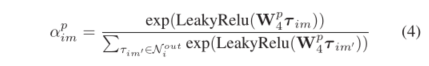
入方向的三元组的注意力机制,其计算方式也和上面类似。
第(l + 1)层的输出嵌入是将第l层的邻域信息从入方向和出方向聚合得到的。我们将两个方向的邻域信息连接起来,并应用线性变换来更新实体嵌入,我们在BiGAT模型中使用多头注意,记为下式:
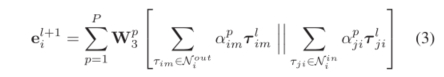
分级嵌入聚合
现存的GAT和KBGAT只使用最后的聚合输出(k-跳图注意结果)来学习实体嵌入,这样会忽略不同的每一跳的邻居的贡献。
为了解决这个问题,我们使用一种注意力机制来组合从BiGAT每一层的输出嵌入,这种通过充分利用每一条嵌入信息的方法可以充分捕获丰富的特征。
该思想的具体流程如下:
具体计算公式如下:
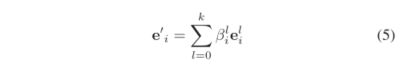
其中,上述的注意力权重是通过实体嵌入和跳嵌入计算得到,具体公式如下:
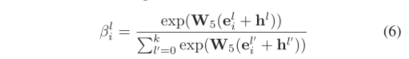
上述的h(l)就是跳嵌入,被用来编码每一层的位置信息,其中l属于范围[0, k]。
注意: 小编没有看懂h的来源以及计算
最终,实体嵌入的更新规则如下式所述:
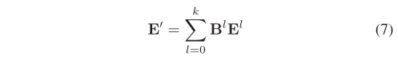
在BiGAT每一层,我们使用一个线性变换来更新关系嵌入,具体表示如下:
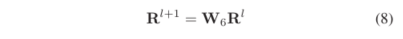
最终的关系嵌入表示也是和实体嵌入类似,通过各层的注意力机制计算得到:
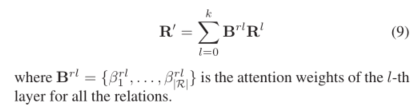
训练函数
三元组评分函数,具体公式如下:
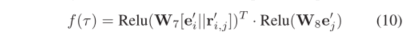
损失函数被定义为如下:
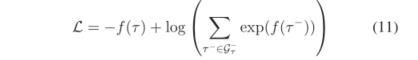
性能评估
数据集
我们在四个公开的标准的数据集上面进行KGE任务,这四个数据集分别是:
WN18RR、FB15k-237、NELL-995、Kinship。
评估指标
我们采用嵌入的常见评估指标: MR、MRR、Hit@N。
评估结果
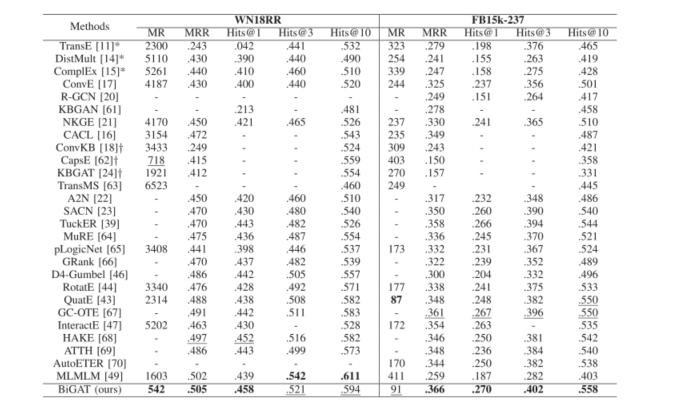
下表显示,我们的BiGAT模型在WN18RR和FB15k-237数据集上使用各种评估指标始终产生最佳性能,除了在WN18RR上的Hits@3和Hits@10以及在FB15k-237上的MR。
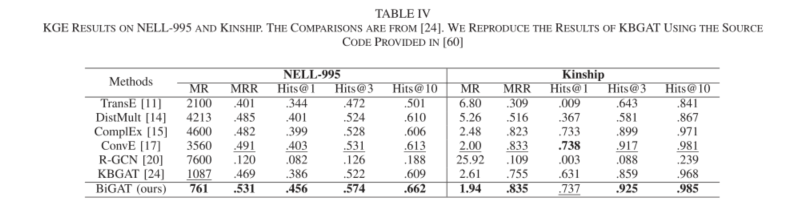
同时关于在NELL-995和Kinship的结果在下表,同样也有着相似的结果:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?