2018-GRAPH ATTENTION NETWORKS
图注意力网络
摘要
我们提出了图注意网络(GATs),这是一种对图结构数据进行操作的新型神经网络架构,利用隐蔽的自注意层来解决基于图卷积或其近似的现有方法的缺点。通过堆叠其中节点能够关注其邻域特征的层,我们能够(隐式地)为邻域中的不同节点指定不同的权重,而不需要任何类型的高成本矩阵运算(例如求逆)或依赖于预先知道的图结构。这样,我们同时解决了基于谱的图神经网络的几个关键挑战,并使我们的模型容易适用于归纳以及直推问题。我们的GAT模型已经在四个既定的直推和归纳图基准上实现或匹配了最先进的结果。
注意力架构
我们引入了一种基于注意力的架构来执行图结构数据的节点分类。这个想法是通过关注其邻居,遵循自注意力策略来计算图中每个节点的隐藏表示。注意力架构有几个有趣的特性:
- 操作是高效的,因为它可以跨节点邻居对并行化;
- 通过给邻居指定任意权重,可以将其应用于具有不同度数的图节点;
- 该模型直接适用于归纳学习问题,包括模型必须泛化到完全看不见的图的任务。
图注意力层
图注意力层是我们通过GAT架构进行实验使用的唯一一层。
这一层的输入为节点特征的集合,h=(h1, h2, h3, ... , hn), n是节点数量,hi是存在于嵌入维度F的向量空间的一个实体。输出是一个新的节点特征集合,h'=(h1', h2', h3', ..., hn'), hi'是存在于输出维度F'的向量空间的一个实体。
所以上述输入特征维度和输出特征维度不一样,为了获得足够的表达能力将输入特征转化为更高层次的特征,至少需要一个可学习的线性变换。
过程如下:
- 首先对每个节点乘以一个共同的线性变换,权重为W, 维度F'*F。
- 然后在节点上执行自注意力——一个共享的注意力机制a, 后面会具体介绍。
如下公式表示点i个j之间的注意力系数, 这表明了节点j的特征对节点i的重要性。
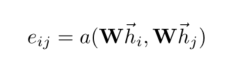
注意,我们只计算所有与节点i相邻的节点j,这样能够保留住图的结构信息。
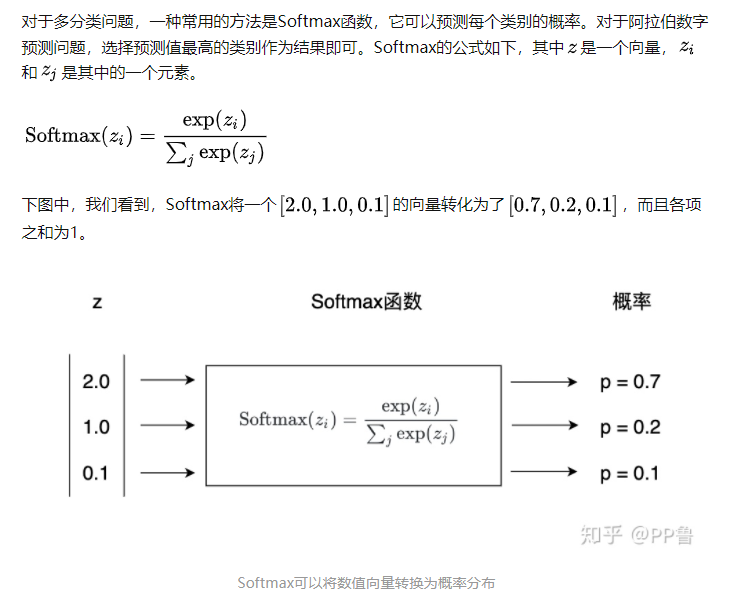
为了最后不同节点之间的注意力系数易于比较,我们还需要使用softmax函数进行归一化
这里是关于softmax的参考资料
所以我们的最终结果如下
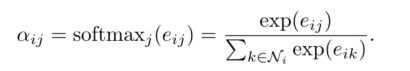
在我们的实验中,注意力机制a是一个单层前馈神经网络,由向量a参数化(注意这里是向量a, 前面是符号a),然后应用一个LeakyReLu函数。所以最终整个表达式如下:
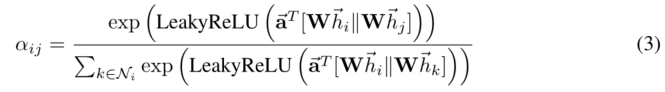
上面T是矩阵转置符号,||是连接符号。
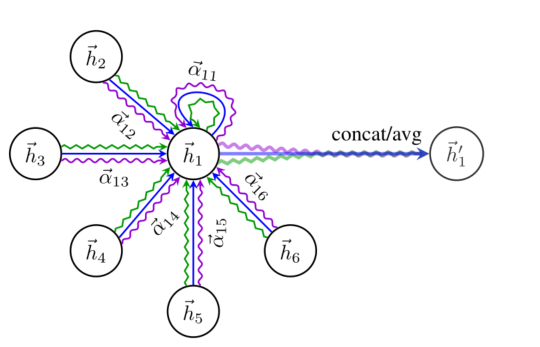
上述过程用图表示如下:
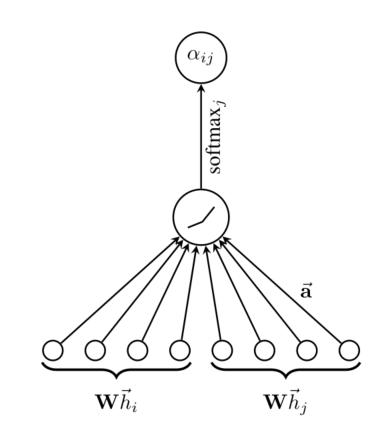
每个节点更新方式如下:
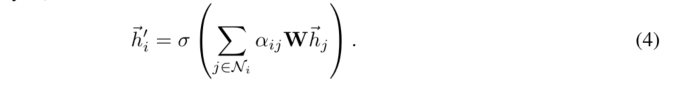
也就是归一化的注意力系数乘以权重矩阵W再乘以邻居向量hj,对所有邻居节点求和,最后进行一次非线性变换,计算出新的i点。
为了稳定自我注意的学习过程,我们发现扩展我们的机制以采用多头注意是有益的。具体地,K个独立的注意机制执行等式4的变换,然后它们的特征被连接,产生以下输出特征表示:
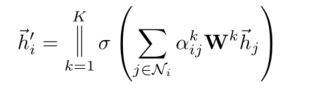
注意上述最后产生的输出向量维度为K*F'。所以对于网络的最后一层,我们其实用||连接时不合适的,可以考虑使用平均,并且把非线性变换放在最后,如下图公式所述:
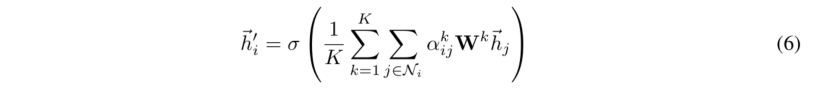
注:上面这些公式中的非线性变换一般指softmax或者sigmod。
我们最后以一张图总结上述多头注意力机制


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署
· 葡萄城 AI 搜索升级:DeepSeek 加持,客户体验更智能