【阿圆实验】Alertmanager HA 高可用配置
注意:没有使用supervisor进程管理器的,只参考配置,忽略和supervisor相关命令。并且alertmanager的版本不得低于0.15.2,低版本alert不支持集群配置。
一.alertmanager高可用
这里使用的是supervisor配置,也可以把配置集合成命令行方式,在服务器运行配置。记得加&,后台运行。
1.配置alertmanager集群
1.1 修改各节点alertmanager.yml
cd /data/yy-monitor-server/etc
vim alertmanager.yml
# The root route on which each incoming alert enters.route: routes: group_wait: 15s group_interval: 15s |
1.2 修改启动文件
根目录下运行 vim /etc/supervisord.d/yy-monitor-server.ini
[program:alertmanager]priority = 3user = yycommand = /usr/bin/alertmanager --cluster.listen-address="10.22.0.1002:12001" # 当前节点ip和自定义的端口号 --log.level=debug |
其他节点配置:
[program:alertmanager]priority = 3user = yycommand = /usr/bin/alertmanager --cluster.listen-address="10.22.0.1001:12002" # 当前节点ip和自定义的端口号: --cluster.peer=10.22.0.1002:12001 # 选择一个节点加入集群 --log.level=debug |
重启配置,否则不能生效:
systemctl restart supervisord
supervisorctl restart alertmanager
2.查看日志
cd /data/yy-monitor-server/log
tail -f alermanager.log
level=debug ts=2018-08-28T08:58:44.75092899Z caller=cluster.go:287 component=cluster memberlist="2018/08/28 16:58:44 [DEBUG] memberlist: Initiating push/pull sync with: 10.22.0.1001:12002\n"level=debug ts=2018-08-28T08:59:21.675338872Z caller=cluster.go:287 component=cluster memberlist="2018/08/28 16:59:21 [DEBUG] memberlist: Stream connection from=10.22.0.1001:42736\n"level=debug ts=2018-08-28T08:59:44.754235616Z caller=cluster.go:287 component=cluster memberlist="2018/08/28 16:59:44 [DEBUG] memberlist: Initiating push/pull sync with: 10.22.0.1000:12003\n" |
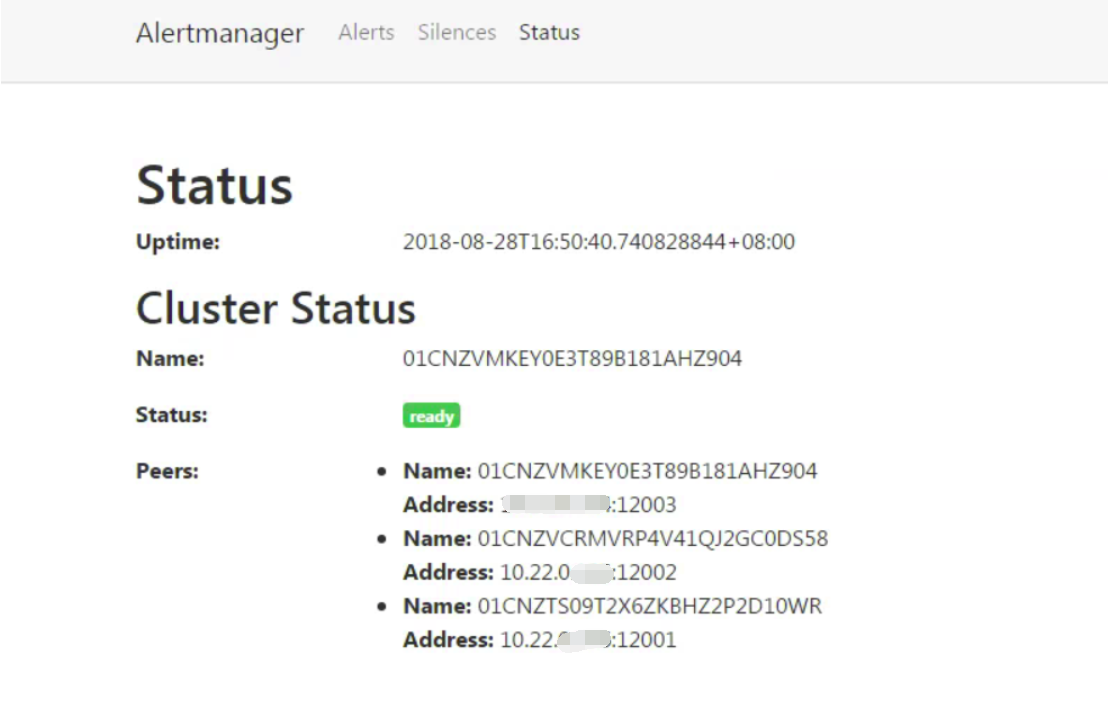
启动完成后访问任意Alertmanager节点http://localhost:9093/#/status,可以查看当前Alertmanager集群的状态。
3.修改各节点prometheus.yml
cd /data/yy-monitor-server/etc
vi prometheus.yml
global: scrape_interval: 5s scrape_timeout: 5s evaluation_interval: 5s # The labels to add to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: dc: europe1# Alertmanager configurationalerting: alert_relabel_configs: - source_labels: [dc] regex: (.+)\d+ target_label: dc alertmanagers: - static_configs: - targets:: ['10.22.0.1000:9093','10.22.0.1001:9093', '10.22.0.1002:9093'] |
global: scrape_interval: 5s scrape_timeout: 5s evaluation_interval: 5s# Note that this is different only by the trailing number. external_labels: dc: europe2# Alertmanager configurationalerting: alert_relabel_configs: - source_labels: [dc] regex: (.+)\d+ target_label: dc alertmanagers: - static_configs: - targets:: ['10.22.0.1000:9093','10.22.0.1001:9093', '10.22.0.1002:9093'] |
global: scrape_interval: 5s scrape_timeout: 5s evaluation_interval: 5s external_labels: dc: europe3# Alertmanager configurationalerting: alert_relabel_configs: - source_labels: [dc] regex: (.+)\d+ target_label: dc alertmanagers: - static_configs: - targets:: ['10.22.0.1000:9093','10.22.0.1001:9093', '10.22.0.1002:9093'] |
2.重启prometheus:
# supervisorctl restart prometheusprometheus: stoppedprometheus: started |
二. Alertmanager代理配置
1.nginx配置
选取一台主机做配置(如:10.22.0.1002)
cd /data/yy-monitor-server/etc
vi nginx.conf
# Alertmanager upstream alert{ server 10.22.0.1002:9093; server 10.22.0.1001:9093; server 10.22.0.1000:9093; } server{ # alertmanager location /alertmanager/ { proxy_pass http://alert/; } } |
重启nginx
# supervisorctl restart nginxnginx: stoppednginx: started |
2.验证配置
停止其中两台服务:
1002 # supervisorctl stop alertmanageralertmanager: stopped1001 # supervisorctl stop alertmanageralertmanager: stopped |
访问ui正常,配置代理成功。
附录:https://github.com/prometheus/alertmanager#high-availability
To create a highly available cluster of the Alertmanager the instances need to be configured to communicate with each other. This is configured using the --cluster.* flags.
--cluster.listen-addressstring: cluster listen address (default "0.0.0.0:9094")--cluster.advertise-addressstring: cluster advertise address--cluster.peervalue: initial peers (repeat flag for each additional peer)--cluster.peer-timeoutvalue: peer timeout period (default "15s")--cluster.gossip-intervalvalue: cluster message propagation speed (default "200ms")--cluster.pushpull-intervalvalue: lower values will increase convergence speeds at expense of bandwidth (default "1m0s")--cluster.settle-timeoutvalue: maximum time to wait for cluster connections to settle before evaluating notifications.--cluster.tcp-timeoutvalue: timeout value for tcp connections, reads and writes (default "10s")--cluster.probe-timeoutvalue: time to wait for ack before marking node unhealthy (default "500ms")--cluster.probe-intervalvalue: interval between random node probes (default "1s")
The chosen port in the cluster.listen-address flag is the port that needs to be specified in the cluster.peer flag of the other peers.
To start a cluster of three peers on your local machine use goreman and the Procfile within this repository.
goreman start
To point your Prometheus 1.4, or later, instance to multiple Alertmanagers, configure them in your prometheus.yml configuration file, for example:
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager1:9093
- alertmanager2:9093
- alertmanager3:9093
Important: Do not load balance traffic between Prometheus and its Alertmanagers, but instead point Prometheus to a list of all Alertmanagers. The Alertmanager implementation expects all alerts to be sent to all Alertmanagers to ensure high availability.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号