Author name disambiguation using a graph model with node splitting and merging based on bibliographic information
Author name disambiguation using a graph model with node splitting and merging based on bibliographic information
基于文献信息进行节点拆分和合并的图模型消歧方法(GFAD)
这是一篇比较早的文章,将人名消歧过程作为一个系统,主要想学习它对消歧过程中的各个阶段的划分
GFAD 是一个面向图的框架,对于元信息缺失,错误信息的存在具有较好的鲁棒性,且不依赖web 环境,也不需要群体数量信息,不需要估计特定的参数或阈值。其中,顶点表示作者,边表示合作关系。
同名问题:分割多个不重叠的环中的共同顶点
异名问题:合并具有不同名的顶点
同时:能够处理异常问题
1. 概述
1. 基于图的作者姓名消歧方法
2. 使用合作关系构建图模型
3. 基于节点分割和合并解决模糊类别
已有研究:
1. 只处理同名问题
2. 依赖于邮件,网页等辅助信息
2. 创新点
涵盖了同名和异名问题
目的:构建对特定域(或数字图书馆)不敏感的通用框架,避免数据缺失和环境错误的影响
只依赖 title 和 co-author
1. 以图表为导向的人名消歧方法,从文献信息分析作者间的关系构建图模型
2. 通过链接合作者推断作者的社交环(过去和现在的学术关系)
3. 利用顶点分割或顶点合并
与以往研究相比:
1. 只需要合著者信息和 title(必要属性)
2. 不要求其他额外信息或估计值
3. 为同名和异名问题提供一个全面的消除歧义的解决方案
3. 整体框架
1. 利用文献信息分析作者关系构建图模型
2. 拆分存在多个合作网络中的顶点解决同名问题
3. 合并同作者不同名字的节点解决异名问题
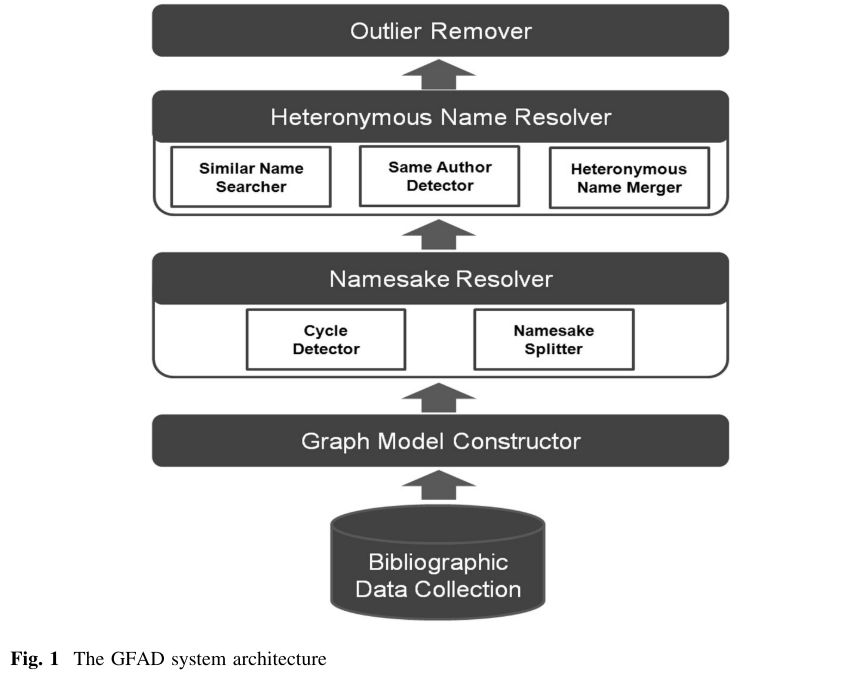
3.1. Graph Model Constructor
图模型建设
合著者是解决作者歧义的最有影响力的因素,将合著者信息构建成一个图,合著者为双向关系
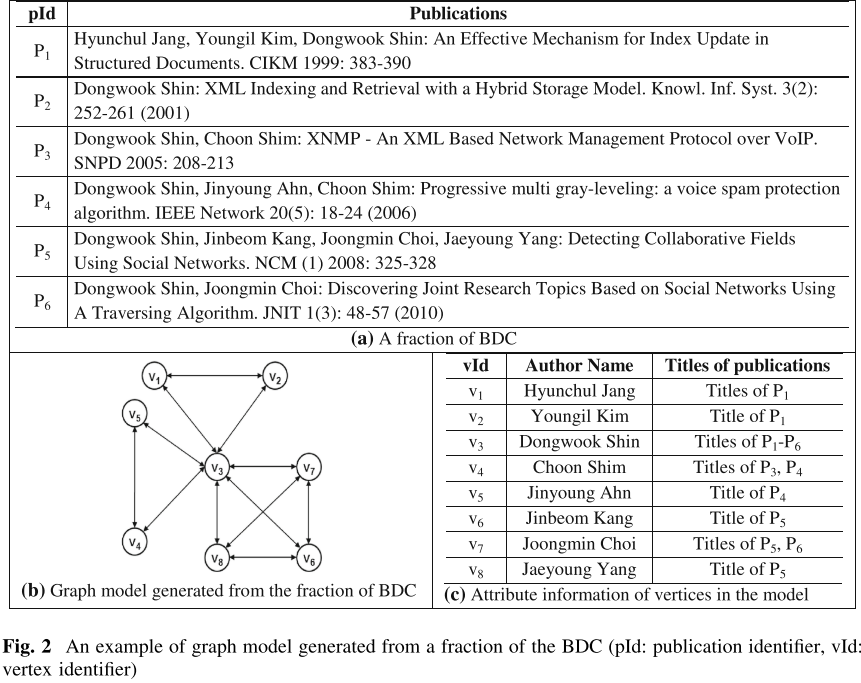
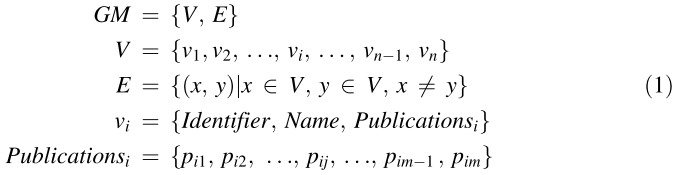
3.2. Namesake Resolver
同名的解析器检测并解决同名问题
假设同一个人同一时期很少在同一个机构工作,社交群体也不同
GFAD将从同一个顶点发出的每个非重叠循环视为不同社交环,循环检测器查找途中具有多个社交环的顶点,名称分割器拆分与多个社交环相关联的顶点
3.2.1. Cycle Detector
算法过程:
1. 如果是别的环的子环,则移除该环
2. 检测并合并在正在检测的环中共享同一顶点的环
Splitting vertices
沿着最长的非重叠环分割包含
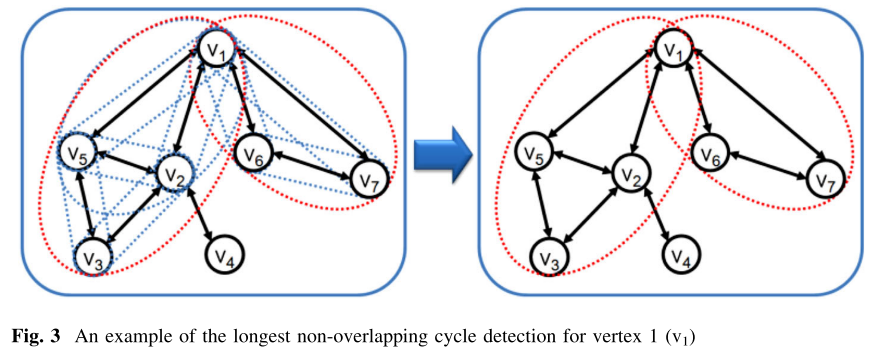
3.2.2. Namesake Splitter
GFAD 是从开始到结束的顶点间没有重复顶点和边的简单环,需要为每个社交圈确定合适的边界。通常,社交圈越宽,将不同的人分到同一个人的可能性越大。
如果BDC 包含相关领域的引用记录,或根据领域构建图,较大的社交圈就不容易出现以上错误
GFAD 将最大的环作为该作者的社交圈,假定,同一个顶点出现在多个最大的社交圈时可能包含同名不同人的作者,因此,我们需要检测每个顶点的最大非重叠环,然后根据这些周期进行顶点分割
3.3. Heteronymous Name Resolver
异名解析器
1. 查找具有相似作者名称,并且相同作者检测器识别表示为同一个人的顶点
2. 异名合并器合并该顶点
同一个作者使用不同名字
GFAD 判断具有相似名字的顶点组,如果该组所有成员至少共享一个公共顶点,则将其视为同一个人
3.3.1. similar name searcher
1. GFAD 使用最长公共子序列( LCS ) 方法检测
2. 使用空格和标点符号作为分隔符标记作者名字,并使用LCS 测量相似度
3. 如果两者相似度 > 0.8 则视为相似
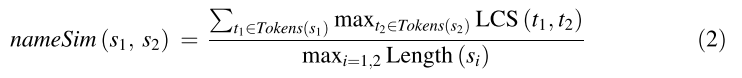
3.3.2. same author detector
两个相似名称的顶点直接或间接的连接到图中的公共顶点,则认为两者为同一个人
3.3.3. heteronymous name merger
一旦确定具有相似名称的作者是同一个人,则合并
3.4. Outlier Remover
孤立点:
缺少消歧所需要的元信息
如:在使用合著关系的系统中,只有一个作者的文章就是孤立点
对于使用作者所属组织的系统中,缺少作者所属信息的文章就是孤立点
GFAD 将异常值根据代表性的关键字的相似性度量,将相应顶点与图模型中最相似的顶点合并
相似度量:
GFAD 将文章中的词汇构成一个特征向量,将其作为关键词,使用余弦相似度,测量异常值和其相似顶点间的相似度
过程:
1. 从 GM 中寻找没有合著信息的顶点
2. 将其中名字相似的顶点标为孤立点,并且选择出有最高相似度的顶点
3. 将孤立点从 GM 中移除,与有最高相似度的节点合并
4. Experiment
分别对比有或没有异常点移除的步骤的效果

孤立点去除将离群点合并成最相似的群,当将单个记录群误解为离群点时,GFAD 性能降低
如何合理的去除离群点?
- 对比使用了哪些属性,信息缺失是否严重
- 如何定义相似性阈值

GFAD-AD: 仅使用共同作者
GFAD-OR:孤立点移除
HHC:使用引用特征的非监督人名消歧
HHC-ALL: 使用所有特征属性(合著者,title,地点)
HHC-CO:仅使用合著者特征
- 使用所有特征属性(合著者,title,地点)
- 在 arnet 上比 GFAD 性能好
- 需要预先定义标题和地址的相似度阈值
- 选择一个唯一的不变的阈值不太现实
GFAD-AD
- 仅使用共同作者
当仅使用共同作者属性时,GFAD-AD 在两集合中都优于 HHC-CO
5. GFAD 局限性
不能处理:
1. 两个同名作者有相同名字但不同人的合作者
2. 虽然是同一个人但没有共同合作者
3. 当由单一作者所著时,没有合著者信息
4. 作者个人资料变更(动态变化)
如果您认为本文对得起您所阅读所花的时间,欢迎点击右下角↘ 推荐。您的支持是我继续写作最大的动力,谢谢 (●'◡'●)
字节跳动职位长期内推,如有需求可发送简历至 lichaoran.cr@bytedance.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号