Hierarchical Attention Based Semi-supervised Network Representation Learning
Hierarchical Attention Based Semi-supervised Network Representation Learning
1. 任务
给定:节点信息网络
目标:为每个节点生成一个低维向量
基于半监督的分层关注网络嵌入方法
2. 创新点:
以半监督的方式结合外部信息
1. 提出SHANE 模型,集成节点结构,文本和标签信息,并以半监督的方式学习网络嵌入
2. 使用分层注意网络学习节点的文本特征, 两层双向GRU 提取单词和句子的潜在特征
3. 背景
1. 现有方法通常基于单词获取节点的文本特征矩阵,忽略分层结构(单词、句子)
2. 不同单词和句子包含不同数量信息,如何评估节点内容的差异性
3. 标签,也是重要的监督信息
4. 网络中存在大量未标记节点,如何合理利用
4. 模型
整合节点的结构,文本和标签信息
基于文本的表示学习
使用分层注意机制
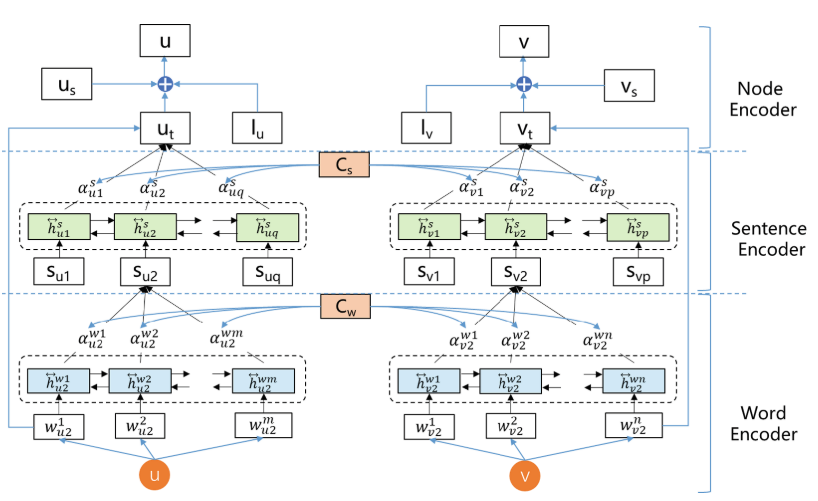
4.1. 问题定义
G = (V, E, T, L)
( V: 节点集
E: 边集合
T: 节点的文本信息
L: 标签节点信息 )
节点u 的文本信息Du = (Su1, Su2,...,Suq)
句子信息 Sui = (Wui..)
给定信息网络,目标:为每个节点u 整合其结构和文本信息 学习一个低维向量 u,
4.2. 基于文本的表示
分层学习可获取不同粒度的文本信息
- 词嵌入:捕获词汇特征
- 句子嵌入: 捕获文本特征
4.2.1. word 编码器
- 使用双向 GRU 编码单词序列
- 使用注意力机制识别重要单词
- 类似:使用双向GRU 编码句子
假设节点 u 包含 q 个句子, 每个句子包含 m 个单词,通过查询获取句子 Sui 的词语序列
使用双向 GRU 编码单词序列
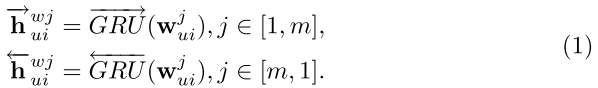
( 通过连接以上两个方向的 h 可包含两个方向的信息,使用注意机制识别词语的重要性,如下)
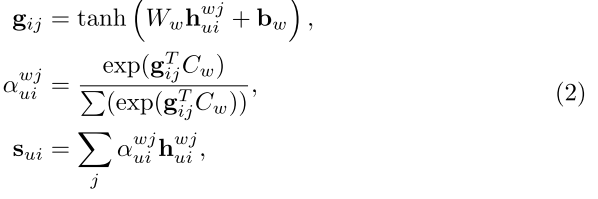
( Sui 是节点 u 第 i 个句子的嵌入, Cw 是全局的词语向量,a 是用于句子表示,融合单词嵌入的权重)
4.2.2. 句子编码器
类似单词编码器,类似的双向GRU ,得到分层编码的文本嵌入 ut
为了避免新的表示与原始文本的偏差,获取分层关注网络的嵌入后,添加该节点词嵌入的平均值向量 Uta,得到节点 u 的文本表示 ut
4.3. 基于结构的表示
含有边的两个节点结构相似
CANE 中将每个部分的对数似然表示为
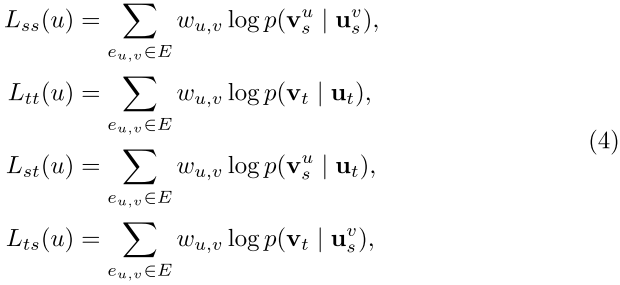
( u 与 v 相连接, Wu,v为权重,Us 是基于结构的嵌入)
u 生成 v 的条件概率为

节点 u 的基于结构的嵌入区别于所连接的节点,结构的最终嵌入为与不同节点连接所得的平均值

( E 为 u 的边)
4.4. 半监督的分层网络嵌入
未标记的节点:只考虑结构和文本特征
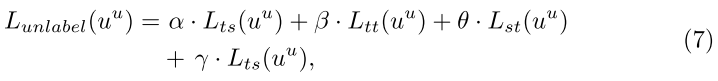
为了匹配标签丢失的节点,我们通过全连接层将节点的嵌入映射到标签空间,可预测节点的标签分布
( Ll 表示有标签的节点子集,有标签的节点的目标函数为:)
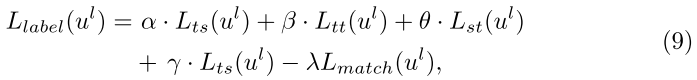
( lamda 是标签损失权重)
SHANE 的全局目标函数:
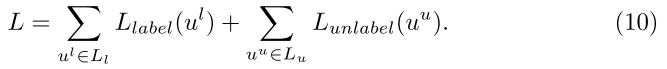
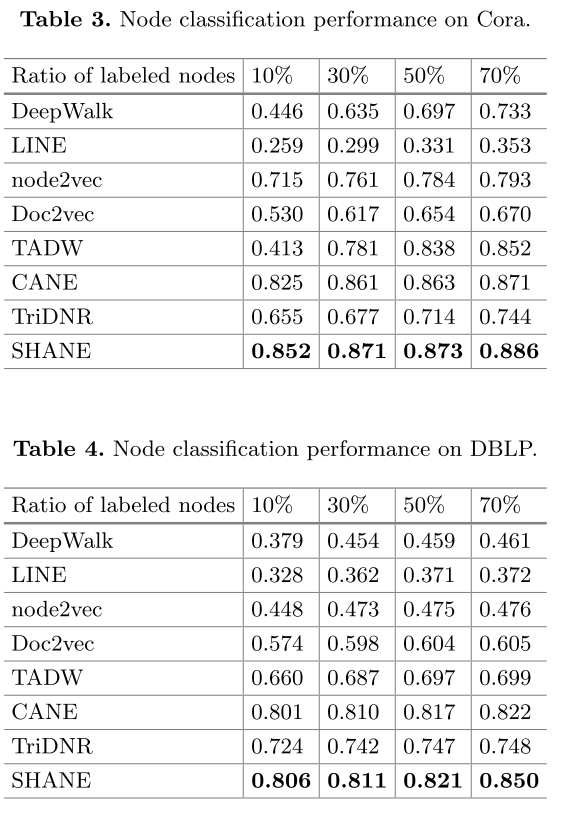
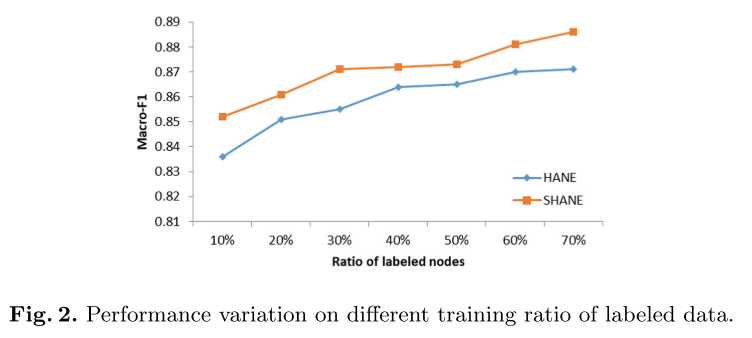
5. 实验
如果您认为本文对得起您所阅读所花的时间,欢迎点击右下角↘ 推荐。您的支持是我继续写作最大的动力,谢谢 (●'◡'●)
字节跳动职位长期内推,如有需求可发送简历至 lichaoran.cr@bytedance.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号