1. Basic idea
基本任务:要得到一个generator,能够模拟想要的数据分布。(一个低维向量到一个高维向量的映射)
discriminator就像是一个score function。
![]()
![]()
如果想让generator生成想要的目标数据,就把这些真实数据作为discriminator的输入,discriminator的另一部分输入就是generator生成的数据。
1. 初始化generator和discriminator。
2. 迭代:
固定generator的参数,更新discriminator的参数,maximize f
固定discriminator的参数,更新generator的参数,minimize f
![]()
noise的先验分布对结果的影响不大
2. GAN as structured learning
Structured Learning/Prediction: 输出一个序列、矩阵、图、树... Output is composed of components with dependency
重要的是各个components之间的关系。
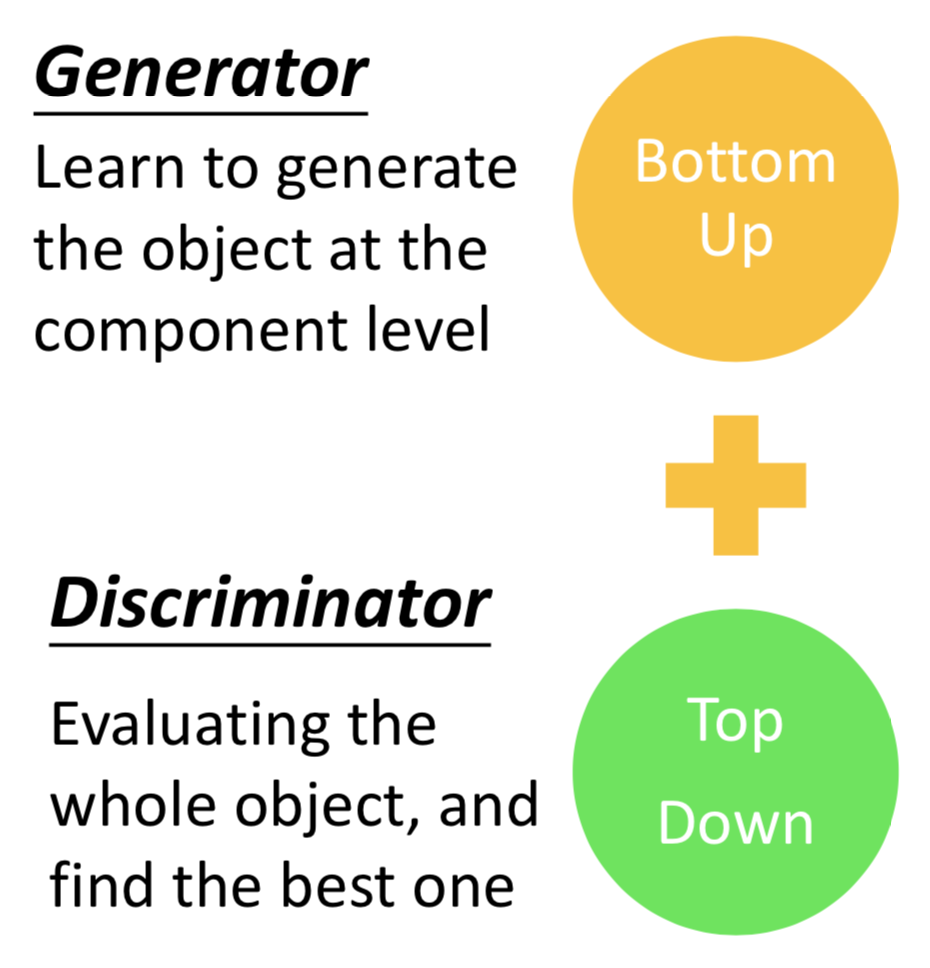
做 structured learning 的两种思路
Bottom up:从component的层面生成object
Top down :整体评价 object,寻找一个最佳的
从这个角度理解 GAN:
3. Can Generator learn by itself?
其实是可以的。把 <code, object> 的 pair 作为训练数据对,据此训练一个NN来拟合code和object之间的映射关系即可。
但问题是:不知道如何把code和object对应起来。(或者说,能反映object中某些特征的code要怎么产生?如何收集这些训练数据对中的code?)
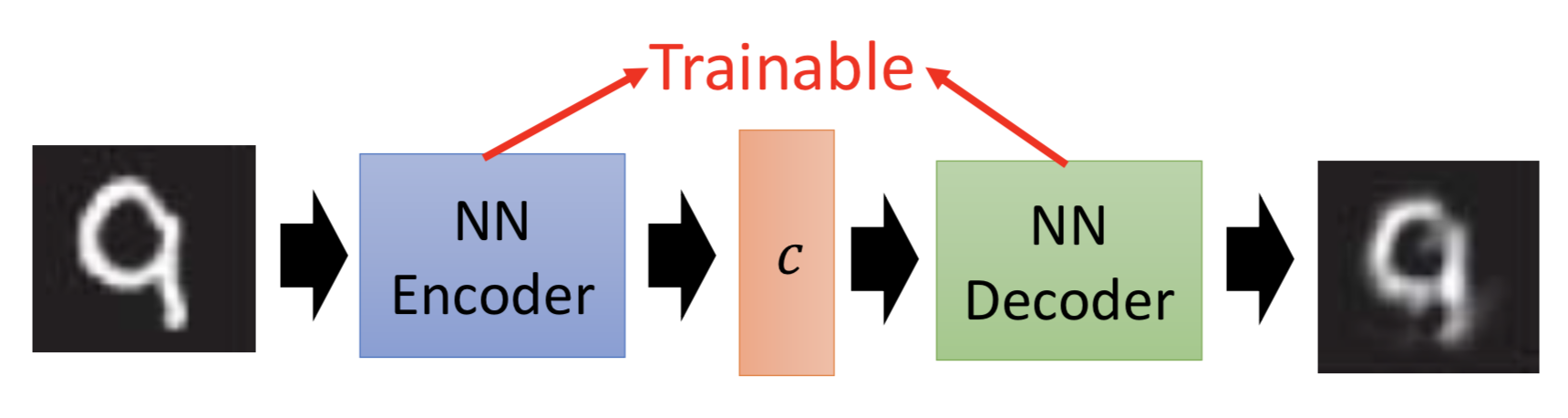
做法:自监督。训练一个ae的encoder,就能把code和object对应起来,获得code。
那么思考到这里,其实decoder就是generator!给定一个code,就能输出对应的object。
既然如此,还要GAN做什么?(或者说,Autoencoder存在什么问题)
因为作为训练数据的object是有限的,导致decoder实际上只能把训练过程中见过的code给还原成对应的object。如果随机给一些code,它不会生成训练集中没有见过的object。
如何解决?
但不管怎么样,训练AE的时候要去最小化的loss,都是定义在 component 层面的,比如 L1 norm distance,L2 norm distance,而神经网络的输出的各个 component 之间尽管是相关的,但是不能互相影响(除非把网络变得很深)。所以单纯让输出和目标在component 层面上越接近越好是不够的。
4. Can Discriminator generate?
输入一个 object 输出一个scalar 表示输入有多好。discriminator 比较容易通过整体去判断生成的结果怎么样,但是无法通过这个方式去做生成(如果非要做,可以穷举所有可能的输入,取 argmax D(x) 的 x )。
问题是,训练 discriminator 的时候要有正类和负类,正类容易搞定因为本来就容易收集,负类就有问题了,negative examples 如果选取的不好(比如就直接用随机噪声),就很难训练好的 discriminator 能够分辨 x。
总结一下两者的优缺点:
5. GAN
综合 generator(用来取代穷举 x 解 argmax D(x) 的问题) 和 discriminator ,迭代地对抗性的训练两部分,一部分做生成一部分做判别。
实际做的话训练discriminator:
如果落在高维空间中 real examples 所在的区域就给高分,落在生成数据的区域就给低分,但是生成数据的区域肯定比真正的数据 real example 之外的区域要小(但 real examples 的区域未必是分数最高的)。因为 real examples 是有限的,所以训练 generator 是让 discriminator 无效的话,就是说让生成的数据的区域跟之前有不同,再去让 discriminator 学的更好。整个迭代地学习过程如下图所示。但这种情况下,也许比较容易出现 overfitting ,所以 real 数据越多越好。
![]()
GAN 的优势,从 generator 和 discriminator 两部分来看,一个是生成容易、一个是判别的整体性
![]()
6. Conditional generation
典型任务:text-to-image,输入一段文字,输出一个对应的图片。
问题是,如果只用一般的监督方法去训练的话,产生的结果是多张图片的平均(比如火车有正面、侧面,但都是火车)。
在做conditional GAN 的时候,Generator 的输入是 z 和 condition,但是 Discriminator 不能只看 Generator 的输出(如果那样的话Generator 只会学着去产生真实的图片,而无视条件),而是要同时看 Generator 的输入。D 要看 condition 和 G(z) 以及 x,输出一个scalar 判断输入,是不是真实的图片+和条件是不是匹配。
训练 D 的时候,负类是有多种情况的。一种是不对的图片+对的条件,一种是对的图片+不对的条件。
拓扑结构上的话,下面的那种 Discriminator 结构可能更合理一点,把到底是条件和数据不匹配、还是生成数据不够好分开来判别。不过比较多的是第一种,把 c 和 x 做 embedding 或别的处理后,直接给到一个network,综合起来判别。
在此基础上,Stack GAN 是把 embedding 后的 vector 分成几部分训练。
image-to-image,可以在Conditional GAN 的基础上,再加上生成图片和真实图片之间的 L1/L2 norm loss。
7. Unsupervised conditional generation
能不能无监督的做条件生成?比如风格转换之类的,要实现从一个 domain 的数据转到另外一个 domain 的数据。
问题是,怎么建立 c 和 x 之间的联系,手里只是有这两种数据而已。
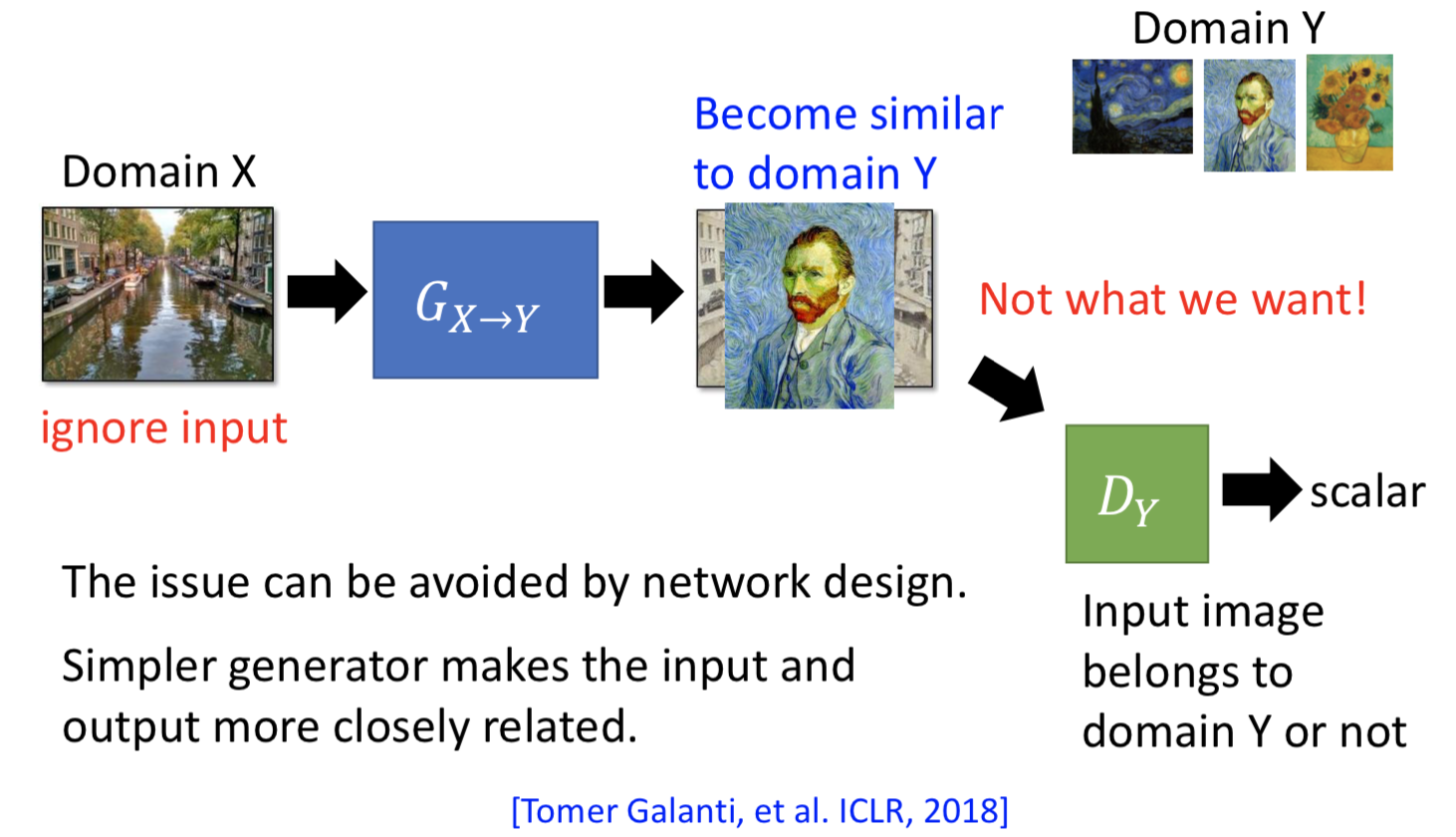
方法一. 直接转换
D的输入是带风格的图片和生成的数据,训练去能够判断输入图片是不是属于目标的输出domain;G就是输入原始图片,训练去让D无效,并且要让 G 的输入和输出还是保持一定的联系(不能光转风格就行了,还得能看的出是原来那个图片)。用这种方法的话,输入输出之间还是不能差太多(风格转换之类的任务)。
![]()
1. 直接忽视 generator 生成数据和输入的联系,硬做就好。但前提是 generator 不要太深(generator 不会把输入变得太多)。
![]()
2. 拿一个 pre-trained 的模型出来,对 generator 的输入和输出都做 embedding。训练 generator 的时候,不仅要骗过 discriminator 让生成图片和目标图片越像越好,同时也要让两个 embedding 后的向量不要差太多。
![]()
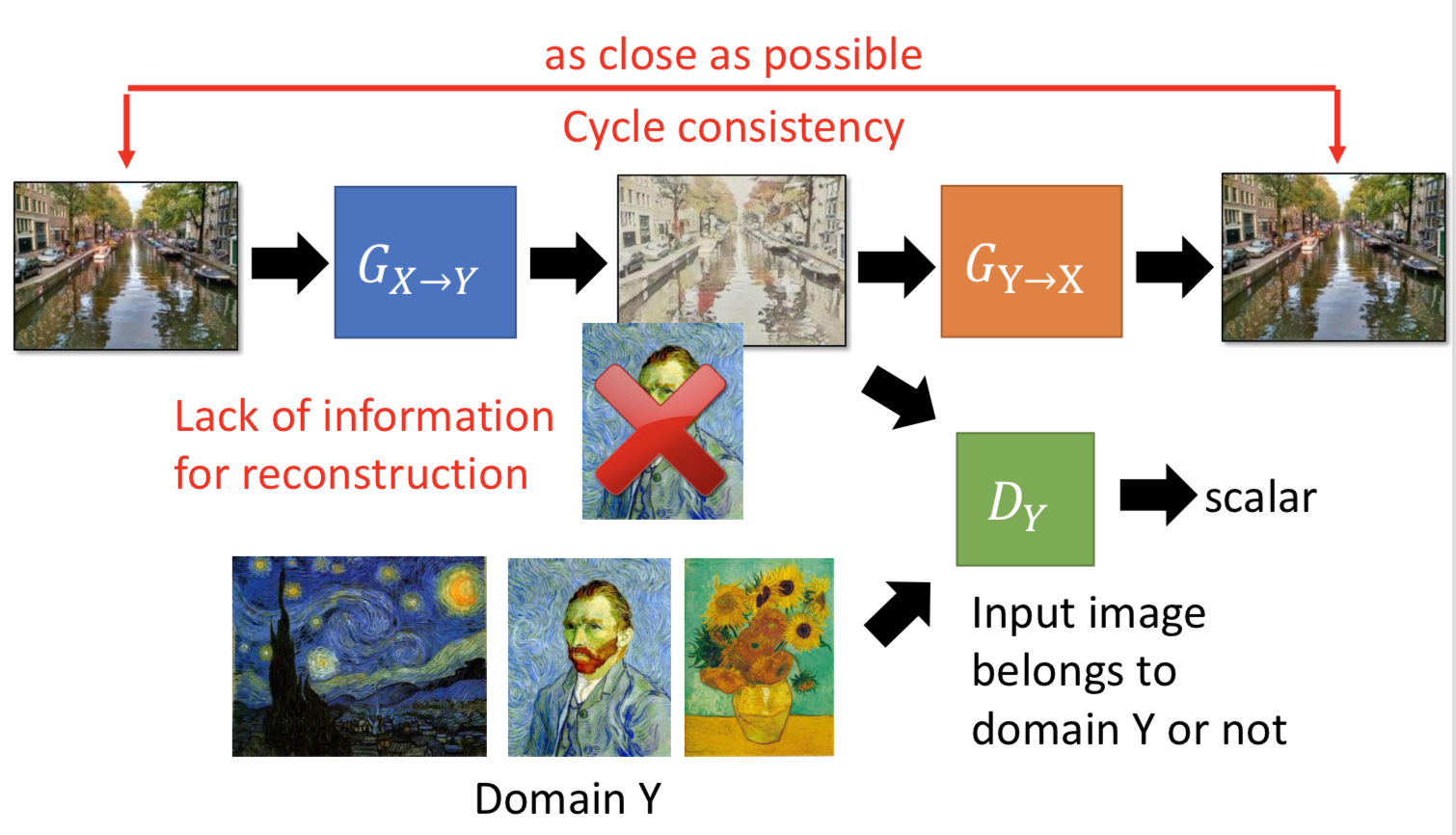
3. Cycle GAN,一个 generator 负责从 domain x 转到 domain y,另一个 generator 负责转回来。所以 generator 不仅要骗过 discriminator,还要使得转回来之后越像越好。Cycle GAN 也可以做双向的。
![]()
4. Star GAN,多个 domain 之间互相转。
方法二. 投到共同的空间里面再去做
如果输入和输出差距很大(比如真人转换为动漫图像),用 encoder 投到 common space (latent space)上去做
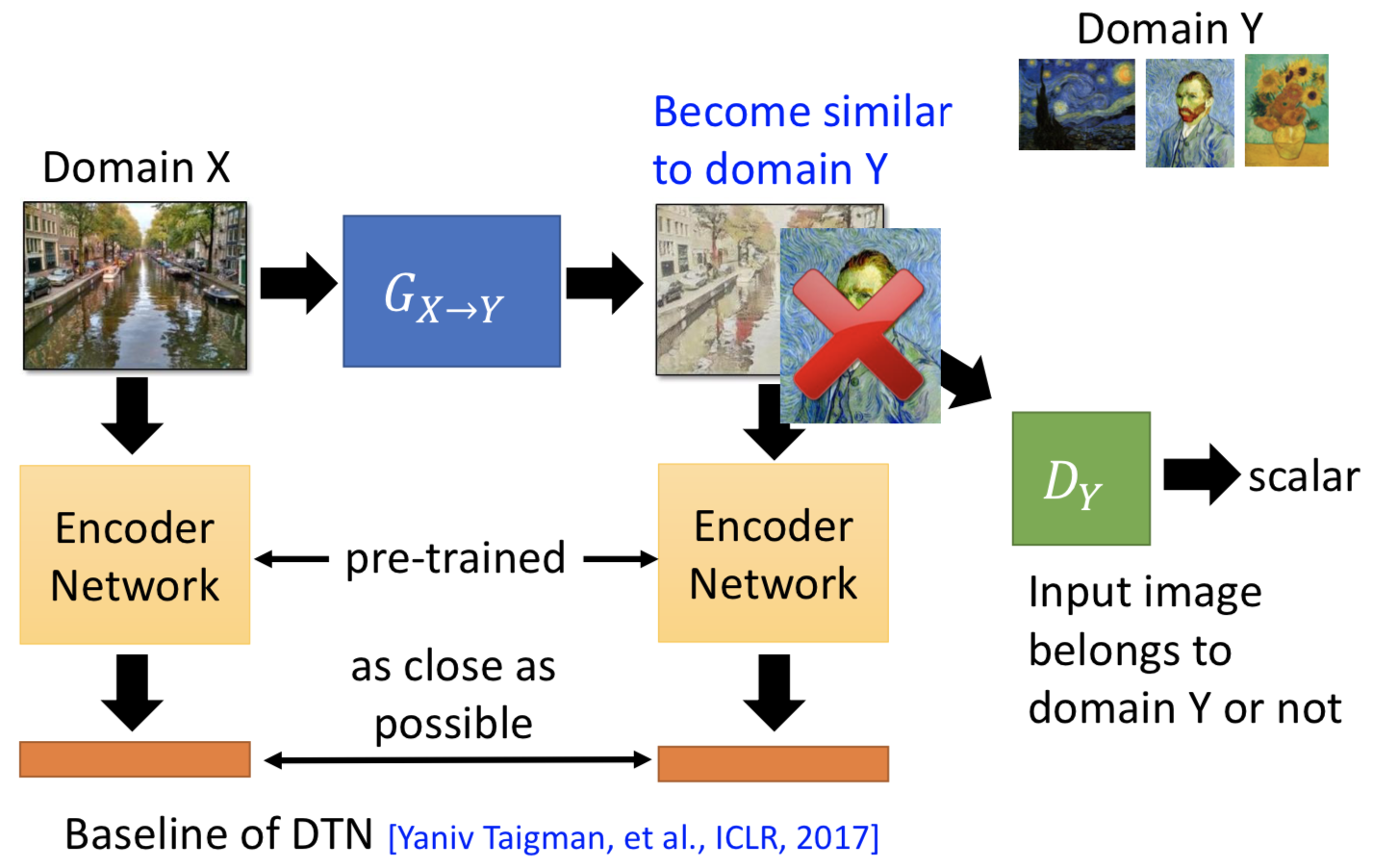
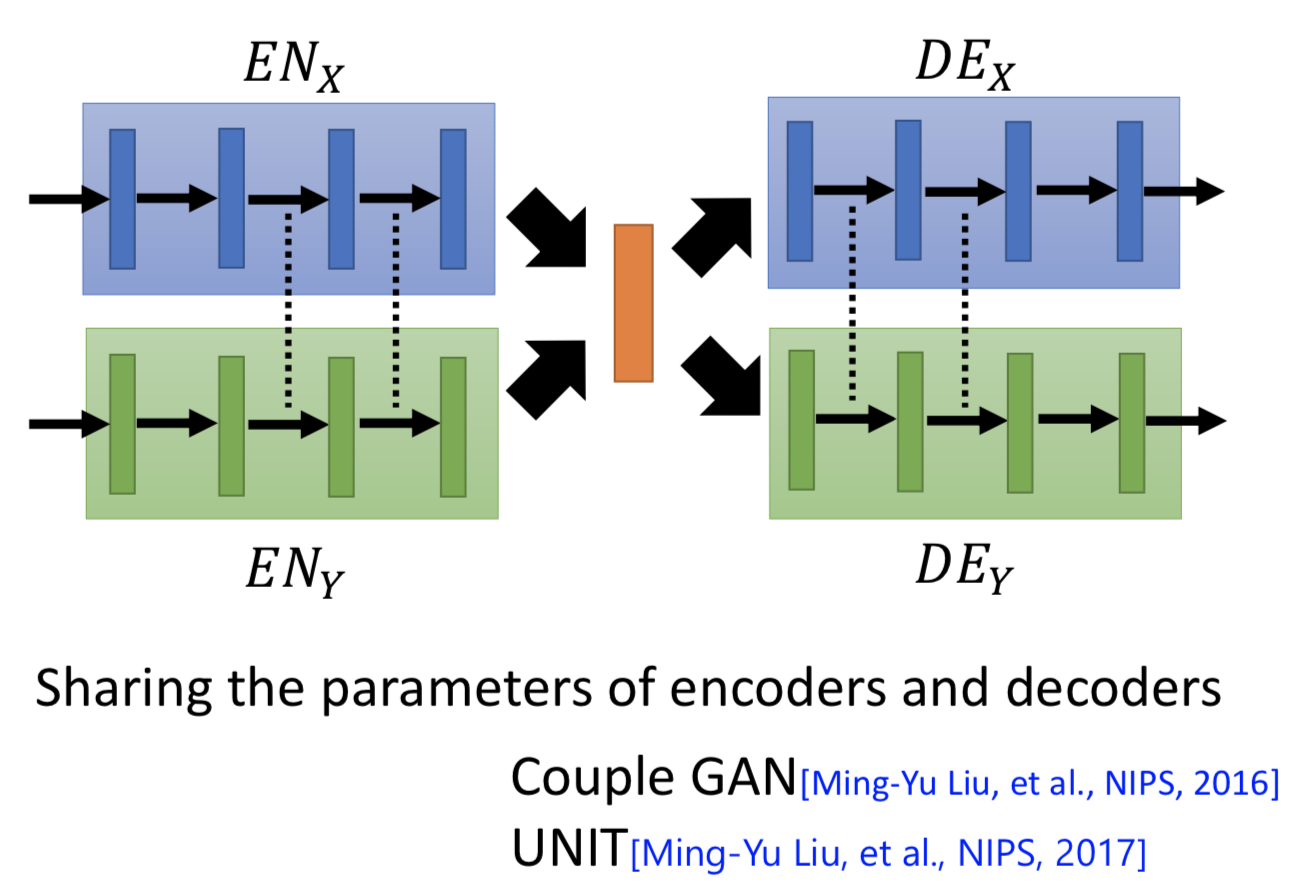
1. VAEGAN,两部分损失,ae的重构损失,和gan的对抗损失。但由于是分开训练两个ae,所以有同样属性的图片经过两个 encoder 之后得到的 code 在 latent space 可能没法映射到同样的位置。解决办法是可以让 domain x 和 domain y 各自的 encoder 最后几层共享参数,decoder的前几层共享参数。
![]()
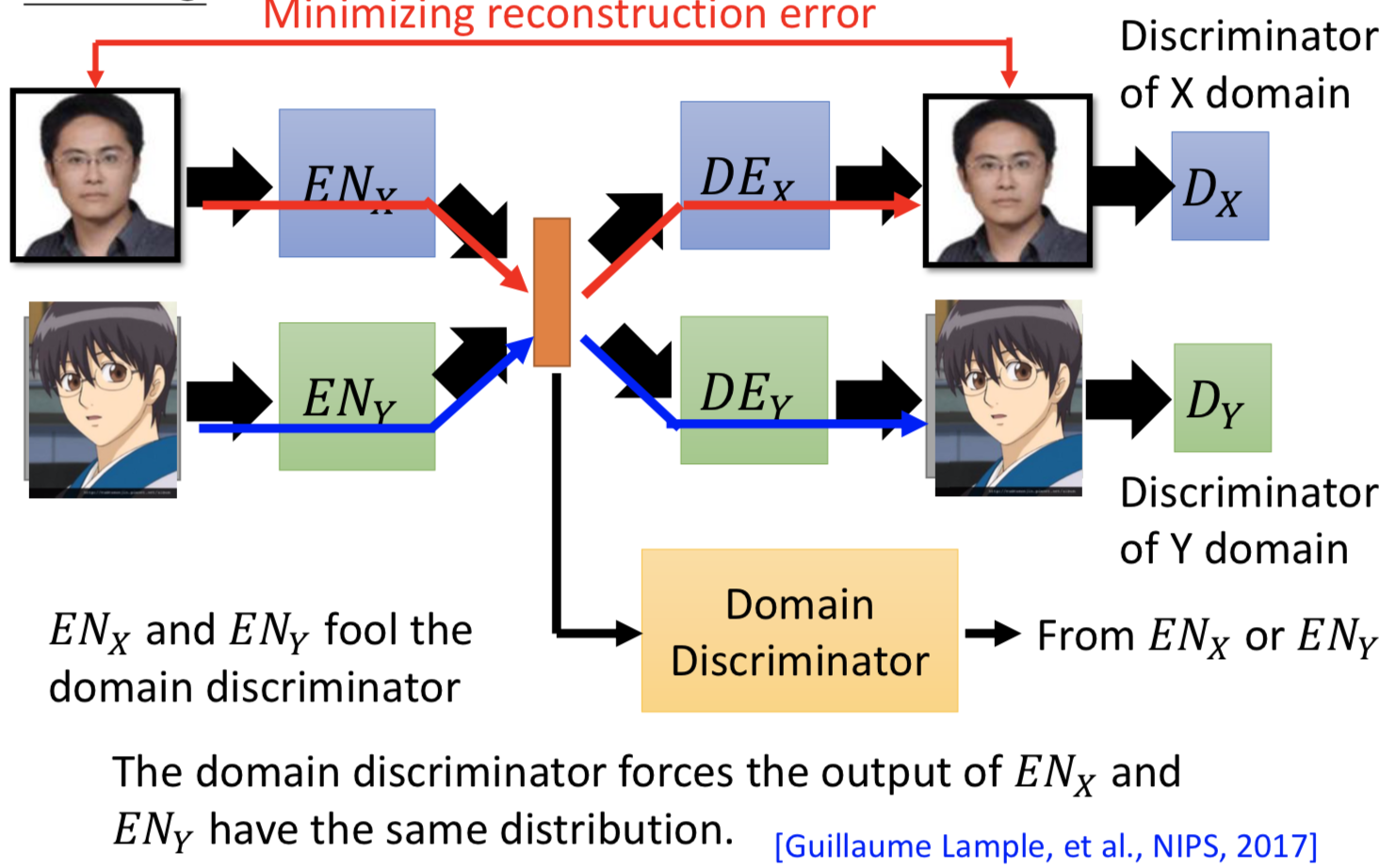
2. 再加一个 domain discriminator,来判别 latent space 的向量是来自 domain x 和 domain y。ENx 和 ENy 就是要骗过这个disriminator,强制不同 domain 的具有同属性的输入经过 encoder 之后都投到一个 latent space 里面并且 code 在空间中的位置越接近越好。
![]()
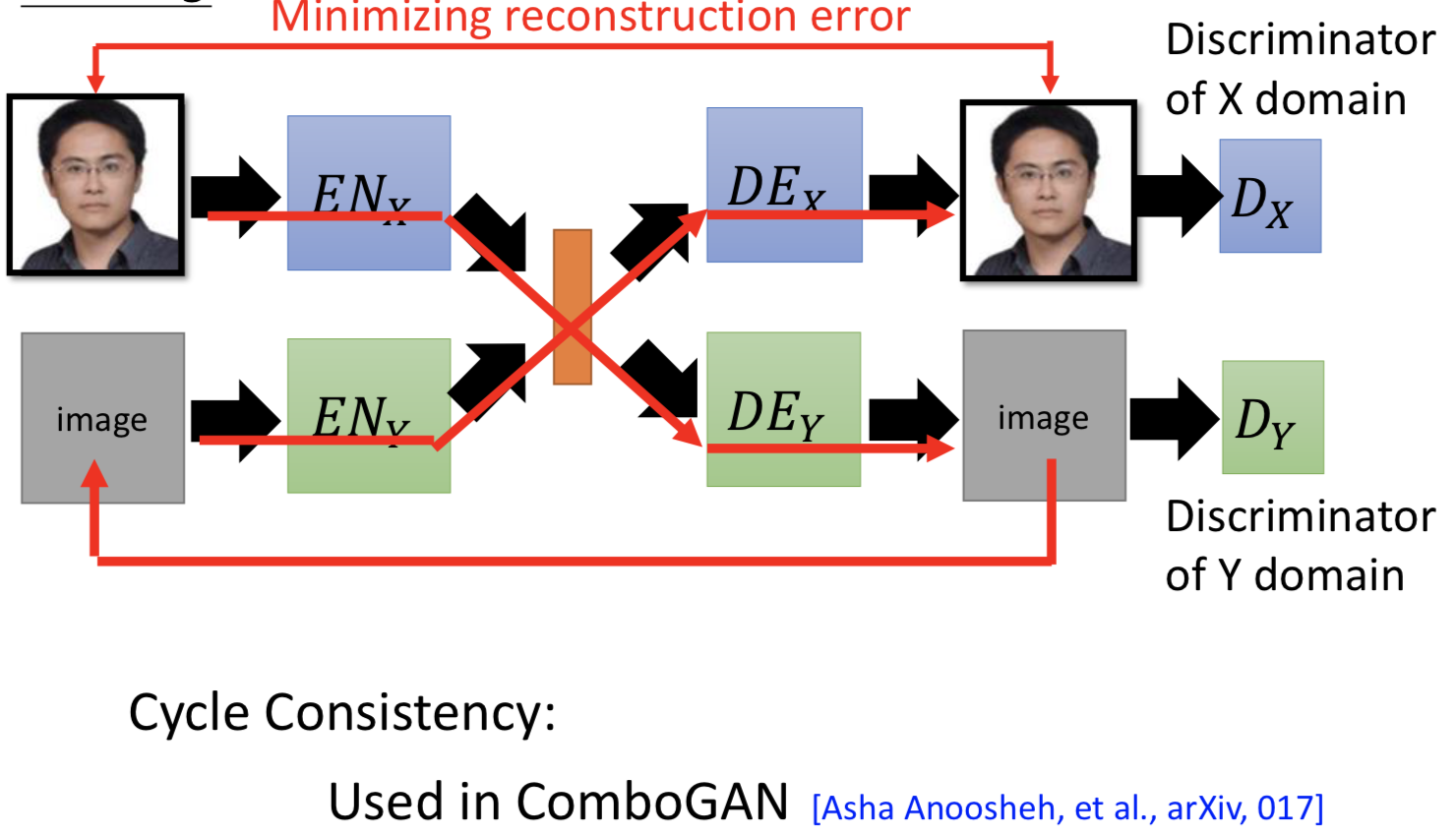
3. cycle consistency
![]()
4. semantic consistency
![]()


















 浙公网安备 33010602011771号
浙公网安备 33010602011771号