线性回归 Linear Regression
一、主要思想
在 L2-norm 的误差意义下寻找对所有观测目标值 Y 拟合得最好的函数 f(X) = WTX 。
其中 yi 是 scalar,xi 和 W 都是 P 维向量(比实际的 xi 多一维,添加一维 xi(0) = 1,用于将偏置 b 写入 W 中)
1. 定义模型:f(X) = WTX
2. 目标函数:L2-norm 损失(均方误差损失)
3. 寻优:梯度下降(迭代)或 最小二乘(解析解)

引入高维可以使得线性回归模型更加复杂,可以在 training data 上拟合的更好,但要考虑 overfitting ,真正关心的应该是模型在 testing data 上的效果

二、正则化
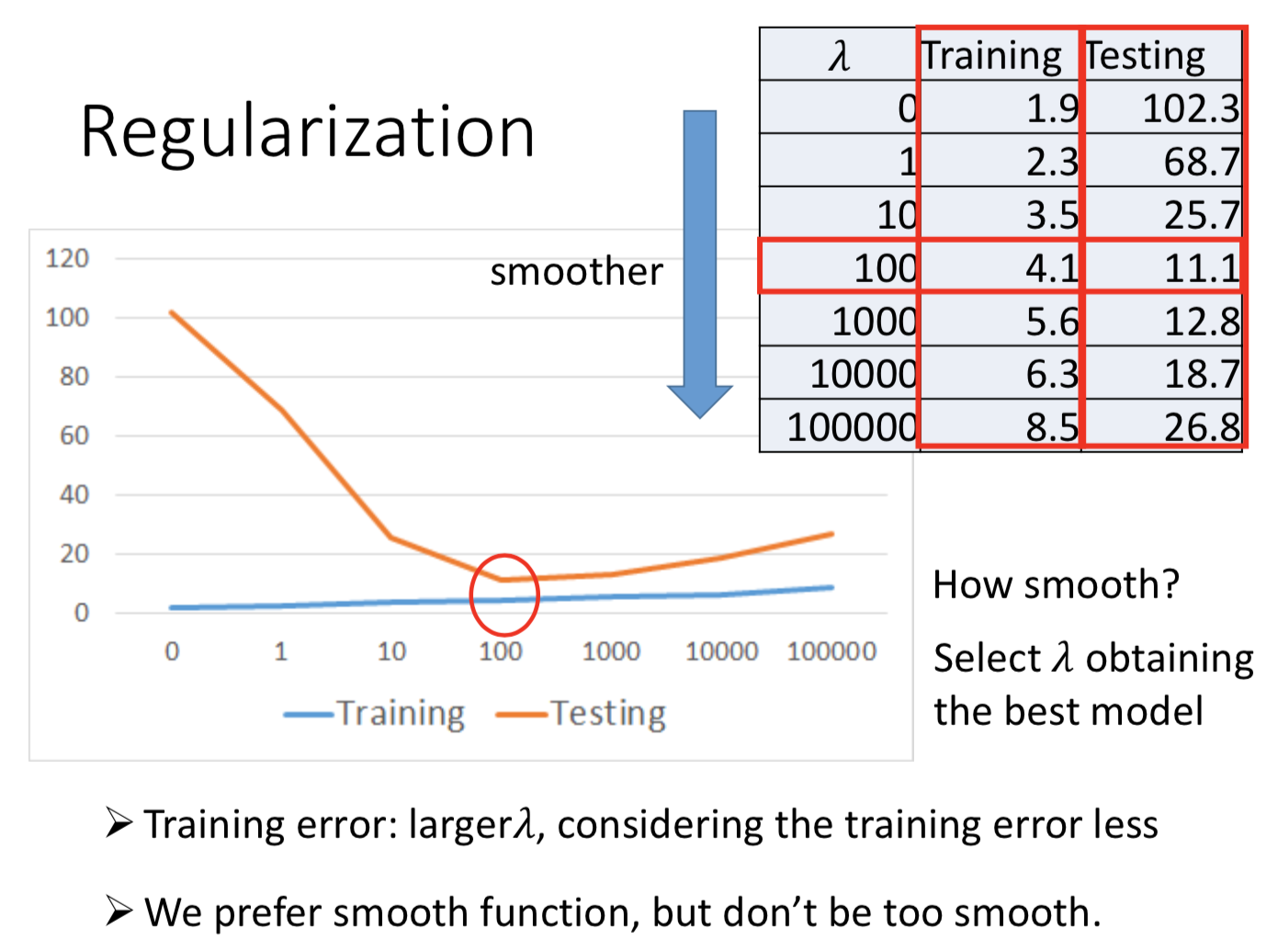
约束参数空间,改善过拟合
通过梯度下降来分析两种正则的区别(Hung-yi Lee)
1. L1 正则的线性回归:Lasso
L1-norm regularization 让参数变小的机制,是每次都减去(if w >= 0)或者加上(if w < 0)一个值(即 λ*learning_rate),不管哪种情况,最后都是让参数往反方向变化。

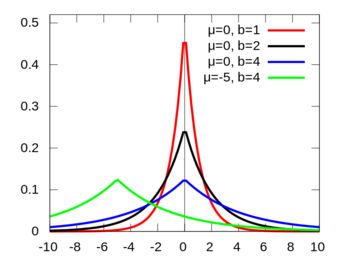

加上L2正则化的最小二乘估计 等价于 噪声 ε 为高斯(0,σ2)、参数 w 先验也为高斯(0, σ02)的最大后验估计
最小二乘法的解析解中 XTX 不可逆怎么处理?
—— XTX + λI (也正是L2正则的效果)

正则化不需要作用在 bias 上,因为偏置项和模型(映射函数)的平滑程度无关,只会上下平移函数。
三、从把误差分散到 P 维的角度考虑线性回归模型
把 f(X) 理解为 P 维向量 X 的线性组合 X·ß
任务:要在 X 所在的 P 维空间里找到一个离Y最近的 X·ß
显然是 Y 在这个 P 维空间的投影,所以 Y-X·ß 垂直于 X,直接求得解析解
四、从概率视角理解线性回归模型
随机变量 X 和 Y 分别表示样本和观测,令 Y = WTX + ε,噪声 ε 服从高斯分布 N(0, σ2)
则 Y | W, X, ε 服从均值偏移 WTX、方差不变的高斯分布 N(WTX, σ2)
MLE:用极大似然估计来寻找参数 W 的值(令似然函数 P(Y | W, X, ε) 最大的 W)
可以发现要 argmin 的函数和最小二乘估计中的平方误差损失函数一致
最小二乘估计 等价于 噪声为高斯的最大似然估计


 浙公网安备 33010602011771号
浙公网安备 33010602011771号