
WebKit Inside: CSS 样式表解码字符集
CSS 样式表引入有3种方式: 外部样式表、内部样式表、行内样式,不同的引入方式,解码样式表的字符集原理不一样。
外部样式表
外部样式表由 link 标签引入,当 WebKit 解析到 link 标签时就会构造 CachedCSSStyleSheet 对象。这个对象持有 CachedResourceRequest 对象和 TextResourceDecoder 对象。CachedResourceRequest 对象负责发送请求,TextResourceDecoder 对象负责对下载回来的 CSS 数据进行解码。TextResourceDecoder 对象里面的 m_encoding 属性,就是存储着解码 CSS 数据使用的字符编码信息。相关类图如下所示:
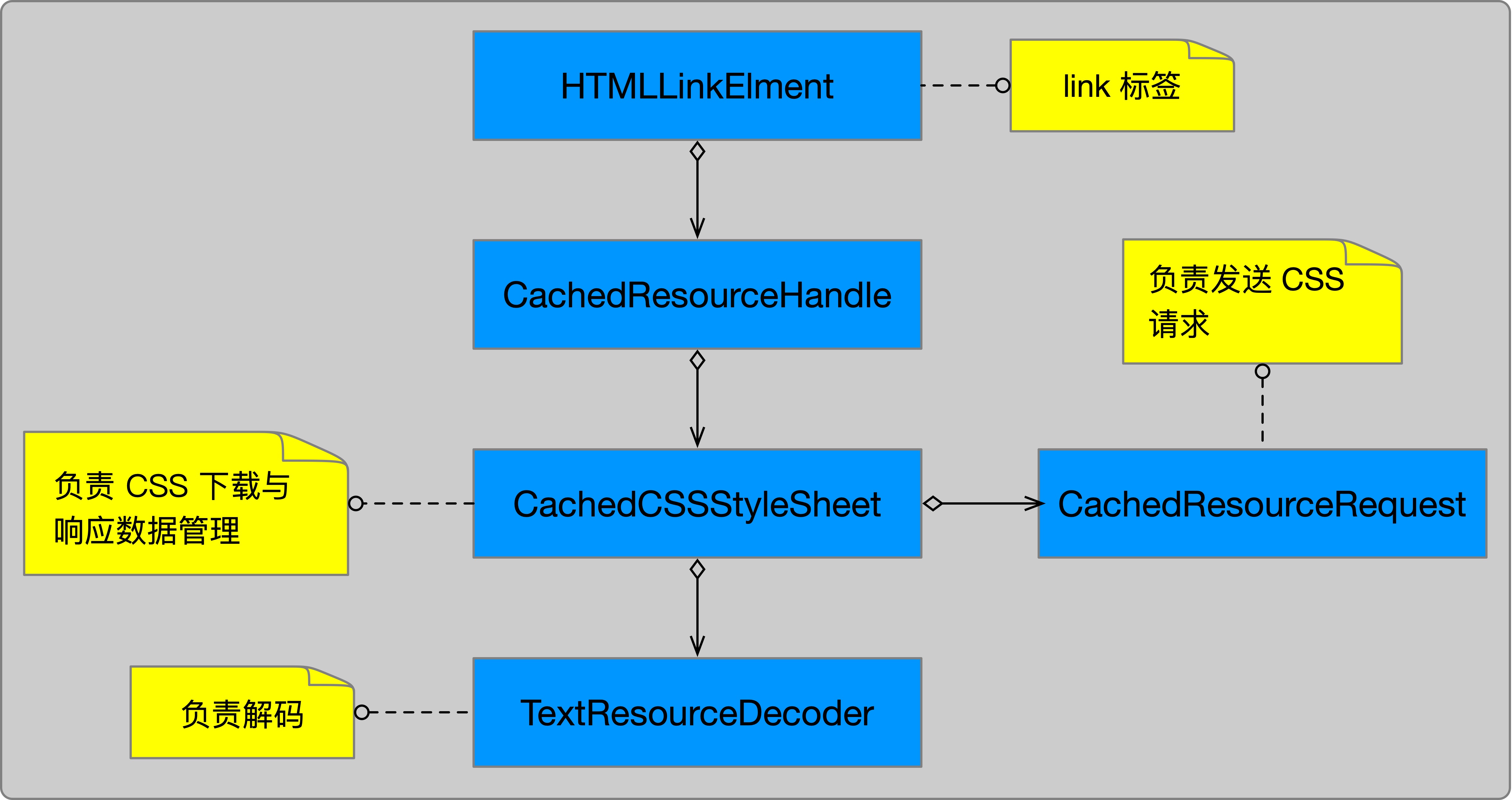
在创建 TextResourceDecoder 对象时,会传入 CachedResourceRequest 使用的字符集信息,代码如下所示:
CachedCSSStyleSheet::CachedCSSStyleSheet(CachedResourceRequest&& request, PAL::SessionID sessionID, const CookieJar* cookieJar) : CachedResource(WTFMove(request), Type::CSSStyleSheet, sessionID, cookieJar) // 1. 创建 TextResourceDecoder,传入 CachedResourceRqeuest 字符集 , m_decoder(TextResourceDecoder::create(cssContentTypeAtom(), request.charset())) { }
在上面代码注释 1 处,就是 CachedCSSStyleSheet 创建 TextResourceDecoder 对象,并且传入了 CachedResourceReqeust 的字符集用来初始化 TextResourceDecoder 内部的 m_encoding 属性,代码如下:
inline TextResourceDecoder::TextResourceDecoder(const String& mimeType, const PAL::TextEncoding& specifiedDefaultEncoding, bool usesEncodingDetector) : m_contentType(determineContentType(mimeType)) // 1. specifiedDefaultEncoding 就是传入的 CachedResourceRequest 的字符集 // m_contentType 此时是 CSS , m_encoding(defaultEncoding(m_contentType, specifiedDefaultEncoding)) , m_usesEncodingDetector(usesEncodingDetector) { }
在上面代码注释 1 处初始化 TextResourceDecoder 的 m_encoding 属性,m_contentType 此时的值是 CSS,specifiedDefaultEncoding 就是 CachedResourceRequest 的字符集。但是在初始化 m_encoding 时,并不是直接将 m_encoding 直接赋值为 specifiedDefaultEncoding,而是调用了 TextResourceDecoder::defaultEncoding 函数,相关代码如下:

const PAL::TextEncoding& TextResourceDecoder::defaultEncoding(ContentType contentType, const PAL::TextEncoding& specifiedDefaultEncoding) { // Despite 8.5 "Text/xml with Omitted Charset" of RFC 3023, we assume UTF-8 instead of US-ASCII // for text/xml. This matches Firefox. // 1. 如果解码的是 XML ,那么无论传入的 specifiedDefaultEncoding 是什么值,都使用 UTF-8 作为默认解码字符集 if (contentType == XML) return PAL::UTF8Encoding(); // 2. 对于其他资源类型,如果 specifiedDefaultEncoding 使用的字符集名为 null,就默认使用 Latin-1 字符集, // 也就是 ISO-8859-1 if (!specifiedDefaultEncoding.isValid()) return PAL::Latin1Encoding(); // 3. 将 specifiedDefaultEncoding 作为 TextResourceDecoder 的默认解码字符集 return specifiedDefaultEncoding; }
上面代码注释 1 处可以看出,TextResourceDecoder 不仅用来解码 CSS,还可以用来解码其他资源类型。如果解码的资源类型是 XML,那么默认的解码字符集就是 UTF-8。
从注释 2 处可以看到,如果不是 XML 资源类型,并且 specifiedDefaultEncoding 不合法,也就是 specifiedDefaultEncoding 内部代码字符集名的 m_name 属性为 null,那么就使用 Latin-1(也就是 ISO-8859-1) 作为 TextResourceDecoder 的默认解码字符集。
从注释 3 可以看到,对于非 XML 资源类型,specifiedDefaultEncoding 就会作为 TextResourceDecoder 的默认解码字符集。也就是会说,解码 CSS 的默认字符集和 CacheResourceRequest 使用同一个字符集。
那么,CacheResourceRequest 的字符集是如何来的呢?相关代码如下:
void HTMLLinkElement::process() { ... if (m_disabledState != Disabled && treatAsStyleSheet && document().frame() && m_url.isValid()) { // 1. 解析 link 标签的 charset 属性值 String charset = attributeWithoutSynchronization(charsetAttr); if (!PAL::TextEncoding { charset }.isValid()) // 2. 获取文档 Document 使用的字符集 charset = document().charset(); ... // 3. 设置 CachedResourceRequest 的字符集 request.setCharset(WTFMove(charset)); ... return; } ... }
上面代码注释 1 处首先解析 link 标签的 charset 属性,如果解析到就使用这个字符集作为 CachedResourceRequest 的字符集,如 注释 3所示。如果解析不到,就使用文档 Document 的字符集作为 CachedResourceReqeust 的字符集,如注释 2 所示。文档 Document 的字符集由 <meta> 标签指定,如果没有 <meta> 标签,那么文档 Document 默认使用 Latin-1 字符集(ISO-8859-1)。
但是,解码 CSS 使用的字符集此时还并没有完全确定,因为 CSS 样式表本身支持 @charset at-rule,它可以指定解码 CSS 样式表需要使用什么字符集。因此,当从网络上下载到 CSS 样式表之后,还需要检测 CSS 样式表里面是否有 @charset at-rule,相关代码如下:
String TextResourceDecoder::decode(const char* data, size_t length) { ... if (m_contentType == CSS && !m_checkedForCSSCharset) // 1. 当下载完 CSS 样式表,这里调用 checkForCSSCharset 函数,检测样式表里是否有 @charset if (!checkForCSSCharset(data, length, movedDataToBuffer)) return emptyString(); ... }
上面代码注释 1处,当下载完 CSS 样式表使用 TextResourceDecoder 进行解码时,会调用 TextResourceDecoder::checkForCSSCharset 检测 CSS 样式表里面是否有 @charset at-rule。如果有 @charset at-rule,那么就将 TextResourceDecoder 的 m_encoding 属性值设置为 @charset 指定的字符集。
综上所述,对于外部引入的样式表,解码字符集的优先级为:
1 如果样式表有 @charset at-rule,就优先使用 @charset 指定的字符集;
2 否则,就看 link 标签有没有 charset 属性,有的话就优先使用 link 标签 charset 属性指定的字符集;
3 否则,就使用文档 Document 的字符集。
内部样式表与行内样式
由于内部样式表和行内样式本身就在 HTML 文件里面,因此对于它们的解码就使用 HTML 字符集。HTML 解码字符集确认规则如下:
1 如果有 <meta> 标签,就使用 <meta> 标签使用的字符集;
2 否则,就默认使用 Latin-1(ISO-8859-1) 字符集


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· CSnakes vs Python.NET:高效嵌入与灵活互通的跨语言方案对比
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· Plotly.NET 一个为 .NET 打造的强大开源交互式图表库
· 上周热点回顾(2.17-2.23)