深度学习基础课:最大池化层的前向传播推导
深度学习基础课:最大池化层的前向传播推导
大家好~本课程为“深度学习基础班”的线上课程,带领同学从0开始学习全连接和卷积神经网络,进行数学推导,并且实现可以运行的Demo程序
线上课程资料:
加QQ群,获得ppt等资料,与群主交流讨论:106047770
本系列文章为线上课程的复盘,每上完一节课就会同步发布对应的文章
本课程系列文章可进入索引查看:
深度学习基础课系列文章索引
回顾相关课程内容
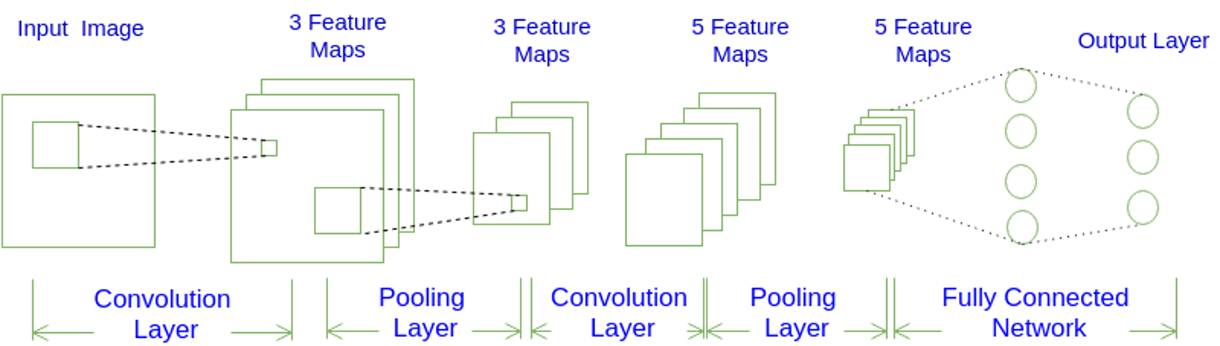
- 卷积神经网络的常用架构模式是是什么?
- 最大池化层在卷积神经网络中的作用是什么?
为什么要学习本课
- 如何推导最大池化层的前向传播?
主问题:如何推导最大池化层的前向传播?
-
最大池化层的输入和输出是什么?
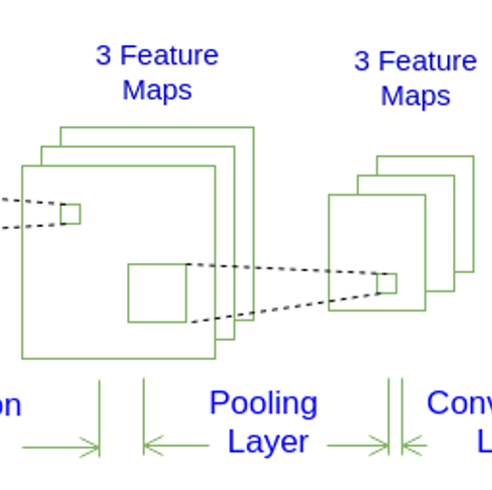
答:输入是上一层(卷积层)输出的多个Feature Map,输出是对每个Feature Map进行了下采样后的多个Feature Map,其中输出的Feature Map的个数与输入的个数相同 -
最大池化层是否包含Filter?
答:是 -
Filter的作用是什么?
答:Filter属于抽象的概念,并没有实际的值。它的作用是取对应区域的最大值 -
有几个Filter?
答:1个 -
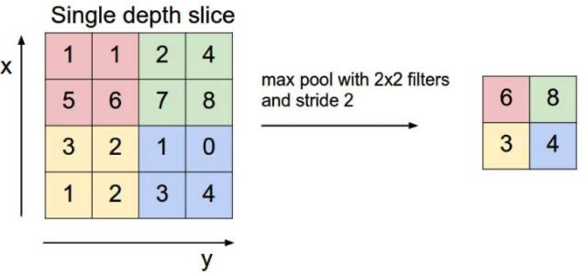
假设有一个\(4*4\)的Feature Map,使用一个\(2*2\)的filter和步幅为2的最大池化层,得到一个\(2*2\)的Feature Map,如下图所示:
-
计算的公式是什么?
答:
\[a_{i,j} = max(
\begin{bmatrix}
x_{i * stride, j * stride} & \cdots & x_{i * stride + stride - 1, j * stride } \\
\vdots & \ddots & \vdots \\
x_{i * stride, j * stride + stride - 1} & \cdots & x_{i * stride + stride - 1, j * stride + stride - 1} \\
\end{bmatrix}
)
\]
\[
用x_{i,j}来表示输入Feature Map的第i行第j列元素; \\
用a_{i,j}表示输出Feature Map的第i行第j列元素;\\
\]
- 如果输入Feature Map的深度大于1,计算的公式是什么?
答:
\[a_{d, i,j} = max(
\begin{bmatrix}
x_{d, i * stride, j * stride} & \cdots & x_{d, i * stride + stride - 1, j * stride } \\
\vdots & \ddots & \vdots \\
x_{d, i * stride, j * stride + stride - 1} & \cdots & x_{d, i * stride + stride - 1, j * stride + stride - 1} \\
\end{bmatrix}
)
\]
\[
用x_{d, i,j}来表示输入Feature Map的第d层第i行第j列元素; \\
用a_{d, i,j}表示输出Feature Map的第d层第i行第j列元素;\\
\]
- 如何计算输出Feature Map大小?
\[W_2 = ? \\
H_2 = ? \\
其中,W_2是输出Feature Map的宽度,H_2是输出Feature Map的高度; \\
W_1是输入Feature Map的宽度,H_1是输入Feature Map的高度;\\
F是Filter的宽度(等于高度),S是步幅
\]
答:
\[W_2 = \frac{W_1 - F}{S} + 1\\
H_2 = \frac{H_1 - F}{S} + 1 \\
其中,W_2是输出Feature Map的宽度,H_2是输出Feature Map的高度; \\
W_1是输入Feature Map的宽度,H_1是输入Feature Map的高度;\\
F是Filter的宽度(等于高度),S是步幅
\]
任务:实现最大池化层的前向传播
- 请实现最大池化层的前向传播?
答:待实现的代码为:MaxPoolingLayer,实现后的代码为:MaxPoolingLayer_answer - 请运行最大池化层的代码,检查前向传播的输出是否正确?
答:在Test.init函数中,构造了输入数据和MaxPooling Layer;
在Test.test函数中,进行了前向传播并打印了结果。
结果为两个Feature Map,它的数据如下所示:
["f:",[
[2,2,[3,2,1,2]],
[2,2,[5,2,2,2]]
]]
我们可以手动计算下\(a_{0,0,0}\),结果等于3,与输出的结果相同,证明forward的实现是正确的
感谢您的阅读~
扫码加入我的QQ群:

扫码加入免费知识星球-YYC的Web3D旅程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号