从0开发3D引擎(五):函数式编程及其在引擎中的应用
大家好,本文介绍我们为什么使用函数式编程来开发引擎,以及它在引擎中的相关的知识点。
上一篇博文
下一篇博文
函数式编程的优点与缺点
优点
(1)粒度小
面向对象编程以类为单位,而函数式编程以函数为单位,粒度更小。
我只想要一个香蕉,而面向对象却给了我整个森林
(2)擅长处理数据,适合3D领域的编程
通过高阶函数、柯西化、函数组合等工具,函数式编程可以像流水线一样对数据进行管道操作,非常方便。
而3D程序正好要处理大量的数据,从函数式编程的角度来看:
3D程序=数据+逻辑
因此,我们可以这样使用函数式编程范式来进行3D编程:
- 使用Immutable/Mutable数据结构、Data Oriented思想来表达数据
- 使用函数来表达逻辑
- 使用组合、柯西化等操作作为工具,把数据和逻辑关联起来,进行管道操作
现代的3D引擎越来越倾向于面向数据进行设计,从而获得更佳的性能,如Unity新版本有很多Data Oriented的思想;
也越来越倾向于使用函数式编程范式,如Frostbite使用Frame Graph来封装现代图形API(DX12),而Frame Graph是面向数据的,有函数式风格的编码框架。
缺点
(1)存在性能问题
-
Reduce、Map、Filter等操作需要遍历多次,会增加时间开销
我们可以通过下面的方法来优化:
a)减少不必要的Map、Reduce等操作;
b)使用transducer来合并这些操作。具体可以参考Understanding transducer in Javascript -
柯西化、组合等操作会增加时间开销
-
每次操作Immutable数据,都需要复制它为新的数据,增加了时间和内存开销
为什么使用Reason语言
本系列使用Reason语言来实现函数式编程。
Reason语言可以解决前面提到的性能问题:
-
Bucklescript编译器在编译时进行了很多优化,使柯西化、组合等操作和Immutable数据被编译成了优化过的js代码,大幅减小了时间开销和内存开销
更多编译器的优化以及与Typescript的比较可参考:
架构最快最好的To JS编译器 -
Reason支持Mutable变量、for/while进行迭代遍历、非纯函数
在性能热点处可以使用它们来提高性能,而在其它地方则尽量使用Immutable数据、递归遍历和纯函数来提高代码的可读性和健壮性。
另外,Reason属于“非纯函数式编程语言”,为什么不使用Haskell这种“纯函数式编程语言”呢?
因为以下几点原因:
(1)获得更高的性能
在性能热点处使用非纯操作(如使用Mutable变量),提高性能。
(2)更简单易用
Reason允许非纯函数,不需要像Haskell一样使用各种Monad来隔离副作用,保持“纯函数”;
Reason使用严格求值,相对于Haskell的惰性求值更简单。
函数式编程学习资料
-
JS 函数式编程指南
这本书作为我学习函数式编程的第一本书,讲得很简单易懂,非常容易上手,推荐~ -
Awesome FP JS
收集了函数式编程相关的资料。 -
F# for fun and profit
这个博客讲了很多F#相关的函数式编程的知识点,介绍了怎样基于类型来设计、怎样处理错误等,非常全面和通俗易懂,强力推荐~
Reason语言基于Ocaml语言,而Ocaml语言与F#语言都属于ML语言类别的,很多概念和语法都类似,所以读者在该博客学到的内容,也可以直接应用到Reason。
引擎中相关的函数式编程知识点
本文从以下几个方面进行介绍:
数据
因为我们不使用全局变量,而是通过形参传入函数需要的变量,所以所有的变量都是函数的局部变量。
我们把与引擎相关的需要持久化的数据,聚合在一起成为一个Record类型的数据,命名为“State”。该Record的一些成员是可变的(用来存放性能优先的数据),另外的成员是不可变的。
关于Record数据结构,可以参考Record。
不可变数据
介绍
不能直接修改不可变数据的值。
创建不可变数据之后,对其任何的操作,都会返回一个复制后的新数据。
示例
变量默认为不可变的(Immutable):
//a为immutable变量
let a = 1;
//导致编译错误
a = 2;
Reason也有专门的不可变数据结构,如Tuple、List、Record。
其中,Record类似于Javascript中的Object,我们以它为例,来看下如何使用不可变数据结构:
首先定义Record的类型:
type person = {
age: int,
name: string
};
然后定义Record的值,它被编译器推导为person类型:
let me = {
age: 5,
name: "Big Reason"
};
最后操作这个Record,如修改“age”的值:
let newMe = {
...me,
age: 10
};
Js.log(newMe === me); /* false */
newMe是从me复制而来的。任何对newMe的修改,都不会影响me。
(这里Reason进行了优化,只复制了修改的age字段,没有复制name字段 )
在引擎中的应用
大部分数据都是不可变的(是不可变变量,或者是Tuple,Record等数据结构),这样的优点是:
1)不用关心数据之间的关联关系,因为每个数据都是独立的
2)不可变数据不能被修改
相关资料
Reason->Let Binding
Reason->Record
facebook immutable.js 意义何在,使用场景?
Introduction to Immutable.js and Functional Programming Concepts
可变数据
介绍
对可变数据的任何操作,都会直接修改原数据。
示例
Reason使用"ref"关键字定义Mutable变量:
let foo = ref(5);
//将foo的值取出来,设置到five这个Immutable变量中
let five = foo^;
//修改foo的值为6,five的值仍然为5
foo := 6;
Reason也可以通过"mutable"关键字,定义Record的字段为Mutable字段:
type person = {
name: string,
mutable age: int
};
let baby = {name: "Baby Reason", age: 5};
//修改原数据baby->age的值为6
baby.age = baby.age + 1;
在引擎中的应用
因为操作可变数据不需要拷贝,没有垃圾回收的开销,所以在性能热点处常常使用可变数据。
相关资料
Reason->Mutable
函数
函数是第一等公民,函数即是数据。
相关资料:
如何理解在 JavaScript 中 "函数是第一等公民" 这句话?
Reason->Function
纯函数
介绍
纯函数是这样一种函数,即相同的输入,永远会得到相同的输出,而且没有任何可观察的副作用。
示例
let a = 1;
/* func2是纯函数 */
let func2 = value => value;
/* func1是非纯函数,因为引用了外部变量"a" */
let func1 = () => a;
在引擎中的应用
脚本组件的钩子函数(如init,update,dispose等函数,这些函数会在主循环的特定时间点被调用,从而执行函数中用户的逻辑)属于纯函数,这样是为了:
1)在导入/导出为Scene Graph文件时,能够正确序列化
当导出为Scene Graph文件时,序列化钩子函数为字符串,保存在文件中;
当导入Scene Graph文件时,反序列化字符串为函数。如果钩子函数不是纯函数(如调用了外部变量),则在此时会报错(因为外部变量并没有定义在字符串中,所以会找不到该变量)。
2)支持多线程
可以通过序列化的方式将钩子函数传到独立于主线程的脚本线程,从而在该线程中被执行,实现多线程执行脚本,提高性能。
虽然纯函数优点很多,但引擎中大多数的函数都是非纯函数,这是因为:
1)为了提高性能
2)为了简单,允许副作用,从而避免使用Monad
相关资料
第 3 章:纯函数的好处
高阶函数
介绍
高阶函数的输入或者输出为函数。
示例
//func1是高阶函数,因为它的参数是函数
let func1 = func => func(1);
let func2 = value => value * 2;
//a=2
let a = func1(func2);
在引擎中的应用
函数之间常常有一些重复或者类似的逻辑,可以通过提出一个私有的高阶函数来消除重复。具体示例如下:
重构前:
let add1 = value => value + 2;
let add2 = value => value + 10;
let minus1 = value => value - 10;
let minus2 = value => value - 200;
let compute1 = value => value |> add1 |> minus1;
let compute2 = value => value |> add2 |> minus2;
//compute1,compute2有重复逻辑
重构后:
...
let _compute = (value, (addFunc, minusFunc)) =>
value |> addFunc |> minusFunc;
let compute1 = value => _compute(value, (add1, minus1));
let compute2 = value => _compute(value, (add2, minus2));
相关资料
理解 JavaScript 中的高阶函数
柯西化
介绍
只传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。
你可以一次性地调用curry 函数,也可以每次只传一个参数分多次调用。
示例
let func1 = (value1, value2) => value1 + value2;
//传入第一个参数,func2只有一个参数value2
let func2 = func1(1);
//a=3
let a = func2(2);
在引擎中的应用
应用的地方太多了,此处省略。
相关资料
第 4 章: 柯里化(curry)
Currying
公有/私有函数
介绍
模块Module中的函数,有些是暴露给外部访问的,我们称其为“公有函数”;另外的函数是内部私有的,我们称其为“私有函数”。
可以通过创建Module对应的.rei文件,来定义要暴露的公有函数。
我们没有使用这种方法,而是通过约定函数的名称:
以下划线“_”开头的函数是私有函数,其它函数是公有函数。
示例
module Test = {
//私有函数
let _func1 = v => v;
//公有函数
let func2 = v => v * 2;
};
在引擎中的应用
引擎中的函数都是用这种命名约定,来区分公有函数和私有函数。
相关资料
Module -> “Every .rei file is a signature”
类型
Reason是强类型语言,编译时会检查类型是否正确。
本系列希望通过尽可能强的类型约束,来达到“编译通过即程序正确,减少大量的测试工作”的目的。
关于Reason类型带来的好处,参考架构最快最好的To JS编译器:
更好的类型安全: typescript是一个JS的超集,它存在很多历史包袱。而微软引入typescript更多的是作为一个工具来使用的比如IDE的代码补全,相对安全的代码重构。而这个类型的准确从第一天开始就不是它的设计初衷,以至于Facebook自己设计了一个相对更准确地类型系统Flow. 而OCaml的类型系统是已经被形式化的证明过正确的。也就是说从理论上BuckleScript 能够保证一旦编译通过是不会有运行时候类型错误的,而typescript远远做不到这点。
更多的类型推断,更好的语言特性:用过typescript的人都知道,typescript的类型推断很弱,基本上所有参数都需要显示的标注类型。不光是这点,像对函数式编程的支持,高阶类型系统GADT的支持几乎是没有。而OCaml本身是一个比Elm,PureScript还要强大的多的语言,它自身有一个非常高阶的module system,是为数不多的对dependent type提供支持的语言,polymorphic variant。而且pattern match的编译器也是优化过的。
相关资料
The "Understanding F# types" series
基本类型
介绍
Reason包含int、float、string等基本类型。
示例
//定义a为string类型
type a = string;
//定义str变量的类型为a
let str:a = "zzz";
在引擎中的应用
应用广泛,包括以下的使用场景:
1)类型驱动设计
2)领域建模
3)枚举
相关资料
Reason->Type
Algebraic type sizes and domain modelling
Discriminated Union类型
介绍
Discriminated Union类型可以接受参数,还可以组合其它的类型。
示例
//result为Discriminated Union Type
type result('a, 'b) =
| Ok('a)
| Error('b);
type myPayload = {data: string};
let payloadResults: list(result(myPayload, string)) = [
Ok({data: "hi"}),
Ok({data: "bye"}),
Error("Something wrong happened!")
];
在引擎中的应用
作为本文后面讲到的“容器”的实现,用于领域建模
相关资料
Reason->Type Argument
Reason->Null, Undefined & Option
Discriminated Unions
抽象类型
介绍
抽象类型只给出类型名字,没有具体的定义。
示例
//value为抽象类型
type value;
在引擎中的应用
包括以下的使用场景:
1)如果不需要类型的具体定义,则将该类型定义为抽象类型
如在封装WebGL API的FFI中(什么是FFI?),因为不需要知道“WebGL的上下文”包含哪些方法和属性,所以将其定义为抽象类型。
示例代码如下:
//抽象类型
type webgl1Context;
[@bs.send]
external getWebgl1Context : ('canvas, [@bs.as "webgl"] _) => webgl1Context = "getContext";
[@bs.send.pipe: webgl1Context]
external viewport : (int, int, int, int) => unit = "";
//client code
//gl是webgl1Context类型
//编译后的js代码为:var gl = canvasDom.getContext("webgl");
let gl = getWebgl1Context(canvasDom);
//编译后的js代码为:gl.viewport(0,0,100,100);
gl |> viewport(0,0,100,100);
2)如果一个数据可能为多个类型,则定义一个抽象类型和它与这“多个类型”之间相互转换的FFI,然后把该数据设为该抽象类型
如脚本->属性->value字段可以为int或者float类型,因此将value设为抽象类型,并且定义抽象类型和int、float类型之间的转换FFI。
示例代码如下:
type scriptAttributeType =
| Int
| Float;
//抽象类型
type scriptAttributeValue;
type scriptAttributeField = {
type_: scriptAttributeType,
//定义value字段为该抽象类型
value: scriptAttributeValue
};
//定义抽象类型scriptAttributeValue和int,float类型相互转换的FFI
external intToScriptAttributeValue: int => scriptAttributeValue = "%identity";
external floatToScriptAttributeValue: float => scriptAttributeValue =
"%identity";
external scriptAttributeValueToInt: scriptAttributeValue => int = "%identity";
external scriptAttributeValueToFloat: scriptAttributeValue => float =
"%identity";
//client code
//创建scriptAttributeField,设置value的数据
let scriptAttributeField = {
type_: Int,
value:intToScriptAttributeValue(10)
};
//修改scriptAttributeField->value
let newScriptAttributeField = {
...scriptAttributeField,
value: (scriptAttributeValueToInt(scriptAttributeField.value) + 1) |> intToScriptAttributeValue
};
相关资料
抽象类型(Abstract Types)
过程
组合
介绍
多个函数可以组合起来,使前一个函数的返回值作为后一个函数的输入,从而对数据进行管道处理。
示例
let func1 = value => value1 + 1;
let func2 = value => value1 + 2;
//13
10 |> func1 |> func2;
在引擎中的应用
把多个函数组合成job,再把多个job组合成一个管道操作,处理每帧的逻辑。
我们从组合的角度来分析下引擎的结构:
job = 多个函数的组合
引擎=初始化+主循环
//而初始化和主循环的每一帧,都是由多个job组合而成的管道操作:
初始化 = create_canvas |> create_gl |> ...
每一次循环 = tick |> dispose |> reallocate_cpu_memory |> update_transform |> ...
相关资料
迭代和递归
介绍
遍历操作可以分成两类:
迭代
递归
例如广度优先遍历是迭代操作,而深度优先遍历是递归操作
Reason支持用for、while循环实现迭代操作,用“rec”关键字定义递归函数。
Reason支持尾递归优化,可将其编译成迭代操作。所以我们应该在需要遍历很多次的地方,用尾递归进行遍历。
示例
//func1为尾递归函数
let rec func1 = (value, result) => {
value > 3 ? result : func1(value + 1, result + value);
};
//0+1+2+3=6
func1(1, 0);
在引擎中的应用
几乎所有的遍历都是尾递归遍历(因为相对于迭代,代码更可读),只有在少数使用Mutable和少数性能热点的地方,使用迭代遍历
相关资料
什么是尾递归?
Reason->Recursive Functions
Reason->Imperative Loops
模式匹配
介绍
使用switch代替if/else来处理程序分支。
示例
let func1 = value => {
switch(value){
| 0 => 10
| _ => 100
}
};
//10
func1(0);
//100
func1(2);
在引擎中的应用
主要用在下面三种场景:
1)取出容器的值
type a =
| A(int)
| B(string);
let aValue = switch(a){
| A(value) => value
| B(value) => value
};
2)处理Option
let a = Some(1);
switch(a){
| None => ...
| Some(value) => ...
}
3)处理枚举类型
type a =
| A
| B;
switch(a){
| A => ...
| B => ...
}
相关资料
Reason->Pattern Matching!
模式匹配
容器
介绍
为了领域建模,或者为了隔离副作用来保证纯函数,需要把值封装到容器中,使外界只能操作容器,不能直接操作值。
示例
1)领域建模示例
比如我们要开发一个图书管理系统,需要对“书”进行建模。
书有书号、页数这两个数据,有小说书、技术书两种类型。
建模为:
type bookId = int;
type pageNum = int;
//book为Discriminated Union Type
//book作为容器,定义了两个Union Type:Novel、Technology
type book =
| Novel(bookId, pageNum)
| Technology(bookId, pageNum);
现在我们创建一本小说,一本技术书,以及它们的集合list:
let novel = Novel(0, 100);
let technology = Technology(1, 200);
let bookList = [
novel,
technology
];
对“书”这个容器进行操作:
let getPage = (book) =>
switch(book){
| Novel(_, page) => page
| Technology(_, page) => page
};
let setPage = (page, book) =>
switch(book){
| Novel(bookId, _) => Novel(bookId, page)
| Technology(bookId, _) => Technology(bookId, page)
};
//client code
//得到新的技术书,它的页数为集合中所有书的总页数
let newTechnology =
bookList
|> List.fold_left((totalPage, book) => totalPage + getPage(book), 0)
|> setPage(_, technology);
在引擎中的应用
包含以下使用场景:
1)领域建模
2)错误处理
3)处理空值
使用Option这个容器包装空值。
相关资料
Railway Oriented Programming
The "Map and Bind and Apply, Oh my!" series
强大的容器
Monad
Applicative Functor
多态
GADT
介绍
全称为Generalized algebraic data type,可以用来实现函数参数多态。
示例
重构前,需要定义多个isXXXEqual函数来处理每种类型:
let isIntEqual = (source: int, target: int) => source == target;
let isStringEqual = (source: string, target: string) => source == target;
//true
isIntEqual(1, 1);
//true
isStringEqual("aaa", "aaa");
使用GADT重构后,只需要一个isEqual函数来处理所有的类型:
type isEqual(_) =
| Int: isEqual(int)
| Float: isEqual(float)
| String: isEqual(string);
let isEqual = (type g, kind: isEqual(g), source: g, target: g) =>
switch (kind) {
| _ => source == target
};
//true
isEqual(Int, 1, 1);
//true
isEqual(String, "aaa", "aaa");
在引擎中的应用
包含以下使用场景:
1)契约检查
使用GADT定义一个assertEqual方法来判断两个任意类型的变量是否相等,从而不需要assertStringEqual,assertIntEqual等方法。
相关资料
Why GADTs matter for performance(需要FQ)
维基百科->Generalized algebraic data type
Module Functor
介绍
module作为参数,传递给functor,得到一个新的module。
它类似于面向对象的“继承”,可以通过函子functor,在基module上扩展出新的module。
示例
module type Comparable = {
type t;
let equal: (t, t) => bool;
};
//module functor
module MakeAdd = (Item: Comparable) => {
let add = (x: Item.t, newItem: Item.t, list: list(Item.t)) =>
Item.equal(x, newItem) ? list : [newItem, ...list];
};
module A = {
type t = int;
let equal = (x1, x2) => x1 == x2;
};
//module B增加了add函数,该方法调用了A.equal函数
module B = MakeAdd(A);
//list == [2]
let list = B.add(1, 2, []);
//list == [2]
let list = list |> B.add(1, 1);
在引擎中的应用
引擎中有些module有相同的模式,可把它们放到提出的基module中,然后通过functor复用基module。
类型搭桥
背景
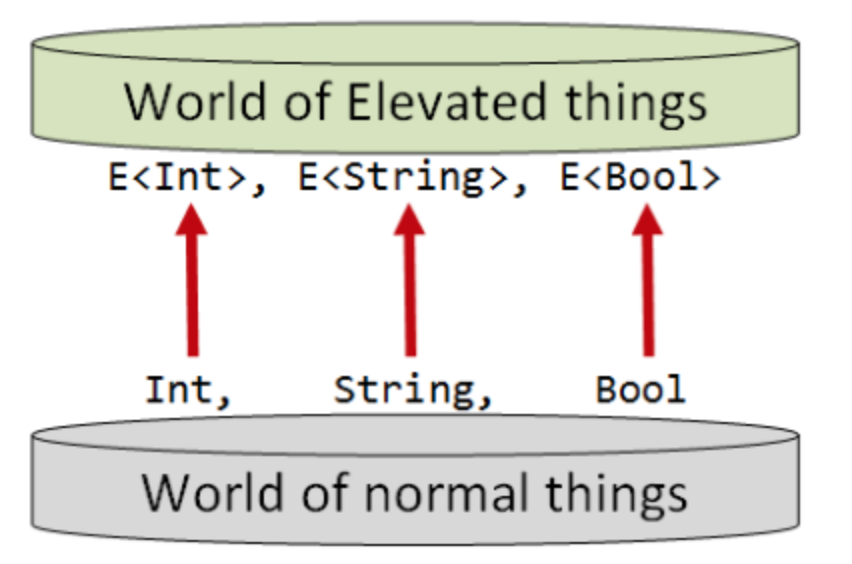
想象有两个世界:“普通世界”和“提升世界”,“提升世界”与“普通世界”非常像,“普通世界”的所有类型在“提升世界”中都有对应的类型。
例如,“普通世界”有int和string类型,对应于“提升世界”就是e(int)和e(string)类型:
(图来自Understanding map and apply)
(TODO 把图中的“<>”改为“()”,“Int”改为“int”,“E”改为“e”)
同样的,“普通世界”有类型签名为“int=>string”的函数,对应于“提升世界”就是类型签名为“e(int)=>e(string)”的函数:
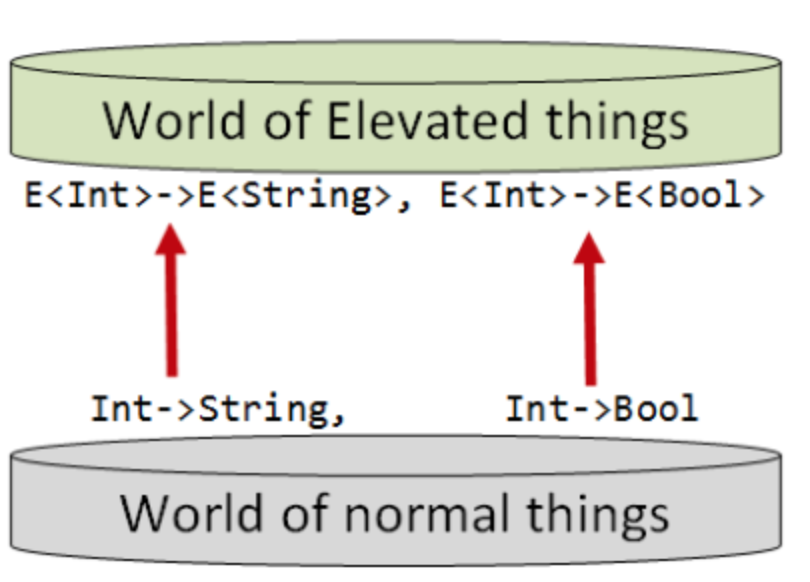
(图来自Understanding map and apply)
什么是“提升世界”?
一个Discriminated Union类型对应一个“提升世界”。
如Discriminated Union类型result:
type result('a, 'b) =
| Ok('a)
| Error('b);
它对应一个“提升世界”:“Result世界”。
“普通世界”的类型int对应于“Result世界”的类型为result(int, 'b)。
又如option对应一个“提升世界”:“Option世界”。
“普通世界”的类型Int对应于“Option世界”的类型为option(int)。
又如list对应一个“提升世界”:“List世界”。
“普通世界”的类型int对应于“List世界”的类型为list(int)。
什么是类型搭桥
两个函数组合时,第一个函数的返回会作为第二个函数的输入。如果它们的类型处于不同的世界(如一个是option(t)类型,另一个是t类型),那么需要升降类型到同一个世界,这样才能组合。对于这个类型升降的过程,我称之为“类型搭桥”。
相关资料
The "Map and Bind and Apply, Oh my!" series
有下面几种操作来升降类型:
return
常用名:return, pure, unit, yield, point
它做了什么:提升类型到“提升世界”
类型签名: a => e(a)
介绍
“return”把类型从“普通世界”提升到“提升世界”:

(图来自Understanding map and apply)
示例
//option增加return函数
module Option = {
...
let return = x => Some(x);
};
//client code
let func = (opt) => {
switch(opt){
| Some(x) => x * 2;
| None => 0
}
};
//a=2
let a = 1 |> Option.return |> func;
在引擎中的应用
处理错误的Result模块实现了succeed和fail函数,它们属于“return”操作:
Result.re
type t('a, 'b) =
| Success('a)
| Fail('b);
let succeed = x => Success(x);
let fail = x => Fail(x);
如果一个函数没有发生错误,则调用Result.succeed,把返回值包装在Success中;否则调用Result.fail,把错误信息包装在Fail中。
相关资料
Understanding map and apply
map
常用名:map, fmap, lift, Select
它做了什么:提升函数到“提升世界”
类型签名: (a=>b) => e(a) => e(b)
介绍
“map”把函数从“普通世界”提升到“提升世界”:
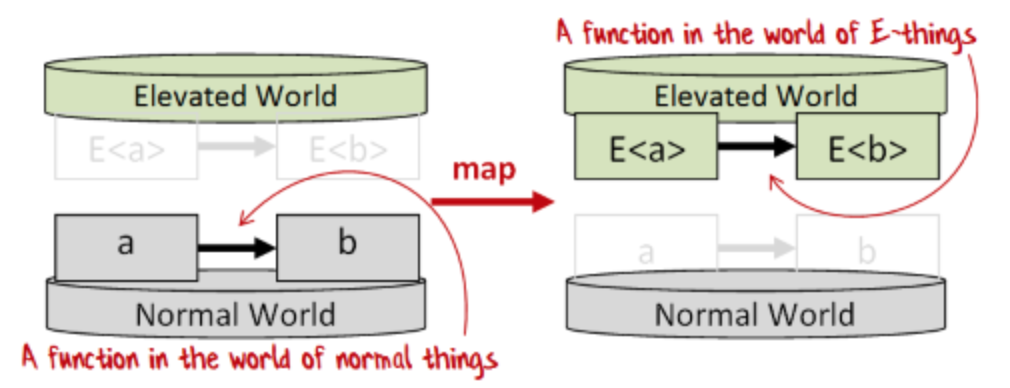
(图来自Understanding map and apply)
示例
//option增加map函数
module Option = {
...
let map = (func, option) => {
switch(option){
| Some(x) => Some(x |> func)
| None => None
}
};
};
//client code
//定义在“普通世界”的函数
//类型签名 : int => int
let add1 = x => x + 1;
//使用map,提升函数到“Option世界”
let add1IfSomething = Option.map(add1)
//a=Some(3)
let a = Some(2) |> add1IfSomething;
在引擎中的应用
处理错误的Result模块实现了map函数:
Result.re
type t('a, 'b) =
| Success('a)
| Fail('b);
let either = (successFunc, failureFunc, twoTrackInput) =>
switch (twoTrackInput) {
| Success(s) => successFunc(s)
| Fail(f) => failureFunc(f)
};
let map = (oneTrackFunc, twoTrackInput) =>
either(result => result |> oneTrackFunc |> succeed, fail, twoTrackInput);
引擎用到Result.map的地方很多,例如可以使用Result.map来处理Success中包含的值,将其转换为另一个值。
示例代码如下:
let func1 = x => x |> Result.succeed;
let func2 = result => result |> Result.map(x => x * 2);
//a=Success(2)
let a = 1 |> func1 |> func2;
相关资料
Understanding map and apply
bind
常用名:bind, flatMap, andThen, collect, SelectMany
它做了什么:使穿越世界(manadic)的函数可以被组合
类型签名: (a=>e(b)) => e(a) => e(b)
介绍
我们经常要处理在“普通世界”和“提升世界”穿越的函数。
例如:一个把字符串解析成int的函数,可能会返回option(int)而不是int类型,因此它穿越了“普通世界”和“Option世界”;一个读取文件的函数可能会返回ienumerable(string)类型;一个接收网页的函数可能返回promise(string)类型。
这种穿越世界的函数,它们的类型签名可以被识别为:a => e(b)。
它们的输入是“普通世界”的类型,而输出则是“提升世界”的类型。
不幸的是,这意味着不能直接组合这些函数:

“bind”把穿越世界的函数(通常称为“monadic”函数)转换为“提升世界”的函数:e(a) => e(b):
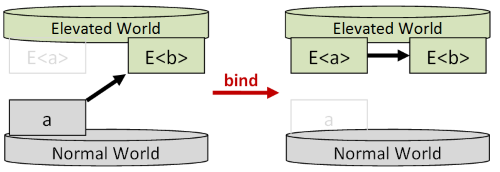
这么做的好处是,转换后的函数完全在“提升世界”,因此可以被直接组合。
例如,一个类型签名为“a => e(b)”的函数不能直接与类型签名为“b => e(c)”的函数组合。但当bind后者以后,后者的类型签名变为“e(b) => e(c)”,这样就可以与前者进行组合了:
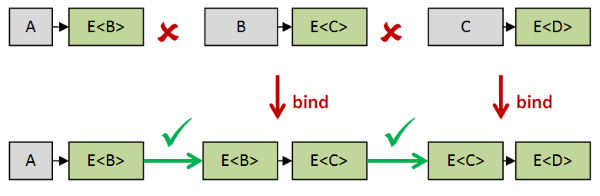
(图来自Understanding bind)
通过bind,能让多个mondadic函数组合在一起。
示例
//option增加bind方法
module Option = {
...
let bind = (func, option) => {
switch(option){
| Some(x) => x |> func
| None => None
}
};
};
//client code
//类型签名:string => option(int)
let parseStr = str => {
switch(str){
| "-1" => Some(-1)
| "0" => Some(0)
| "1" => Some(1)
| "2" => Some(2)
// etc
| _ => None
};
}
type orderQty =
| OrderQty(int);
//类型签名:int => option(orderQty)
let toOrderQty = (qty) =>
if (qty >= 1) {
Some(OrderQty(qty));
} else {
None;
};
//使用bind转换toOrderQty函数,使它能与parseInt函数组合
//类型签名:string => option(orderQty)
let parseOrderQty = str => str |> parseStr |> Option.bind(toOrderQty);
在引擎中的应用
处理错误的Result模块实现了bind函数:
Result.re
type t('a, 'b) =
| Success('a)
| Fail('b);
let either = (successFunc, failureFunc, twoTrackInput) =>
switch (twoTrackInput) {
| Success(s) => successFunc(s)
| Fail(f) => failureFunc(f)
};
let bind = (switchFunc, twoTrackInput) =>
either(switchFunc, fail, twoTrackInput);
引擎用到Result.bind的地方很多,例如:
在主循环中,获得数据state的函数unsafeGetState的类型签名为:unit => Result.t(state, Js.Exn.t),处理主循环逻辑的loopBody函数的类型签名为:state => Result.t(state, Js.Exn.t)。
需要对loopBody函数进行Result.bind,从而使它们能够组合。
相关代码为:
let rec _loop = () =>
DomExtend.requestAnimationFrame((time: float) => {
StateData.unsafeGetState()
|> Result.bind(Director.loopBody)
...
});
相关资料
Understanding bind
traverse
常用名:mapM, traverse, for
它做了什么:转换一个穿越世界的函数为另一个穿越世界的函数,转换后的函数用来在遍历集合时处理每个元素
类型签名:(a=>e(b)) => list(a) => e(list(b))
介绍
我们来看看一个经常会遇到的场景:处理一个集合(如list),该集合元素为“提升世界”的类型。
举例来说:
我们有一个类型签名为“string => option(int)”的函数parseStr和一个集合:list(string),我们想要解析该集合所有的字符串。我们可以使用“map”:list |> List.map(parseStr),将list(string)转换为list(option(int))。
但我们真正想要的不是“list(option(int))”,而是“option(list(int))”,即用option来包装解析后的列表list。
这可以通过traverse来做到,我们把list对应的“提升世界”称为“Traversable世界”(因为可以使用traverse来遍历它),把option对应的“提升世界”称为“Applicative世界”。使用“traverse”操作遍历list,得到option(list('b))类型,如下图所示:
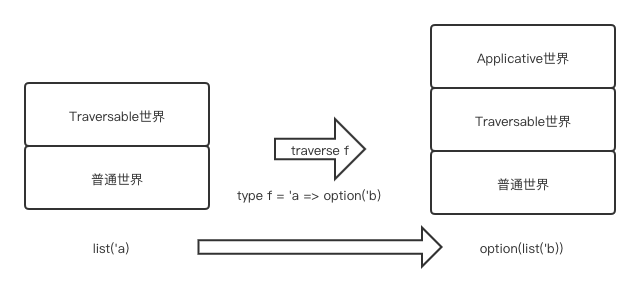
示例
介绍中的示例的相关代码如下:
module List = {
...
//注:可以将该函数作为模版。如果Applicative世界变为其它世界,如Result世界,只需要把returnFunc替换为Result.succeed,Js.Option.andThen替换为Result.bind
let traverseOptionM = (traverseFunc, list) => {
let returnFunc = Js.Option.some;
list
|> List.fold_left(
(resultArr, value) =>
//andThen相当于bind
Js.Option.andThen(
(. h) =>
Js.Option.andThen((. t) => returnFunc(t @ [h]), resultArr),
traverseFunc(value),
),
returnFunc([]),
);
};
};
//client code
//类型签名:string => option(int)
let parseStr = str => {
switch (str) {
| "" => None
| str => Some(str |> Js.String.length)
};
};
//a=None
let a = ["", "aaa", "bbbb"] |> List.traverseOptionM(parseStr);
//b=Some([3,4])
let b = ["aaa", "bbbb"] |> List.traverseOptionM(parseStr);
关于traverse具体实现的分析,详见Understanding traverse and sequence
在引擎中的应用
引擎的List、Array实现了traverseResultM函数,用来遍历处理集合中Result类型(存在错误的函数会返回Result类型)的元素。
相关资料
Understanding traverse and sequence
sequence
常用名:sequence
它做了什么:交换Traversable世界和Applicative世界的位置
类型签名:list(e(a)) => e(list(a))
介绍
sequence交换Traversable世界和Applicative世界的位置:
Traversable世界下降
Applicative世界上升
如下图所示:
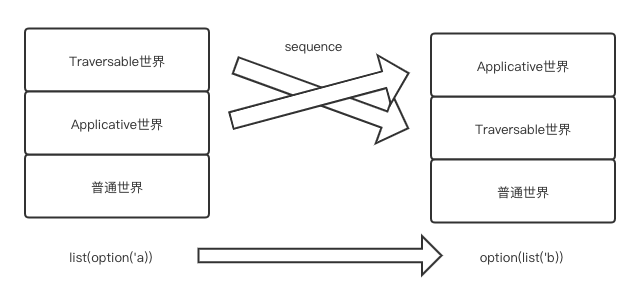
示例
如果已经实现了traverseResultM,那么可以从中很简单地导出sequence。
示例代码为:
module List = {
...
let id = x => x;
let sequenceResultM = x => traverseResultM(id, x);
};
//client code
//与traverse示例中的parseStr函数一样
let parseStr = ...
let a =
["1", "22", "333"]
//得到[Some(1), Some(2), Some(3)]
|> List.map(parseStr)
//得到Some([1,2,3])
|> List.sequenceResultM;
let b =
["", "22", "333"]
//得到[None, Some(2), Some(3)]
|> List.map(parseStr)
//得到None
|> List.sequenceResultM;
在引擎中的应用
引擎对元组Tuple实现了sequenceResultM函数,用来交换Tuple和Result的位置。
相关资料
Understanding traverse and sequence
错误处理
使用Result
介绍
我们使用Result来处理错误,它相对于“抛出异常”的错误处理方式,有下面的优点:
1、分离“发生错误”和“处理错误”的逻辑,延迟到后面来统一处理错误
2、对流程更加可控,如可以在第一个错误发生后继续执行后面的程序
3、显示地标示出错误
通过函数返回Result类型,在类型的编译检查时可确保使用错误得到了处理
示例
首先增加Result.re这个模块,在其中定义一个Discriminated Union类型,使其包含Success和Fail的数据(设置为泛型参数'a和'b,使其可为任意类型,增加通用型):
type t('a, 'b) =
| Success('a)
| Fail('b);
接着定义return(此处为succeed和fail函数)、map、bind等函数:
let succeed = x => Success(x);
let fail = x => Fail(x);
let either = (successFunc, failureFunc, twoTrackInput) =>
switch (twoTrackInput) {
| Success(s) => successFunc(s)
| Fail(f) => failureFunc(f)
};
let bind = (switchFunc, twoTrackInput) =>
either(switchFunc, fail, twoTrackInput);
let map = (oneTrackFunc, twoTrackInput) =>
either(result => result |> oneTrackFunc |> succeed, fail, twoTrackInput);
最后定义处理Result的函数:
let getSuccessValue = (handleFailFunc: 'f => unit, result: t('s, 'f)): 's =>
switch (result) {
| Success(s) => s
| Fail(f) => handleFailFunc(f)
};
我们来看下如何使用Result处理错误:
//func使用Result包装错误
let func = (x) => {
x > 0 ? Result.succeed(x) : Result.fail(Js.Exn.raiseError("x should > 0"));
};
//处理错误的函数:抛出异常
let throwError: Js.Exn.t => unit = [%raw err => {|
throw err;
|}];
//抛出异常
let a = func(-1) |> Result.getSuccessValue(throwError);
//正常执行,b=1
let b = func(1) |> Result.getSuccessValue(throwError);
在引擎中的应用
引擎使用Result来处理错误。
相关资料
Railway oriented programming
参考资料
感谢您的阅读~
扫码加入我的QQ群:

扫码加入免费知识星球-YYC的Web3D旅程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号