WebGPU学习(五): 现代图形API技术要点和WebGPU支持情况调研
大家好,本文整理了现代图形API的技术要点,重点研究了并行和GPU Driven Render Pipeline相关的知识点,调查了WebGPU的相关支持情况。
另外,本文对实时光线追踪也进行了简要的分析。这是我非常感兴趣的技术方向,也是图形学的发展方向之一。本系列后续文章会围绕这个方向进行更多的研究和实现相关的Demo。
上一篇博文:
WebGPU学习(四):Alpha To Coverage
下一篇博文:
WebGPU学习(六):学习“rotatingCube”示例
本文内容
前置知识
-
现代图形API包括哪些API?
包括DX12、Vulkan、Metal -
MVP是什么?
是WebGPU的最小可用版本。
在1.0版本发布前,先发布MVP版本。
技术要点
现代图形API包含下面的技术要点:
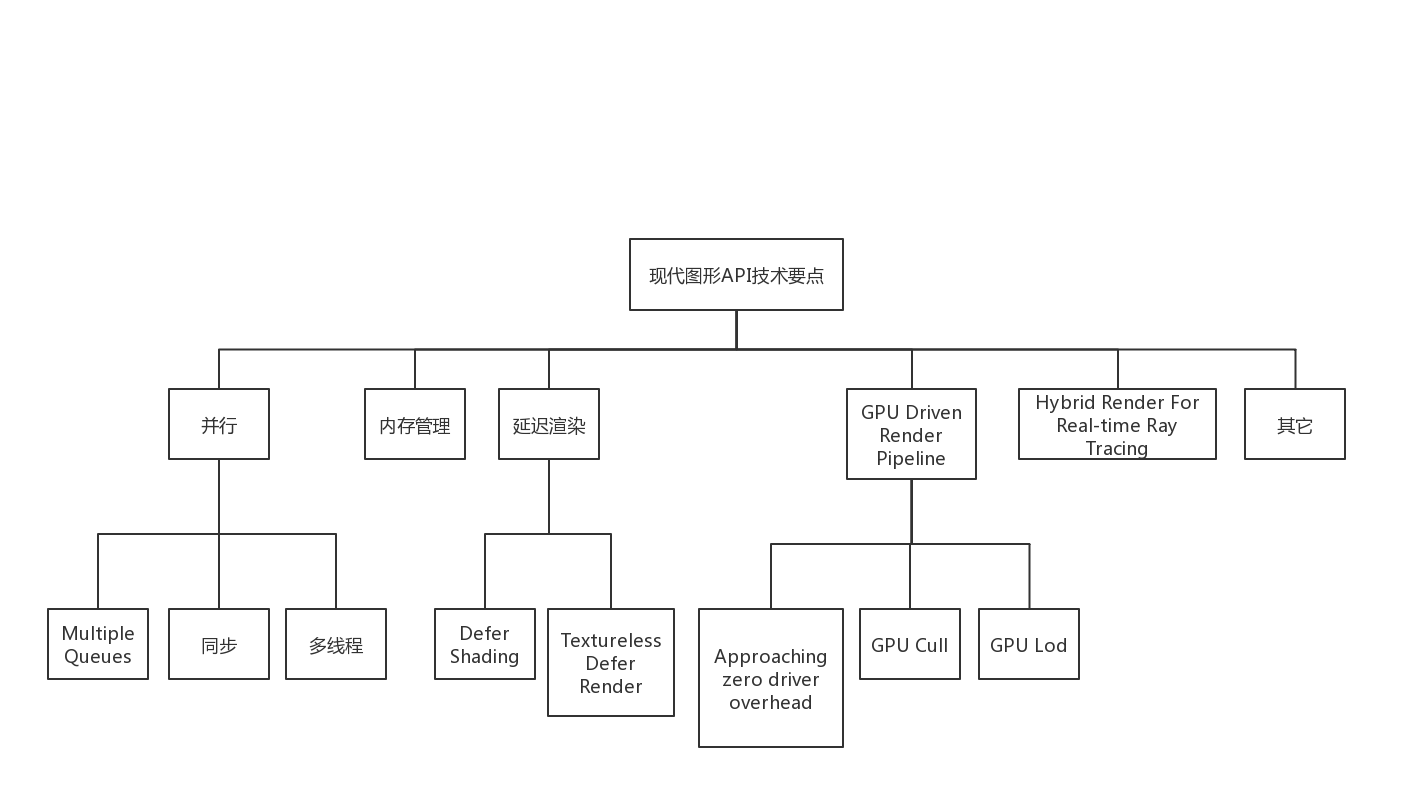
下面依次进行分析:
并行
为了提高多核CPU和GPU的利用率,现代图形API充分支持了并行。
并行包含下面的技术要点:
Multiple Queues
介绍
为了提高GPU利用率,可以将不同种类的任务对应的command buffer提交到3种队列中:
graphics queue
copy queue
compute queue
不同队列的任务能够在GPU中并行执行,从而实现Async Compute,提高利用率。
参考资料
Multi-engine synchronization
WebGPU支持情况
根据Multiple Queues skeleton proposal,MVP只支持单队列:
what single queue is exposed in the MVP
同步
介绍
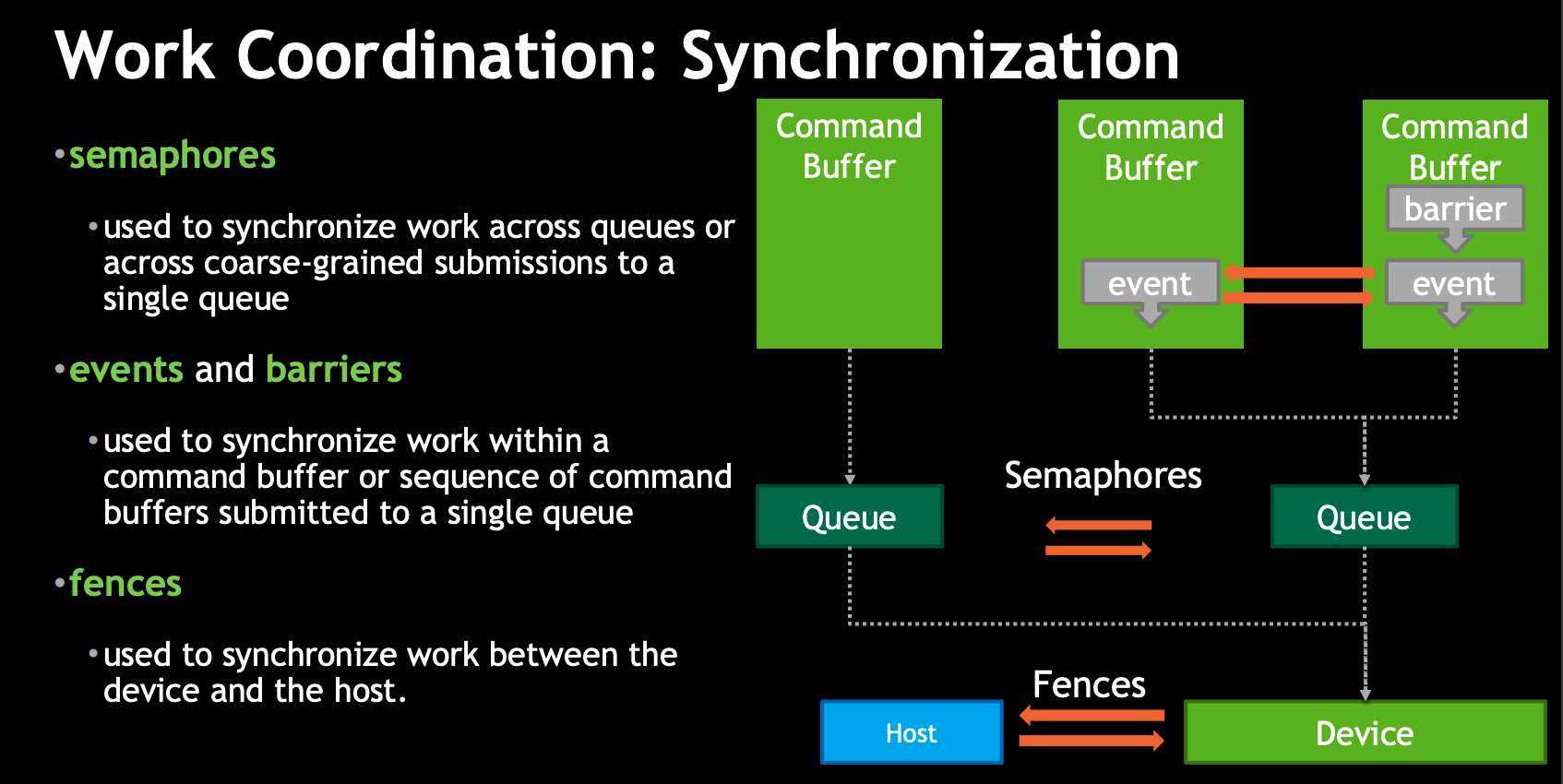
有3个技术可以实现CPU与GPU之间以及GPU内部的同步:
- semaphores
我不了解它,它应该是用来同步队列的
- memory barrier
它用来避免GPU因为资源依赖关系造成等待,以及避免CPU和GPU之间发生Race Condition。
现代图形API更加底层,以前GPU做的同步工作也交给了图形程序员,更加灵活的同时也加重了程序员的负担。
- fence
它用来在CPU和GPU之间同步。
这3个技术的关系可以参考Vulkan Multi-Threading:
WebGPU支持情况
- semaphores
因为目前只支持单队列,所以不需要它
- memory barrier
大家都表示memory barrier不容易实现,所以barriers由WebGPU帮我们做了(参考Memory barriers investigations、Memory Barriers portability、The case for passes -> Synchronization and validation),我们只需要给WebGPU一些提示(如指定buffer的usage)
- fence
支持以计数的方式实现fence。
参考资料
TimelineFences
多线程
介绍
可以在线程中执行现代图形API相关的渲染任务:
-
在线程中更新资源
如更新buffer -
并行地编译shader
-
并行地创建pipeline state
-
在线程中创建command buffer

WebGPU支持情况
有两种方法实现多线程:
- 通过OffscreenCanvas API,实现主线程与渲染线程分离
根据Rendering to OffscreenCanvas on non-yielding workers:
WebGPU支持OffScreenCanvas API,但是目前Chrome不能使用它。
- 创建worker,在worker中执行WebGPU相关的渲染任务
Create a proposal for multi-worker中提出了WebGPU如何在worker中执行渲染任务:
1.Asynchronous texture & buffer uploads
2.Asynchronous shader compilation
3.Asynchronous pipeline state creation
4.Using MTLParallelRenderEncoder
5.Each thread in a thread pool records into its own command buffer
根据Minutes for GPU Web meeting 2019-08-05 -> Multi threading:
其中的1,2,3正在实现中;
4, 5会最终实现(没有说好久实现);
根据我目前的调查:
1.shader编译和创建pipeline state目前是同步的,还不是异步的。
2.在WebGPU 规范中,GPUTexture,GPUBuffer,GPUDevice,GPUComputePipeline,GPURenderPipeline,GPUShaderModule是Serializable的,意味着可以传给worker。
那是不是现在已经可以在worker中使用它们,从而实现1,2,3呢?需要进一步验证!
扩展阅读
引擎对于多线程的封装:
Parallelizing the Naughty Dog Engine using Fibers
Destiny’s Multi-threaded Renderer Architecture
内存管理
介绍
与memory barriers类似,现代图形API需要程序员自己管理GPU的资源。
如Memory Management in Vulkan™ and DX12所示:
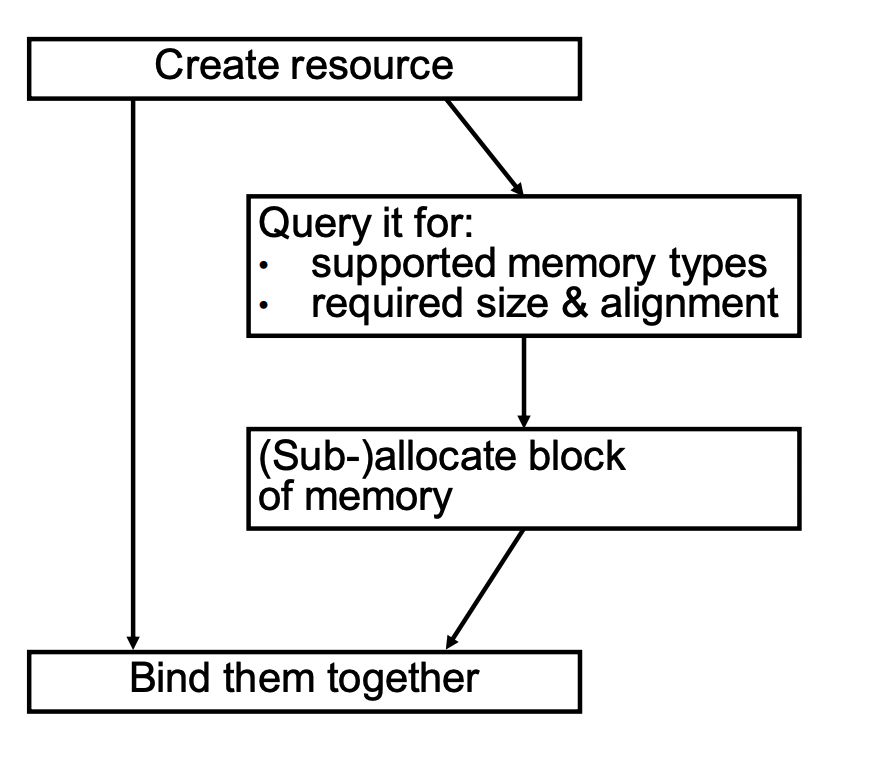
参考资料
Memory Management in Vulkan™ and DX12
WebGPU支持情况
根据WebGPU as low level graphics API :
WebGPU compares closest to Metal (probably since Apple is the one that originally proposed it)--both don't require manual memory management while DX12 and Vulkan do
不需要手动管理memory,WebGPU会帮我们管理
延迟渲染
defer shading
包括两个步骤:
第一个pass遍历gameObjects,创建gbuffer;
第二个pass遍历lights,使用gbuffer计算光照。
相对于前向渲染,它的优点是只在屏幕上出现的像素中计算SHADING,从而使复杂度由O(M * N)将为O(M) + O(N)
WebGPU支持情况
因为支持MRT(多渲染目标),所以支持延迟渲染。
值得一提的是两个优化的方向:
- 优化内存访问
在Investigation: Managing on-chip memory中提到:
第一个pass创建gbuffer后,gbuffer的数据会从on-chip内存移到主内存中;
第二个pass读取gbuffer时,将gbuffer的数据从主内存移到on-chip内存。
gbuffer的数据来回移动,造成了性能损失。
因此在Add render sub-passes中,建议增加render的子pass,在子pass中读取gbuffer,从而实现在创建和读取gbuffer期间,gbuffer的数据一直在on-chip内存中。
Minutes for GPU Web meeting 2019-10-28也讨论了这一点。
WebGPU可能会在extension中支持这个优化。
- 针对tile-based defer shading,使用compute shader,在第二个pass中剔除光源,剩余的光源参与光照计算
正如DirectX 11 Rendering in Battlefield 3所说:
Hybrid Graphics/Compute shading pipeline:
› Graphics pipeline rasterizes gbuffers for opaque surfaces
› Compute pipeline uses gbuffers, culls lights, computes lighting &
combines with shading
› Graphics pipeline renders transparent surfaces on top
参考资料
延迟着色法
Optimizing tile-based light culling
DirectX 11 Rendering in Battlefield 3
textureless defer render
介绍
在defer shading的第一个pass中,我们将gameObject的几何数据(如Position, Normal等)和材质贴图数据(如从diffuse map中获得的diffuse)存到gbuffer中。
有了bindless texture的支持,我们可以对此进行优化:
- gbuffer不再存储材质贴图的数据,而是存储uv和material id。在第二个pass中,shader根据它们去获取对应材质贴图texture的数据
这样做的优点是:
1.减少了gbuffer的大小
2.只在可见的像素中,采样texture的数据,减少了采样次数
这样做也存在一些问题,不过都是可以解决的:
具体可以参考什么是deferred material shading?是否会在未来流行开来?:
1.多材质如何做deferred shading?总不能每个像素做动态分支,一个一个判断吧。有人提出了做tile把像素区块合并,然后一次性dispatch,性能会高很多。至于vgpr,sgpr,lds占用率之类需要通盘考虑,偏向一边都会影响性能。
2.结果SSAO,SSR之类的post effect还是需要用到normal,roughness之类的g-bufffer信息。应用上还是需要权衡利弊。
以及参考Deferred Texturing:
What about mip levels, or derivatives?
- gbuffer不存储几何数据,而是存储primitive ID。在第二个pass中,接收vertex data,在每个可见像素上执行vertex shader
具体可以参考Deferred Texturing -> Defer All The Things:
It stores only primitive IDs in its G-buffer; then in a later pass, it fetches vertex data, re-runs the vertex shader per pixel (!), finds the barycentric coordinates of each fragment within its triangle, interpolates the vertex attributes, then finally samples all the textures and does the shading work.
WebGPU支持情况
根据本文后面bindless texture的分析,目前WebGPU不支持bindless texture
或许可用texture 2d array代替bindless texture,从而使用WebGPU实现textureless defer render
参考资料
Deferred Texturing
什么是deferred material shading?是否会在未来流行开来?
BINDLESS TEXTURING FOR DEFERRED RENDERING AND DECALS
Modern textureless deferred rendering techniques
GPU Driven Render Pipeline
介绍
这个技术应该是在[Siggraph15] GPU-Driven Rendering Pipelines中提出来的。它的思想是把渲染任务从CPU端移到GPU端,减少CPU与GPU的同步和数据传输,实现1个draw call就渲染整个场景,从而提高GPU的利用率。
优点
-
GPU更细粒度的Visibility
-
不需要在CPU和GPU之间来回传递数据
应用场景
-
绘制大量的静态物体
-
绘制人群
-
绘制模块化半自动生成内容
主要步骤
离线处理
1.分解gameObject的mesh为多个cluster
参考GPU Driven Pipeline — 工具链与进阶渲染
CPU
1.对gameObject进行粗粒度的frustum cull
2.使用persistent map buffer,准备GPU的数据
可以按照数据的类型,创建多个mapped buffer(如一个buffer存储人群的数据,另一个buffer存储所有静态物体的数据)
3.使用virtual texture处理texture
所有的texture数据一次性全部准备好,只绑定一次texture
4.用indirect draw发起multi draw call,提交mapped buffer
WebGPU目前不支持multi draw,因此需要发起多个draw call,每个draw call使用indirect draw提交对应的mapped buffer
GPU
1.对gameObject进行frustum cull和occlusion cull
2.对gameObject的cluster进行frustum cull和occlusion cull
3.修改index buffer,生成新的indices数据
根据Proposal: Run all index buffers through a compute shader validator:
I'm inclined to propose that WebGPU MVP doesn't support index buffers changed on the GPU, since this is quite a bit of headache, but eventually we can do that.
...
In an actual 1.0 release we'll absolutely need to support GPU-generated indices, there is no question here.
WebGPU MVP不会支持在GPU端修改index buffer,1.0版本会支持。
4.multi draw call
根据ExecuteIndirect investigation:
In order to issue draw calls on the CPU, there must be a synchronization point where the CPU waits for the GPU update to complete. This is particularly devastating for WebGPU, where if the CPU has to wait for the GPU, you miss your implicit present and now you're a frame late. Being able to issue these commands on the GPU directly means the rendering and update steps can be in sync.
在GPU端发起draw call可以去掉“CPU和GPU同步”的开销。
However, making it an extension seems valuable.
可能会在WebGPU extension中支持该特性。
总结
GPU Driven Render Pipeline可以一次性取得所有mesh data,通过virtual texture可以取得所有texture,意味着整个场景只需要一次drawcall
参考资料
[Siggraph15] GPU-Driven Rendering Pipelines
[GDC16] Optimizing the Graphics Pipeline with Compute
知乎大神MaxwellGeng关于GPU Driven Rendering Pipelines的相关文章1
知乎大神MaxwellGeng关于GPU Driven Rendering Pipelines的相关文章2
现在我们介绍下GPU Driven Render Pipeline相关的概念和技术要点:
Approaching zero driver overhead
这个概念(简称为AZDO)出自approaching-zero-driver-overhead,它分析了OpenGL如何使用GPU实现CPU端0负载,具体包括下面几个方面:
- persistent map buffer
介绍
该技术是为了在“CPU把数据传输到GPU“时减小数据传输的开销。
它包括下面的步骤:
1.映射GPU的buffer到CPU
2.在CPU端修改这个mapped buffer的数据(因为mapped buffer在shared memory中,CPU和GPU都可以访问它,所以要使用fence同步来确保GPU没操作这个buffer)
3.提交修改buffer数据的command
4.GPU执行该command,更新buffer数据
通过上面的步骤,不再需要“从CPU传输新buffer的数据到GPU”了,减小了开销
参考资料:
Persistent mapped buffers
Persistent Mapped Buffers in OpenGL
WebGPU支持情况
有两种方式实现“CPU把数据传输到GPU“:
1.调用GPUBuffer->setSubData方法
该方法性能差,需要从CPU传输数据到GPU(WebGPU规范并没有定义该方法,但是Chrome的WebGPU实现目前有该方法)
2.使用persistent map buffer技术
对于该方法,有以下的要点要说明:
1)不需要fence
WebGPU提供了GPUBuffer->unmap方法,该方法将buffer设置为unmapped state,使该buffer能够被GPU使用。
WebGPU应该在该方法中帮我们做了fence同步的工作。
2)如何创建mapped buffer?
有两种方式创建:
a)调用GPUDevice->createBufferMapped方法,创建mapped buffer
Make it easier to upload data into buffers correctly指出:
createBufferMapped创建的buffer会使内存增加,因此需要destory它。
b)调用GPUBuffer->mapReadAsync,mapWriteAsync,将buffer设置为mapped buffer
Make it easier to upload data into buffers correctly指出,使用mapWriteAsync会造成一些问题:
in WebGPU, have an implicit present after rAF() returns
...
Using mapWriteAsync() requires you to wait on a promise, so if you do the naive thing and just wait on the promise inside rAF(), you’ll miss your present
...
Could we replace mapWriteAsync returning a Promise with it taking a callback that is guaranteed to execute before any submitted queue bundles are executed?
其中“rAF”指“requestAnimationFrame”
我们根据示例代码来说明下这个问题:
function frame(time){
...
const vertexBuffer = device.createBuffer({
...
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC,
});
vertexBuffer.mapWriteAsync().then((vertexBufferData) => {
设置vertexBufferData
vertexBuffer.unmap();
提交修改buffer数据的command到队列中
...
});
window.requestAnimationFrame(frame);
}
因为mapWriteAsync是异步操作,而frame函数是同步操作,所以当执行到unmap时,可能已经执行了好几次frame(过了好几帧)。
在这几帧中,可能提交了其它的command到队列,WebGPU可能会在这几帧之间提交了队列中的command到GPU,GPU可能已经执行了其中的一些command。
执行unmap时,我们预期GPU还没有执行其它的command,但实际上可能已经执行了。这样会造成不同步的错误。
为了解决该问题,或许可以使用await关键字,将mapWriteAsync变成同步操作。
示例代码如下:
async function frame(time){
...
var vertexBufferData = await vertexBuffer.mapWriteAsync();
设置vertexBufferData
vertexBuffer.unmap();
提交修改buffer数据的command到队列
...
}
这里给出使用persistent map buffer技术的参考代码(来自Buffer operations)
(参考代码通过“调用GPUDevice->createBufferMapped方法”来创建mapped buffer):
//Updating data to an existing buffer(destBuffer)
function bufferSubData(device, destBuffer, destOffset, srcArrayBuffer) {
const byteCount = srcArrayBuffer.byteLength;
const [srcBuffer, arrayBuffer] = device.createBufferMapped({
size: byteCount,
usage: GPUBufferUsage.COPY_SRC
});
new Uint8Array(arrayBuffer).set(new Uint8Array(srcArrayBuffer)); // memcpy
srcBuffer.unmap();
const encoder = device.createCommandEncoder();
encoder.copyBufferToBuffer(srcBuffer, 0, destBuffer, destOffset, byteCount);
const commandBuffer = encoder.finish();
const queue = device.getQueue();
queue.submit([commandBuffer]);
srcBuffer.destroy();
}
参考资料
Make it easier to upload data into buffers correctly
What is the purpose of WebGPUSwapChain.present()?
Buffer operations
Minutes for GPU Web meeting 2019-10-21
- indirect draw
介绍
以WebGPU为例,draw方法需要指定顶点个数、实例个数等数据,每次只能绘制一个gameObject(可以批量绘制多个实例instance):
void draw(unsigned long vertexCount, unsigned long instanceCount, unsigned long firstVertex, unsigned long firstInstance);
而indirect draw可以使用buffer进行批量绘制多个gameObject(也可以批量绘制多个实例),这个buffer包含了每个gameObject的顶点个数等数据:
void drawIndirect(GPUBuffer indirectBuffer, GPUBufferSize indirectOffset);
优点
1.可以在compute shader修改buffer的数据,从而实现gpu cull
2.减少了绘制gameObject的次数
3.减少了CPU和GPU之间的同步开销
WebGPU支持情况
支持Indirect draw/dispatch,相关讨论参考 Indirect draw/dispatch commands investigation
参考资料
What are the advantage of using indirect rendering in OpenGL?
vulkan Indirect drawing
INDIRECT RENDERING : “A WAY TO A MILLION DRAW CALLS”
Surviving without gl_DrawID
- bindless texture and virtual texture
bindless texture和virtual texture可以结合使用,实现“只绑定一次texture”。
具体参见本文后面的说明:
其它->Bindless Texture
其它->Virtual Texture
GPU Cull
在GPU端实现剔除。
实现思路
1.创建persistent map buffer,indirect draw该buffer
2.在compute shader进行cull操作,将剩余的gameObject对应的draw call数据(如顶点个数)写到该buffer中
相关技术要点
- 剔除的目标可以是gameObject的整个mesh,也可以是部分mesh(以cluster为单位)
具体可参考GPU Driven Pipeline — 工具链与进阶渲染
- frustum cull
通过判断目标是否在主相机的视锥体中,来实现剔除
- occlusion cull
通过判断目标是否被遮挡,来实现剔除
具体可参考Hi-Z GPU Occlusion Culling
GPU Lod
在GPU端实现lod。
这个我没有仔细研究,读者可以参考相关资料:
谷歌搜索结果
GPU based dynamic geometry LOD
Hybrid Render For Real-time Ray Tracing
介绍
以前Ray Tracing只在离线渲染中使用(如制作CG电影,一般会使用path tracing来加快收敛速度),现在随着DXR(DirectX Raytracing)的发布,新增了Ray Tracing管线,提出了专为Ray Tracing设计的shader,再配合上新的降噪方法(如使用SVGF降噪算法或者NVDIA提供的基于AI的降噪SDK),能够实现实时的Ray Tracing!
混合渲染
完全用Ray Tracing来渲染太耗性能,所以目前业界使用混合方案来实现实时Ray Tracing:
如果支持DXR,可以使用“光栅化管线 + Ray Tracing管线”来实现;
如果不支持DXR,可以使用“光栅化管线 + Compute管线(即使用compute shader)”来实现。
我们可以把渲染分解为:
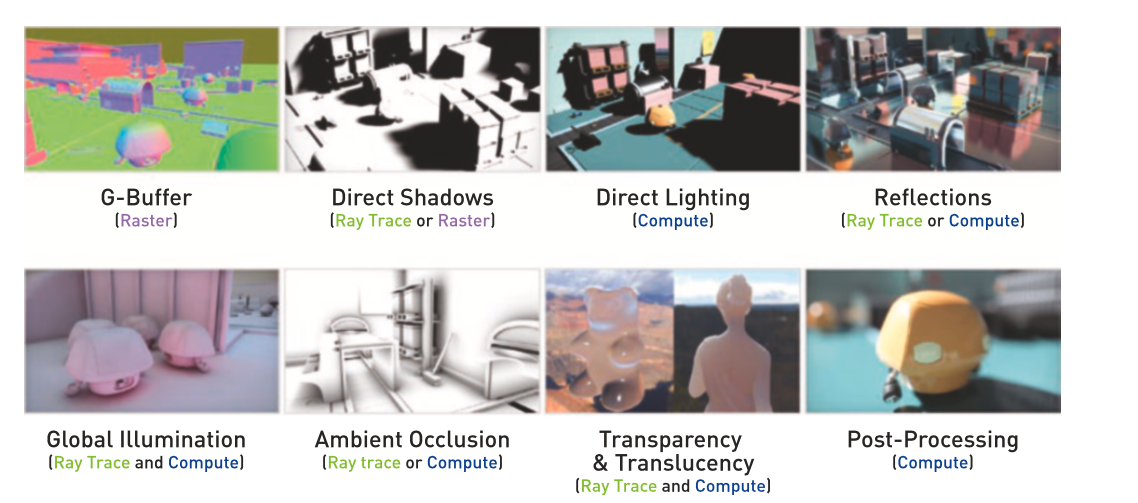
(图来自于《Ray Tracing Gems》)
WebGPU支持情况
根据Is there some plan for Ray Tracing?:
There are not plan for ray-tracing for the forseeable future because WebGPU is meant to be extremely portable and ray-tracing isn't mature yet and is implemented only by a single hardware vendor for now.
WebGPU目前不支持Ray Tracing管线,因此只能使用“光栅化管线 + Compute管线(即使用compute shader)”来实现混合渲染。
如何使用WebGPU学习和实现Ray Tracing
可以按照下面的步骤:
1.广泛收集相关资料,对整个技术体系有初步的了解(读者可以看下面的“学习资料”)
2.参考Ray Tracing in One Weekend、Ray Tracing: The Next Week、对应的详解,使用fragment shader,从0实现Ray Tracing。
目前只需要渲染球体或者立方体就好了,不用渲染模型。
3.使用compute shader实现Ray Tracing
4.使用混合渲染(如使用光栅化实现GBuffer和直接光照,使用Ray Tracing实现阴影和反射)
5.实现降噪算法
直接实现SVGF很有难度,可以先实现其中的子环节(如temporal anti aliasing、tone map、Edge-Avoiding À-Trous等),然后再把它们组装起来,实现SVGF
6.渲染模型
需要实现BVH
7.进一步研究和实现,探索path tracing、优化采样、优化光线排序和连贯性、支持更多的材质等方向
学习资料
一篇光线追踪的入门
光线追踪与实时渲染的未来
实时光线追踪技术:业界发展近况与未来挑战
Introduction to NVIDIA RTX and DirectX Ray Tracing
如何评价微软的 DXR(DirectX Raytracing)?
Daily Pathtracer!安利下不错的Pathtracer学习资料
Ray Tracing in One Weekend
Ray Tracing: The Next Week
Ray Tracing in One Weekend和Ray Tracing: The Next Week的详解
基于OpenGL的GPU光线追踪
Webgl中采用PBR的实时光线追踪
Spatiotemporal Variance-Guided Filter, 向实时光线追踪迈进
系统学习Ray Tracing的资料:Ray Tracing Gems
其它
Bindless Texture
在WebGPU中,什么是bind texture?
Investigation: Bindless resources提到:
Currently, in WebGPU, if a draw/dispatch call wants to use a resource, that resource must be part of a pre-baked "bind group" and then associated with the draw call inside the current render/compute pass. This means that all the resources that the draw/dispatch call could possibly access are explicitly listed by the programmer at the draw/dispatch site.
也就是说,我们需要定义每个texture在shader的binding,然后在每次提交command时,绑定该texture。
我们来看具体的textureCube sample:
绑定的texture需要在shader中指定binding:
//在fragment shader中指定binding为2
const fragmentShaderGLSL = `#version 450
...
layout(set = 0, binding = 2) uniform texture2D myTexture;
在BindGroup中,设置binding为2的相关数据:
const bindGroupLayout = device.createBindGroupLayout({
bindings: [
...
{
// Texture view
binding: 2,
visibility: GPUShaderStage.FRAGMENT,
type: "sampled-texture"
}]
});
...
const uniformBindGroup = device.createBindGroup({
layout: bindGroupLayout,
bindings: [
...
{
binding: 2,
resource: cubeTexture.createView(),
}],
});
把BindGroup设置到Pipeline中:
const pipelineLayout = device.createPipelineLayout({ bindGroupLayouts: [bindGroupLayout] });
const pipeline = device.createRenderPipeline({
layout: pipelineLayout,
...
});
提交command时,设置该bind group和pipeline:
const passEncoder = commandEncoder.beginRenderPass(renderPassDescriptor);
passEncoder.setPipeline(pipeline);
passEncoder.setBindGroup(0, uniformBindGroup);
...
passEncoder.endPass();
在WebGPU中,什么是bindless texture?
Investigation: Bindless resources提到:
"Bindless" is a model where the programmer doesn't explicitly list all of the available resources at the draw/dispatch site. Instead, a large swath of resources are made available to the GPU ahead of time (e.g. during application launch) and then shaders can access any/all of them at runtime.
可以将所有的texture设置到一个buffer中,将其传给GPU,然后shader可以在运行时操作任意的texture。
这样的好处是我们不需要在每次提交command时绑定特定的texture,只需要绑定一次。
如果不支持bindless texture,可以使用texture 2d array替代
参考approaching-zero-driver-overhead->36页,我们可以使用texture 2d array代替bindless texture,只需要绑定一次texture 2d array,不需要在每次提交command时绑定特定的texture。
texture 2d array的优点参考:
为什么要强调Texture2DArray在地形上的应用?
缺点是texture array中的每个texture的大小、格式要相同,而bindless texture没有该要求。
为了解决该缺点,我们可以按照大小和格式,把texture划分为多组,对应多个texture 2d array。
WebGPU支持情况
从Minutes for GPU Web meeting 2019-08-12中得知,目前还未决定何时实现bindless texture,可能实现为extension,可能在1.0版本后实现。
所以目前可考虑用texture 2d array作为替代品
参考资料
OPENGL AZDO : BINDLESS TEXTURES : BATCHING PROBLEM SOLVED
Virtual Texture
思想
把所有要用到的texture拼到一起,组成physic texture;
通过索引,只把当前要用到的texture加载到内存中。
优点
1.只绑定一次texture
2.组成physic texture的子纹理的格式和mipmap等可以不一样;
3.减小了内存占用(内存中只有当前使用的texture)
缺点
因为要不断地在内存中加载/卸载texture,所以增加了IO开销
应用场景
- 地形纹理
WebGPU支持情况
有人提出了Investigation: Sparse Resources, 希望WebGPU增加操作堆heap的API。不过目前没有回应。
我目前不清楚WebGPU是否能实现virtual texture
参考资料
approaching-zero-driver-overhead -> Sparse Texture
知乎->Virtual Texture Tools & Practices
关于对virtual texture的浅显认识
Tessellation
根据Investigation: Tessellation:
Let's wait until after the release of a MVP
WebGPU应该会在MVP后考虑加入Tessellation shader
Mesh Shader
介绍
NVDIA在Turing架构中推出了新的管线,用来替代光栅化管线。新管线只保留了Pixel Shader(即fragment shader),新增了Task Shader和Mesh Shader,如下图所示:
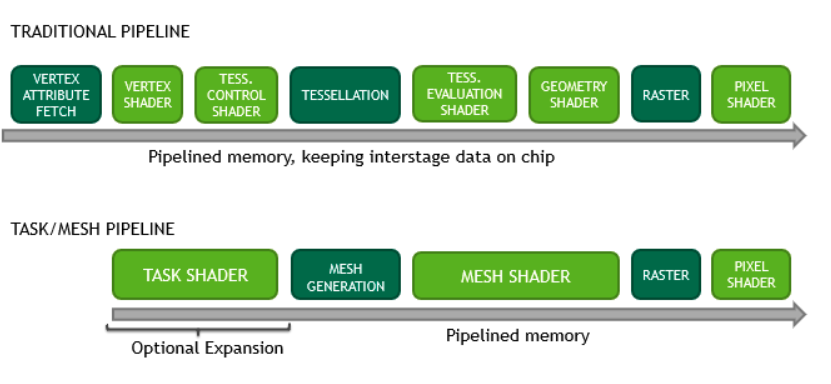
新管线更适合于GPU Driven Render Pipeline的理念,包括以下的特性:
类似于Compute管线(compute shader),具有强大的计算能力;
把Mesh分解为Meshlet(类似于GPU Driven Render Pipeline中提到的Cluster),更好地支持cluster cull。
WebGPU支持情况
根据Investigation: Tessellation中的讨论,因为Vulkan和Metal还没支持Mesh Shader,所以WebGPU至少要等它们支持后才会考虑支持。
参考资料
DX12支持了Mesh Shader
Introduction to Turing Mesh Shaders
怎么评价nvidia 推出mesh shader管线?
感谢您的阅读~
扫码加入我的QQ群:

扫码加入免费知识星球-YYC的Web3D旅程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号