


Python爬取网页上想要的数据
1、源代码如下

from urllib.request import urlopen,Request
import urllib.request
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
url ='http://movie.douban.com/top250?format=text'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36'}
ret = Request(url,headers=headers)
page = urllib.request.urlopen(ret)
contents = page.read()
# print(contents)
soup = BeautifulSoup(contents, "html.parser")
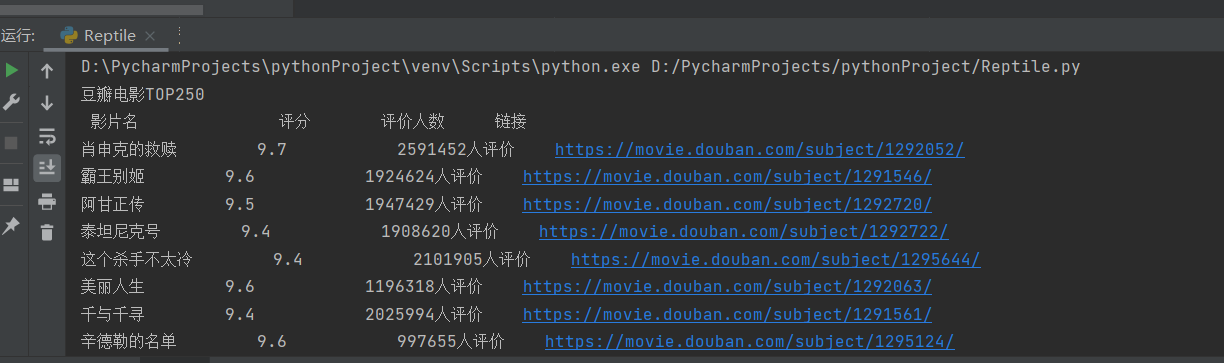
print("豆瓣电影TOP250" + "\n" + " 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span', class_='rating_num').get_text())
m_people = tag.find('div', class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url = tag.find('a').get('href')
print(m_name + " " + str(m_rating_score) + " " + m_peoplecount + " " + m_url)
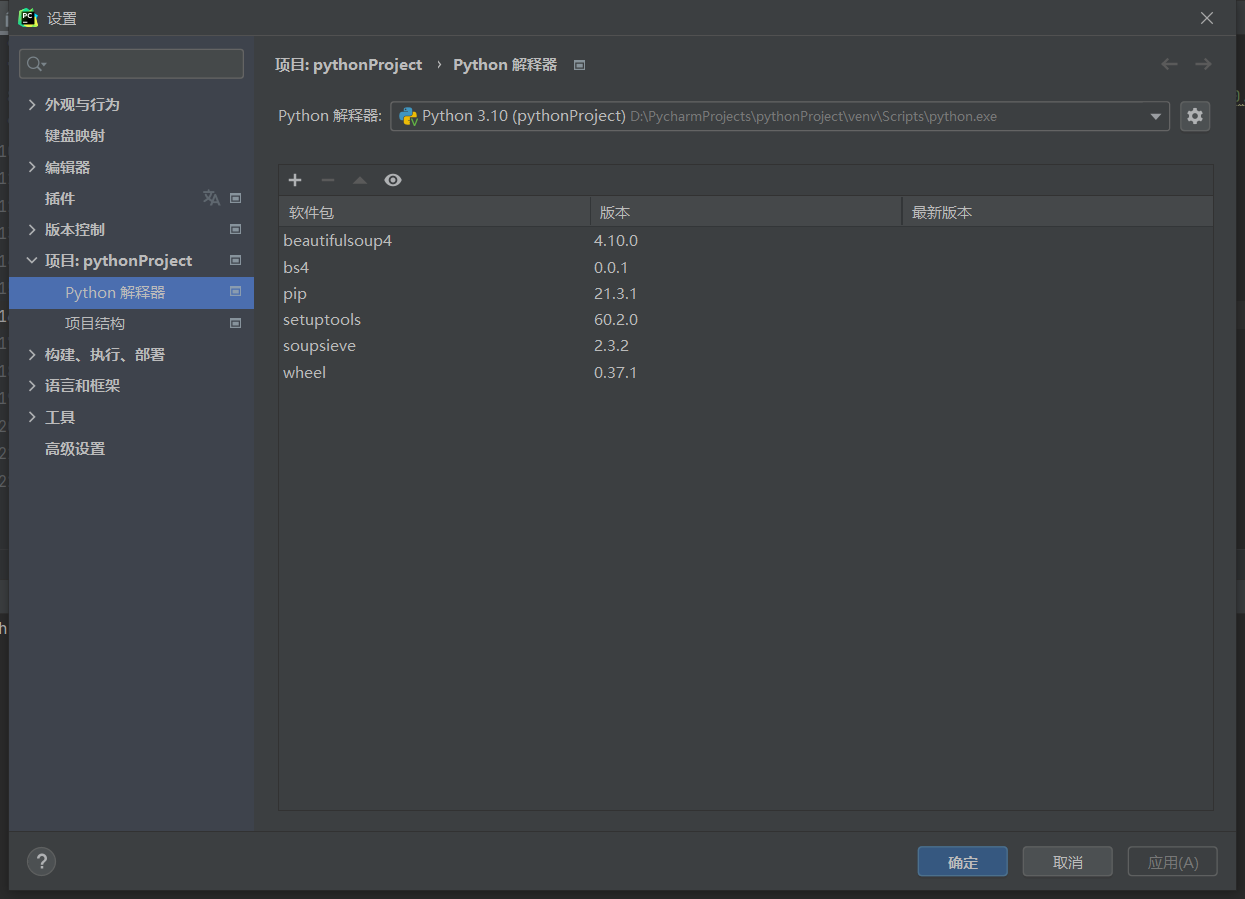
2、安装bs4
在文件-设置-python Project-搜索ps4并点击安装,安装完成以后会提示安装成功
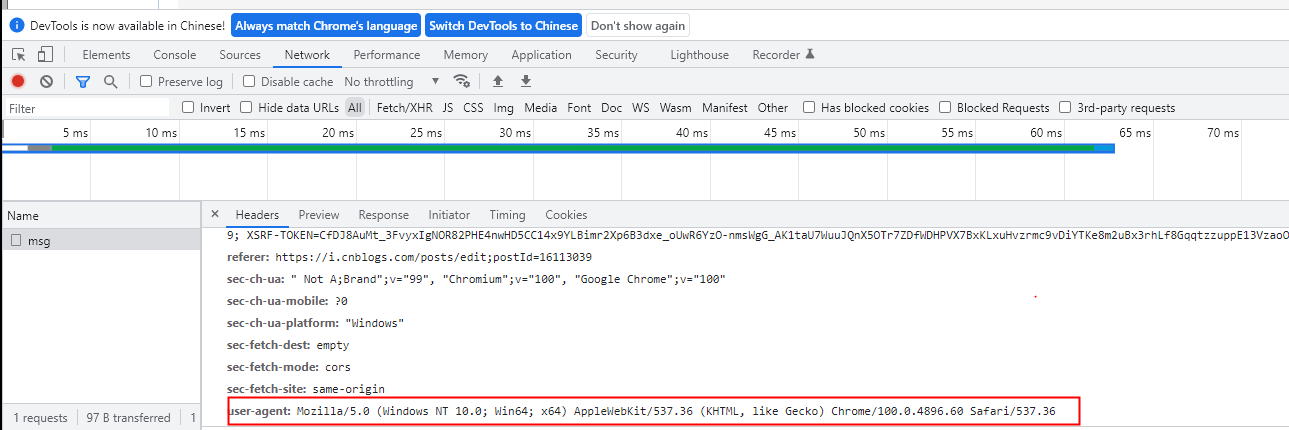
3、URLLIB.ERROR.HTTPERROR: HTTP ERROR 418错误
需要模拟浏览器访问,直接爬取会被拦截。打开浏览器按F12,随便访问一个网站,选中连接,找Headers,往下拉找到其中user-agent代表用的哪个请求的浏览器。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)