scrapy爬取彼岸图网照片(搜索关键字,去重)
系列文章目录
第四章:scrapy爬取起点中文网24小时热销榜单(将数据存到数据库)
第五章:scrapy爬取彼岸图网照片(搜索关键字,去重)
前言
利用scrapy在彼岸图网上搜索关键字,并在之前的基础上进行去重。
之前的图片获取selenium搜索关键字爬虫
一、项目需求
之前搜索的关键字是“美女”,现在将范围进一步放大,只搜索一个“女”字,图片含量足足翻了一倍,本来博主只是准备做一个简单的图片获取,没准备做这么大工程,不过博主刚刚考完试,时间比较充分,所以就扩大工程规模,这次项目重点有数据库去重,随机伪装浏览器,照片保存,以及scrapy自带的降速(以前用time.sleep)。之前项目的数据存储了一个照片的三条数据,分别是所在的html页面,引用的jpg链接和照片的名称,为了完成数据的复用,这次也要获取这三条数据。
二、项目分析
1.获取彼岸图关键字url
彼岸图网本身就提供了关键字搜索,这也是我为什么选择彼岸图的网的原因。

搜索完之后跳转到相应的url,这里还是没有页数的显示,咱们在看一下第二页在来第一页。
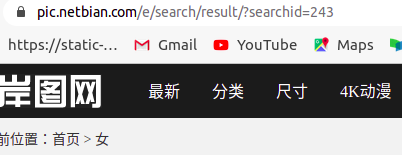
现在就很明显了第一页是从page=0开始的,

可以看到一共有近300多页,之前搜索“美女”也就180多。
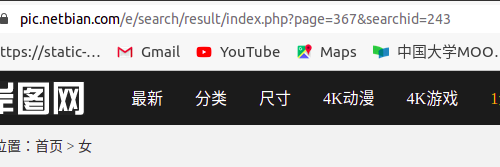
2.数据抓取
可以发现咱们需要的第一个数据在一个class=‘slist’的div中
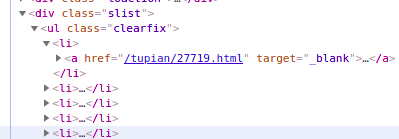
跳转到相应的网页后,在运用控制台的分析,找到剩下数据所在的地址。
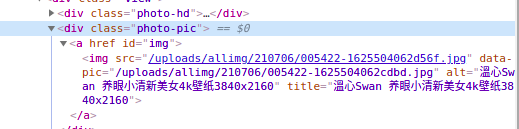
至此需要的所有数据都找到了。
三、代码编写
创建项目不说了
1.编写item(数据封装)
import scrapy
class BiantuItem(scrapy.Item):
name = scrapy.Field()
html=scrapy.Field()
jpg=scrapy.Field()2.编写spider(数据抓取)
#coding:utf-8
from scrapy import Request
from scrapy.spiders import Spider
from ..items import BiantuItem
import copy
class BianSpider(Spider):
name = 'biantu'
root_url='https://pic.netbian.com'#初始url后边拼接用的
current_page = 0 #初始页面数
def start_requests(self):
url='https://pic.netbian.com/e/search/result/index.php?page=0&searchid=243'#第一页url
yield Request(url)
def parse(self, response):
list=response.xpath("//div[@class='slist']/ul/li")
#获取所有html链接所在的li,并形成列表。
item=BiantuItem()
for one in list:
#遍历每一个li
html=one.xpath('a/@href').extract_first()
#获取html地址
url=self.root_url+html
#之前获取的是相对地址,拼接后形成完整的地址。
item['html']=self.root_url+html
#数据封装
yield Request(url,meta={'item':copy.deepcopy(item)},callback=self.xiangxi_parse)
#将url进行访问,并以copy模块将item传递(如果不用有可能传递前后有错误,具体原因博主还在研究中),用另一个parse进行分析。
self.current_page+=1
#页数+1
if self.current_page<369:
#当页数小于369是再次发送请求达到翻页的目的
next_url='https://pic.netbian.com/e/search/result/index.php?page=%d&searchid=243'%self.current_page
yield Request(url=next_url)
def xiangxi_parse(self,response):
item=response.meta['item']
#接受传递的item
message=response.xpath("//div[@class='photo-pic']")
#获取到剩余两天数据所在的div
jpg=message.xpath("a/img/@src").extract_first()
#获取jpg链接
pic_name=message.xpath("a/img/@alt").extract_first()
#获取图片名称
item['name']=pic_name
item['jpg']=self.root_url+jpg
yield item3.编写middlewares(伪装成随机浏览器)
这里要介绍一个库fake直接pip安装就行,里面带有许多浏览器的UserAgent
这个scrapy最常用的修改UserAgent,没有什么要讲的,直接复制就行。
from scrapy.downloadermiddlewares.useragent import UserAgentMiddleware
import random
from fake_useragent import UserAgent
class BianwangUserAgentMiddleware(UserAgentMiddleware):
def process_request(self, request, spider):
ua=UserAgent()
request.headers["User-Agent"]=ua.random
#print("user-agent:", request.headers["User-Agent"])
#测试初期打印一下浏览器信息,确认生效后注释掉就可以了。3.编写pipelines(去重,数据存储,照片保存)
import MySQLdb
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class MySQLPipline(object):
#完成数据去重和数据保存
def open_spider(self,spider):
#连接数据,之前说过,不说了。
db_name=spider.settings.get("MYSQL_DB_DNNAME","tupian")
host = spider.settings.get("MYSQL_HOST", "localhost")
user = spider.settings.get("MYSQL_USER", "root")
password = spider.settings.get("MYSQL_PASSWORD", "123456")
self.db_coon=MySQLdb.connect(db=db_name,
host=host,
user=user,
password=password,
charset="utf8")
self.db_cursor = self.db_coon.cursor()
def process_item(self,item,spider):
values=(item['html'],item['jpg'],item['name'])
get_sql="select html from suoyin"
#获取html信息的sql语句
set_sql="insert into suoyin(html,jpg,name) value(%s,%s,%s)"
#插入新数据的sql语句
self.db_cursor.execute(get_sql)
#执行获取语句
result=self.db_cursor.fetchall()
#将结果返回一个打的元组
i = (str(item['html']),)
#将需要判断的数据进行规格话,不然没法和元组比较。
if i in result:
#如果数据已存在,直接丢掉
raise DropItem()
else:
self.db_cursor.execute(set_sql,values)
#否则插入数据
self.db_coon.commit()
#可以理解为保存(如果不执行是存储不进去的)
return item
def close_spider(self, spider):
#关闭数据库
self.db_cursor.close()
self.db_coon.close()
class SaveImagePipline(ImagesPipeline):
#重写scrapy自带的SaveImagePipline
def get_media_requests(self, item, info):
yield Request(url=item['jpg'],
meta={'name':item['name']})
#以jpg连接作为url发起提交请求,meta传递图片名称(一般传递一种类型的一条数据(它就一条变不成其他的)如果数据很多,还是要用copy)
def item_completed(self, results, item, info):
#判断是否下载成功,固定格式
if not results[0][0]:
raise DropItem('下载失败')
return item
def file_path(self, request, response=None, info=None, *, item=None):
#文件重命名
image_name=str(request.meta['name'])[0].replace(" ",'')
#设置图片名称(item会形成一个列表)我把空格去掉了
filename = u'{0}/{1}'.format("女", image_name)
#重命名固定格式子目录,文件名
return filename4.编写setting(启动piplines middliwares,设置延迟)
只写需要修改的地方
ROBOTSTXT_OBEY = False
#关闭机器人协议
IMAGES_STORE="./彼岸网图片"
#存储路径(自己添加)
DOWNLOADER_MIDDLEWARES = {
'biantu.middlewares.BianwangUserAgentMiddleware': 543,
}
#启动中间键伪装随机浏览器
ITEM_PIPELINES = {
'biantu.pipelines.MySQLPipline': 300,
'biantu.pipelines.SaveImagePipline': 400,
}
#启动管道文件进行去重,先去重后下载
DOWNLOAD_DELAY = 0.5
#访问一个网站的延迟时间单位为秒
MYSQL_DB_DNNAME="tupian"
MYSQL_HOST="localhost"
MYSQL_user="root"
MYSQL_PASSWORD="123456"
#数据库配置信息5.编写start
from scrapy import cmdline
cmdline.execute("scrapy crawl biantu" .split())总结
博主之前都是在获得了第一个数据之后进行去重,然后是否进行下一步的数据获取,但scrapy数据获取和清洗的完全分开的,这也就是为什么scrapy写大型爬虫不如request灵活的原因,但这个项目完全没必要纠结。
