
特征工程2:归一化与标准化
归一化与标准化属于特征预处理的范畴
· 特征预处理是什么?
通过特定的数学统计方法将数据转化为算法要求的数据; 特征预处理在scikit-learn中的模块是:sklearn.preprocessing
对于不同的数据类型,有不同的处理方式,三种常见的数据类型:
-
数值型
-
类别型
-
时间类型
· 这里我们先看数值型的预处理:
标准缩放:有两种常见方式,归一化和标准化。
在特征较多时,并且认为这些特征同等重要,或者算法模型涉及到距离计算时(比如K近邻),为了防止某些特征的值对算法产生的影响过大,需要将特征数据缩放至某一个区间,这样比较起来才有意义,并且可以减少程序的计算量,加快速度。
举例说明:比如体型特征,数据如下,有身高和体重两个特征,计量单位分别是cm和kg
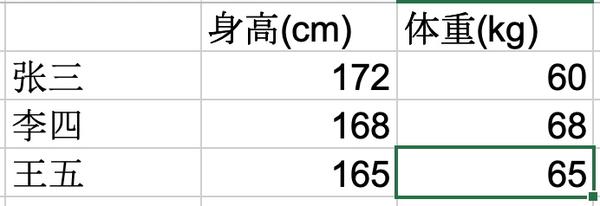
如果我们要按体形特征将人群分类,找出王五的体型与谁最接近,并且认为身高和体重对于体型评判同等重要,由于身高和体重单位不同,身高的值较大,对结果的影响可能较大,所以需要将这两个特征缩放到同一个区间,这样每个特征对结果的影响是相同的。
1、 归一化
常用的归一化方法是:极差变换法,也称为min-max方法,通过线性变换将数据映射到[0,1]之间,变换公式是:
其中min是样本中最小值,max是样本中最大值,x为每一个特征的值
对应到示例中的数据,计算过程如下:

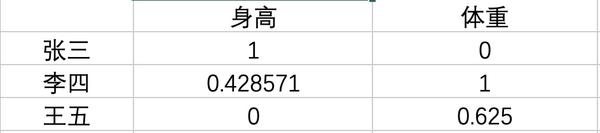
scikit-learn中归一化API是MinMaxScaler
使用方法如下:
# 归一化处理
from sklearn.preprocessing import MinMaxScaler
m = MinMaxScaler()
feature_data = [[172,60], [168,68], [165,65]]
data = m.fit_transform(data)
print(data)
输出结果:
array([[ 1. , 0. ],
[ 0.42857143, 1. ],
[ 0. , 0.625 ]])
归一化总结:从归一化的公式中,可以看出最大值最小值在计算过程起到的作用很大,因此计算结果特别容易受到异常数据的影响,所以这种方法的稳定性很差,只适用于数据精确的场景,但是现实中数据难免有异常,所以归一化很少被用到,为了避免异常数据对结果的影响,可以使用另一种方法:标准化。
2、 标准化
常用的标准化方法是:z-score,将数据转换到均值为0,标准差为1的范围内,公式如下:
作用于每一列,其中mean为特征的平均值,σ为标准差
scikit-learn中标准化的API是StandardScaler,使用方法与归一化类似,代码如下:
# 标准化处理
from sklearn.preprocessing import StandardScaler
m = StandardScaler()
data = [[172,60], [168,68], [165,65]]
stand_data = m.fit_transform(data)
print(stand_data)
输出结果:
array([[ 1.27872403, -1.31319831],
[-0.11624764, 1.1111678 ],
[-1.16247639, 0.20203051]])
标准化总结:标准化的应用场景非常广泛,在具有一定数据量的前提下,少量异常点对于平均值的影响不大,从而对于标准差的影响不大,进而对结果的影响也不大。
3、 归一化与标准化总结
1. 归一化和标准化本质上都是线性变换,线性变换的性质决定了对数据转换之后不会“失效”,反而还能提高数据的表现,因为线性变化不改变原始数据的数值排序;2. 归一化的缩放是“拍扁”统一到区间(仅由极值决定),而标准化的缩放更加“弹性”和“动态”,与整体样本的分布有很大关系;3. 归一化的输出范围在0-1之间,标准化的输出范围是负无穷到正无穷;4. 当算法涉及到距离运算时,必须先使用归一化或标准化进行标准缩放,由于对于异常数据的反应不同,标准化的使用更广泛。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号