
上一篇扒了single-core的实现,这篇记录一些扩展到多核的思路。
1. 单个AIE core
对于单核,这里假设矩阵乘计算的输入输出为A[m*k] x B [k*n] = C[m*n]
2. 扩展成一条chain:级联
k的维度是需要乘累加起来的,假设k为2048,分到2个核上,每个核就只需要各自reduce 1024, 如果分到4个核上,各自reduce 512.
这里有两种思路将单核扩展成一条chain:
2.1 前核不做中间结果暂存
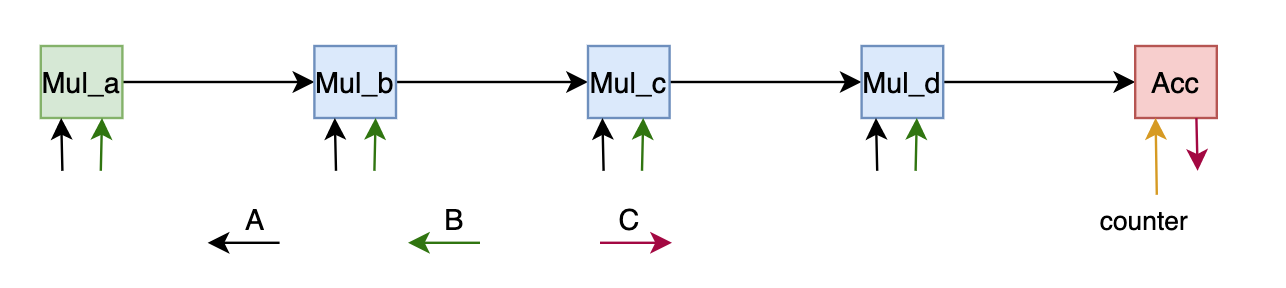
如上图,需要更新单core的kernel,衍生出三种类型的kernel(a核,bcd核,acc核):
链首的core只需要将结果写入本地data memory改为推给下一个core。链中间的核就是“接->算->发”。
1 /////////////////////////////////////////////////////////////////////////////////////// 2 //Mul_head_kernel 3 for (unsigned int i=0;i<F_Ra/2;i++) { 4 FPMUL; 5 FPMAC(1,9); FPMAC(2,10); FPMAC(3,11); FPMAC(4,12); 6 FPMAC(5,13); FPMAC(6,14); FPMAC(7,15); 7 8 buf_matA = window_readincr_v16(matA); // reads the next 2 rows of A 9 window_decr_v8(matB,8); // reset B pointer 10 11 put_mcd(acc1); // 不写入本核的data memory,直接走cascade 推给下一个core 12 put_mcd(acc2); 13 } 14 15 /////////////////////////////////////////////////////////////////////////////////////// 16 //Mul_middle_kernel 17 for (unsigned int i=0;i<F_Ra/2;i++) { 18 acc1 = get_scd(); // 用前核cascade 的值初始化acc 19 acc2 = get_scd(); 20 21 FPMAC(0,8); //替换掉FPMUL; 22 FPMAC(1,9); FPMAC(2,10); FPMAC(3,11); FPMAC(4,12); 23 FPMAC(5,13); FPMAC(6,14); FPMAC(7,15); 24 25 buf_matA = window_readincr_v16(matA); // reads the next 2 rows of A 26 window_decr_v8(matB,8); // reset B pointer 27 28 put_mcd(acc1); // 不写入本核的data memory,直接走cascade 推给下一个core 29 put_mcd(acc2); 30 }
链尾的核就不做Mul了,只切ping-pong做累加。需要一个counter参数标识该core转几次往外出数。例如前核每个核在k维度的reduce能力是8,那4个核一次就是reduce 32。
如果k = 32,那正好counter = 1, Acc 核接到cascade来的数直接存到输出窗口让DMA搬走。
如果k = 64,那counter = 2, Acc核要work两次,it_0: 接->存Ping, it_1: (接+Ping)-> 输出窗口
如果k = 96, counter = 3, Acc核3次,it_0: 接->存Ping, it_1: (接+Ping)-> 存Pong, it_2: (接+Pong)-> 输出窗口
以此类推。
2.2 前核做中间结果暂存
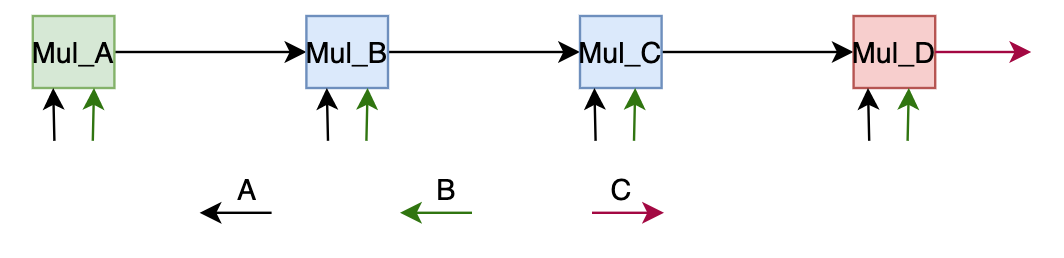
如上图,也是需要三种类型的kernel(链首,链中,链尾),区别于2.1 的chain,链前部的核不是傻乎乎做相同的计算,而是要知道自己算到哪一部分了,将结果写到自己data memory还是推到cascade 上。
1 /////////////////////////////////////////////////////////////////////////////////////// 2 //Mul_A_kernel 3 switch(path){ 4 case IN2CASC: // 算->推 cascade 5 case IN2DM: // 算->存 datamemory 6 case INaDM2DM: //取部分和->算->存 7 case INaDM2CASC: ////取部分和->算->推 8 } 9 10 /////////////////////////////////////////////////////////////////////////////////////// 11 //Mul_BC_kernel 12 switch(path){ 13 case CASCaIN2CASC: // 接->算->推 cascade 14 case CASCaIN2DM: // 接->算->存 datamemory 15 case CASCaINaDM2DM: //接+部分和->算->存 16 case CASCaINaDM2CASC: ////接+部分和->算->推 17 } 18 19 /////////////////////////////////////////////////////////////////////////////////////// 20 //Mul_D_kernel 21 switch(path){ 22 case CASCaIN2OUT: // 接->算->推 cascade 23 case CASCaIN2DM: // 接->算->存 datamemory 24 case CASCaINaDM2DM: //接+部分和->算->存 25 case CASCaINaDM2OUT: ////接+部分和->算->存结果 26 }
单核k做8的reduce,4核reduce 32。对于不同的k, 各核的path如下:
| k | MulA | MulB | MulC | MulD |
| 32 |
it_0: IN2CASC |
CASCaIN2CASC |
CASCaIN2CASC |
CASCaIN2OUT |
| 64 |
it_0: IN2DM it_1: INaDM2CASC |
CASCaIN2DM CASCaINaDM2CASC |
CASCaIN2DM CASCaINaDM2CASC |
CASCaIN2DM CASCaINaDM2OUT |
| 96 |
it_0: IN2CASC it_1: INaDM2DM it_2: INaDM2CASC |
CASCaIN2DM CASCaINaDM2DM CASCaINaDM2CASC |
CASCaIN2DM CASCaINaDM2DM CASCaINaDM2CASC |
CASCaIN2DM CASCaINaDM2DM CASCaINaDM2OUT |
3. 扩展成多条chain
一条chain是横着布局,那相对于某一列来看,该chain对stream口的需求是两个口子(1个A和1个B), AIE array 上能放8行就是8条chain,那单列来看,对stream口的需求是16(2*8), 不好意思,硬件上没有这么多stream连接,上行(South->North)只有6, 下行(North->South)为4。那就只能广播了,以下是一种广播思路:
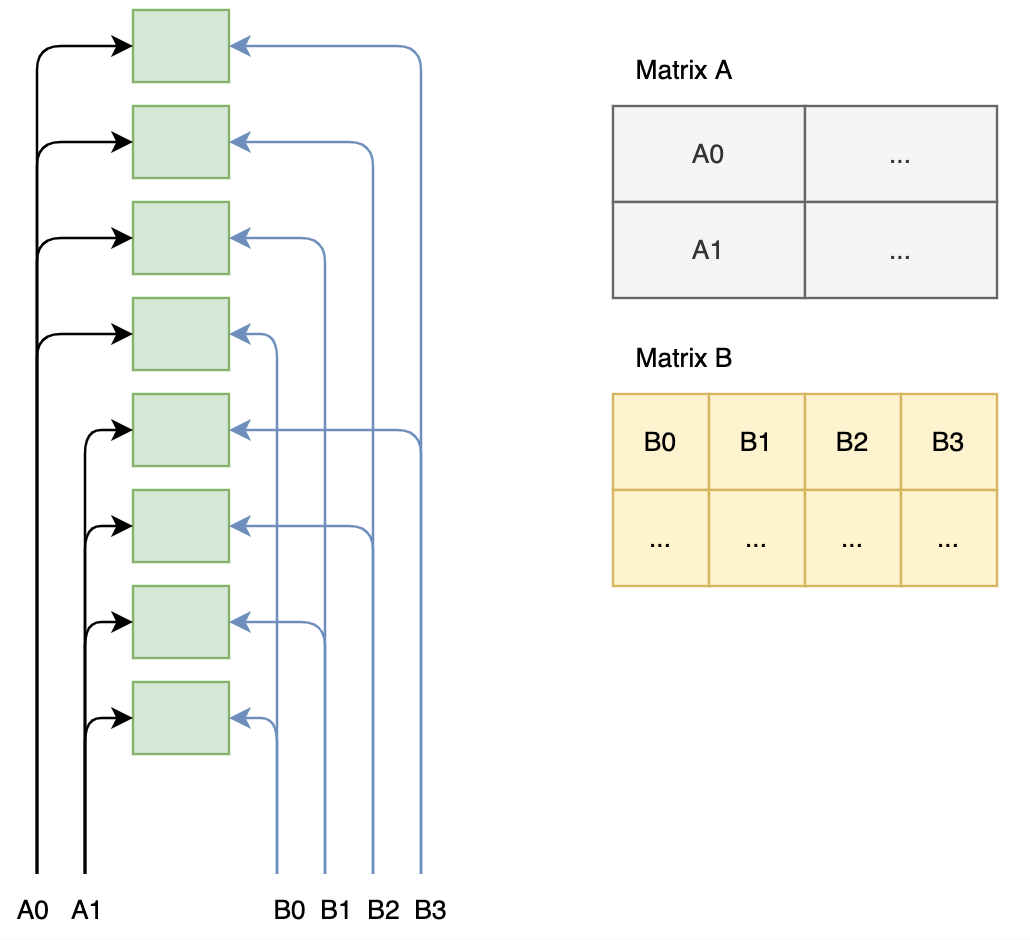
4. 一个32 cores的矩阵乘
按2.2的kernel code,第3节的广播方式,32 个cores能放下8条chain,处理能力如下:
|
struct |
M | N | K |
| one core | M | 8 | 8 |
| one chain(4cores) | -- | -- | x4 |
| two chains(8cores) | -- | x2 | -- |
| eight chains(32cores) | x4 | -- | -- |
| overall | 4*M | 16 | 32 |
显然的,第3节中可以将A/B 对调,也就是1播2的stream用来传A, 1播4 的线来传B, 32cores 的处理能力就是[2*M] x [32] x [32]。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号