

web框架本质
Web框架本质
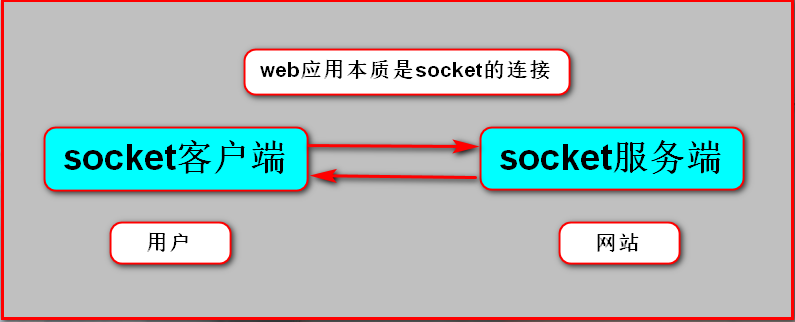
众所周知,对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端。
依据HTTP协议开发的web框架版本
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('127.0.0.1', 8000))
sock.listen()
while True:
conn, addr = sock.accept()
data = conn.recv(8096)
# 给回复的消息加上响应状态行
conn.send(b"HTTP/1.1 200 OK\r\n\r\n")
conn.send(b"OK")
conn.close()
根据不同的路径返回不同的内容
"""
根据URL中不同的路径返回不同的内容
"""
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按\r\n分割
data1 = data.split("\r\n")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容
if url == "/index/":
response = b"index"
elif url == "/home/":
response = b"home"
else:
response = b"404 not found!"
conn.send(response)
conn.close()
根据不同的路径返回不同的内容--函数版
"""
根据URL中不同的路径返回不同的内容--函数版
"""
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
# 将返回不同的内容部分封装成函数
def index(url):
s = "这是{}页面!".format(url)
return bytes(s, encoding="utf8")
def home(url):
s = "这是{}页面!".format(url)
return bytes(s, encoding="utf8")
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按\r\n分割
data1 = data.split("\r\n")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容,response是具体的响应体
if url == "/index/":
response = index(url)
elif url == "/home/":
response = home(url)
else:
response = b"404 not found!"
conn.send(response)
conn.close()
根据不同的路径返回不同的内容--函数进阶版
"""
根据URL中不同的路径返回不同的内容--函数进阶版
"""
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
# 将返回不同的内容部分封装成函数
def index(url):
s = "这是{}页面!".format(url)
return bytes(s, encoding="utf8")
def home(url):
s = "这是{}页面!".format(url)
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
list1 = [
("/index/", index),
("/home/", home),
]
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按\r\n分割
data1 = data.split("\r\n")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容
func = None # 定义一个保存将要执行的函数名的变量
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
# 返回具体的响应消息
conn.send(response)
conn.close()
返回具体的HTML文件
"""
根据URL中不同的路径返回不同的内容--函数进阶版
返回独立的HTML页面
"""
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
# 将返回不同的内容部分封装成函数
def index(url):
# 读取index.html页面的内容
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
# 返回字节数据
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
list1 = [
("/index/", index),
("/home/", home),
]
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按\r\n分割
data1 = data.split("\r\n")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容
func = None # 定义一个保存将要执行的函数名的变量
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
# 返回具体的响应消息
conn.send(response)
conn.close()
让网页动态起来
"""
根据URL中不同的路径返回不同的内容--函数进阶版
返回HTML页面
让网页动态起来
"""
import socket
import time
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
# 将返回不同的内容部分封装成函数
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.time())
s = s.replace("@@oo@@", now) # 在网页中定义好特殊符号,用动态的数据去替换提前定义好的特殊符号
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
list1 = [
("/index/", index),
("/home/", home),
]
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按\r\n分割
data1 = data.split("\r\n")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容
func = None # 定义一个保存将要执行的函数名的变量
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
# 返回具体的响应消息
conn.send(response)
conn.close()
服务器程序和应用程序
对于真实开发中的python web程序来说,一般会分为两部分:服务器程序和应用程序。
服务器程序负责对socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理。
应用程序则负责具体的逻辑处理。为了方便应用程序的开发,就出现了众多的Web框架,例如:Django、Flask、web.py 等。不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。
这样,服务器程序就需要为不同的框架提供不同的支持。这样混乱的局面无论对于服务器还是框架,都是不好的。对服务器来说,需要支持各种不同框架,对框架来说,只有支持它的服务器才能被开发出的应用使用。
这时候,标准化就变得尤为重要。我们可以设立一个标准,只要服务器程序支持这个标准,框架也支持这个标准,那么他们就可以配合使用。一旦标准确定,双方各自实现。这样,服务器可以支持更多支持标准的框架,框架也可以使用更多支持标准的服务器。
WSGI(Web Server Gateway Interface)就是一种规范,它定义了使用Python编写的web应用程序与web服务器程序之间的接口格式,实现web应用程序与web服务器程序间的解耦。
常用的WSGI服务器有uwsgi、Gunicorn。而Python标准库提供的独立WSGI服务器叫wsgiref,Django开发环境用的就是这个模块来做服务器。
wsgiref
利用wsgiref模块来替换我们自己写的web框架的socket server部分:
"""
根据URL中不同的路径返回不同的内容--函数进阶版
返回HTML页面
让网页动态起来
wsgiref模块版
"""
import time
from wsgiref.simple_server import make_server
# 将返回不同的内容部分封装成函数
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.time())
s = s.replace("@@oo@@", now)
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
list1 = [
("/index/", index),
("/home/", home),
]
def run_server(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ]) # 设置HTTP响应的状态码和头信息
url = environ['PATH_INFO'] # 取到用户输入的url
func = None
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
return [response, ]
if __name__ == '__main__':
httpd = make_server('127.0.0.1', 8090, run_server)
print("我在8090等你哦...")
httpd.serve_forever()
jinja2
上面的代码实现了一个简单的动态,我完全可以从数据库中查询数据,然后去替换我html中的对应内容,然后再发送给浏览器完成渲染。 这个过程就相当于HTML模板渲染数据。 本质上就是HTML内容中利用一些特殊的符号来替换要展示的数据。 我这里用的特殊符号是我定义的,其实模板渲染有个现成的工具: jinja2
下载jinja2:
pip install jinja2


<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="x-ua-compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> </head> <body> <h1>姓名:{{name}}</h1> <h1>爱好:</h1> <ul> {% for hobby in hobby_list %} <li>{{hobby}}</li> {% endfor %} </ul> </body> </html>
使用jinja2渲染index2.html文件:
from wsgiref.simple_server import make_server from jinja2 import Template def index(): with open("index2.html", "r") as f: data = f.read() template = Template(data) # 生成模板文件 ret = template.render({"name": "Alex", "hobby_list": ["烫头", "泡吧"]}) # 把数据填充到模板里面 return [bytes(ret, encoding="utf8"), ] def home(): with open("home.html", "rb") as f: data = f.read() return [data, ] # 定义一个url和函数的对应关系 URL_LIST = [ ("/index/", index), ("/home/", home), ] def run_server(environ, start_response): start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ]) # 设置HTTP响应的状态码和头信息 url = environ['PATH_INFO'] # 取到用户输入的url func = None # 将要执行的函数 for i in URL_LIST: if i[0] == url: func = i[1] # 去之前定义好的url列表里找url应该执行的函数 break if func: # 如果能找到要执行的函数 return func() # 返回函数的执行结果 else: return [bytes("404没有该页面", encoding="utf8"), ] if __name__ == '__main__': httpd = make_server('', 8000, run_server) print("Serving HTTP on port 8000...") httpd.serve_forever()
现在的数据是我们自己手写的,那可不可以从数据库中查询数据,来填充页面呢?
使用pymysql连接数据库:
conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="xxx", db="xxx", charset="utf8") cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) cursor.execute("select name, age, department_id from userinfo") user_list = cursor.fetchall() cursor.close() conn.close()
创建一个测试的user表:
CREATE TABLE user( id int auto_increment PRIMARY KEY, name CHAR(10) NOT NULL, hobby CHAR(20) NOT NULL )engine=innodb DEFAULT charset=UTF8;
模板的原理就是字符串替换,我们只要在HTML页面中遵循jinja2的语法规则写上,其内部就会按照指定的语法进行相应的替换,从而达到动态的返回内容。
