

关于Python执行过程中的内存优化的思考
通过思考变量的存储方式引发了我对于python中的内存优化的思考,思考许久开始查资料...
变量赋值存储的过程
变量赋值
首先,变量在存储的时候是怎样存储的(包括变量名和变量值),在这个地方了解到了栈区(存放变量名)和堆区(存放变量值),例如存取x = 10 如图:
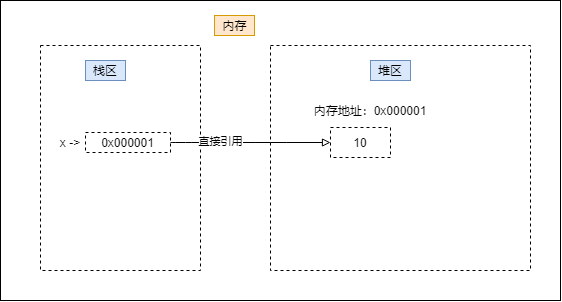
但是在这个的基础上y = x 的存储又是怎样的呢:
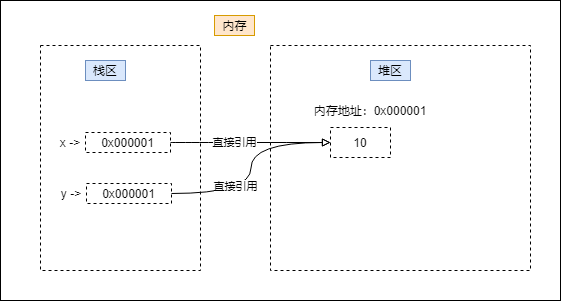
实际上 y 只是引用了 x 的指向的内存地址,如果 x 的指向地址再次发生改变的时候其实y是不会有任何变化的,例如x = 20 如图:
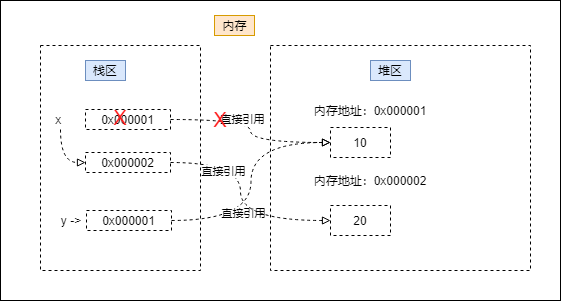
修改赋值
x 更改了存储的内存地址,但是 y 还是指向的之前的内存地址没有任何改变,具体代码的实现效果如下:
>>> x = 10
>>> x
10
>>> y = x
>>> y
10
>>> x = 20
>>> x
20
>>> y
10
列表的存储
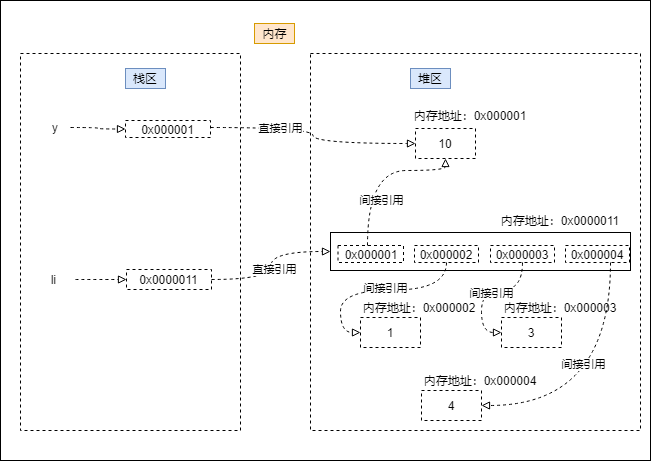
这个只是关于简单的数字存储,数字属于不可变的类型,文字存储相似,但是在列表等可变的类型的数据的存储是什么样的呢?
>>> y = 10
>>> li = [y,1,3,4]
>>> li
[10, 1, 3, 4]
具体存储如图:
内存存储机制
在大致了解了存储后思考了一个问题,就是在优化数字和字符上的内存机制上是怎样完成的呢,后面观察发现大致如下,主要从编译Python文件(compiler-time) --> 运行文件内容(run-time)两个部分完成
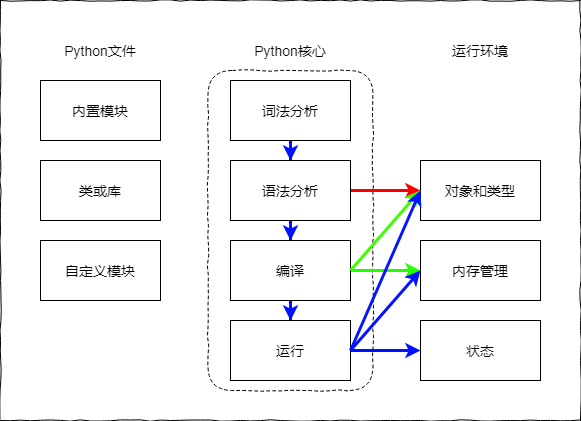
编译过程
首先在compiler-time(编译机制)上的缓存如下:
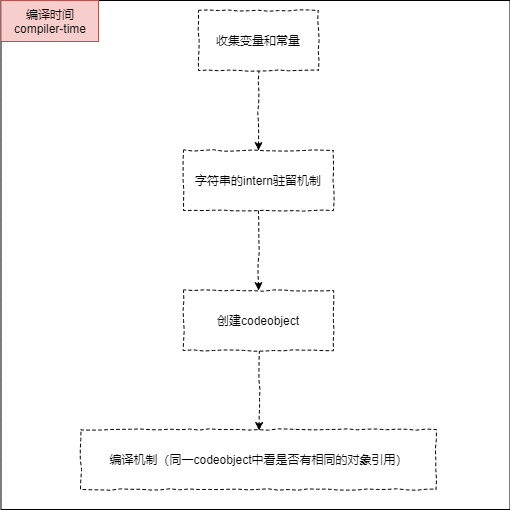
字符串的intern驻留机制
1、仅支持下划线、字母、数字组合
>>> a = "12345Sda_5421"
>>> b = "12345Sda_5421"
>>> a is b
True
>>> a = "1234 hedakl21"
>>> b = "1234 hedakl21"
>>> a is b
False
# 有空格所以不支持
2、不支持超过20个字符存储
>>> a = "1aA_" * 5
>>> b = "1aA_" * 5
>>> a is b
True
>>> a = "a" * 21
>>> b = "a" * 21
>>> a is b
False
codeobject编译模拟以及学会看编译过程
1、用内置compile模拟编译
a = 1
def func(d=0):
b=1
print("hello")
func()
# 命令行模式中打开源文件进行编译
>>a=open('test.py','r',encoding = "utf-8").read()
>>co=compile(a,'test','exec')
# 使用dis模块进行反编译
>>> import dis
>>> dis.dis(co)
37 0 LOAD_CONST 0 (1)
2 STORE_NAME 0 (a)
38 4 LOAD_CONST 6 ((0,))
6 LOAD_CONST 2 (<code object func at 0x000001D8C5AE54B0, file "test", line 38>)
8 LOAD_CONST 3 ('func')
10 MAKE_FUNCTION 1
12 STORE_NAME 1 (func)
41 14 LOAD_NAME 2 (print)
16 LOAD_CONST 4 ('hello')
18 CALL_FUNCTION 1
20 POP_TOP
42 22 LOAD_NAME 1 (func)
24 CALL_FUNCTION 0
26 POP_TOP
28 LOAD_CONST 5 (None)
30 RETURN_VALUE
'''从上面可以看出有两个codeobject对象,一个是全局的,还有一个是局部的函数中的,
不同的codeobject所指的对象不同'''
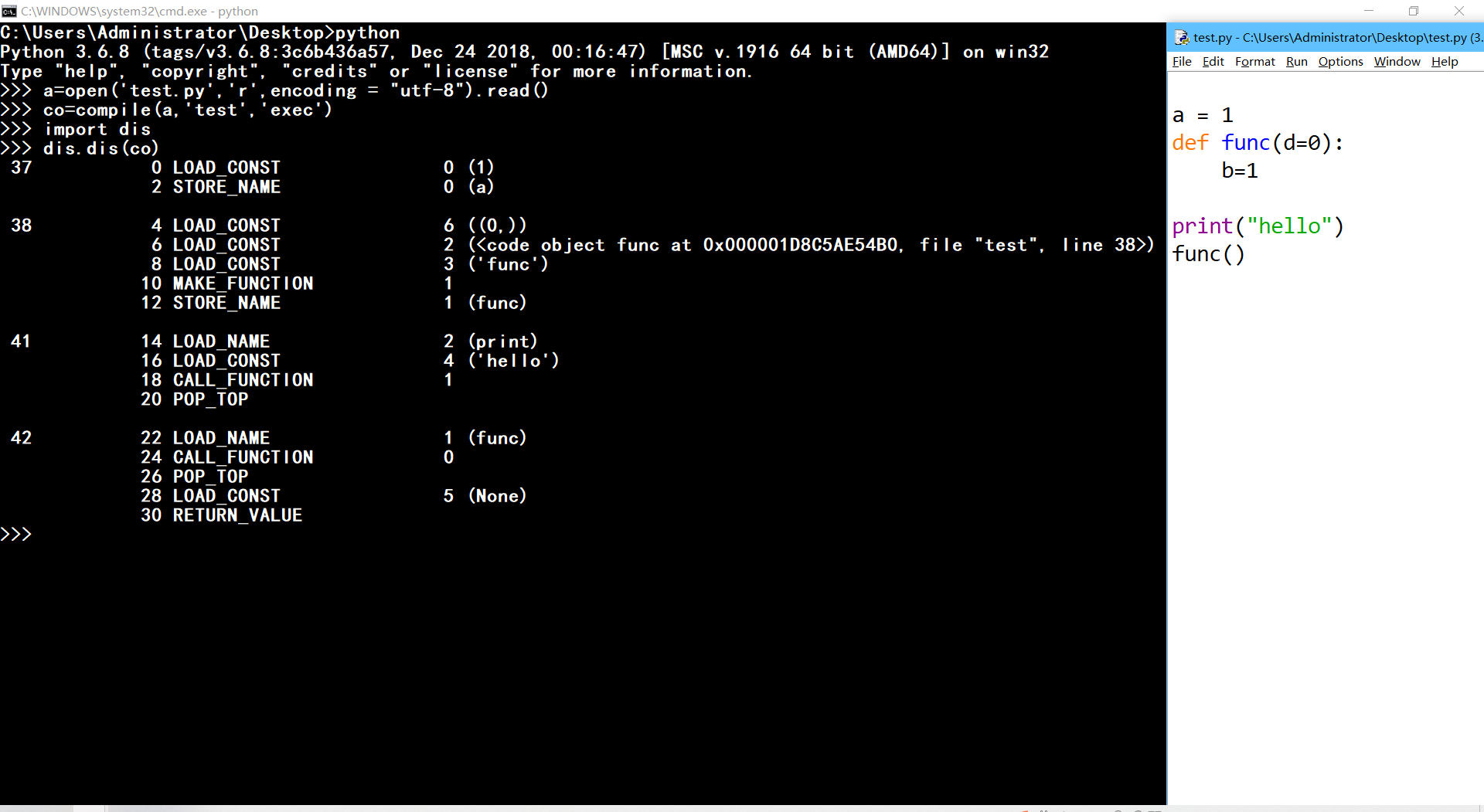
codeobject中的编译机制
# 第一列:行号
# 第二列:指令在代码块中的偏移量
# 第三列:指令
# 第四列:操作数
# 第五列:操作数说明
运行过程
小整数池的理解
1、对于[-5, 256]之间的所有小整数都存储在小整数池中的,不会被垃圾回收
>>> a = -5
>>> b = -5
>>> a is b
True
字符串缓存池的理解
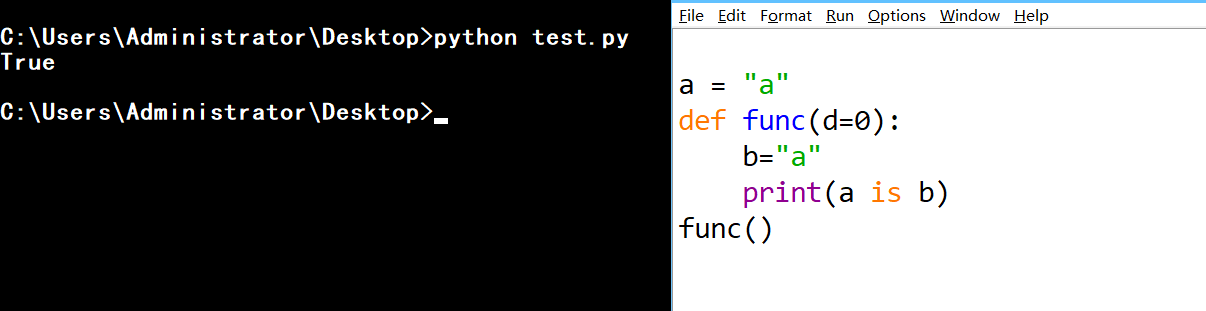
1、单个字符不会被回收
a = "a"
def func(d=0):
b="a"
print(a is b)
func()
# 虽然不在同一个codeobject中,但是在运行阶段单个字符会被字符串缓存池缓存,所以指向的是同一个对象
以上仅仅是个人对于内存机制的存储的浅析,内容正确与否仅代表的是个人的观点,如有其他意见可以给到证据,希望可以相互交流~
