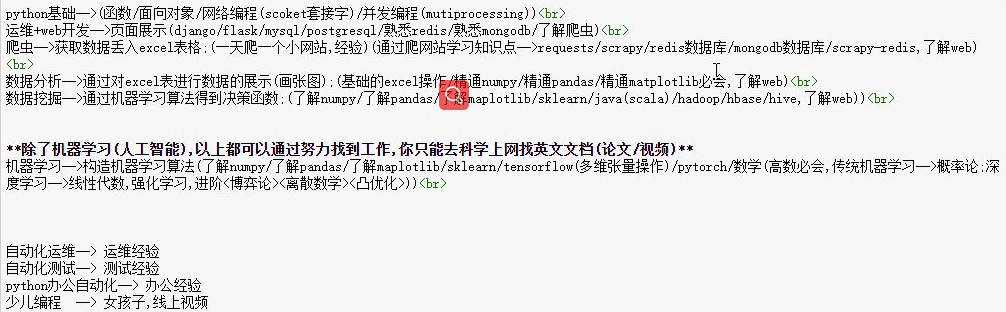
三个数据分析的模块
在一切开始前,先看一下这张图。这是python现在的就业方向,曾经的我好高骛远,不知天高地厚,师傅领进门,我要学python。豪言壮志我要搞机器学习。
现在我懂了,我把目标定在了数据分析,紧接着今天的教学内容又给我上了一课,但是我不服。
给老子打气!

今日洗脑金句:路漫漫其修远兮,吾将上下而求索。
numpy模块
这个模块用一句话来形容:专门数组(矩阵)的运算。
当然,只要是模块就必须要导入。
import numpy as np
也是约定俗成的,大家都把他实例化为np。用np就可以调用numpy的功能了。
那么它都是怎么运算的?
lis1 = [1, 2, 3] # 向量
lis2 = [4, 5, 6] # 向量
# [4,10,18]
lis = []
for i in range(len(lis1)):
lis.append(lis1[i] * lis2[i])
print(lis)
[4, 10, 18]
让你把两个列表的元素一一对应相乘,按照我们传统的方法就是这么做的。
如果你使用numpy模块来实现
import numpy as np
arr1 = np.array([1,2,3])
arr2 = np.array([4,5,6])
print(arr1*arr2)
就变得非常方便了。
解释一下这些都是什么
#numpy数组
arr = np.array([1, 2, 3])
print(arr) # 一维的numpy数组
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2) # 二维的numpy数组(一般就是二维)
arr3 = np.array([[[1, 2, 3], [4, 5, 6]],[[1, 2, 3], [4, 5, 6]],[[1, 2, 3], [4, 5, 6]]])
print(arr3)
#三维的不使用numpy模块,使用tensorflow/pytorch模块
arr是一个新的数据类型,numpy数组,arr是一个一维数组,arr2是一个二维数组,三维就不会用numpy来处理了。通常都是处理二维数组,一维很少。np.array(),方法就是生成数组的。
1.T 数组的转置(对高维数组而言)
2.dtype 数组元素的数据类型
3.size 数组元素的个数
4.ndim数组的维数
5.shape 数组的维度大小(以元组形式)
6.astype 类型转换'''
以上都是numpy数组的属性
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2) # 二维的numpy数组(一般就是二维)
print(arr2.T) # 行与列互换
print(arr2.dtype) # python中的数据类型,
print(arr2.astype(np.float64).dtype)
print(arr2.size)
print(arr2.shape)
print(arr2.ndim)
[[1 2 3]
[4 5 6]]
[[1 4]
[2 5]
[3 6]]
int32
float64
6
(2, 3)
2
解释的很清楚了。如果看不懂的话也没必要去较真,你看得懂也还远不够。
# 切片
lis = [1,2,3]
print(lis[:])
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
print(arr2) # 二维的numpy数组(一般就是二维)
print(arr2[:, :])
print(arr2[0:1, :])
print(arr2[0:1, 0:1])
print(arr2[0, :])
print(arr2[0, 0],type(arr2[0, 0]))
print(arr2[0, [0,2]])
print(arr2[0, 0] + 1)
[1, 2, 3]
[[1 2 3]
[4 5 6]]
[[1 2 3]
[4 5 6]]
[[1 2 3]]
[[1]]
[1 2 3]
1 <class 'numpy.int32'>
[1 3]
2
和字符串一样,numpy数组也有切片的功能。一个一个打印结果对应着看,应该很容易看明白(放屁)
# 修改值
lis = [1,2,3]
lis[0] = 2
print(lis)
arr2 = np.array([[1, 2, 3], [4, 5, 6]]) # 可变数据类型
print(arr2) # 二维的numpy数组(一般就是二维)
arr2[0, :] = 0
print(arr2)
arr2[1, 1] = 1
print(arr2)
arr2[arr2 < 3] = 3 # 布尔取值
print(arr2)
[2, 2, 3]
[[1 2 3]
[4 5 6]]
[[0 0 0]
[4 5 6]]
[[0 0 0]
[4 1 6]]
[[3 3 3]
[4 3 6]]
# 合并
arr1 = np.array([[1, 2, 3], [4, 5, 6]]) # 可变数据类型
print(arr1)
arr2 = np.array([[7, 8, 9], [10, 11, 12]]) # 可变数据类型
print(arr2)
print(np.hstack((arr1,arr2))) # 行合并
print(np.vstack((arr1,arr2))) # 列合并
print(np.concatenate((arr1, arr2))) # 默认列合并
print(np.concatenate((arr1, arr2),axis=1)) # 1表示行;0表示列
[[1 2 3]
[4 5 6]]
[[ 7 8 9]
[10 11 12]]
[[ 1 2 3 7 8 9]
[ 4 5 6 10 11 12]]
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
[[ 1 2 3 7 8 9]
[ 4 5 6 10 11 12]]
# 通过函数创建numpy数组
arr1 = np.array([[1, 2, 3], [4, 5, 6]]) # 可变数据类型
print(arr1)
print(np.zeros((5, 5)))
print(np.ones((5, 5)) * 100)
print(np.eye(5))
print(np.arange(1,10,2)) # 生成一维的
print(np.linspace(0,20,10)) # 平均分成10份 # 构造x坐标轴的值
arr = np.zeros((5, 5))
print(arr.reshape((1,25)))
[[1 2 3]
[4 5 6]]
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
[[100. 100. 100. 100. 100.]
[100. 100. 100. 100. 100.]
[100. 100. 100. 100. 100.]
[100. 100. 100. 100. 100.]
[100. 100. 100. 100. 100.]]
[[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]]
[1 3 5 7 9]
[ 0. 2.22222222 4.44444444 6.66666667 8.88888889 11.11111111
13.33333333 15.55555556 17.77777778 20. ]
[[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0.]]
懵逼了吗,没必要较真
# 数组运算
arr1 = np.array([[1, 2, 3], [4, 5, 6]]) # 可变数据类型
print(arr1)
arr2 = np.array([[7, 8, 9], [10, 11, 12]]) # 可变数据类型
print(arr2)
#+-*/ // % **
print(arr1*arr2)
print(arr1+arr2)
这个是最简单的了。
运算函数就不挂上去了,因为都是什么正弦余弦正切的,根本用不到,至少现在用不到,如果你想走数据分析这条道路的话,就得精通。
pandas模块
pandas更多的是excel/csv文件处理,excel文件, 对numpy+xlrd模块做了一层封装
所以pandas一般和numpy连用,numpy生成numpy数组,然后通过pandas生成个表格。
一、Series数据结构
历史遗留问题,现在已经不用这个了。
二、DataFrame数据结构
DataFrame是一个表格型的数据结构,含有一组有序的列。
DataFrame可以被看做是由Series组成的字典,并且共用一个索引。
dates = pd.date_range('20190101', periods=6, freq='M')
print(dates)
values = np.random.rand(6, 4) * 10
print(values)
columns = ['c1','c2','c3','c3']
df = pd.DataFrame(values,index=dates,columns=columns)
print(df)
DatetimeIndex(['2019-01-31', '2019-02-28', '2019-03-31', '2019-04-30',
'2019-05-31', '2019-06-30'],
dtype='datetime64[ns]', freq='M')
[[1.14330956 5.02778527 5.56126955 2.66649354]
[0.23009087 6.80907008 9.24073531 2.03374115]
[0.13695151 2.5131673 0.57219933 2.00328875]
[0.05006053 4.67975291 9.25777263 4.84685409]
[8.87645798 1.45425476 6.38351469 6.3532072 ]
[1.88228672 7.34926214 6.49032347 6.79507932]]
c1 c2 c3 c3
2019-01-31 1.143310 5.027785 5.561270 2.666494
2019-02-28 0.230091 6.809070 9.240735 2.033741
2019-03-31 0.136952 2.513167 0.572199 2.003289
2019-04-30 0.050061 4.679753 9.257773 4.846854
2019-05-31 8.876458 1.454255 6.383515 6.353207
2019-06-30 1.882287 7.349262 6.490323 6.795079
讲也讲不了什么,你看到的是什么规律,那他就是什么作用。
3、DataFrame属性
dtype 查看数据类型
index 查看行序列或者索引
columns 查看各列的标签
values 查看数据框内的数据,也即不含表头索引的数据
describe 查看数据每一列的极值,均值,中位数,只可用于数值型数据
transpose 转置,也可用T来操作
sort_index 排序,可按行或列
index排序输出sort_values 按数据值来排序
dates = pd.date_range('20190101', periods=6, freq='M')
values = np.random.rand(6, 4) * 10
columns = ['c1','c2','c3','c3']
df = pd.DataFrame(values,index=dates,columns=columns)
print(df.dtypes)
print(df.index)
print(df.columns)
print(df.describe())
print(df.T)
c1 float64
c2 float64
c3 float64
c3 float64
dtype: object
DatetimeIndex(['2019-01-31', '2019-02-28', '2019-03-31', '2019-04-30',
'2019-05-31', '2019-06-30'],
dtype='datetime64[ns]', freq='M')
Index(['c1', 'c2', 'c3', 'c3'], dtype='object')
c1 c2 c3 c3
count 6.000000 6.000000 6.000000 6.000000
mean 3.260165 3.826890 5.819315 4.290508
std 2.781914 3.270453 2.959151 3.732968
min 0.070209 0.396237 2.373191 0.919921
25% 1.214333 1.325428 3.318873 1.179912
50% 2.720464 3.507323 6.221180 3.212104
75% 5.708322 5.280542 7.434588 7.168175
max 6.633288 9.080714 9.909844 9.409539
2019-01-31 2019-02-28 2019-03-31 2019-04-30 2019-05-31 2019-06-30
c1 6.633288 1.806324 6.399562 0.070209 3.634604 1.017002
c2 0.396237 5.422510 4.854639 9.080714 1.047235 2.160007
c3 9.909844 2.513602 7.676892 5.734685 6.707676 2.373191
c3 5.084987 7.862571 9.409539 1.126809 1.339221 0.919921
四、DataFrame取值
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 2019-01-31 | 16.243454 | -6.117564 | -5.281718 | -10.729686 |
| 2019-02-28 | 8.654076 | -23.015387 | 17.448118 | -7.612069 |
| 2019-03-31 | 3.190391 | -2.493704 | 14.621079 | -20.601407 |
| 2019-04-30 | -3.224172 | -3.840544 | 11.337694 | -10.998913 |
| 2019-05-31 | -1.724282 | -8.778584 | 0.422137 | 5.828152 |
| 2019-06-30 | -11.006192 | 11.447237 | 9.015907 | 5.024943 |
4.1通过columns取值
df['c2']
2019-01-31 -6.117564
2019-02-28 -23.015387
2019-03-31 -2.493704
2019-04-30 -3.840544
2019-05-31 -8.778584
2019-06-30 11.447237
Freq: M, Name: c2, dtype: float64
df[['c2', 'c3']]
| c2 | c3 | |
|---|---|---|
| 2019-01-31 | -6.117564 | -5.281718 |
| 2019-02-28 | -23.015387 | 17.448118 |
| 2019-03-31 | -2.493704 | 14.621079 |
| 2019-04-30 | -3.840544 | 11.337694 |
| 2019-05-31 | -8.778584 | 0.422137 |
| 2019-06-30 | 11.447237 | 9.015907 |
4.2loc(通过标签取值)
# 通过自定义的行标签选择数据
df.loc['2019-01-01':'2019-01-03']
| c1 | c2 | c3 | c4 |
|---|---|---|---|
df[0:3]
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 2019-01-31 | 16.243454 | -6.117564 | -5.281718 | -10.729686 |
| 2019-02-28 | 8.654076 | -23.015387 | 17.448118 | -7.612069 |
| 2019-03-31 | 3.190391 | -2.493704 | 14.621079 | -20.601407 |
4.3iloc(类似于numpy数组取值)
df.values
array([[ 16.24345364, -6.11756414, -5.28171752, -10.72968622],
[ 8.65407629, -23.01538697, 17.44811764, -7.61206901],
[ 3.19039096, -2.49370375, 14.62107937, -20.60140709],
[ -3.22417204, -3.84054355, 11.33769442, -10.99891267],
[ -1.72428208, -8.77858418, 0.42213747, 5.82815214],
[-11.00619177, 11.4472371 , 9.01590721, 5.02494339]])
# 通过行索引选择数据
print(df.iloc[2, 1])
-2.493703754774101
df.iloc[1:4, 1:4]
| c2 | c3 | c4 | |
|---|---|---|---|
| 2019-02-28 | -23.015387 | 17.448118 | -7.612069 |
| 2019-03-31 | -2.493704 | 14.621079 | -20.601407 |
| 2019-04-30 | -3.840544 | 11.337694 | -10.998913 |
4.4使用逻辑判断取值
df[df['c1'] > 0]
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 2019-01-31 | 16.243454 | -6.117564 | -5.281718 | -10.729686 |
| 2019-02-28 | 8.654076 | -23.015387 | 17.448118 | -7.612069 |
| 2019-03-31 | 3.190391 | -2.493704 | 14.621079 | -20.601407 |
df[(df['c1'] > 0) & (df['c2'] > -8)]
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 2019-01-31 | 16.243454 | -6.117564 | -5.281718 | -10.729686 |
| 2019-03-31 | 3.190391 | -2.493704 | 14.621079 | -20.601407 |
五、DataFrame值替换
df
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 2019-01-31 | 16.243454 | -6.117564 | -5.281718 | -10.729686 |
| 2019-02-28 | 8.654076 | -23.015387 | 17.448118 | -7.612069 |
| 2019-03-31 | 3.190391 | -2.493704 | 14.621079 | -20.601407 |
| 2019-04-30 | -3.224172 | -3.840544 | 11.337694 | -10.998913 |
| 2019-05-31 | -1.724282 | -8.778584 | 0.422137 | 5.828152 |
| 2019-06-30 | -11.006192 | 11.447237 | 9.015907 | 5.024943 |
df.iloc[0:3, 0:2] = 0
df
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 2019-01-31 | 0.000000 | 0.000000 | -5.281718 | -10.729686 |
| 2019-02-28 | 0.000000 | 0.000000 | 17.448118 | -7.612069 |
| 2019-03-31 | 0.000000 | 0.000000 | 14.621079 | -20.601407 |
| 2019-04-30 | -3.224172 | -3.840544 | 11.337694 | -10.998913 |
| 2019-05-31 | -1.724282 | -8.778584 | 0.422137 | 5.828152 |
| 2019-06-30 | -11.006192 | 11.447237 | 9.015907 | 5.024943 |
df['c3'] > 10
2019-01-31 False
2019-02-28 True
2019-03-31 True
2019-04-30 True
2019-05-31 False
2019-06-30 False
Freq: M, Name: c3, dtype: bool
# 针对行做处理
df[df['c3'] > 10] = 100
df
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 2019-01-31 | 0.000000 | 0.000000 | -5.281718 | -10.729686 |
| 2019-02-28 | 100.000000 | 100.000000 | 100.000000 | 100.000000 |
| 2019-03-31 | 100.000000 | 100.000000 | 100.000000 | 100.000000 |
| 2019-04-30 | 100.000000 | 100.000000 | 100.000000 | 100.000000 |
| 2019-05-31 | -1.724282 | -8.778584 | 0.422137 | 5.828152 |
| 2019-06-30 | -11.006192 | 11.447237 | 9.015907 | 5.024943 |
# 针对行做处理
df = df.astype(np.int32)
df[df['c3'].isin([100])] = 1000
df
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 2019-01-31 | 0 | 0 | -5 | -10 |
| 2019-02-28 | 1000 | 1000 | 1000 | 1000 |
| 2019-03-31 | 1000 | 1000 | 1000 | 1000 |
| 2019-04-30 | 1000 | 1000 | 1000 | 1000 |
| 2019-05-31 | -1 | -8 | 0 | 5 |
| 2019-06-30 | -11 | 11 | 9 | 5 |
六、读取CSV文件(重点)
import pandas as pd
from io import StringIO
test_data = '''
5.1,,1.4,0.2
4.9,3.0,1.4,0.2
4.7,3.2,,0.2
7.0,3.2,4.7,1.4
6.4,3.2,4.5,1.5
6.9,3.1,4.9,
,,,
'''
test_data = StringIO(test_data)
df = pd.read_csv(test_data, header=None)
df.columns = ['c1', 'c2', 'c3', 'c4']
df
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 0 | 5.1 | NaN | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | NaN | 0.2 |
| 3 | 7.0 | 3.2 | 4.7 | 1.4 |
| 4 | 6.4 | 3.2 | 4.5 | 1.5 |
| 5 | 6.9 | 3.1 | 4.9 | NaN |
| 6 | NaN | NaN | NaN | NaN |
七、处理丢失数据
df.isnull()
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 0 | False | True | False | False |
| 1 | False | False | False | False |
| 2 | False | False | True | False |
| 3 | False | False | False | False |
| 4 | False | False | False | False |
| 5 | False | False | False | True |
| 6 | True | True | True | True |
# 通过在isnull()方法后使用sum()方法即可获得该数据集某个特征含有多少个缺失值
print(df.isnull().sum())
c1 1
c2 2
c3 2
c4 2
dtype: int64
# axis=0删除有NaN值的行
df.dropna(axis=0)
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 3 | 7.0 | 3.2 | 4.7 | 1.4 |
| 4 | 6.4 | 3.2 | 4.5 | 1.5 |
# axis=1删除有NaN值的列
df.dropna(axis=1)
| 0 |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
# 删除全为NaN值得行或列
df.dropna(how='all')
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 0 | 5.1 | NaN | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | NaN | 0.2 |
| 3 | 7.0 | 3.2 | 4.7 | 1.4 |
| 4 | 6.4 | 3.2 | 4.5 | 1.5 |
| 5 | 6.9 | 3.1 | 4.9 | NaN |
# 删除行不为4个值的
df.dropna(thresh=4)
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 3 | 7.0 | 3.2 | 4.7 | 1.4 |
| 4 | 6.4 | 3.2 | 4.5 | 1.5 |
# 删除c2中有NaN值的行
df.dropna(subset=['c2'])
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | NaN | 0.2 |
| 3 | 7.0 | 3.2 | 4.7 | 1.4 |
| 4 | 6.4 | 3.2 | 4.5 | 1.5 |
| 5 | 6.9 | 3.1 | 4.9 | NaN |
# 填充nan值
df.fillna(value=10)
| c1 | c2 | c3 | c4 | |
|---|---|---|---|---|
| 0 | 5.1 | 10.0 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 10.0 | 0.2 |
| 3 | 7.0 | 3.2 | 4.7 | 1.4 |
| 4 | 6.4 | 3.2 | 4.5 | 1.5 |
| 5 | 6.9 | 3.1 | 4.9 | 10.0 |
| 6 | 10.0 | 10.0 | 10.0 | 10.0 |
八、合并数据
df1 = pd.DataFrame(np.zeros((3, 4)))
df1
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 |
df2 = pd.DataFrame(np.ones((3, 4)))
df2
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2 | 1.0 | 1.0 | 1.0 | 1.0 |
# axis=0合并列
pd.concat((df1, df2), axis=0)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2 | 1.0 | 1.0 | 1.0 | 1.0 |
# axis=1合并行
pd.concat((df1, df2), axis=1)
| 0 | 1 | 2 | 3 | 0 | 1 | 2 | 3 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 |
# append只能合并列
df1.append(df2)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 |
| 0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1 | 1.0 | 1.0 | 1.0 | 1.0 |
| 2 | 1.0 | 1.0 | 1.0 | 1.0 |
九、导入导出数据
使用df = pd.read_excel(filename)读取文件,使用df.to_excel(filename)保存文件。
已经很晕了,我操
9.1读取文件导入数据
读取文件导入数据函数主要参数:
| 参数 | 详解 |
|---|---|
| sep | 指定分隔符,可用正则表达式如'\s+' |
| header=None | 指定文件无行名 |
| name | 指定列名 |
| index_col | 指定某列作为索引 |
| skip_row | 指定跳过某些行 |
| na_values | 指定某些字符串表示缺失值 |
| parse_dates | 指定某些列是否被解析为日期,布尔值或列表 |
df = pd.read_excel(filename)
df = pd.read_csv(filename)
9.1写入文件导出数据
写入文件函数的主要参数:
| 参数 | 详解 |
|---|---|
| sep | 分隔符 |
| na_rep | 指定缺失值转换的字符串,默认为空字符串 |
| header=False | 不保存列名 |
| index=False | 不保存行索引 |
| cols | 指定输出的列,传入列表 |
df.to_excel(filename)
十、pandas读取json文件(不推荐)
strtext = '[{"ttery":"min","issue":"20130801-3391","code":"8,4,5,2,9","code1":"297734529","code2":null,"time":1013395466000},\
{"ttery":"min","issue":"20130801-3390","code":"7,8,2,1,2","code1":"298058212","code2":null,"time":1013395406000},\
{"ttery":"min","issue":"20130801-3389","code":"5,9,1,2,9","code1":"298329129","code2":null,"time":1013395346000},\
{"ttery":"min","issue":"20130801-3388","code":"3,8,7,3,3","code1":"298588733","code2":null,"time":1013395286000},\
{"ttery":"min","issue":"20130801-3387","code":"0,8,5,2,7","code1":"298818527","code2":null,"time":1013395226000}]'
df = pd.read_json(strtext, orient='records')
df
| code | code1 | code2 | issue | time | ttery | |
|---|---|---|---|---|---|---|
| 0 | 8,4,5,2,9 | 297734529 | NaN | 20130801-3391 | 1013395466000 | min |
| 1 | 7,8,2,1,2 | 298058212 | NaN | 20130801-3390 | 1013395406000 | min |
| 2 | 5,9,1,2,9 | 298329129 | NaN | 20130801-3389 | 1013395346000 | min |
| 3 | 3,8,7,3,3 | 298588733 | NaN | 20130801-3388 | 1013395286000 | min |
| 4 | 0,8,5,2,7 | 298818527 | NaN | 20130801-3387 | 1013395226000 | min |
df.to_excel('pandas处理json.xlsx',
index=False,
columns=["ttery", "issue", "code", "code1", "code2", "time"])
matplotlib模块
https://www.cnblogs.com/nickchen121/p/10807571.html
为什么放链接在这里,因为我根本还没搞懂这个东西,我现在暂定的宏大目标是做数据分析,但是做数据分析一定要精通这篇博客里的全部内容,而且这些都还只是基础中的基础,就单单是matplotlib就有上千个参数,太多了,因此革命尚未成功,啊字仍需努力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号