这三大特性,让 G1 取代了 CMS!

大家好,我是树哥。
之前我们聊过 CMS 回收器,但那时候我们说 CMS 回收器已经落伍了,现在应该是用 G1 回收器的时候了。那么 G1 回收器到底有什么魔力,它比 CMS 回收器相比强在哪里呢?今天,就让树哥带大家盘一盘!
G1 回收器的历史
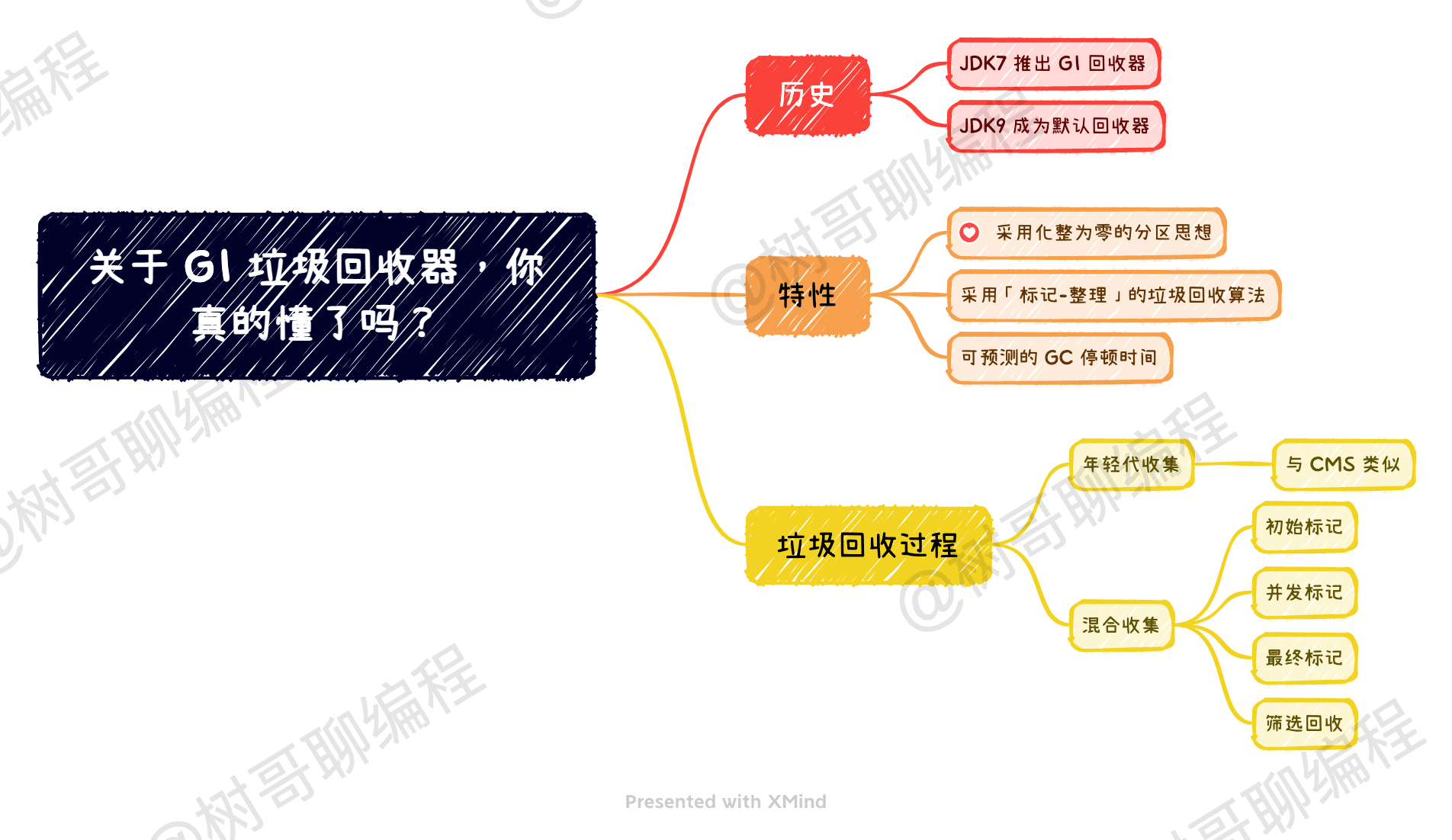
G1(Garbage-First)回收器早在 JDK1.7 的时候就确定要做,但直到 JDK7u4 的时候才正式推出使用。等到了 JDK9 之后变成了默认的垃圾回收器,同时废弃了 CMS 回收器。
G1 回收器特性
G1 回收器是一款面向服务端应用的垃圾回收器,它的长期实名是替换 CMS 回收器。
G1 回收器于 CMS 回收器相比,它们有相似的地方,例如:都是关注 GC 停顿时间的回收器,都采用了分代回收的思想。但从整体的实现上来看,G1 回收器做了非常多的改进,可以说是对 CMS 回收器的全面改进。相对于 CMS 回收器来说,G1 回收器有下面几个不同的地方:
- 采用化整为零的分区思想
- 采用标记-整理的垃圾回收算法
- 可预测的 GC 停顿时间
分区思想
对于 CMS 及之前的回收器来说,其 JVM 内存空间按照分代的思路划分成物理连续的一大片区域,如下图所示。

但在 G1 回收器中,虽然也采用了分代的思路,但其并没有为其分配一块连续的内存,而是将整块内存化整为零拆分成一个个 Region,如下图所示。

正如上图所示,G1 回收器不再为年轻代和老年代划分大块的内存,而是划分成了一个个的 Region,每个 Region 被标记成年轻代或者老年代。在 G1 中,还多了一个 Humongous 区域,其是为了优化大对象的分配而诞生的。
G1 回收器化整为零的 Region 设计思想,是 G1 回收器比 CMS 回收器强大的核心。 通过将大块的内存化整为零,G1 回收器能够更加灵活地控制 GC 停顿时间,并且也解决了 CMS 回收器存在的内存碎片问题以及大内存下的长 GC 停顿时间问题。
标记-整理算法
G1 回收器与 CMS 回收器的另一个很大的区别是:G1 回收器使用的是「标记-整理」算法,而 CMS 回收器使用的是「标记-清除」算法。 因此,CMS 回收器会产生非常多的内存碎片,而 G1 回收器则没有这个困扰。
有些小伙伴会问:那为什么 CMS 回收器不用「标记-整理」算法呢?
很简单,因为 CMS 回收器的老年代很大,使用「标记-整理」算法需要耗费很长的 GC 停顿时间,这会导致接口响应时间变长。实际上 CMS 回收器后续提供了 -XX:+UseCMSCompactAtFullCollection 参数去实现内存压缩,但在内存压缩的时候 GC 停顿时间会很长,从而导致接口响应时间变长。
好奇宝宝又问了:G1 回收器也用的是「标记-整理」算法,为啥就不会导致长 GC 停顿时间呢?
很简单,因为 G1 回收器使用了分 Region 的思想,其将大块的内存化整为零成为 Region。此外,其还维护了一个待回收 Region 列表,可以选择回收性价比最高的 Region 进行回收,从而实现对 GC 停顿时间的灵活控制。
看到了么,G1 回收器化整为零的 Region 设计思想,真的是 G1 回收器的大杀器!
可预测的停顿时间
G1 回收器对于 CMS 而言还有一个很大的优势,即能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在垃圾收集上的时间不得超过 N 毫秒。对于该特性现在还用得比较少,大家了解一下就可以了。
垃圾回收过程
比起 CMS 回收器来说,G1 回收器的垃圾回收过程就比较特别了,其采用了「年轻代收集」和「混合收集」两种垃圾回收方式。
年轻代收集
在应用刚刚启动的时候,流量慢慢进来,JVM 开始生成对象。G1 会选择一个分区并指定 eden 分区,当这块分区用满之后,G1 会选一个新的分区作为 eden 分区。这个操作会一直进行下去,一直到达到 eden 分区的上限,接着触发一次年轻代收集。
年代收集采用的是「复制算法」,其首先使用单 eden、双 survivor 迁移存活对象。在迁移过程中,会根据对象年龄以及其他特性,将对象晋升到老年代分区中,原有的年轻代分区会被整个回收掉。这个过程涉及到的规则和 CMS 回收器类似,只是 G1 回收器将内存化整为零了而已。
混合收集
随着时间推移,越来越多的对象晋升到老年代中。当老年代占比(占 Java 堆内存的比例)达到 InitiatingHeapOccupancyPercent 参数之后,JVM 便会触发「混合收集」进行垃圾收集。要注意的是:混合收集会收集年轻代和部分老年代的内存,其并不等同于 Full GC。Full GC 会回收整个老年代内存。
对于混合收集方式来说,其收集过程可以分为 4 个阶段:
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
初始标记。 该阶段与 CMS 回收器一样,都只是简单标记一下 GC Roots 能直接关联到的对象,让后续 GC 回收线程能与用户线程并发执行。初始标记阶段是需要「Stop the World」的。
并发标记。 该阶段与 CMS 回收器一样,它从 GC Root 开始对堆中对象进行可达性分析,找出存活的对象,这阶段耗时很长,但可与用户程序并发执行,不需要「Stop the World」。
最终标记。 该阶段与 CMS 回收器一样,它是为了修正在并发标记期间因用户程序继续运作而导致引用发生变化的问题。只是 G1 回收器采用了不同的方式去实现,在这个阶段是需要「Stop the World」的。
筛选回收。 该阶段与 CMS 回收器的并发清除一样,它是去将标记为垃圾的对象清除掉。只是对于 G1 回收器来说,它会维护各个 Region 的回收价值和成本,随后根据用户期望的 GC 停顿时间来指定回收计划。

整体看下来,我们会发现 G1 回收器的混合收集过程与 CMS 回收器非常类似,都经历初始标记、并发标记、最终标记、筛选回收(并发清除)几个阶段。
总结
从 JDK7 正式推出到 JDK9 成为默认的垃圾收集器,G1 回收器用了两代人的时间打败了 CMS 回收器。
从 G1 回收器的实现来看,其开创性的化整为零的 Region 设计思想,无疑是其打败 CMS 回收器的秘诀。通过该设计思想,G1 回收器得以更加灵活地控制 GC 停顿时间,同时也可以实现更加高效、复杂的功能,例如:根据回收空间和耗时选择最佳的回收 Region、预测 GC 停顿时间等。
参考资料
- 名字解释不错!VIP!搞懂 G1 垃圾收集器 - GrimMjx - 博客园
- 关于 GC 过程,写得不错!VIP!Java Hotspot G1 GC 的一些关键技术 - 美团技术团队
- 08 大厂面试题:有了 G1 还需要其他垃圾回收器吗?.md
- 官方资料!VIP!Garbage First Garbage Collector Tuning | Oracle 中国
- 官方资料!VIP!垃圾回收期的推荐使用场景!Java HotSpot Garbage Collection
- 还行!VIP!5 张图带你彻底理解 G1 垃圾收集器 - 51CTO.COM
- G1 垃圾收集器详解 - 掘金
- 深入理解 Java 虚拟机系列 --12 垃圾回收篇 03 -- 常用的垃圾回收器详解 - 掘金
- 深入理解 JAVA 垃圾收集器 CMS,G1 工作流程原理 - 掘金
- GC - Java 垃圾回收器之G1详解 | Java 全栈知识体系
- VIP!有美团的具体实践!GC - Java 垃圾回收器之ZGC详解 | Java 全栈知识体系
- 《深入理解 Java 虚拟机》
- CMS 垃圾回收器存在的问题及解决方案 - 代码先锋网




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧