IO多路复用完全解析
 本篇文章为BIO与阻塞IO的续篇,详细介绍了select、poll以及epoll等多路复用组件的使用方法以及底层原理。尤其详细分析了epoll的源码,做到一篇文章完全搞懂I/O多路复用模型
本篇文章为BIO与阻塞IO的续篇,详细介绍了select、poll以及epoll等多路复用组件的使用方法以及底层原理。尤其详细分析了epoll的源码,做到一篇文章完全搞懂I/O多路复用模型
上一篇文章以近乎啰嗦的方式详细描述了BIO与非阻塞IO的各种细节。如果各位还没有读过这篇文章,强烈建议先阅读一下,然后再来看本篇,因为逻辑关系是层层递进的。
1. 多路复用的诞生
非阻塞IO使用一个线程就可以处理所有socket,但是付出的代价是必须频繁调用系统调用来轮询每一个socket的数据,这种轮询太耗费性能,而且大部分轮询都是空轮询。
我们希望有个组件能同时监控多个socket,并在socket把数据准备好的时候告诉进程哪些socket已“就绪”,然后进程只对就绪的socket进行数据读写。
Java在JDK1.4的时候引入了NIO,并提供了Selector这个组件来实现这个功能。
2. NIO
在引入NIO代码之前,有点事情需要解释一下。
“就绪”这个词用得有点暧昧,因为不同的socket对就绪有不同的表达。比如对于监听socket而言,如果有客户端对其进行了连接,就说明处于就绪状态,它并不像连接socket一样,需要对数据的收发进行处理;相反,连接socket的就绪状态就至少包含了数据准备好读(is ready for reading)与数据准备好写(is ready for writing)这两种。
因此,可以想象,我们让Selector对多个socket进行监听时,必然需要告诉Selector,我们对哪些socket的哪些事件感兴趣。这个动作叫注册。
接下来看代码。
public class NIOServer {
static Selector selector;
public static void main(String[] args) {
try {
// 获得selector多路复用器
selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 监听socket的accept将不会阻塞
serverSocketChannel.configureBlocking(false);
serverSocketChannel.socket().bind(new InetSocketAddress(8099));
// 需要把监听socket注册到多路复用器上,并告诉selector,需要关注监听socket的OP_ACCEPT事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 该方法会阻塞
selector.select();
// 得到所有就绪的事件,事件被封装成了SelectionKey
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) {
handleAccept(key);
} else if (key.isReadable()) {
handleRead(key);
} else if (key.isWritable()) {
//发送数据
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
// 处理「读」事件的业务逻辑
private static void handleRead(SelectionKey key) {
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer allocate = ByteBuffer.allocate(1024);
try {
socketChannel.read(allocate);
System.out.println("From Client:" + new String(allocate.array()));
} catch (IOException e) {
e.printStackTrace();
}
}
// 处理「连接」事件的业务逻辑
private static void handleAccept(SelectionKey key) {
ServerSocketChannel serverSocketChannel = (ServerSocketChannel) key.channel();
try {
// socketChannel一定是非空,并且这里不会阻塞
SocketChannel socketChannel = serverSocketChannel.accept();
// 将连接socket的读写设置为非阻塞
socketChannel.configureBlocking(false);
socketChannel.write(ByteBuffer.wrap("Hello Client, I am Server!".getBytes()));
// 注册连接socket的「读事件」
socketChannel.register(selector, SelectionKey.OP_READ);
} catch (IOException e) {
e.printStackTrace();
}
}
}
我们首先使用Selector.open();得到了selector这个多路复用对象;然后在服务端创建了监听socket,并将其设置为非阻塞,最后将监听socket注册到selector多路复用器上,并告诉selector,如果监听socket有OP_ACCEPT事件发生的话就要告诉我们。
我们在while循环中调用selector.select();方法,进程将会阻塞在该方法上,直到注册在selector上的任意一个socket有事件发生为止,才会返回。如果不信的话可以在selector.select();的下一行打个断点,debug模式运行后,在没有客户端连接的情况下断点不会被触发。
当select()返回,意味着有一个或多个socket已经处于就绪状态,我们使用Set<SelectionKey>来保存所有事件,SelectionKey封装了就绪的事件,我们循环每个事件,根据不同的事件类型进行不同的业务逻辑处理。
OP_READ事件就绪的话,我们就准备一个缓冲空间,将数据从内核空间读到缓冲中;如果是OP_ACCEPT就绪,那就调用监听socket的accept()方法得到连接socket,并且accept()不会阻塞,因为在最开始的时候我们已经将监听socket设置为非阻塞了。得到的连接socket同样需要设置为非阻塞,这样连接socket的读写操作就是非阻塞的,最后将连接socket注册到selector多路复用器上,并告诉selector,如果连接socket有OP_READ事件发生的话就要告诉我们。
上个动图对Java的多路复用代码做个解释。
接下来的重点自然是NIO中的select()的底层原理了,还是那句话,NIO之所以能提供多路复用的功能,本质上还是操作系统底层提供了多路复用的系统调用。
多路复用本质上就是同时监听多个socket的请求,当我们订阅的socket上有我们感兴趣的事件发生的时候,多路复用函数会返回,然后我们的用户程序根据返回结果继续处理这些就绪状态的socket。
但是,不同的多路复用模型在具体的实现上有所不同,主要体现在三个方面:
- 多路复用模型最多可以同时监听多少个socket?
- 多路复用模型会监听socket上哪些事件?
- 当socket就绪时,多路复用模型如何找到就绪的socket?
多路复用主要有3种,分别是select、poll和epoll,接下来将带着上面3个问题分别介绍这3种底层模型。
下文相关函数的声明以及参数的定义源于64位CentOS 7.9,内核版本为3.10.0
3. select
我们可以通过select告诉内核,我们对哪些描述符(这些描述符可以表示标准输入、监听socket或者连接socket等)的哪些事件(可读、可写、发生异常)感兴趣,或者某个超时时间之后直接返回。
举个例子,我们调用select告诉内核仅在下列情况下发生时才返回:
- 集合{1, 4, 7}中有任何描述符读就绪;
- 集合{2, 9}中有任何描述符写就绪;
- 集合{1, 3, 5}中有任何描述符有异常发生;
- 超过了10S,啥事儿也没有发生。
3.1. select使用方法
// 返回:若有就绪描述符则为其数目,若超时则为0,若出错则为-1
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);
nfds参数用来告诉select需要检查的描述符的个数,取值为我们感兴趣的最大描述符 + 1,按照刚才的例子来讲nfds应该是{{1, 4, 7}, {2, 9}, {1, 3, 5}}中的最大描述符+1,也就是9 + 1,为10。至于为什么这样,别急,我们下文再说。
timeout参数允许我们设置select的超时时间,如果超过指定时间还没有我们感兴趣的事件发生,就停止阻塞,直接返回。
readfds里保存的是我们对读就绪事件感兴趣的描述符,writefds保存的是我们对写就绪事件感兴趣的描述符,exceptfds保存的是我们对发生异常这种事件感兴趣的描述符。这三个参数会告诉内核,分别需要在哪些描述符上检测数据可读、可写以及发生异常。
但是这些描述符并非像我的例子一样,直接把集合{1, 4, 7}作为数组存起来,设计者从内存空间和使用效率的角度设计了fd_set这个数据结构,我们看一下它的定义以及某些重要信息。
// file: /usr/include/sys/select.h
/* __fd_mask 是 long int 类型的别名 */
typedef long int __fd_mask;
#define __NFDBITS (8 * (int) sizeof (__fd_mask))
typedef struct {
...
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];
...
} fd_set;
因此,fd_set的定义,其实就是long int类型的数组,元素个数为__FD_SETSIZE / __NFDBITS,我直接在我的CentOS上输出了一下两个常量值,如下:
#include <stdio.h>
#include "sys/select.h"
int main(){
printf("__FD_SETSIZE:%d\n",__FD_SETSIZE);
printf("__NFDBITS:%d\n",__NFDBITS);
return 0;
}
// 输出结果
__FD_SETSIZE:1024
__NFDBITS:64
因此该数组中一共有16个元素(1024 / 64 = 16),每个元素为long int类型,占64位。
数组的第1个元素用于表示描述符0~63,第2个元素用于表示描述符64~127,以此类推,每1个bit位用0、1两种状态表示是否检测当前描述符的事件。
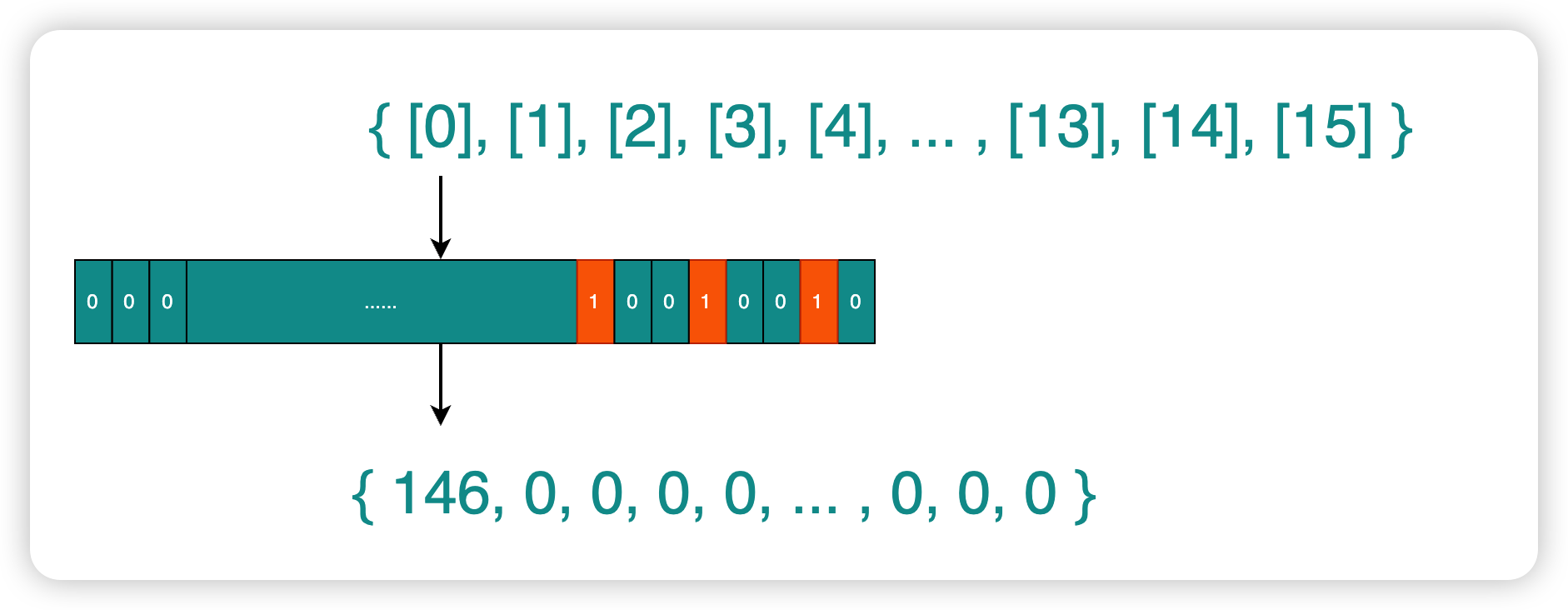
假设我们对{1, 4, 7}号描述符的读就绪事件感兴趣,那么readfds参数的数组第1个元素的二进制表示就如下图所示,第1、4、7位分别被标记为1,实际存储的10进制数字为146。
实际使用select的时候如果让我们自己推导上面这个过程进行参数设置那可费了劲了,于是操作系统提供了4个宏来帮我们设置数组中每个元素的每一位。
// 将数组每个元素的二进制位重置为0
void FD_ZERO(fd_set *fdset);
// 将第fd个描述符表示的二进制位设置为1
void FD_SET(int fd, fd_set *fdset);
// 将第fd个描述符表示的二进制位设置为0
void FD_CLR(int fd, fd_set *fdset);
// 检查第fd个描述符表示的二进制位是0还是1
int FD_ISSET(int fd, fd_set *fdset);
还是上面{1, 4, 7}这个例子,再顺带着介绍一下用法,知道有这么回事儿就行了。
fd_set readSet;
FD_ZERO(&readSet);
FD_SET(1, &readSet);
FD_SET(4, &readSet);
FD_SET(7, &readSet);
既然fd_set底层用的是数组,那就一定有长度限制,也就是说select同时监听的socket数量是有限的,你之前可能听过这个有限的数量是1024,但是1024是怎么来的呢?
3.2. 上限为什么是1024
其实select的监听上限就等于fds_bits数组中所有元素的二进制位总数。接下来我们用初中数学的解题步骤推理一下这个二进制位到底有多少。
已知:

证明如下:

结论就是__FD_SETSIZE这个宏其实就是select同时监听socket的最大数量。该数值在源码中有定义,如下所示:
// file: /usr/include/bits/typesizes.h
/* Number of descriptors that can fit in an `fd_set'. */
#define __FD_SETSIZE 1024
所以,select函数对每一个描述符集合fd_set,最多可以同时监听1024个描述符。
3.3. nfds的作用
为什么偏偏把最大值设置成1024呢?没人知道,或许只是程序员喜欢这个数字罢了。
最初设计select的时候,设计者考虑到大多数的应用程序根本不会用到很多的描述符,因此最大描述符的上限被设置成了31(4.2BSD版本),后来在4.4BSD中被设置成了256,直到现在被设置成了1024。
这个数量说多不多,说少也不算少,select()需要循环遍历数组中的位判断此描述符是否有对应的事件发生,如果每次都对1024个描述符进行判断,在我们感兴趣的监听描述符比较少的情况下(比如我上文的例子)那就是一种极大的浪费。于是,select给我们提供了nfds这个参数,让我们告诉select()只需要迭代数组中的前nfds个就行了,而不要总是在每次调用的时候遍历整个数组。
身为一个系统函数,执行效率自然需要优化到极致。
3.4. 再谈阻塞
上一篇文章讲过,当用户线程发起一个阻塞式的read系统调用,数据未就绪时,线程就会阻塞。阻塞其实是调用线程被投入睡眠,直到内核在某个时机唤醒线程,阻塞也就结束。这里我们借着select再聊一聊这个阻塞。
本小节中不做「进程」和「线程」的明确区分,线程作为轻量级进程来看待
内核会为每一个进程创建一个名为task_struct的数据结构,这个数据结构本身是分配在内核空间的,其中保存了当前进程的进程号、socket信息、CPU的运行上下文以及其他很重要但是我不讲的信息(/狗头)。
Linux内核维护了一个执行队列,里边放的都是处于TASK_RUNNING状态的进程的task_struct,这些进程以双向链表的方式排队等待CPU极短时间的临幸。
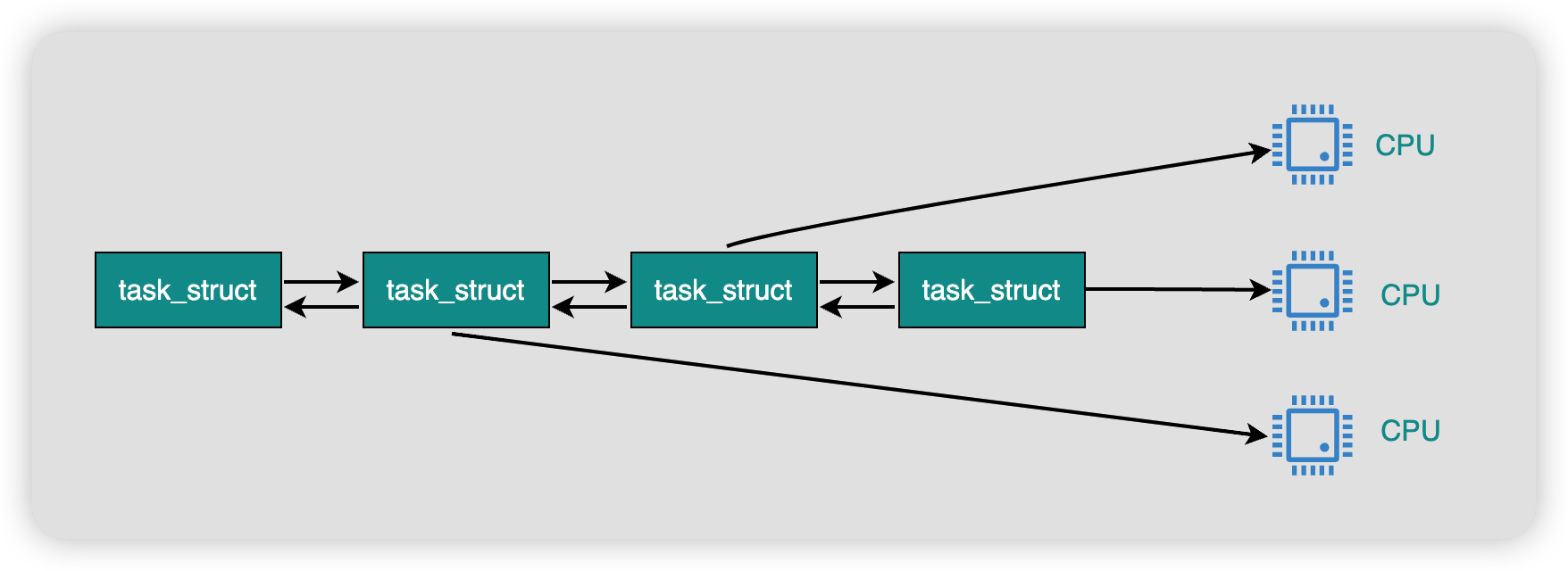
阻塞的本质就是将进程的task_struct移出执行队列,让出CPU的调度,将进程的状态的置为TASK_UNINTERRUPTIBLE或者TASK_INTERRUPTIBLE,然后添加到等待队列中,直到被唤醒。
那这个等待队列在哪儿呢?比如我们对一个socket发起一个阻塞式的 read 调用,用户进程肯定是需要和这个socket进行绑定的,要不然socket就绪之后都不知道该唤醒谁。这个等待队列其实就是保存在socket数据结构中,我们瞄一眼socket源码:
struct socket {
...
// 这个在epoll中会提到
struct file *file;
...
// struct sock - network layer representation of sockets
struct sock *sk;
...
};
struct sock {
...
// incoming packets
struct sk_buff_head sk_receive_queue;
...
// Packet sending queue
struct sk_buff_head sk_write_queue;
...
// socket的等待队列,wq的意思就是wait_queue
struct socket_wq __rcu *sk_wq;
};
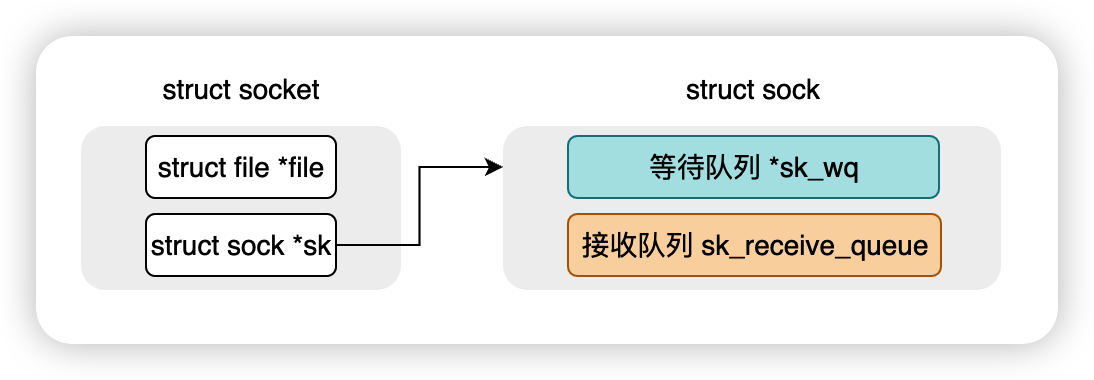
不用深入理解哈,只要知道socket自己维护了一个等待队列sk_wq,这个队列中每个元素保存的是:
- 阻塞在当前socket上的进程描述符
- 进程被唤醒之后应该调用的回调函数
这个回调函数是进程在加入等待队列的时候设置的一个函数指针(行话叫,向内核注册了一个回调函数),告诉内核:我正等着这个socket上的数据呢,先睡一会儿,等有数据了你就执行这个回调函数吧,里边有把我唤醒的逻辑。
就这样,经过网卡接收数据、硬中断以及软中断再到内核调用回调函数唤醒进程,把进程的task_struct从等待队列移动到执行队列,进程再次得到CPU的临幸,函数返回结果,阻塞结束。
现在回到select。
用户进程会阻塞在select之上,由于select会同时监听多个socket,因此当前进程会被添加到每个被监听的socket的等待队列中,每次唤醒还需要从每个socket等待队列中移除。
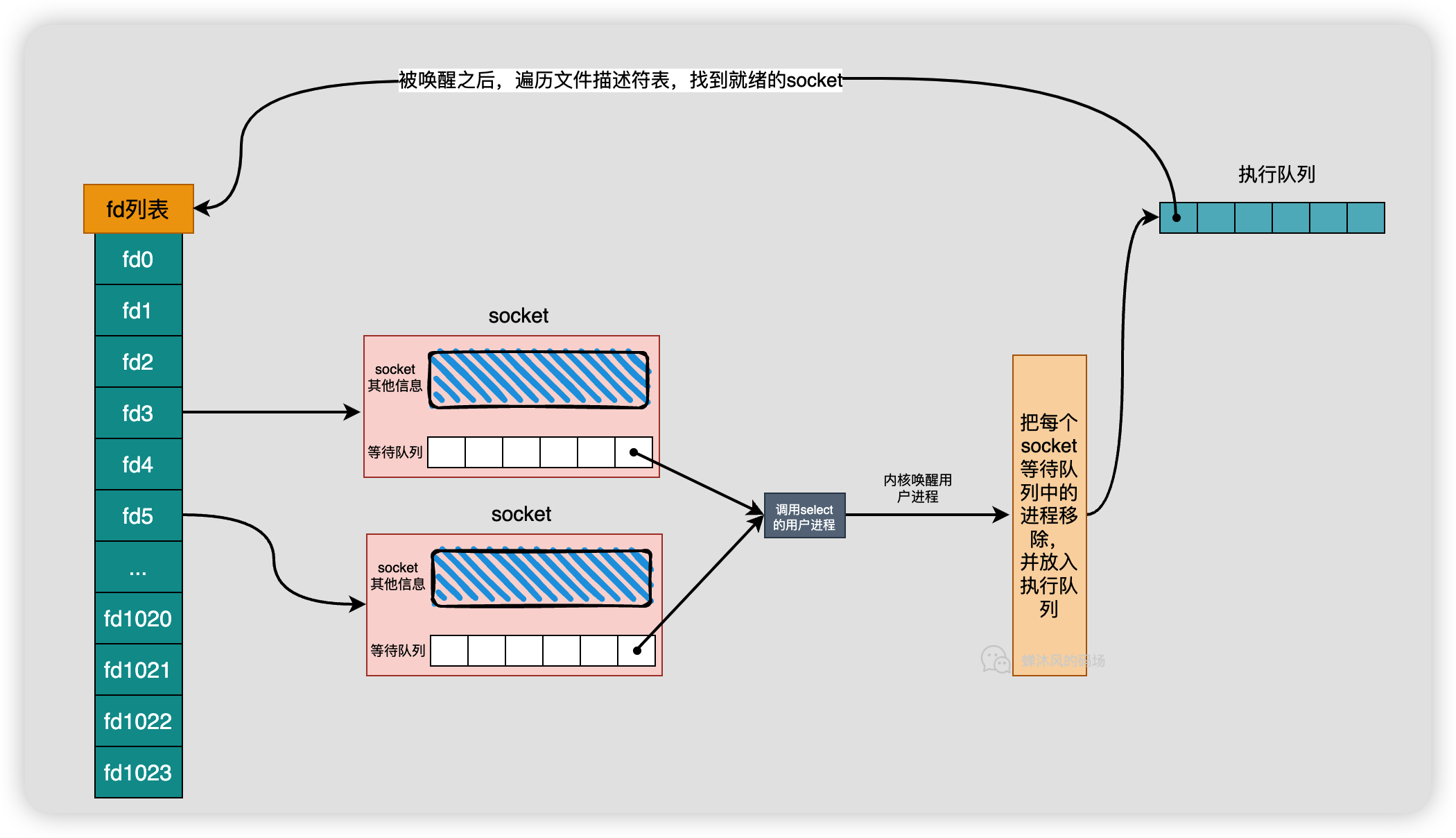
select的唤醒也有个问题,调用select的进程被唤醒之后是一脸懵啊,内核直接扔给他一个整数,进程不知道哪些socket收到数据了,还必须遍历一下才能知道。

3.5. select如何多路复用
select在超时时间内会被阻塞,直到我们感兴趣的socket读就绪、写就绪或者有异常事件发生(这话好像啰嗦了好多遍了,是不是自然而然已经记住了),然后select会返回已就绪的描述符数。
其实读就绪、写就绪或者有异常事件发生这3种事件里边的道道儿非常多,这里我们就仅作字面上的理解就好了,更多细节,可以参考《Unix网络编程 卷一》。
用户进程拿到这个整数说明了两件事情:
- 我们上文讲的所有
select操作都是在内核态运行的,select返回之后,权限交还到了用户空间; - 用户进程拿到这个整数,需要对
select监听的描述符逐个进行检测,判断二进制位是否被设置为1,进而进行相关的逻辑处理。可是问题是,内核把“就绪”的这个状态保存在了哪里呢?换句话说,用户进程该遍历谁?
select的readfds、writefds、exceptfds 3个参数都是指针类型,用户进程传递这3个参数告诉内核对哪些socket的哪些事件感兴趣,执行完毕之后反过来内核会将就绪的描述符状态也放在这三个参数变量中,这种参数称为值-结果参数。
用户进程通过调用FD_ISSET(int fd, fd_set *fdset)对描述符集进行判断即可,看个整体流程的动图。
-
用户进程设置
fd_set参数,调用select()函数,并将描述符集合拷贝到内核空间; -
为了提高效率,内核通过
nfds参数避免检测那些总为0的位,遍历的过程发生在内核空间,不存在系统调用切换上下文的开销; -
select函数修改由指针readset、writeset以及exceptset所指向的描述符集,函数返回时,描述符集中只有之前我们标记过的并且处于就绪状态的描述符对应的二进制位才是1,其余都会被重置为0(因此每次重新调用select时,我们必须把所有描述符集中感兴趣的位再次设置为1); -
进程根据
select()返回的结果判断操作是否正常,如果为0表示超时,-1表示出错,大于0表示有相应数量的描述符就绪了,进而利用FD_ISSET遍历检查所有相应类型的fd_set中的所有描述符,如果为1,则进行业务逻辑处理即可。
3.6. 总结
select(包括下文讲到的poll)是阻塞的,进程会阻塞在select之上,而不是阻塞在真正的I/O系统调用上,模型示意图见下图:
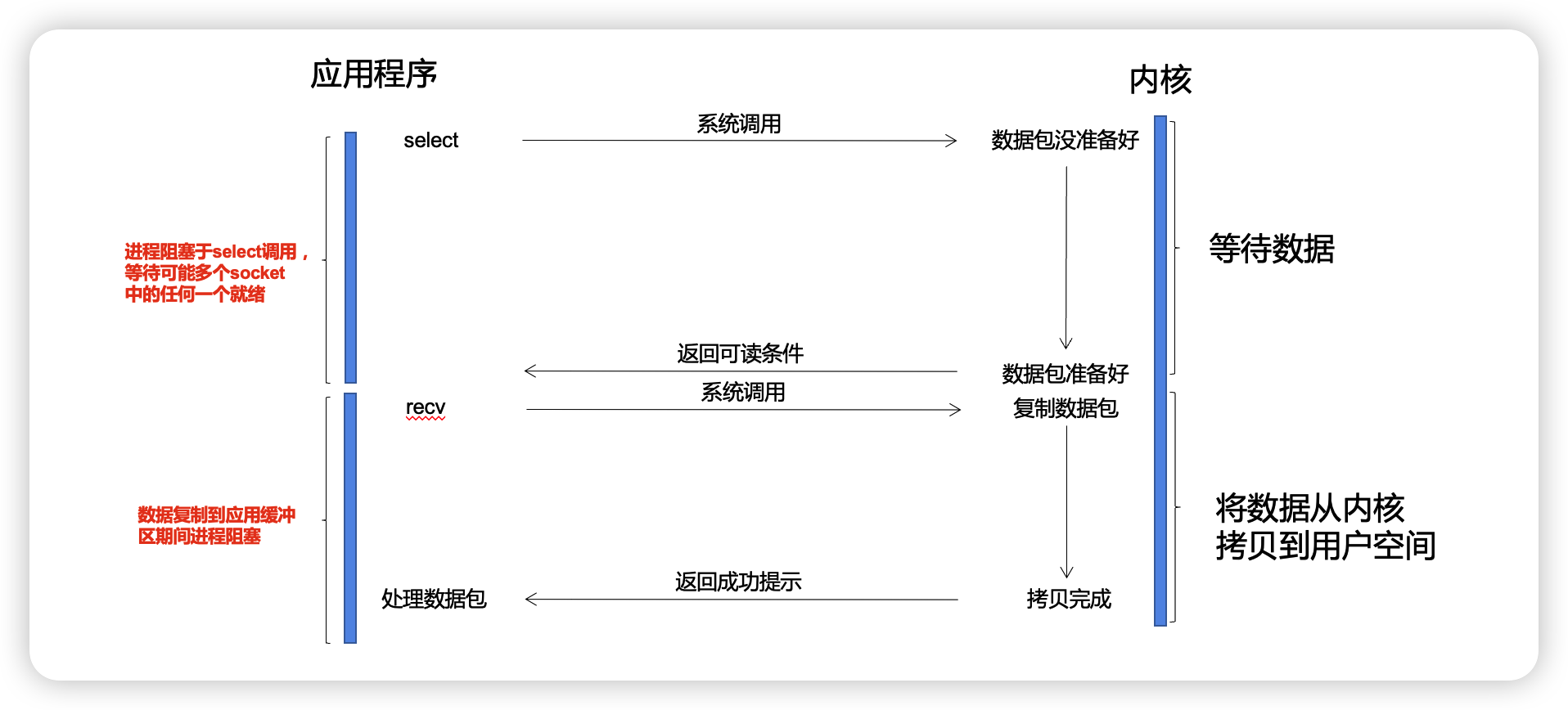
我们从头到尾都是使用一个用户线程来处理所有socket,同时又避免了非阻塞IO的那种无效轮询,为此付出的代价是一次select系统调用的阻塞,外加N次就绪文件描述符的系统调用。
4. poll
poll是select的继任者,接下来聊它。
4.1. 函数原型
先看一下函数原型:
// 返回:若有就绪描述符则为其数目,若超时则为0,若出错则为-1
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
函数有3个参数,第一个参数是一个pollfd类型的数组,其中pollfd结构如下:
struct pollfd {
int fd; /* file descriptor */
short events; /* events to look for */
short revents; /* events returned */
};
4.2. poll订阅的事件
pollfd由3部分组成,首先是描述符fd,其次events表示描述符fd上待检测的事件类型,一个short类型的数字用来表示多种事件,自然可以想到用的是二进制掩码的方式来进行位操作。
源码中我们可以找到所有事件的定义,我根据事件的分类对源码的顺序做了一定调整,如下:
// file: /usr/include/bits/poll.h
/* 第一类:可读事件 */
#define POLLIN 0x001 /* There is data to read. */
#define POLLPRI 0x002 /* There is urgent data to read. */
#define POLLRDNORM 0x040 /* Normal data may be read. */
#define POLLRDBAND 0x080 /* Priority data may be read. */
/* 第二类:可写事件 */
#define POLLOUT 0x004 /* Writing now will not block. */
#define POLLWRNORM 0x100 /* Writing now will not block. */
#define POLLWRBAND 0x200 /* Priority data may be written. */
/* 第三类:错误事件 */
#define POLLERR 0x008 /* Error condition. */
#define POLLHUP 0x010 /* Hung up. */
#define POLLNVAL 0x020 /* Invalid polling request. */
pollfd结构中还有一个revents字段,全称是“returned events”,这是poll与select的第1个不同点。
poll会将每次遍历之后的结果保存到revents字段中,没有select那种值-结果参数,也就不需要每次调用poll的时候重置我们感兴趣的描述符以及相关事件。
还有一点,错误事件不能在events中进行设置,但是当相应事件发生时会通过revents字段返回。这是poll与select的第2个不同点。
再来看poll的第2个参数nfds,表示的是数组fds的元素个数,也就是用户进程想让poll同时监听的描述符的个数。
如此一来,poll函数将设置最大监听数量的权限给了程序设计者,自由控制pollfd结构数组的大小,突破了select函数1024个最大描述符的限制。这是poll与select的第3个不同点。
至于timeout参数就更好理解了,就是设置超时时间罢了,更多细节朋友们可以查看一下api。
poll和select是完全不同的API设计,因此要说不同点那真是海了去了,但是由于本质上和select没有太大的变化,因此我们也只关注上面的这几个不同点也就罢了。需要注意的是poll函数返回之后,被唤醒的用户进程依然是懵的,踉踉跄跄地去遍历文件描述符、检查相关事件、进行相应逻辑处理。
其他的细节就再参考一下select吧,poll我们到此为止。
5. epoll
epoll是三者之中最强大的多路复用模型,自然也更难讲,要三言两语只讲一下epoll的优势倒也不难,不过会丧失很多细节,用源码解释又太枯燥,思来想去,于是。。。
我拖更了。。。

5.1. epoll入门
还是先从epoll的函数使用开始,不同于select/poll单个函数走天下,epoll用起来稍微麻烦了一点点,它提供了函数三件套,epoll_create、epoll_ctl、epoll_wait,我们一个个来看。
5.1.1. 创建epoll实例
// size参数从Linux2.6.8之后失去意义,为保持向前兼容,需要使size参数 > 0
int epoll_create(int size);
// 这个函数是最新款,如果falgs为0,等同于epoll_create()
int epoll_create1(int flags);
epoll_create() 方法创建了一个 epoll 实例,并返回了指向epoll实例的描述符,这个描述符用于下文即将介绍的另外两个函数。也可以使用epoll_create1()这个新函数,这个函数相比前者可以多添加EPOLL_CLOEXEC这个可选项,至于有啥含义,对本文并不重要。
这个epoll实例内部维护了两个重要结构,分别是需要监听的文件描述符树和就绪的文件描述符(这两个结构下文会讲),对于就绪的文件描述符,他们会被返回给用户进程进行处理,从这个角度来说,epoll避免了每次select/poll之后用户进程需要扫描所有文件描述符的问题。
5.1.2. epoll注册事件
创建完epoll实例之后,我们可以使用epoll_ctl(ctl就是control的缩写)函数,向epoll实例中添加、修改或删除我们感兴趣的某个文件描述符的某些事件。
// 返回值: 若成功返回0;若返回-1表示出错
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
第一个参数epfd就是刚才调用epoll_create创建的epoll实例的描述符,也就是epoll的句柄。
第二个参数op表示要进行什么控制操作,有3个选项
EPOLL_CTL_ADD: 向 epoll 实例注册文件描述符对应的事件;EPOLL_CTL_DEL:向 epoll 实例删除文件描述符对应的事件;EPOLL_CTL_MOD: 修改文件描述符对应的事件。
第三个参数fd很简单,就是被操作的文件描述符。
第四个参数就是注册的事件类型,我们先看一下epoll_event的定义:
struct epoll_event {
uint32_t events; /* 向epoll订阅的事件 */
epoll_data_t data; /* 用户数据 */
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
events这个字段和poll的events参数一样,都是通过二进制掩码设置事件类型,epoll的事件类型在/usr/include/sys/epoll.h中有定义,更详细的可以使用man epoll_ctl看一下文档说明,其中内容很多,知道有这么回事儿就行了,但是注意一下EPOLLET这个事件,我特意加了一下注释,下文会讲到。
enum EPOLL_EVENTS {
EPOLLIN = 0x001,
#define EPOLLIN EPOLLIN
EPOLLPRI = 0x002,
#define EPOLLPRI EPOLLPRI
EPOLLOUT = 0x004,
#define EPOLLOUT EPOLLOUT
EPOLLRDNORM = 0x040,
#define EPOLLRDNORM EPOLLRDNORM
EPOLLRDBAND = 0x080,
#define EPOLLRDBAND EPOLLRDBAND
EPOLLWRNORM = 0x100,
#define EPOLLWRNORM EPOLLWRNORM
EPOLLWRBAND = 0x200,
#define EPOLLWRBAND EPOLLWRBAND
EPOLLMSG = 0x400,
#define EPOLLMSG EPOLLMSG
EPOLLERR = 0x008,
#define EPOLLERR EPOLLERR
EPOLLHUP = 0x010,
#define EPOLLHUP EPOLLHUP
EPOLLRDHUP = 0x2000,
#define EPOLLRDHUP EPOLLRDHUP
EPOLLWAKEUP = 1u << 29,
#define EPOLLWAKEUP EPOLLWAKEUP
EPOLLONESHOT = 1u << 30,
#define EPOLLONESHOT EPOLLONESHOT
// 设置为 edge-triggered,默认为 level-triggered
EPOLLET = 1u << 31
#define EPOLLET EPOLLET
};
data字段比较有意思,我们可以在data中设置我们需要的数据,具体是什么意思现在说起来还有点麻烦,稍安勿躁,我们接着看最后一个函数。
5.1.3. epoll_wait
// 返回值: 成功返回的是一个大于0的数,表示事件的个数;0表示超时;出错返回-1.
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
这个是不是就感觉很熟悉了啊。epoll_wait的用法和select/poll很类似,用户进程被阻塞。不同的是,epoll会直接告诉用户进程哪些描述符已经就绪了。
第一个参数是epoll实例的描述符。
第二个参数是返回给用户空间的需要处理的I/O事件,是一个epoll_event类型的数组,数组的长度就是epoll_wait函数的返回值,再看一眼这个结构吧。
struct epoll_event {
uint32_t events; /* 向epoll订阅的事件 */
epoll_data_t data; /* 用户数据 */
};
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
events 表示具体的事件类型,至于这个data就是在epoll_ctl中设置的data,这样用户进程收到这个epoll_event,根据之前设置的data就能获取到相关信息,然后进行逻辑处理了。
第三个参数是一个大于 0 的整数,表示 epoll_wait 可以返回的最大事件值。
第四个参数是 epoll_wait 阻塞调用的超时值,如果设置为 -1,表示不超时;如果设置为 0 则立即返回,即使没有任何 I/O 事件发生。
5.2. edge-triggered 和 level-triggered
epoll还提供了一个利器——边缘触发(edge-triggered),也就是上文我没解释的EPOLLET 参数。
啥意思呢?我举个例子。如果有个socket有100个字节的数据可读,边缘触发(edge-triggered)和条件触发(level-triggered)都会产生读就绪事件。
但是如果用户进程只读取了50个字节,边缘触发就会陷入等待,数据不会丢失,但是你爱读不读,反正老子已经通知过你了;而条件触发会因为你还没有读完,兢兢业业地不停产生读就绪事件催你去读。
边缘触发只会产生一次事件提醒,效率和性能要高于条件触发,这是epoll的一个大杀器。
5.3. epoll进阶
5.3.1. file_operations与poll
进阶之前问个小问题,Linux下所有文件都可以使用select/poll/epoll来监听文件变化吗?
答案是不行!
只有底层驱动实现了 file_operations 中 poll 函数的文件类型才可以被 epoll 监视!
注意,这里的
file_operations中定义的poll和上文讲到的poll()是两码事儿,只是恰好名字一样罢了。
socket 类型的文件驱动实现了 poll 函数,具体实现是sock_poll(),因此才可以被 epoll 监视。
下面我摘录了 file_operations 中我们常见的函数定义给大家看一下。
// file: include/linux/fs.h
struct file_operations {
...
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
...
unsigned int (*poll) (struct file *, struct poll_table_struct *);
...
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
...
};
有点懵对吧,继续看。
Linux对文件的操作做了高度的抽象,每个开发者都可以开发自己的文件系统,Linux并不知道其中的具体文件应该怎样open、read/write或者release,所以Linux定义了file_operations这个“接口”,设备类型需要自己实现struct file_operations结构中定义的函数的细节。有点类似于Java中的接口和具体实现类的关系。
poll函数的作用我们下文再说。
5.3.2. epoll内核对象的创建
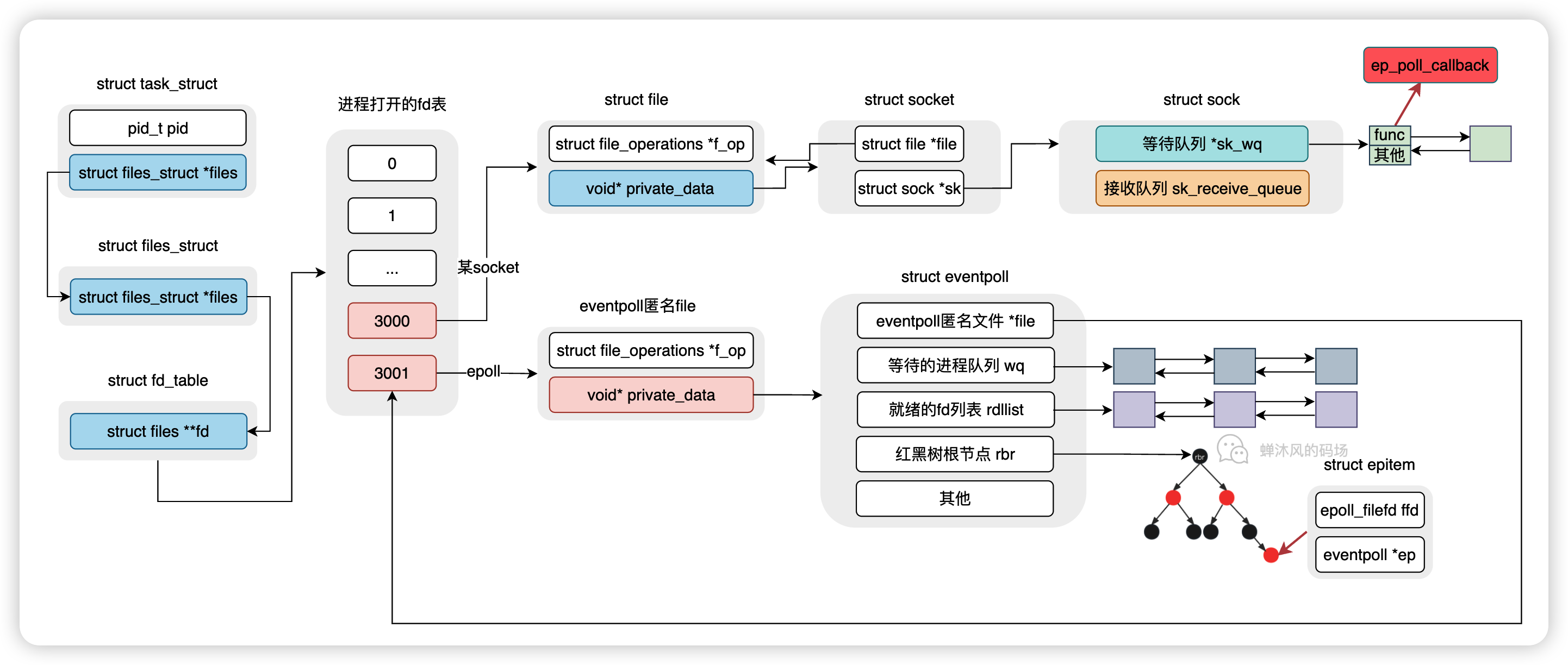
epoll_create()的主要作用是创建一个struct eventpoll内核对象,后续epoll的操作大部分都是对这个数据结构的操作。
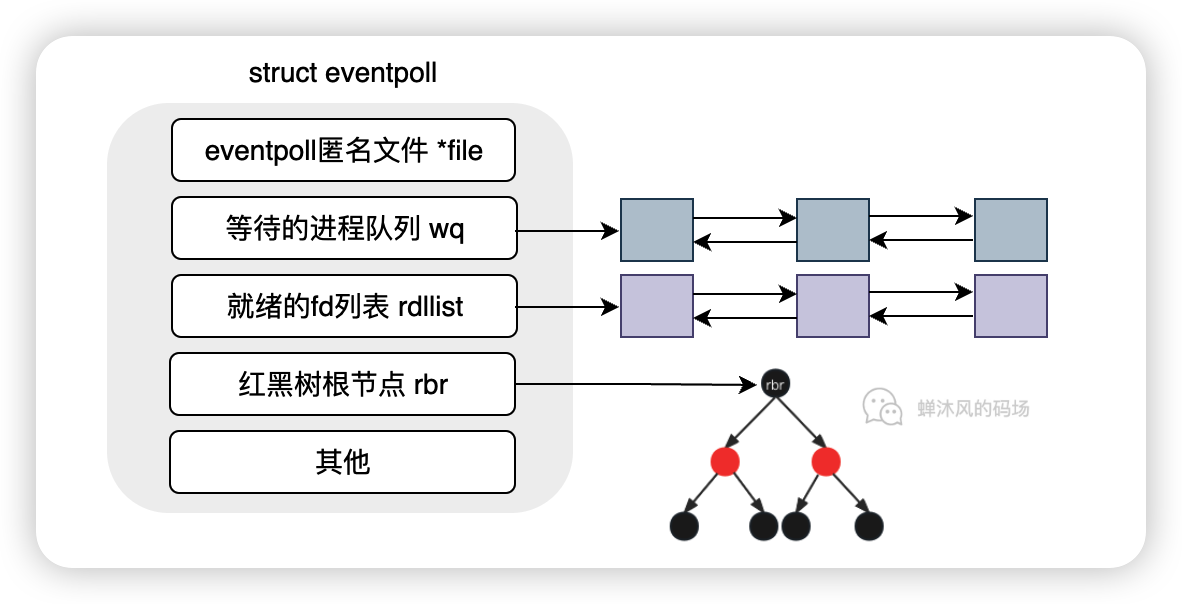
wq:等待队列。双向链表,软中断就绪的时候会通过wq找到阻塞在epoll对象上的进程;rdllist:就绪的描述符链表。双向链表,当描述符就绪时,内核会将就绪的描述符放到rdllist,这样用户进程就可以通过该链表直接找到就绪的描述符;rbr:Red Black Root。指向红黑树根节点,里边的每个节点表示的就是epoll监听的文件描述符。
然后,内核将eventpoll加入到当前进程已打开的文件列表中。啥?eventpoll也是一个文件?别急,我们看看epoll_create1的源码。
//file: /fs/eventpoll.c
SYSCALL_DEFINE1(epoll_create1, int, flags)
{
int error, fd;
struct eventpoll *ep = NULL;
struct file *file;
...
// 1. 为struct eventpoll分配内存并初始化
// 初始化操作主要包括初始化等待队列wq、rdllist、rbr等
error = ep_alloc(&ep);
...
// 2. 获取一个可用的描述符号fd,此时fd还未与具体的file绑定
fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));
...
// 3. 创建一个名为"[eventpoll]"的匿名文件file
// 并将eventpoll对象赋值到匿名文件file的private_data字段进行关联
file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep,
O_RDWR | (flags & O_CLOEXEC));
// 4. 将eventpoll对象的file指针指向刚创建的匿名文件file
ep->file = file;
// 5. 将fd和匿名文件file进行绑定
fd_install(fd, file);
return fd;
}
好好看一下代码中的注释(一定要看!),代码执行完毕的结果就如下图这般。
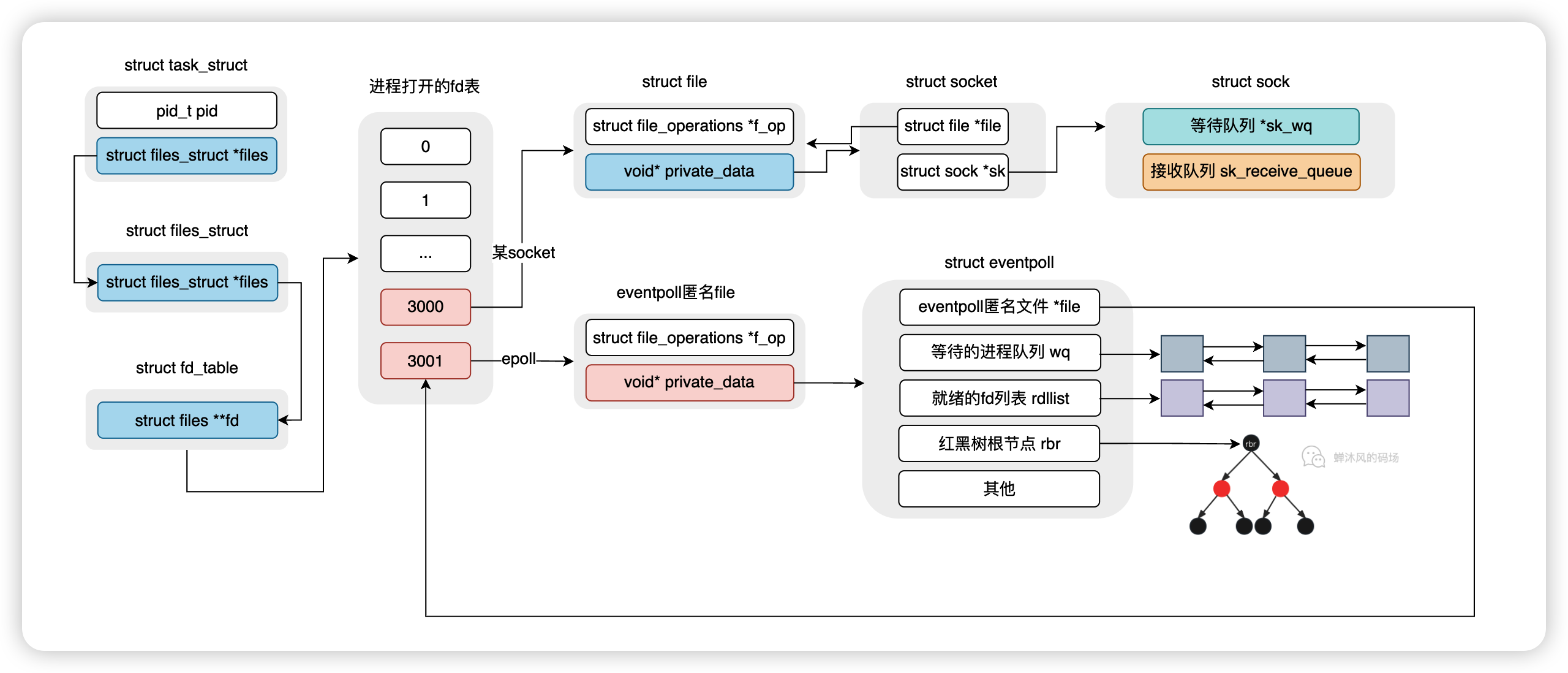
调用epoll_create1后得到的文件描述符本质上是匿名文件[eventpoll]的描述符,该匿名文件中的private_data字段才指向了真正的eventpoll对象。
Linux中的一切皆文件并非虚言。这样一来,eventpoll文件也可以被epoll本身监测,也就是说epoll实例可以监听其他的epoll实例,这一点很重要。
至此,epoll_create1调用结束。是不是很简单呐~
5.3.3. 添加socket到epoll
现在我们考虑使用EPOLL_CTL_ADD向epoll实例中添加fd的情况。
接下来会涉及到较多的源码,别恐惧,都很简单
这时候就要用到上文的rbr红黑树了, epoll_ctl对fd的增删改操查作实际上就是对这棵红黑树进行操作,树的节点结构epitem如下所示:
// file: /fs/eventpoll.c
struct epitem {
/* 红黑树的节点 */
struct rb_node rbn;
/* 用于将当前epitem连接到eventpoll中rdllist中的工具 */
struct list_head rdllink;
...
/* 该结构保存了我们想让epoll监听的fd以及该fd对应的file */
struct epoll_filefd ffd;
/* 当前epitem属于哪个eventpoll */
struct eventpoll *ep;
};
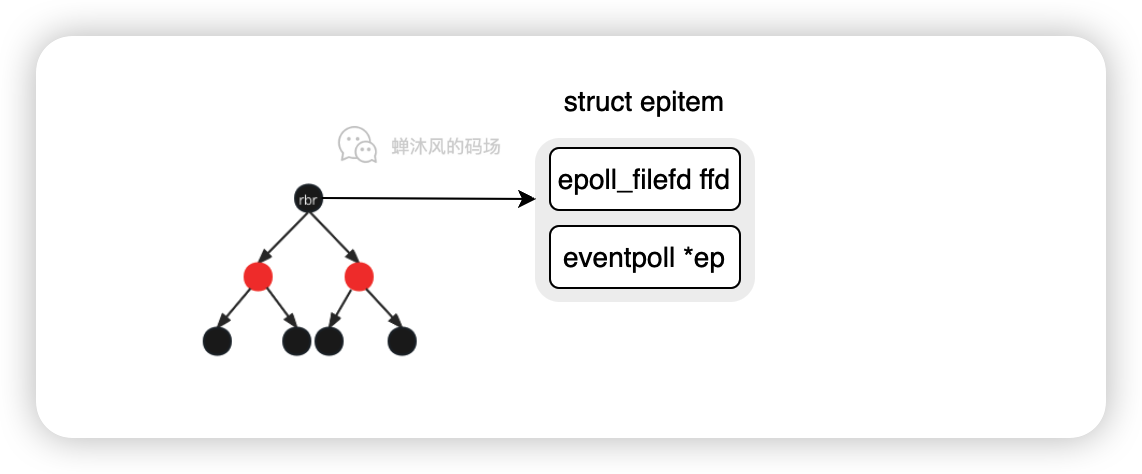
接着我们看一下epoll_ctl的源码。
// file: /fs/eventpoll.c
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd,
struct epoll_event __user *, event)
{
struct file *file, *tfile;
struct eventpoll *ep;
struct epitem *epi;
...
/* 根据epfd找到eventpoll对应的匿名文件 */
file = fget(epfd);
/* fd是我们感兴趣的socket描述符,根据它找到对应的文件 */
tfile = fget(fd);
/* 根据file的private_data字段找到eventpoll实例 */
ep = file->private_data;
...
/* 在红黑树中查找一下,看看是不是已经存在了
如果存在了,那就报错;否则,执行ep_insert */
epi = ep_find(ep, tfile, fd);
switch (op) {
case EPOLL_CTL_ADD:
if (!epi) {
epds.events |= POLLERR | POLLHUP;
error = ep_insert(ep, &epds, tfile, fd);
} else
error = -EEXIST;
clear_tfile_check_list();
break;
...
}
...
}
epoll_ctl中,首先根据传入的epfd以及fd找到相关的内核对象,然后在红黑树中判断这个epitem是不是已经存在,存在的话就报错,否则继续执行ep_insert函数。
ep_insert故名思义就是将epitem结构插入到红黑树当中,但是并非单纯插入那么简单,其中涉及到一些细节。
5.3.3.1. ep_insert
很多关键操作都是在ep_insert函数中完成的,看一下源码。
// file: /fs/eventpoll.c
static int ep_insert(struct eventpoll *ep, struct epoll_event *event,
struct file *tfile, int fd)
{
int error, revents, pwake = 0;
unsigned long flags;
long user_watches;
struct epitem *epi;
struct ep_pqueue epq;
// 1. 分配epitem内存空间
if (!(epi = kmem_cache_alloc(epi_cache, GFP_KERNEL)))
return -ENOMEM;
...
// 2. 将epitem进行初始化
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
epi->nwait = 0;
epi->next = EP_UNACTIVE_PTR;
...
/* 3. 初始化 poll table,设置回调函数为ep_ptable_queue_proc */
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
/*
* 4. 调用ep_ptable_queue_proc函数,
* 设置socket等待队列的回调函数为ep_poll_callback
*/
revents = ep_item_poll(epi, &epq.pt);
...
/* 5. epitem插入eventpoll的红黑树 */
ep_rbtree_insert(ep, epi);
...
}
5.3.3.2. 分配与初始化epitem
虽然源码行数不少,但是这一步非常简单,就是将epitem中的数据准备好,到插入的时候直接拿来用就行了。用一张图来说明这一步的重点问题。
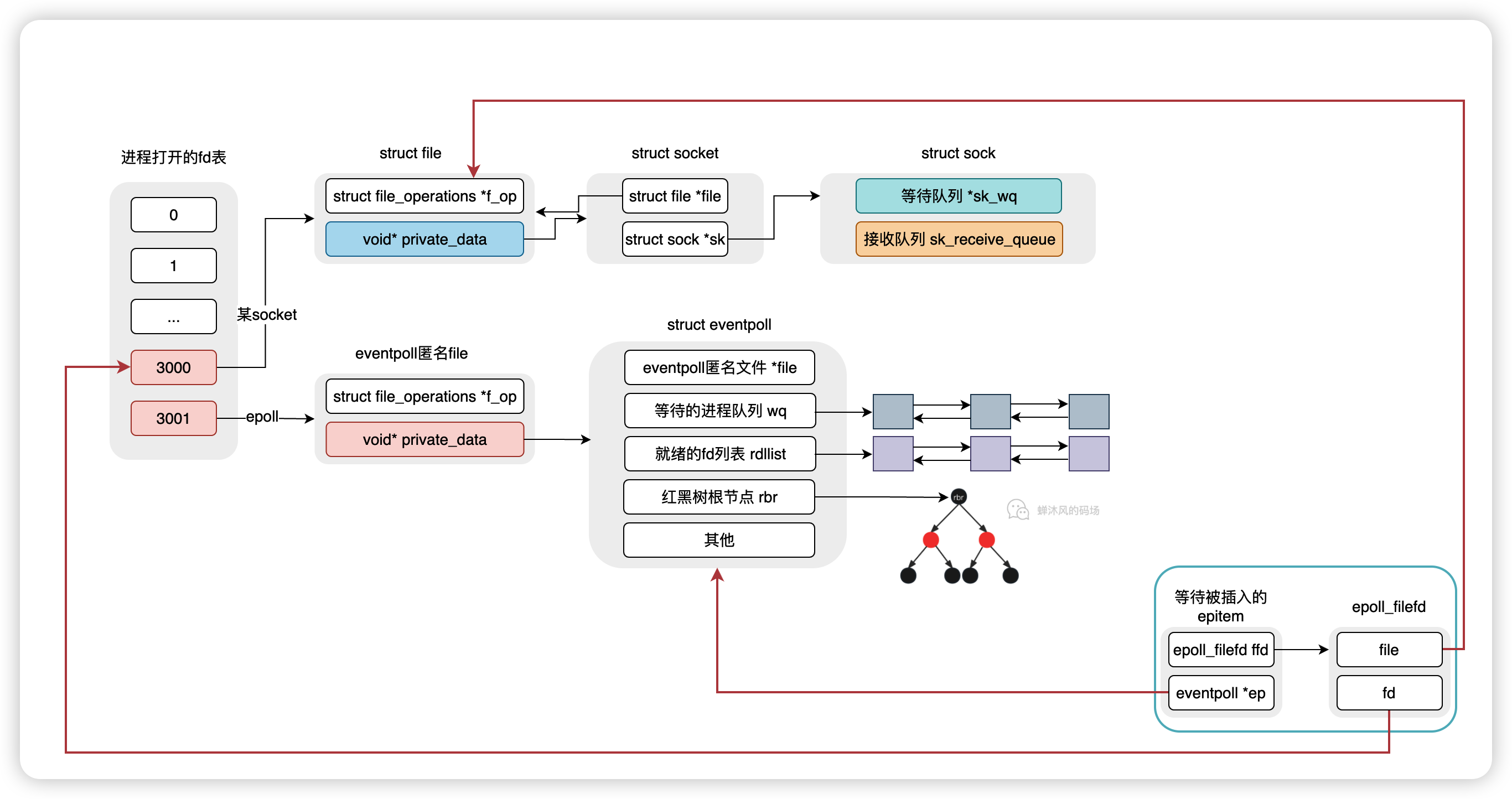
epitem已经准备好了,也就是监听的socket对象已经有了,就差插入到红黑树了,但是在插入之前需要解决个问题,当监听的对象就绪了之后内核该怎么办?
那就是设置回调函数!
这个回调函数是通过函数 ep_ptable_queue_proc 来进行设置的。回调函数是干什么的呢?就是当对应的文件描述符上有事件发生,就会调用这个函数,比如socket缓冲区有数据了,内核就会回调这个函数。这个函数就是 ep_poll_callback。
5.3.3.3. 设置回调函数
这一小节就是通过源码讲解如何设置ep_poll_callback回调函数的。
没有耐心的话可以暂时跳过这一小节,但是强烈建议整体看完之后回看这部分内容。
// file: /include/linux/poll.h
static inline void init_poll_funcptr(poll_table *pt, poll_queue_proc qproc)
{
pt->_qproc = qproc;
pt->_key = ~0UL; /* all events enabled */
}
init_poll_funcptr函数将poll_table结构的_qproc函数指针设置为qproc参数,也就是在ep_insert中看到的ep_ptable_queue_proc函数。
接下来轮到ep_item_poll了,扒开它看看。
// file: /fs/eventpoll.c
static inline unsigned int ep_item_poll(struct epitem *epi, poll_table *pt)
{
pt->_key = epi->event.events;
// 这行是重点
return epi->ffd.file->f_op->poll(epi->ffd.file, pt) & epi->event.events;
}
重点来了,通过上文我们知道了,ffd.file指的是socket代表的文件,也就是调用了socket文件自己实现的poll方法,也就是上文提到过的sock_poll()。
然后经过下面层层函数调用,最终来到了poll_wait函数。

// file: /include/linux/poll.h
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
{
if (p && p->_qproc && wait_address)
p->_qproc(filp, wait_address, p);
}
你看,poll_wait又调用了poll_table的_qproc函数,我们刚刚在init_poll_funcptr中将其设置为了ep_ptable_queue_proc,于是,代码来到了ep_ptable_queue_proc。
// file: /fs/eventpoll.c
static void ep_ptable_queue_proc(struct file *file, wait_queue_head_t *whead,
poll_table *pt)
{
...
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, GFP_KERNEL))) {
// 设置最终的回调方法ep_poll_callback
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback);
...
// 将包含ep_poll_callback在内的信息放入socket的等待队列
add_wait_queue(whead, &pwq->wait);
...
}
}
ep_ptable_queue_proc被我简化地只剩2个函数调用了,我们在3.4节中提到了socket自己维护了一个等待队列sk_wq,并且这个等待队列中的每一项保存了阻塞在当前socket上的进程描述符(明确知道该唤醒谁)以及回调函数(内核明确知道数据来了该怎么做)。
这一系列的操作就是设置回调函数为ep_poll_callback,并封装队列项数据结构,然后把这个结构放到socket的等待队列中。
还有一个小问题,不知道朋友们注意到了没有,我没提保存当前用户进程信息这回事儿。这也是epoll更加高效的一个原因,现在socket已经完全托管给epoll了,因此我们不能在一个socket准备就绪的时候就立刻去唤醒进程,唤醒的时机得交给epoll,这就是为什么eventpoll对象还有一个队列的原因,里边存放的就是阻塞在epoll上的进程。
再看一遍这个结构。
说完这些,你可能在想,交给epoll不也是让epoll唤醒嘛,有啥区别?还有ep_poll_callback这个回调具体怎么用也没解释。
别急,现在还不是解释的时候,继续往下。
5.3.3.4. 插入红黑树
最后一步就是通过ep_rbtree_insert(ep, epi)把epitem插入到红黑树中。
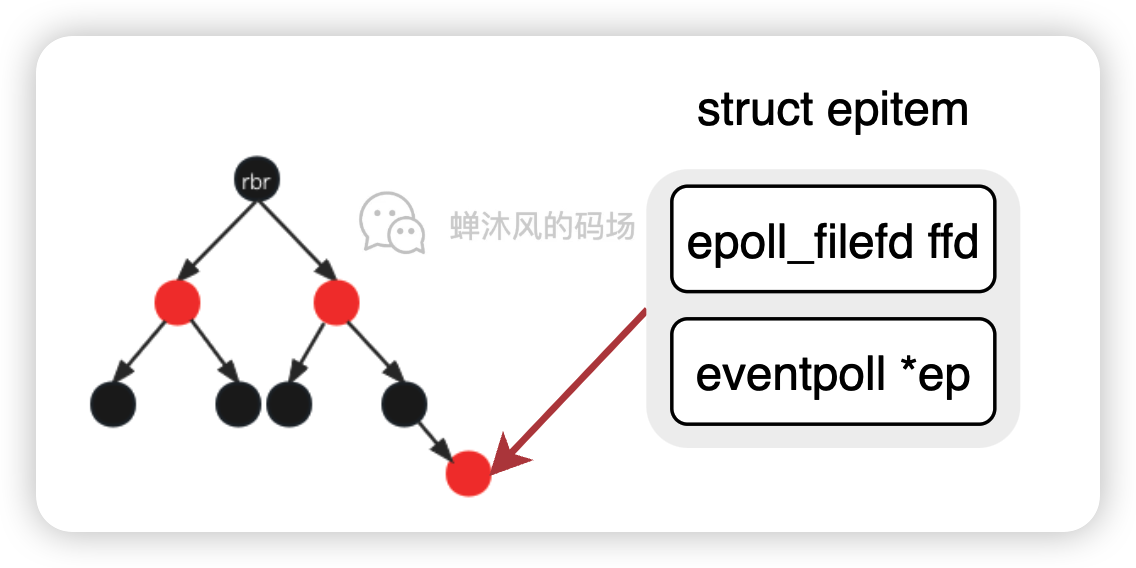
至此,epoll_ctl的整个调用过程全部结束。
此过程中我没有解释关于红黑树的任何操作,我也建议大家把它当成一个黑盒,只需要知道epoll底层采用了红黑树对epitem进行增删改查即可,毕竟学习红黑树不是我们的重点。
至于为什么内核开发者选择了红黑树这个结构,自然就是为了高效地管理epitem,使得在插入、查找、删除等各个方面不会因为epitem数量的增加而产生性能的剧烈波动。
上面几个小节的所有工作,得到了如下这一张图。
5.3.4. epoll_wait
epoll本身是阻塞的,阻塞也正是在这一步中体现的。
大部分人听到阻塞这个词就觉得很低效,这种想法并不对。
epoll_wait做的事情就是检查eventpoll对象中的就绪fd列表rdllist中是否有数据,如果有,就说明有socket已经准备好了,那就直接返回,用户进程对该列表中的fd进行处理。
如果列表为空,那就将当前进程加入到eventpoll的进程等待队列wq中,让出CPU,主动进入睡眠状态。
也就是说,只要有活儿(fd就绪),epoll会玩儿命一直干,绝对不阻塞。但是一旦没活儿了,阻塞就是一种正确的选择,要不然一直占用CPU也是一种极大的浪费。因此,epoll避免了很多不必要的进程上下文切换。
好了,现在来看epoll_wait的实现吧。
// file: /fs/eventpoll.c
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events,
int, maxevents, int, timeout)
{
...
error = ep_poll(ep, events, maxevents, timeout);
...
}
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events,
int maxevents, long timeout)
{
...
fetch_events:
...
// 如果就绪队列上没有时间发生,进入下面的逻辑
// 否则,就返回
if (!ep_events_available(ep)) {
/*
* We don't have any available event to return to the caller.
* We need to sleep here, and we will be wake up by
* ep_poll_callback() when events will become available.
*/
// 定义等待队列项,并将当前线程和其进行绑定,并设置回调函数
init_waitqueue_entry(&wait, current);
// 将等待队列项加入到wq等待队列中
__add_wait_queue_exclusive(&ep->wq, &wait);
for (;;) {
/*
* We don't want to sleep if the ep_poll_callback() sends us
* a wakeup in between. That's why we set the task state
* to TASK_INTERRUPTIBLE before doing the checks.
*/
// 让出CPU,进入睡眠状态
set_current_state(TASK_INTERRUPTIBLE);
...
if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS))
timed_out = 1;
...
}
...
}
...
}
源码中有部分英文注释我没有删除,读一下这些注释可能会对理解整个过程有帮助。
ep_poll做了以下几件事:
- 判断
eventpoll的rdllist队列上有没有就绪fd,如果有,那就直接返回;否则执行下面的步骤; - 定义
eventpoll的wq等待队列项,将当前进程绑定至队列项,并且设置回调函数; - 将等待队列项加入到
wq队列; - 当前进程让出CPU,进入睡眠状态,进程阻塞。
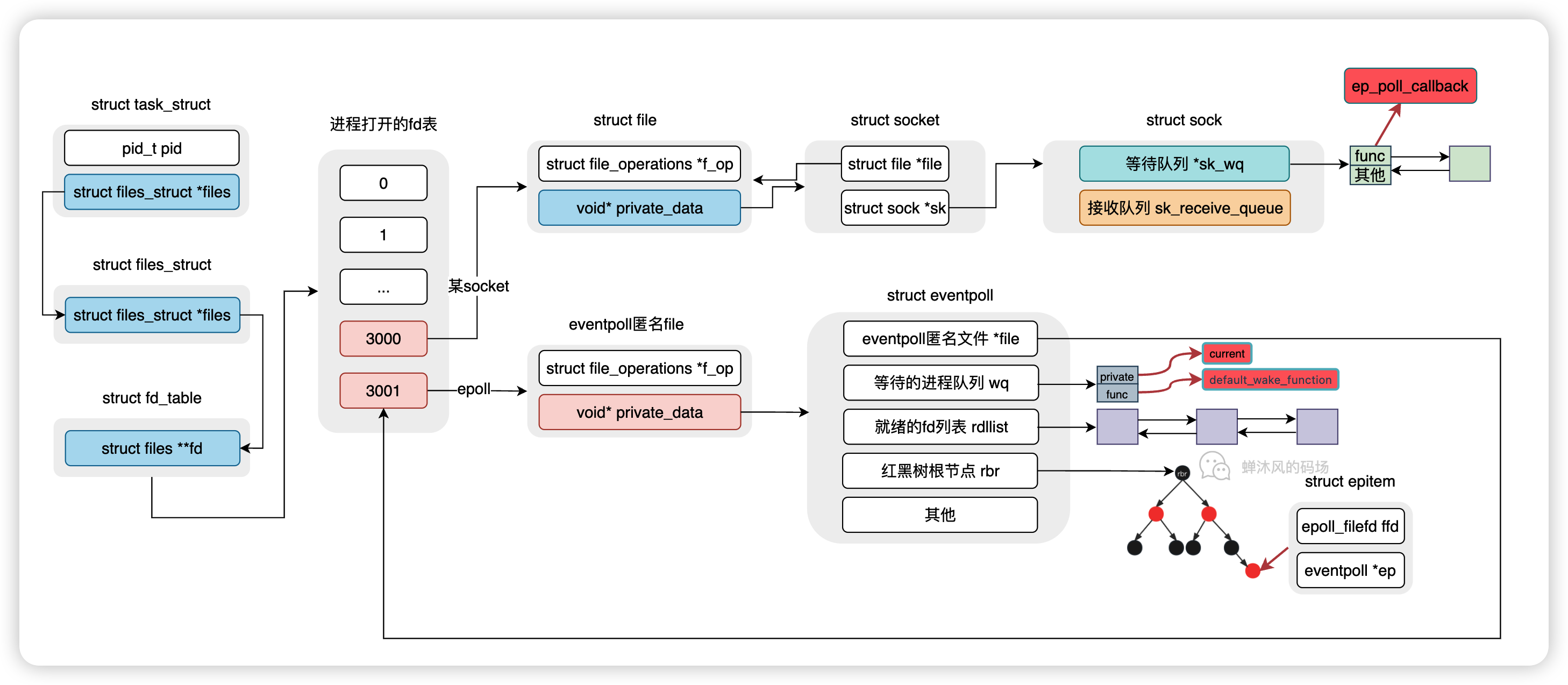
每一步都比较好理解,我们重点来看一下第2步,也就是init_waitqueue_entry函数。
// file: /include/linux/wait.h
static inline void init_waitqueue_entry(wait_queue_t *q, struct task_struct *p)
{
q->flags = 0;
q->private = p;
q->func = default_wake_function;
}
wait_queue_t就是wq等待队列项的结构体类型,将其中的private字段设置成了当前进程的task_struct结构体指针。然后将default_wake_function作为回调函数,赋值给了func字段,至于这个回调函数干嘛用的,还是别急,下文会说的。
于是,这个图又完整了一些。
5.3.5. 来活儿了
收到数据之后,首先干苦力活的是网卡,网卡会将数据放到某块关联的内存当中,这个操作不需要CPU的参与。等到数据保存完了之后,网卡会向CPU发起一个硬中断,通知CPU数据来了。
这个时候CPU就要开始对中断进行处理了,但是CPU太忙了,它必须时时刻刻准备好接收各种设备的中断,比如鼠标、键盘等,而且还不能卡在一个中断上太长时间,要不然可以想像我们的计算机得“卡”成什么样子。
所以实际设计中硬中断只负责做一些简单的事情,然后接着触发软中断,比较耗时且复杂的工作就交给软中断处理程序去做了。
软中断以内核线程的方式运行,每个CPU都会对应一个软中断内核线程,名字叫做ksoftirqd/CPU编号,比如 0 号 CPU 对应的软中断内核线程的名字是 ksoftirqd/0,为了方便,我们直接叫做ksoftirqd好了。
从这个角度上来说,操作系统就是一个死循环,在循环中不断接收各种中断,处理不同逻辑。
内核线程经过各个函数调用,最终会调用到就绪的socket等待队列项中的回调函数ep_poll_callback,是时候看看这个函数了。
// file: /fs/eventpoll.c
static int ep_poll_callback(wait_queue_t *wait, unsigned mode, int sync, void *key)
{
...
// 获取等待队列项对应的epitem
struct epitem *epi = ep_item_from_wait(wait);
// 获取epitem对应的eventpoll实例
struct eventpoll *ep = epi->ep;
...
/* 如果当前epitem指向的socket已经在就绪队列里了,那就直接退出
否则,将epitem添加到eventpoll的就绪队列rdllist中
If this file is already in the ready list we exit soon
*/
if (!ep_is_linked(&epi->rdllink)) {
list_add_tail(&epi->rdllink, &ep->rdllist);
}
// 查看eventpoll等待队列上是否有等待的进程
if (waitqueue_active(&ep->wq))
wake_up_locked(&ep->wq);
...
}
ep_poll_callback的逻辑非常简洁清晰。
先找到就绪socket对应的等待队列项中的epitem,继而找到对应的eventpoll实例,再接口着判断当前的epitem是不是已经在rdllist就绪队列里了,如果在,那就没啥好做的了,函数退出就行了;如果不在,那就把epitem加入到rdllist中。
最后看看eventpoll的等待队列上是不是有阻塞的进程,有的话就调用5.3.4节中设置的default_wake_function回调函数来唤醒这个进程。
epoll中重点介绍的两个回调函数,ep_poll_callback和default_wake_function就串起来了。前者调用了后者,后者唤醒了进程。epoll_wait的最终使命就是将rdllist中的就绪fd返回给用户进程。
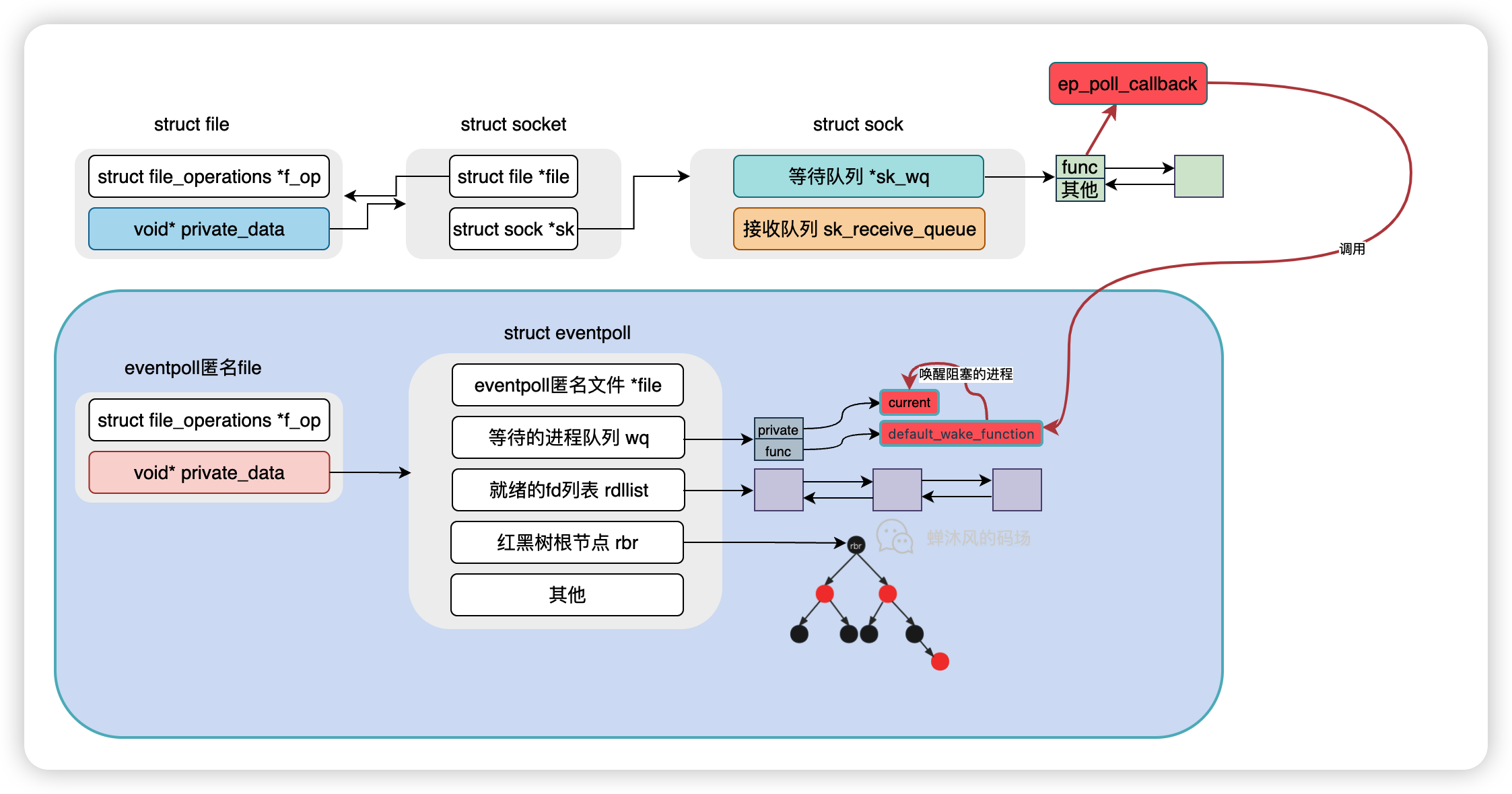
5.4. epoll总结
我们来梳理一下epoll的整个过程。
epoll_create创建了eventpoll实例,并对其中的就绪队列rdllist、等待队列wq以及红黑树rbr进行了初始化;epoll_ctl将我们感兴趣的socket封装成epitem对象加入红黑树,除此之外,还封装了socket的sk_wq等待队列项,里边保存了socket就绪之后的函数回调,也就是ep_poll_callback;epoll_wait检查eventpoll的就绪队列是不是有就绪的socket,有的话直接返回;否则就封装一个eventpoll的等待队列项,里边保存了当前的用户进程信息以及另一个回调函数default_wake_function,然后把当前进程投入睡眠;- 直到数据到达,内核线程找到就绪的socket,先调用
ep_poll_callback,然后ep_poll_callback又调用default_wake_function,最终唤醒eventpoll等待队列中保存的进程,处理rdllist中的就绪fd; - epoll结束!
等下,还没结束!在5.3.2节中还留了一个小坑,我说:eventpoll文件也可以被epoll本身监测,也就是说epoll实例可以监听其他的epoll实例,这一点很重要。
怎么个重要法,这就涉及到eventpoll实例中的另一个队列了,叫做poll_wait。
struct eventpoll {
...
wait_queue_head_t wq;
/* 就是它!!!!!!! */
wait_queue_head_t poll_wait;
struct list_head rdllist;
struct rb_root rbr;
struct file *file;
};
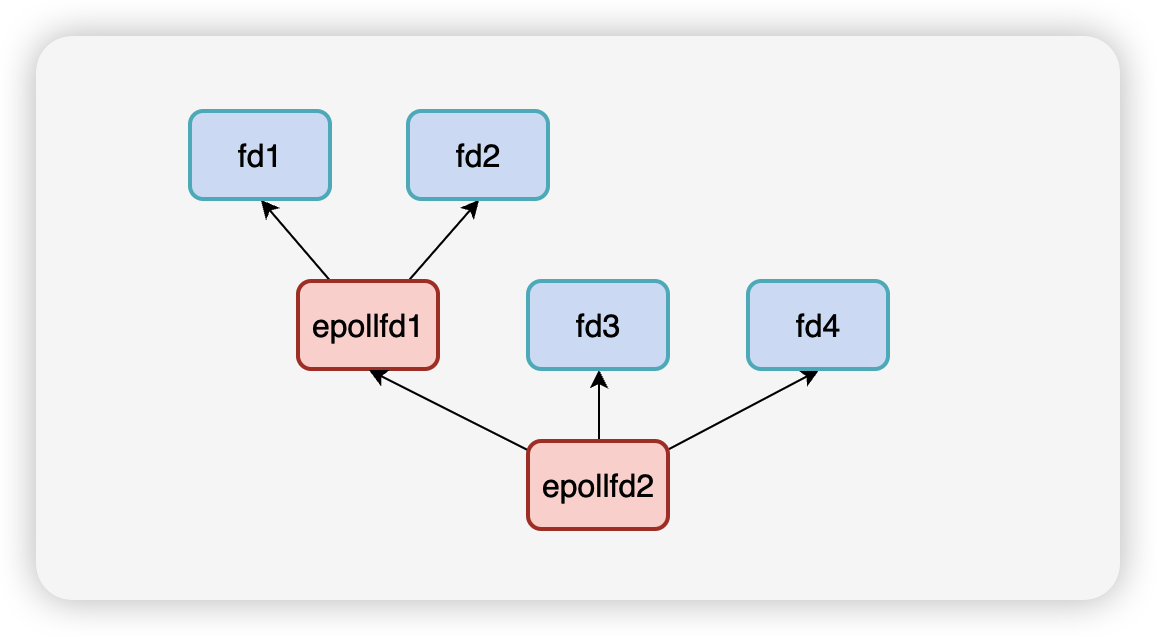
如上图所示
epollfd1监听了2个普通描述符fd1和fd2epollfd2监听了epollfd1和2个普通描述符fd3、fd4
如果fd1或fd2有可读事件触发,那么就绪的fd的回调函数ep_poll_callback对将该fd放到epollfd1的rdllist就绪队列中。由于epollfd1本身也是个文件,它的可读事件此时也被触发,但是ep_poll_callback怎么知道该把epollfd1放到谁的rdllist中呢?
poll_wait来喽~~
当epoll监听epoll类型的文件的时候,会把监听者放入被监听者的poll_wait队列中,上面的例子就是epollfd1的poll_wait队列保存了epollfd2,这样一来,当epollfd1有可读事件触发,就可以在poll_wait中找到epollfd2,调用epollfd1的ep_poll_callback将epollfd1放入epollfd2的rdllist中。
所以poll_wait队列就是用来处理这种递归监听的情况的。
到此为止,多路复用彻底结束~~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号