


事务的隔离级别与MVCC
 提到数据库,你多半会联想到事务,进而还可能想起曾经背得滚瓜乱熟的ACID,不知道你有没有想过这个问题,事务有原子性、隔离性、一致性和持久性四大特性,为什么偏偏给隔离性设置了级别? 一切还得从事务说起。
提到数据库,你多半会联想到事务,进而还可能想起曾经背得滚瓜乱熟的ACID,不知道你有没有想过这个问题,事务有原子性、隔离性、一致性和持久性四大特性,为什么偏偏给隔离性设置了级别? 一切还得从事务说起。
提到数据库,你多半会联想到事务,进而还可能想起曾经背得滚瓜乱熟的ACID,不知道你有没有想过这个问题,事务有原子性、隔离性、一致性和持久性四大特性,为什么偏偏给隔离性设置了级别?

一切还得从事务说起。
1. 事务(transaction)的起源
学习数据库事务的时候,一个典型的案例就是「转账」,这篇文章也不能免俗,故事就从招财向陀螺借100块钱开始吧。
一个看似非常简单的现实世界的状态转换,转换成数据库中的操作却并没有那么单纯。这个看起来很简单的借钱操作至少包含了两个动作:
- 陀螺的账户余额-100
- 招财的账户余额+100
要保证转账操作的成功,数据库必须把这两个操作作为一个逻辑整体来执行,这个逻辑整体就是一个事务。
1.1. 事务的定义
事务就是包含有限个(单条或多条)数据库操作(增删改查)的、最小的逻辑工作单元(不可再分)。
说到这里不得不吐槽一下,事务的英文是transaction,直译为“交易”的意思,但是不知道为什么被意译成了“事务”,让人很难从字面上理解这个概念的含义。
中国人对翻译的“信达雅”的偏执在计算机领域或多或少有点不讨喜。
1.2. 哪些存储引擎支持事务
并不是所有的数据库或者所有的存储引擎都支持事务。
对于MySQL而言,事务作为一种功能特性由存储引擎提供。目前支持事务功能的存储引擎只有InnoDB和NDB,鉴于InnoDB目前是MySQL默认的存储引擎,我们的研究重点自然也就是InnoDB存储引擎了。
因此文章接下来默认的存储引擎就是InnoDB,特殊情况下会特别指出。
那么InnoDB在什么情况下才会出现事务呢?
2. MySQL的事务语法
如果你不是DBA,在平时和MySQL的交互中你可能极少直接使用到它的事务语法,一切都被编程框架封装得很好了。但是现在我们要直接使用MySQL进行事务的研究了,抛开框架,跟我稍微回顾一下语法,这是非常必要的。
2.1. 自动提交
当我运行这样单独一条更新语句的时候,它会有事务吗?
UPDATE user_innodb SET name = '蝉沐风' WHERE id = 1;
实际上,这条语句不仅会自动开启一个事务,而且执行完毕之后还会自动提交事务,并持久化数据。
这是MySQL默认情况下使用的方式——自动提交。在此方式下,增删改的SQL语句会自动开启事务,并且是一条SQL一个事务。
自动提交的方式虽然简单,但是对于转账这种涉及到多条SQL的业务,就不太适合了。因此,MySQL提供了手动开启事务的方法。
2.2. 手动操作事务
2.2.1. 开启事务
可以使用下面两种语句开启一个事务
BEGINSTART TRANSACTION
对比
BEGIN而言,START TRANSACTION后面可以添加一些操作符,不过这不是我们的研究重点,可以不必理会。
2.2.2. 提交或回滚
开启事务之后就可以继续编写需要放到当前事务中的SQL语句了。当写完最后一条语句,如果你觉得写得没问题,你可以提交事务;反之你后悔了,想把数据库恢复到之前的状态,你可以回滚事务。
- 提交事务
COMMIT - 回滚事务
ROLLBACK
2.3. autocommit系统变量
MySQL提供了一个叫做autocommit的系统变量,用来表示是否开启自动提交:
mysql> SHOW VARIABLES LIKE 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
autocommit的默认值为ON,表示默认开启自动提交。但是自动提交和手动操作事务并不冲突,如果不显式使用BEGIN或START TRANSACTION开启一个事务,那么InnoDB会在每一条增删改语句执行之后提交事务。
如果我们把autocommit设为OFF,除非我们手动使用BEGIN或START TRANSACTION开启一个事务,否则InnoDB绝不会自动开启事务;同样,除非我们使用COMMIT或ROLLBACK提交或回滚事务,否则InnoDB不会自动结束事务。
实际上,InnoDB会因为某些特殊语句的执行或客户端连接断开等特殊情况而导致事务自动提交(即使我们没有手动输入
COMMIT),这种情况叫做隐式提交。
3. 事务并发执行导致的读问题
MySQL会使用独立的线程处理每一个客户端的连接,这就是多线程。每个线程都可以开启事务,这就是事务的并发。
不管是多线程的并发执行还是事务的并发执行(其实本质上是一回事儿),如果不采取点措施,都会带来一些问题。
3.1. 脏读
假设事务T1和T2并发执行,都要访问user_innodb表中id为1的数据,不同的是T1先读取数据,紧接着T2修改了数据的name字段,需要注意的是,T2并没有提交!
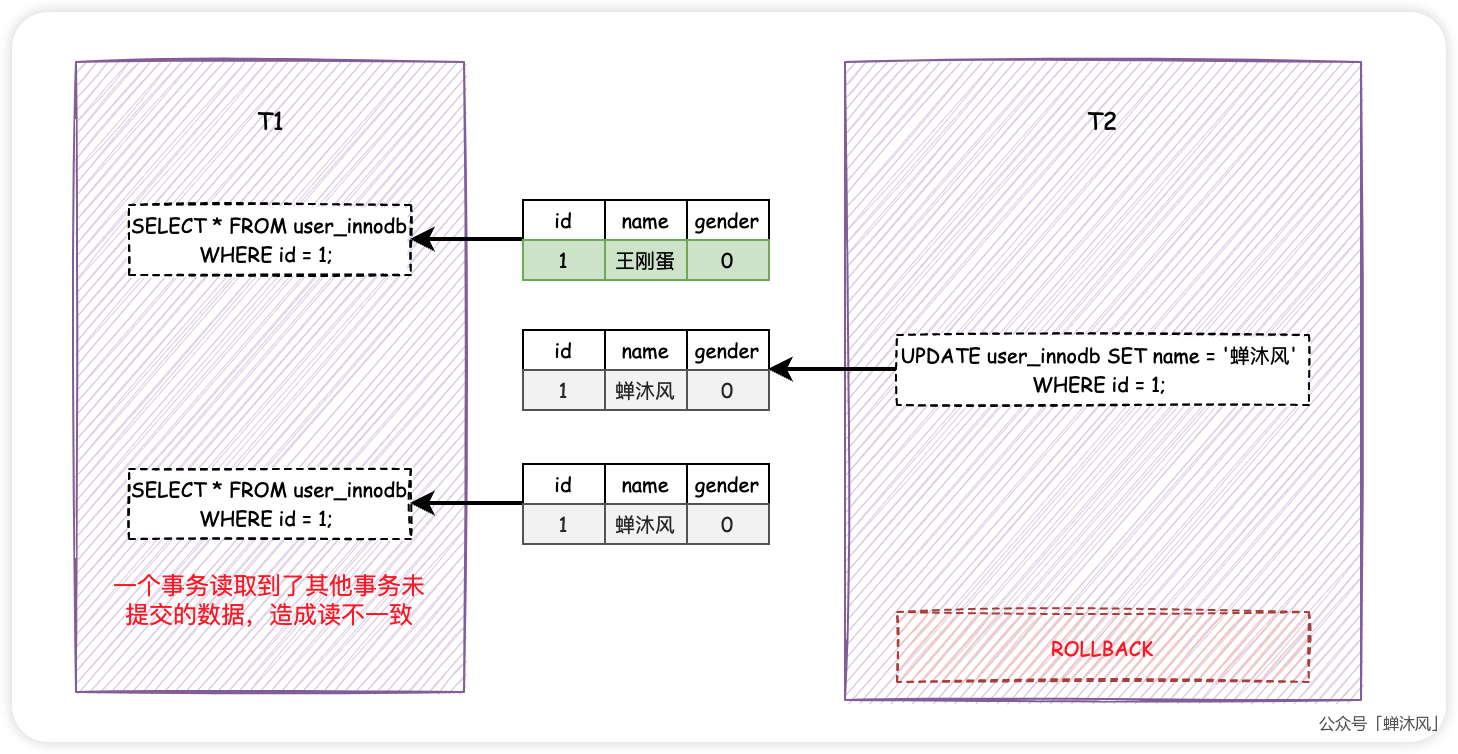
此时,T1再次执行相同的查询操作,会发现数据发生了变化,name字段由「王刚蛋」变成了「蝉沐风」。
如果一个事务读到了另一个未提交事务修改过的数据,而导致了前后两次读取的数据不一致的情况,这种事务并发问题叫做脏读。
3.2. 不可重复读
同样是T1和T2两个事务,T1通过id=1查询到了一条数据,然后T2紧接着UPDATE(DELETE也可以)了该条记录,不同的是,T2紧接着通过COMMIT提交了事务。
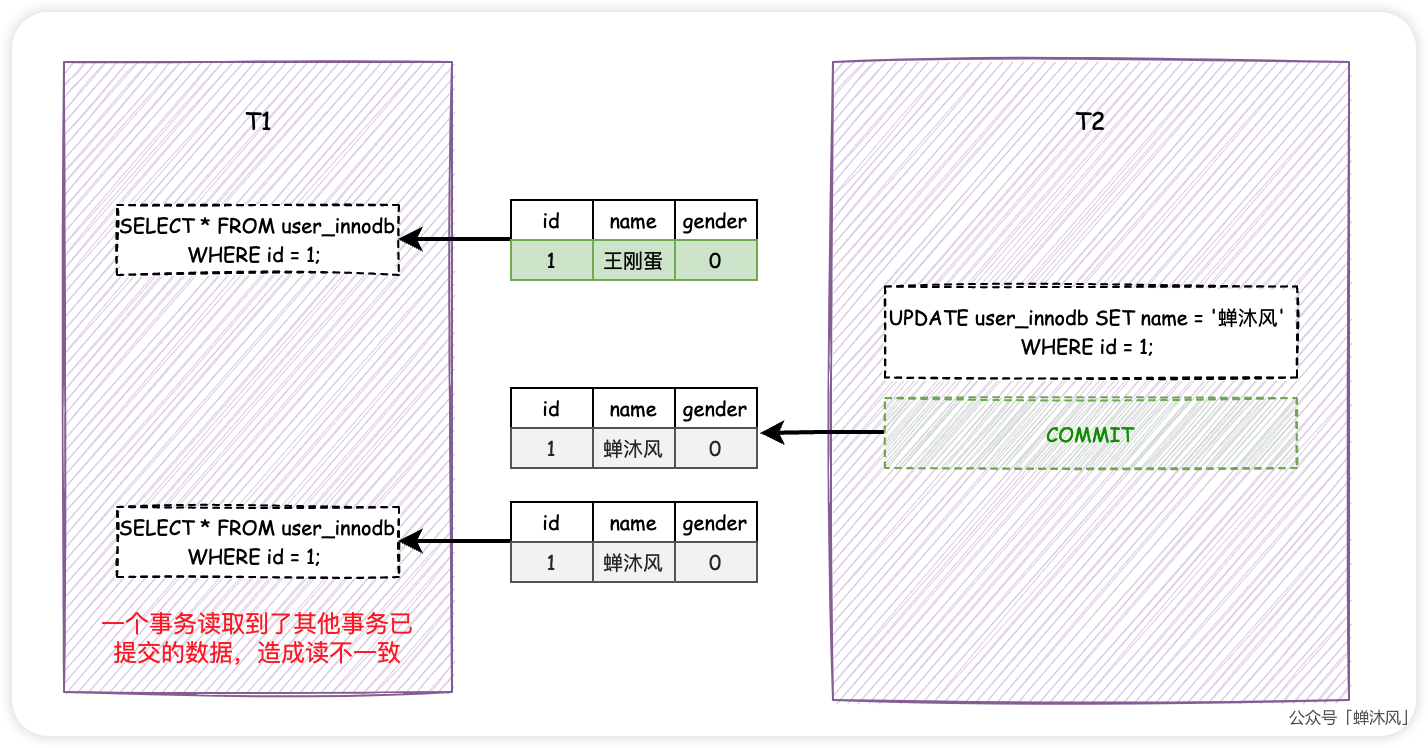
此时,T1再次执行相同的查询操作,会发现数据发生了变化,name字段由「王刚蛋」变成了「蝉沐风」。
如果一个事务读到了另一个已提交事务修改过的(或者是删除的)数据,而导致了前后两次读取的数据不一致的情况,这种事务并发问题叫做不可重复读。
看到这里是不是有点懵了?怎么读到未提交事务修改的数据是并发问题,读到已提交事务修改的数据还是并发问题呢?
这里先不急着回答你,因为还有个幻读呢。
3.3. 幻读
还是T1和T2这俩货,T1先查找了所有name为「王刚蛋」的用户信息,此时发现拥有这个硬汉名字的用户只有一个。然后T2插入了一个同样叫做「王刚蛋」的用户的信息,并且提交了。
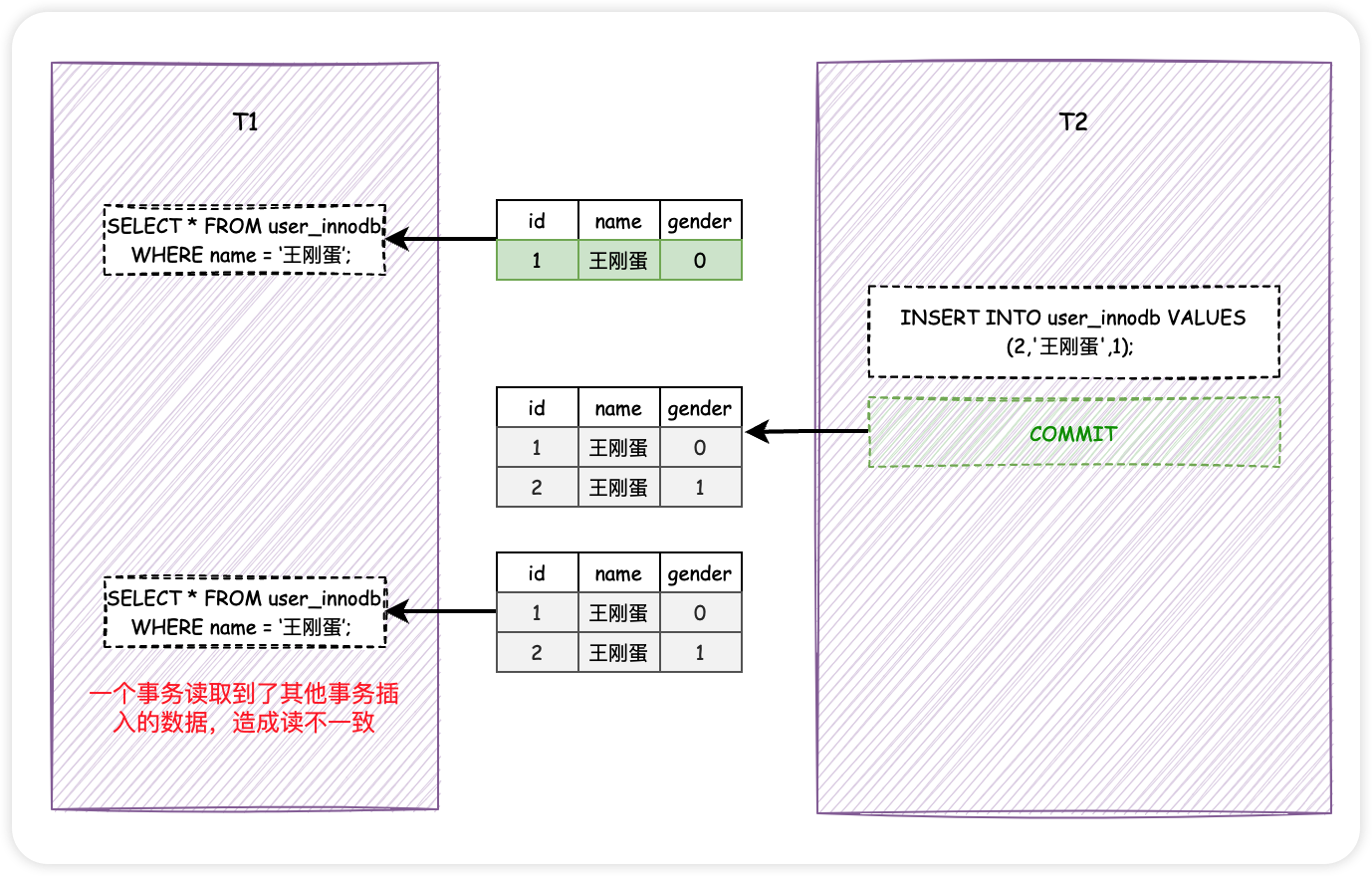
此时,T1再次执行相同的查询操作,发现相比上次的查询结果多了一行数据,不由得怀疑自己是不是出了幻觉。
如果一个事务首先根据某些搜索条件P查询出一些结果,另一个事务写入(可以是INSERT,UPDATE)了一些符合搜索条件P的数据,此时前一个事务再次读取符合条件P的记录时就会获取到之前没有读取过的记录。这个现象叫做幻读。
4. 回答一些可能存在的问题
现在是中场答疑时间。
- 一个事务读到未提交事务修改的数据不行,读到已提交事务修改的数据为什么还不行?
你是不是觉得一个事务读取到其他事务最新提交的数据是一种正常现象?或者说在多数情况下这是我们期望的一种行为?没错,这种现象确实是正常的。不是说不行,而是针对我们讨论的读一致性问题上,这两种现象都算是并发问题,因为谈这个问题的时候我们已经把语境固定死了,就是在同一个事务中的前后两次SELECT的操作结果不该和其他事务产生瓜葛,否则就是出现了读一致性问题。
- 我只听说过事务的一致性,没听说过读一致性
事务在并发执行时一共有下面3种情况:
- 读-读:并发事务相继读取相同记录,由于读取操作本身不会改变记录的值,因此这种情况下自然不会有并发问题;
- 读-写/写-读:一个事务进行读取操作,另一个事务进行写(增删改)操作;
- 写-写:并发事务相继对相同记录进行写(增删改)操作。
不知道你有没有注意到上一节的标题是「事务并发执行导致的读问题」。并且脏读、不可重复读和幻读都是在读-写/写-读的情况下出现的,那写-写情况怎么办?
一切的并发问题都可以通过串行化解决,但是串行化效率太低了!
再优化一下,一切并发问题都可以通过加锁来解决,这种方案我们称为基于锁的并发控制(Lock Bases Concurrency Control, LBCC)!但是在读多写少的环境下,客户端连读取几条记录都需要排队,效率还是太低了!
难不成数据库有避免给读操作加锁就可以解决一致性问题的方法?没错,接下来我们要讲的就是这个方法,所以我们才把一致性问题分为读一致性和写一致性,而写一致性就得依赖数据库的锁机制了。
心急吃不了热豆腐,这篇文章先给你讲明白读一致性问题。
- 不可重复读和幻读的最大区别是什么?
这个问题的答案在网上五花八门,要回答这个问题自然要找官方了。这个官方不是MySQL官方,而是美国国家标准协会(ANSI)。
我们上面谈到的脏读、不可重复读和幻读问题都是理论知识,并不涉及到具体的数据库。考虑到所有数据库在设计的过程中都可能遇到这些问题,ANSI就制定了一个SQL标准,其中最著名的就是SQL92标准,其中定义了「不可重复读」和「幻读」(当然也定义了脏读,但鉴于没啥异议,我就没截图),我把其中的重点单词给大家标注了一下,希望大家能彻底搞懂两者的区别。

我用中文翻译一下就是:
不可重复读:事务T1读取了一条记录,事务T2修改或者删除了同一条记录,并且提交。如果事务T1试图再次读取同一条记录的时候,会读到被事务T2修改的数据或者压根读不到。
幻读:事务T1首先读取了符合某些搜索条件P的一些记录。然后事务T2执行了某些SQL语句产生了符合搜索条件P的一条或多条记录。如果事务T1再次读取符合条件P的记录,将会得到不同于之前的数据集。
SQL标准对于不可重复读已经说得很清楚了,事务T2要对T1读取的记录进行修改或者删除操作,并且必须要提交事务。但是对于幻读的定义就说得很模糊,尤其是文中使用了generate(生成/产生),再结合one or more rows,我们可以认为事务T2执行了INSERT语句插入了之前没有读到的记录,或者是执行了更新记录键值的UPDATE语句生成了符合T1之前的搜索条件的记录,总之只要是事务T1之前没有读到的数据,都算是幻影数据,至于事务T2需不需要提交压根儿没提。
5. SQL标准与4种隔离级别
如果按照对一致性影响的严重程度,对上面提到的3种并发读问题排个序的话,就是下图这样:

我们刚才也提到了,这3种并发读问题都是理论知识,并不涉及到具体的数据库。因此SQL标准再次发挥了作用,他们建议数据库厂家按照他们的规范,提供给用户4种隔离级别,让用户根据自己的业务需要权衡利弊,选择合适的隔离级别,以此解决所有的并发读问题(脏读、不可重复读、幻读)或者对某些无关紧要的并发读问题做出妥协。
SQL标准中定义的隔离级别有如下4种:
READ UNCOMMITTED:未提交读READ COMMITTED:已提交读REPEATABLE READ:可重复读SERIALIZABLE:串行化
SQL标准中规定,针对不同的隔离级别,并发事务执行过程中可以发生不同的并发读问题。
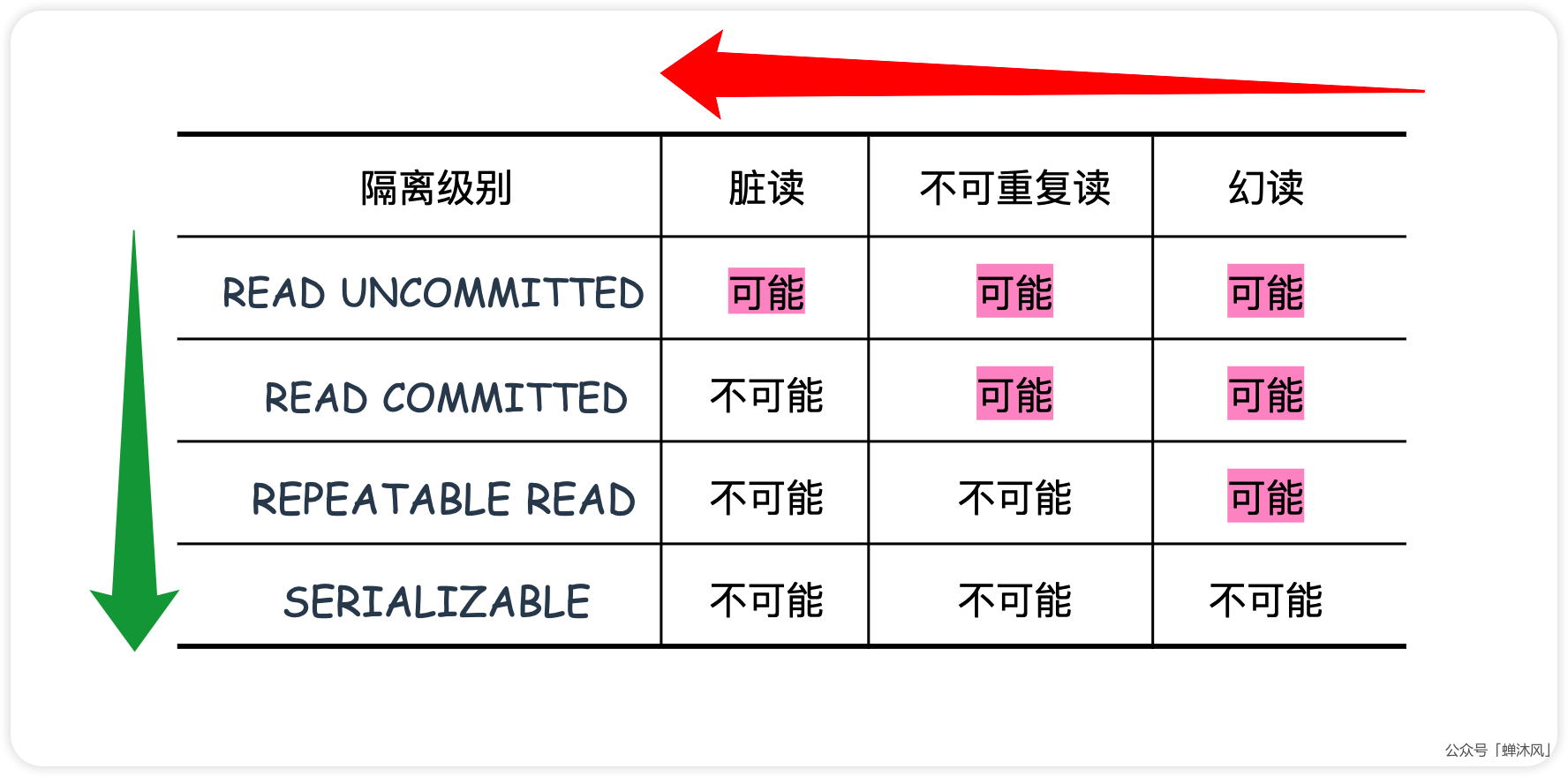
其中绿色箭头表示隔离级别由弱到强,红色箭头表示并发问题的严重程度由弱变强。翻译一下上面的表格就是:
- 在
READ UNCOMMITTED隔离级别下,脏读、不可重复读和幻读都有可能发生。也就是这种隔离级别啥也没干; - 在
READ COMMITTED隔离级别下,不可能发生脏读现象,但是不可重复读和幻读有可能发生; - 在
REPEATABLE READ隔离级别下,可能发生幻读现象,但是绝不可能发生脏读和不可重复读; - 在
SERIALIZABLE隔离级别下,上述所有现象都不可能发生。
说完这些,有些人可能像当时的我一样,依旧是懵的。为什么要设置隔离级别?事务T1读到其他事务最新修改的数据难道不好吗?为什么这些隔离级别的中文翻译这么蹩脚,感觉好不通顺啊。为什么单单给隔离性设置了级别?
5.1. 为什么要设置隔离级别?
说实话,我至今还没遇到过需要我手动修改MySQL隔离级别的业务,而且我也相信,短时间也不会出现这种场景。我相信大部分开发者也是一样。因此,在没有机会实战的情况下,要能记住隔离级别的这个概念,必须从需求出发,来理解为什么需要隔离级别。
我举一个例子,假设你有一个账单系统,每个月底需要对你所有的客户的借贷操作和账户余额进行对账。对此你写了一个定时任务,每个月初1号的00:00:00时刻开始启动对账业务,由于是只对上个月的业务进行对账,所以该时刻之后所有的对该用户账户的写操作都不应该对对账事务的读操作可见。
现在你知道并不是任何情况下都要读取到最新修改的数据了吧。
5.2. 蹩脚的中文翻译
至于中文蹩脚的问题,纯属是我个人揣测的了。因为直到现在我都觉得隔离级别的中文翻译不顺口,因此猜测可能读这篇文章的其中一个你也会和我有同样的问题呢。我的办法就是直接用英文代替中文翻译,纯属个人方法,不好使不要怪我。
5.3. 为什么单单给隔离性设置了级别?
终于聊到了为什么单单给隔离性设置了级别这个问题了。如果想想事务的4个特性,也就自然明白这个问题了。
原子性
简单总结就是一个事务中的语句,要么全部执行成功,要么全部执行失败,不允许存在中间状态。所以对于原子性没有级别可以设置,我们总不能提出至少有80%的SQL语句执行成功这种无理的要求吧。
一致性
一致性是事务的最终目标。简而言之就是数据库的数据操作之后的最终结果符合我们的预期,符合现实世界的规定。比如,陀螺账户里有100块钱,招财分文无有,不管陀螺借给招财多少次,招财分成多少次还,他俩的账户总额必须是100,有借必有贷,借贷必相等,这就是一致性。
呃。。。好像也没找到可以商量商量打个折扣的点。
持久性
这个特性最简单,就是要把事务的所有写操作持久化到磁盘。我们自然也不可能提出至少80%的写操作被持久化到磁盘这样傻兮兮的要求吧。
隔离性
我们唯独可以在这个隔离性上做点手脚。
以新冠疫情为例。疫情紧张的时候,我们最常听到的词就是隔离,虽然都是隔离,却有居家隔离、方舱隔离、酒店单间隔离之分。
再举个例子,你和邻居以墙相隔,这是一种很强的隔离性。但是某一天,你凿壁偷了个光,你们两家依然是有隔离性的,毕竟墙还在那立着呢,但是隔离性显然没有原来那么强了。
说到这儿,不知道你理解了吗?
6. MySQL支持的4种隔离级别
标准归标准,不同的数据库厂商或者存储引擎对标准的实现有一定的差异。比如Oracle数据库只提供了READ COMMITTED和SERIALIZABLE两种隔离级别。
说回MySQL。 InnoDB支持的4个隔离级别和SQL标准定义的完全一致,隔离级别越高,事务的并发程度就越低,但是出现并发问题的概率就越小。
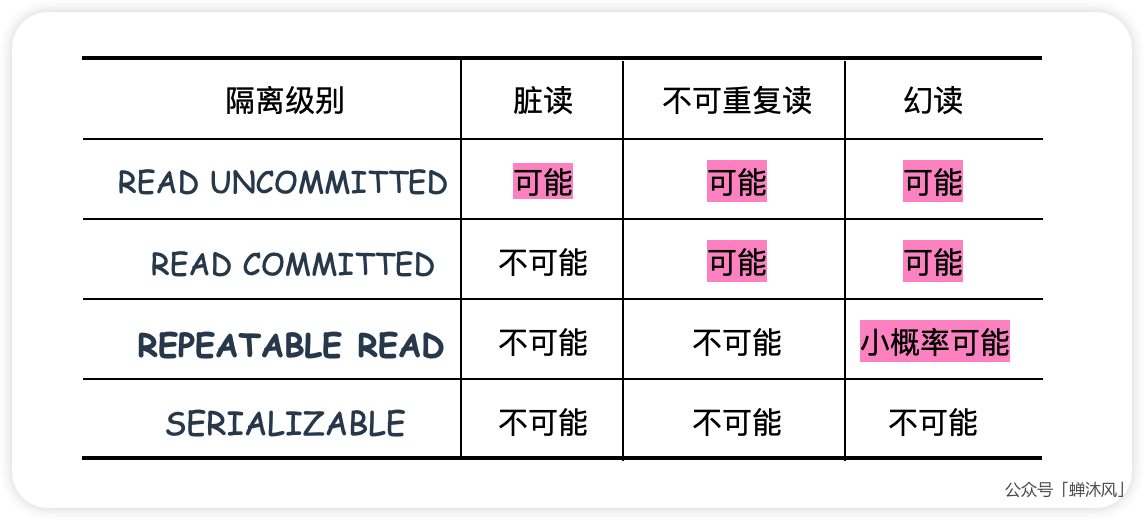
上图中还有非常重要的一点,就是InnoDB在REPEATABLE READ隔离级别下,在很大程度上就解决了幻读的问题,让幻读的发生成为一种小概率事件。在这一点上InnoDB不仅完成了SQL标准,一定程度上也可以说是超越了标准。因此,REPEATABLE READ也成了InnoDB默认的隔离级别。
那什么时候幻读还会发生呢?我举个例子。我用两个终端分别开启两个MySQL会话,每个会话中开启了一个事务,并且保证了每个会话的事务隔离级别都是REPEATABLE READ。
# 事务T1首先开启事务
mysql> BEGIN;
# 事务T1搜索id为1的记录,结果集为空
mysql> SELECT * FROM user_innodb WHERE id = 1;
Empty set (0.01 sec)
# 事务T2插入一条id为1的记录,并且提交事务
# INSERT INTO user_innodb VALUES(1,'wanggangdan',0);
# COMMIT;
# 事务T1在重新搜索之前,修改一下事务T2刚插入的那条记录
mysql> UPDATE user_innodb SET name = 'chanmufeng' WHERE id = 1;
Query OK, 1 row affected (0.03 sec)
# 事务T1再搜索id为1的记录,发现多了一条记录
mysql> SELECT * FROM user_innodb WHERE id = 1;
+----+------------+--------+
| id | name | gender |
+----+------------+--------+
| 1 | chanmufeng | 0 |
+----+------------+--------+
1 row in set (0.00 sec)
要说清楚这个问题就牵扯到MySQL锁的知识了,这个以后再说,知道这么回事儿就行了。
回到我们的主线。我们现在想让事务在自己的一亩三分地儿里随便折腾,其他事务的增删改操作我不想知道(或者我想知道,就放开一下隔离级别)。怎么办?
或许你用过git?
我们用git进行开发任务的时候,通常情况下都会自己创建一个分支,在自己的分支上完成自己的任务,这样和其他开发者不会造成冲突。我们可以借鉴一下这个思路。

git的每个分支都有一个分支id,那事务也该有自己的唯一标识吧,这是自然的,下面稍微回顾一下行格式。
7. 再聊行格式
为什么叫再聊?因为我之前好几篇文章都提到了行格式,你要是早点读到那几篇文章也就不用我再说一遍了。(所以赶紧关注我公众号啊。。。[旺柴])。
但是总有些新朋友嘛。
7.1. 简易版行格式
你存入MySQL的每一条记录都会以某一种MySQL提供的行格式来进行存储,具体有哪些行格式我不打算说明,你也没必要记住,他们之间的最大区别只是对磁盘占用率的优化程度不同罢了。
我们把所有行格式的公有部分拿出来,总之,一条用户数据可以用下面的图来表示
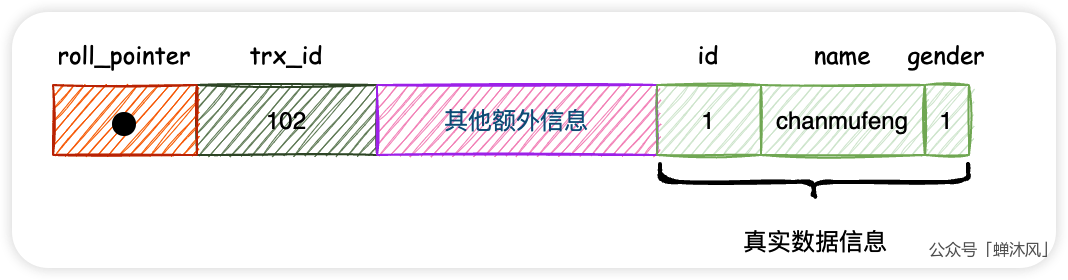
注:图中标识的字段顺序和实际MySQL的字段存储顺序并不一致,这样画是为了能更清晰地说明问题。
roll_pointer:是我们接下来聊的重点,这里先不管它;trx_id:它就是事务id了,每条用户记录都有这个字段。千万不要忘了一个至关重要的前提,我们用的存储引擎是InnoDB;- 其他:就不用多说了吧。
7.2. 分配事务id的时机
对于读写事务而言,只有在它第一次对某个表进行增删改操作时,才会为这个事务分配一个事务id,否则不会分配。
更特殊地,如果一个读写事务中全是查询语句,没有增删改的操作,这个事务也不会被分配事务id。
如果不分配事务id,事务id的值默认为0。
8. MVCC登场
8.1. 版本链
当一个事务T1读到了一条记录,我们当然希望能禁止其他事务对该条记录进行修改和删除的操作,直到T1结束,但是这种满足一己之私的行为在并发领域是要遭到唾骂的。这严重拖系统后腿啊。
于是InnoDB的设计者提出了一种和git类似的想法,每对记录做一次修改操作,都要记录一条修改之前的日志,并且该日志还保存了当前事务的id,和行格式类似,这条日志也有一个roll_pointer节点。
实际InnoDB的这个功能和git没有半毛钱关系,这里单纯为了类比。
当对同一条记录更新的次数多了,所有的这些日志会被roll_pointer属性连接成一个单链表,这个链表就是版本链,而版本链的头节点就是当前记录的最新值。

注:这种日志的格式和普通记录的格式其实并不相同,上图中我们只关注两者之间共同的部分。
上图展示了一条记录的版本链。该条记录的最初始版本是由id为21的事务进行UPDATE得到的(大家可以想一下,这里为什么不可能是INSERT呢?)
后来,这条记录分别被事务280和事务300各自连续UPDATE了两次。这里有个细节,事务280和事务300并没有交叉着更新这条记录,这是为什么呢?也留给亲爱的你思考吧。
InnoDB正是利用这个版本链来控制不同事务访问相同记录的行为,这种机制就是MySQL大名鼎鼎的MVCC(Multi-Version Concurrency Control),多版本并发控制。
而上文中我们一直提及的日志,就是大名鼎鼎的undo日志。
除了标题,在正文中我尽量没有提及
MVCC术语,可把我憋坏了。因为对于没有了解过这个概念的读者而言,这个术语确实有点让人害怕。不过看到这儿的话,是不是觉得也不过如此呢?

接下来就是看一下MySQL的各个隔离级别是怎么利用MVCC的。
8.2. ReadView
READ UNCOMMITTED隔离级别啥也不是,脏读、不可重读和幻读问题一个都解决不了,所以干脆在这个隔离级别下直接读取记录的最新版本就得了。
而SERIALIZALE隔离级别又矫枉过正,必须得用锁机制才能实现,所以就先按下不表了。
对于使用READ COMMITTED和REPEATABLE READ隔离级别的事务而言,决不允许发生脏读现象(忘记了的话再回去看看表格),也就是说如果事务T2已经修改了记录但是没有提交,那T1就不能直接读取T2修改之后的内容。
现在的核心问题就是,怎么判断版本链中的哪个版本是当前事务可见的。
为此,InnoDB的设计者提出了ReadView的概念,其中包含了4个比较重要的内容:
m_ids:生成ReadView时,当前系统中活跃的读写事务id列表;min_trx_id:生成ReadView时,当前系统中活跃的读写事务中最小的事务id,也就是m_ids中的最小值;max_trx_id:生成ReadView时,待分配给下一个事务的id号;creator_trx_id:生成当前ReadView的事务的事务id。
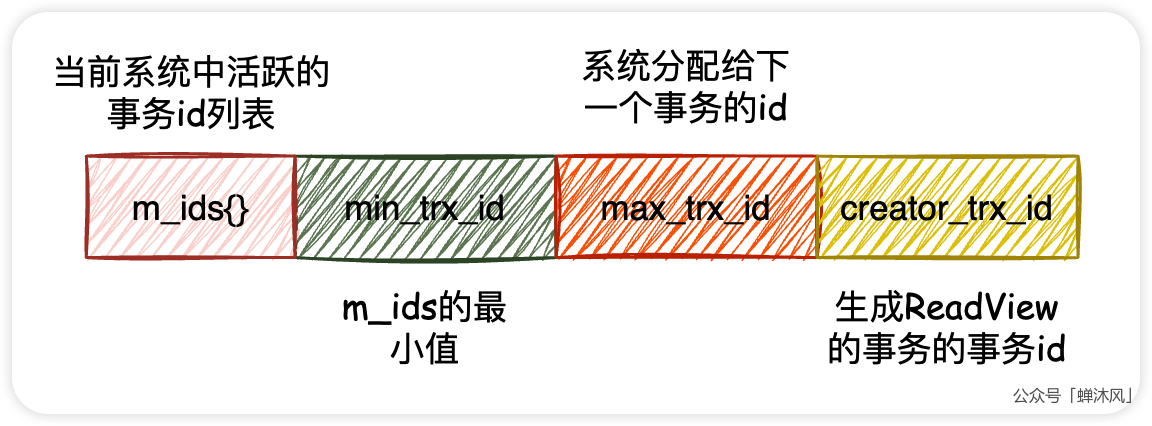
有了ReadView这个数据结构,事务判断可见性的规则就是这样的:
- 从版本链中的最新版本开始判断
- 如果被访问版本的
trx_id = creator_trx_id,说明这个版本就是当前事务修改的,允许访问; - 如果被访问版本的
trx_id < min_trx_id(未提交事务的最小id),说明生成这个版本的事务在当前ReadView生成之前就已经提交了,允许访问; - 如果被访问版本的
trx_id > max_trx_id(待分配的事务id),说明生成这个版本的事务是在当前ReadView生成之后建立的,不允许访问; - 如果被访问版本的
trx_id在min_trx_id和max_trx_id之间,那就需要判断trx_id是否在m_ids之中,如果在,说明生成当前ReadView时,生成该版本的事务还是活跃的,因此不允许访问。否则,可以访问; - 如果当前版本不可见,就沿着版本链找到下一个版本,重复上面的1~4步。
READ COMMITTED和REPEATABLE READ隔离级别之间的不同之处就是生成ReadView的时机不同。接下来具体看一下它们之间的区别。
8.2.1. READ COMMITTED
READ COMMITTED是每次读取数据之前都生成一个ReadView。
我们来做个实验,实验之前先看一下我们的目标记录现在的值:
mysql> SELECT * FROM user_innodb WHERE id = 1;
+----+-------------+--------+
| id | name | gender |
+----+-------------+--------+
| 1 | wanggangdan | 1 |
+----+-------------+--------+
假设系统中有两个事务id分别为100,200的事务T1、T2在执行:
# 事务T1(100)开始执行
mysql> BEGIN;
mysql> UPDATE user_innodb SET name = 'chanmufeng' WHERE id = 1;
mysql> UPDATE user_innodb SET name = 'zhaosi' WHERE id = 1;
# 注意,事务T1(100)并没有提交
# 事务T2(200)开始执行
mysql> BEGIN;
# 做了其他表的一些增删改操作
# 注意,事务T2(200)并没有提交
此时,表user_innodb中id为1的记录的版本链的形式如下图所示:

接下来我们在新的会话中将隔离级别设置为READ COMMITTED,并开始事务T3
# 在新的会话中设置SESSION级别的隔离级别,这种设置方式对当前会话的后续所有事务生效
mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
# 查看当前会话默认的隔离级别,发现是READ-COMMITTED,说明设置成功
mysql> SHOW VARIABLES LIKE 'transaction_isolation';
+-----------------------+----------------+
| Variable_name | Value |
+-----------------------+----------------+
| transaction_isolation | READ-COMMITTED |
+-----------------------+----------------+
# T3开启事务
mysql> BEGIN;
# T3查询id为1的记录信息,发现是最原始的、事务T1修改之前的版本
mysql> SELECT * FROM user_innodb WHERE id = 1;
+----+-------------+--------+
| id | name | gender |
+----+-------------+--------+
| 1 | wanggangdan | 1 |
+----+-------------+--------+
我们对照着上文说过的可见性判断规则,来捋一遍整个流程:
T3执行SELECT时会首先生成一个ReadView数据结构,这个ReadView的信息如下m_ids列表的内容是[100,200]min_trx_id为100max_trx_id为201(这里我们假设待分配给下一个事务就是201)creator_trx_id为0(因为事务T3只是SELECT而已,没有做增删改操作,所以事务id为0)
- 从版本链中的最新版本开始判断;
- 最新版本的
trx_id是100,在min_trx_id和max_trx_id之间,继续判断trx_id是否在m_ids之中,发现在,说明生成当前ReadView时,生成该版本的事务还是活跃的,因此不允许访问,根据链表找到下一个版本; - 当前版本的
trx_id是100,不允许访问,理由同上,继续跳到下一个版本; - 当前版本的
trx_id是99,小于min_trx_id值100,所以当前版本对T3可见,返回的数据就是name为'wanggangdan'的这条记录。
接着,实验继续,我们把T1提交一下:
# 事务T1提交
mysql> COMMIT;
然后在事务T2中(目前还没有提交)再次更新id为1的记录
# 事务T2继续执行id为1的记录的更新操作,但是依然不提交
mysql> UPDATE user_innodb SET name = 'wangwu' WHERE id = 1;
mysql> UPDATE user_innodb SET name = 'wanger' WHERE id = 1;
现在,版本链就变成了这个样子:
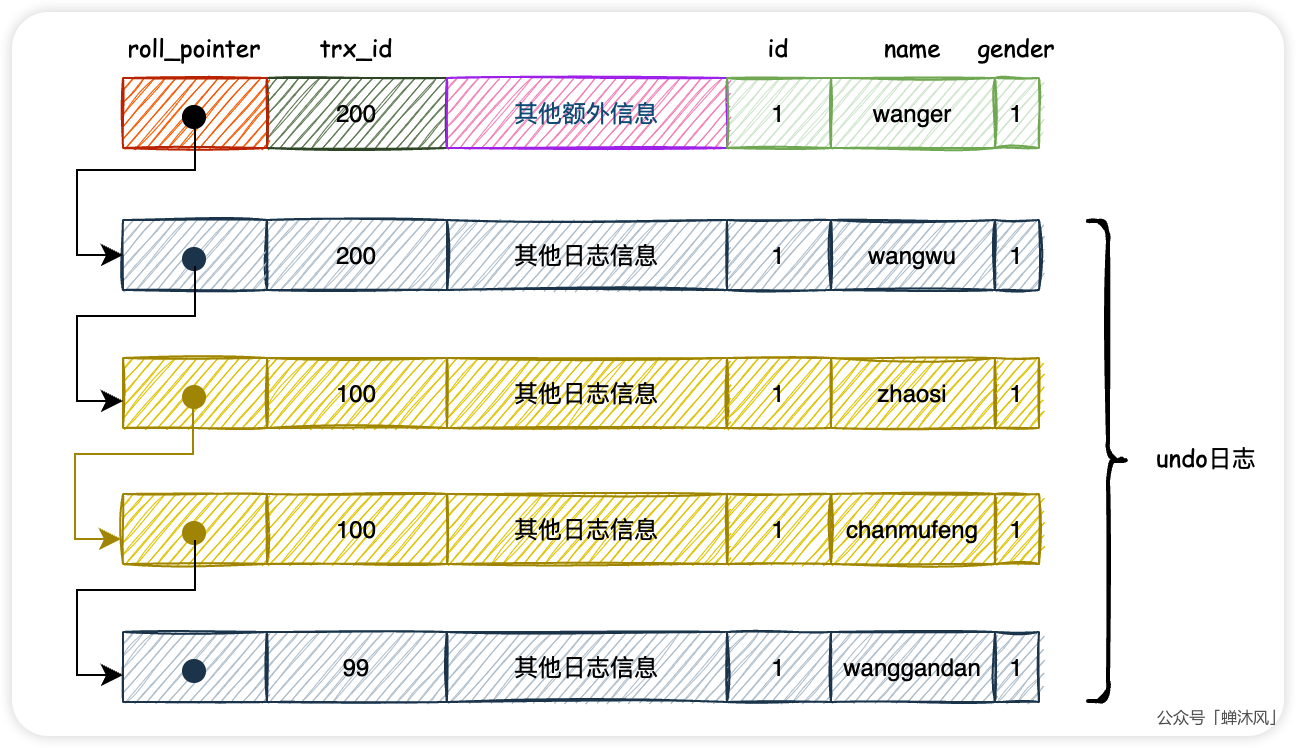
最后在事务T3中重新执行查询,再来看一下结果集会是什么:
# 事务T3再次执行查询
mysql> SELECT * FROM user_innodb WHERE id = 1;
+----+--------+--------+
| id | name | gender |
+----+--------+--------+
| 1 | zhaosi | 1 |
+----+--------+--------+
我们来捋一下这次的查询的执行过程:
-
因为
T3的隔离级别是READ COMMITTED,所以再次执行查询会重新生成一个ReadView,此时这个ReadView里边的信息如下:m_ids列表的内容是[200],因为T1已经提交了min_trx_id为200max_trx_id为201(这里我们假设待分配给下一个事务就是201)creator_trx_id为0(因为事务T3只是SELECT而已,没有做增删改操作,所以事务id为0)
-
从版本链中的最新版本开始判断;
-
最新版本的
trx_id是200,在min_trx_id和max_trx_id之间,继续判断trx_id是否在m_ids之中,发现在,说明生成当前ReadView时,生成该版本的事务还是活跃的,因此不允许访问,根据链表找到下一个版本; -
当前版本的
trx_id是200,不允许访问,理由同上,继续跳到下一个版本; -
当前版本的
trx_id是100,小于min_trx_id值200,所以当前版本对T3可见,返回的数据就是name为'zhaosi'的这条记录。
重点就是:READ COMMITTED在每次SELECT的时候都重新生成一个ReadView。
注意,在做实验的时候如果长时间未操作终端,可能导致和MySQL服务器的连接自动断开,连接一旦断开,事务会自动进行提交。做实验的小伙伴需要注意一下。
8.2.2. REPEATABLE READ
学会了READ COMMITTED,REPEATABLE READ也是同样的道理了,唯一的区别是:
REPEATABLE READ只会在第一次执行SELECT的时候生成一个ReadView,之后不管SELECT多少次,都是用最开始生成的ReadView中的变量进行判断。
还是拿上面的事务id为100和200的事务为例,在实验之前,先将数据重置到最初的状态。
mysql> UPDATE user_innodb SET name = 'wanggangdan' WHERE id = 1;
事务T1先执行:
# 事务T1(100)开始执行
mysql> BEGIN;
mysql> UPDATE user_innodb SET name = 'chanmufeng' WHERE id = 1;
mysql> UPDATE user_innodb SET name = 'zhaosi' WHERE id = 1;
# 注意,事务T1(100)并没有提交
# 事务T2(200)开始执行
mysql> BEGIN;
# 做了其他表的一些增删改操作
# 注意,事务T2(200)并没有提交
此时,表user_innodb中id为1的记录的版本链的形式如下图所示:
接下来我们在新的会话中将隔离级别设置为REPEATABLE READ,并开始事务T3
# 在新的会话中设置SESSION级别的隔离级别,这种设置方式对当前会话的后续所有事务生效
mysql> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
# 查看当前会话默认的隔离级别,发现是READ-COMMITTED,说明设置成功
mysql> SHOW VARIABLES LIKE 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
# T3开启事务
mysql> BEGIN;
# T3查询id为1的记录信息,发现是最原始的、事务T1修改之前的版本
mysql> SELECT * FROM user_innodb WHERE id = 1;
+----+-------------+--------+
| id | name | gender |
+----+-------------+--------+
| 1 | wanggangdan | 1 |
+----+-------------+--------+
现在捋这个流程你应该已经熟悉很多了:
T3初次执行SELECT时会生成一个ReadView数据结构,这个ReadView的信息如下m_ids列表的内容是[100,200]min_trx_id为100max_trx_id为201(这里我们假设待分配给下一个事务就是201)creator_trx_id为0(因为事务T3只是SELECT而已,没有做增删改操作,所以事务id为0)
- 从版本链中的最新版本开始判断;
- 最新版本的
trx_id是100,在min_trx_id和max_trx_id之间,继续判断trx_id是否在m_ids之中,发现在,说明生成当前ReadView时,生成该版本的事务还是活跃的,因此不允许访问,根据链表找到下一个版本; - 当前版本的
trx_id是100,不允许访问,理由同上,继续跳到下一个版本; - 当前版本的
trx_id是99,小于min_trx_id值100,所以当前版本对T3可见,返回的数据就是name为'wanggangdan'的这条记录。
接着,实验继续,我们把T1提交一下:
# 事务T1提交
mysql> COMMIT;
然后在事务T2中(目前还没有提交)再次更新id为1的记录
# 事务T2继续执行id为1的记录的更新操作,但是依然不提交
mysql> UPDATE user_innodb SET name = 'wangwu' WHERE id = 1;
mysql> UPDATE user_innodb SET name = 'wanger' WHERE id = 1;
现在,版本链就变成了这个样子:
最后在事务T3中重新执行查询,再来看一下结果集会是什么:
# 事务T3再次执行查询
mysql> SELECT * FROM user_innodb WHERE id = 1;
+----+-------------+--------+
| id | name | gender |
+----+-------------+--------+
| 1 | wanggangdan | 1 |
+----+-------------+--------+
我们来捋一下这次的查询的执行过程:
-
因为
T3的隔离级别是REPEATABLE READ,所以还是沿用一开始生成的那个ReadView,再抄一遍:m_ids列表的内容是[100,200]min_trx_id为100max_trx_id为201creator_trx_id为0
-
从版本链中的最新版本开始判断;
-
最新版本的
trx_id是200,在min_trx_id和max_trx_id之间,继续判断trx_id是否在m_ids之中,发现在,说明生成当前ReadView时,生成该版本的事务还是活跃的,因此不允许访问,根据链表找到下一个版本; -
当前版本的
trx_id是200,不允许访问,理由同上,继续跳到下一个版本; -
当前版本的
trx_id是100,在min_trx_id和max_trx_id之间,继续判断trx_id是否在m_ids之中,发现在,说明生成当前ReadView时,生成该版本的事务还是活跃的,因此不允许访问,根据链表找到下一个版本; -
当前版本的
trx_id是100,不允许访问,理由同上,继续跳到下一个版本; -
当前版本的
trx_id是99,小于min_trx_id值100,所以当前版本对T3可见,返回的数据就是name为'wanggangdan'的这条记录。
也就是说,READ COMMITTED隔离级别下,T3前后两次SELECT得到的结果完全一致,跟其他事务提交不提交没有关系,即使事务T2后来也提交了,也不影响T3的搜索结果。怎么样,是不是一致性的程度比READ COMMITTED更强了呢?
好了,到目前为止你已经知道怎么利用MVCC来解决一致性读问题了,但是写一致性该怎么办呢?那就是下一篇事务的隔离级别与锁的内容了。敬请关注喽。

