

图解|12张图告诉你MySQL的主键查询为什么这么快
 什么是InnoDB行格式?InnoDB页是什么? InnoDB页和InnoDB行格式都有哪些字段信息? 为什么推荐使用自增ID作为主键,而不推荐使用UUID? InnoDB设计者如何设计高效算法,快速在一个页中搜索记录。
什么是InnoDB行格式?InnoDB页是什么? InnoDB页和InnoDB行格式都有哪些字段信息? 为什么推荐使用自增ID作为主键,而不推荐使用UUID? InnoDB设计者如何设计高效算法,快速在一个页中搜索记录。
这是图解MySQL的第3篇文章,这篇文章会让大家清楚地明白:
- 什么是InnoDB行格式?InnoDB页是什么?
- InnoDB页和InnoDB行格式都有哪些字段信息?
- 为什么推荐使用自增ID作为主键,而不推荐使用UUID?
- InnoDB设计者如何设计高效算法,快速在一个页中搜索记录。
正文开始!
注:我们接下来的所有描述,针对的都是InnoDB存储引擎,如果涉及到其他存储引擎,将会特殊说明
1. 初探InnoDB行格式(ROW_FORMAT)
我们平时都是以记录为单位向MySQL的表中插入数据的,这些记录在磁盘中的存放的格式就是InnoDB的行格式。
为了证明我不是瞎说,举个例子,我查询一下本地数据库以forward开头的数据表的行格式

我们平时很少操作行格式,所以对这个概念可能不是很清楚。其实InnoDB存储引擎为我们提供了4种不同的行格式
-
DYNAMIC(默认的行格式) -
COMPACT -
REDUNDANT -
COMPRESSED
我们可以在创建表时指定行格式(如果不指定,默认行格式为DYNAMIC),比如我指定row_format_table表的行格式为COMPACT
mysql> CREATE TABLE row_format_table(
-> id INT,
-> c1 VARCHAR(10),
-> c2 CHAR(10),
-> PRIMARY KEY(id)
-> ) CHARSET=utf8 ROW_FORMAT=COMPACT;
语法了解到这一步就可以了,接下来我们看一下4种行格式的具体表现形式,画个图就是

从图中可以看出,一条完整的记录可以分为「记录的额外信息」和「真实数据信息」两部分,4种行格式的不同也主要体现在「真实数据信息」这一部分。也就是说,不同的行格式采用了不同的数据格式来存储我们的真实数据,至于有什么具体的不同,对我们这篇文章并不重要,不需要关注。
next_record表示下一条记录的相对位置,有了这个字段,记录之间可以串联成一个单链表,这个比较好理解,看看图吧。至于其他的字段信息,我们用到的时候再介绍就好了。

注意:图中所列字段的排列顺序(包括下文即将提及的)并非是InnoDB行格式在存储设备上的真实存储顺序,为了方便说明接下来的故事,此处我做了简化,大家理解思想即可
2. 引入InnoDB页
对于MySQL的任何存储引擎而言,数据都是存储在磁盘中的,存储引擎要操作数据,必须先把磁盘中的数据加载到内存中才可以。
那么问题来了,一次性从磁盘中加载多少数据到内存中合适呢?当获取记录时,InnoDB存储引擎需要一条条地把记录从磁盘中读取出来吗?
当然不行!我们知道磁盘的读写速度和内存读写速度差了几个数量级,如果我们需要读取的数据恰好运行在磁盘的不同位置,那就意味着会产生多次I/O操作。
因此,无论是操作系统也好,MySQL存储引擎也罢,都有一个预读取的概念。概念的依据便是统治计算机界的局部性原理。
空间局部性:如果当前数据是正在被使用的,那么与该数据空间地址临近的其他数据在未来有更大的可能性被使用到,因此可以优先加载到寄存器或主存中提高效率
就是当磁盘上的一块数据被读取的时候,我们干脆多读一点,而不是用多少读多少。
InnoDB存储引擎将数据划分为若干个页,以页作为磁盘和内存之间交互的最小单位。InnoDB中页的大小默认为16KB。也就是默认情况下,一次最少从磁盘中读取16KB的数据到内存中,一次最少把内存中16KB的内容刷新到磁盘上。
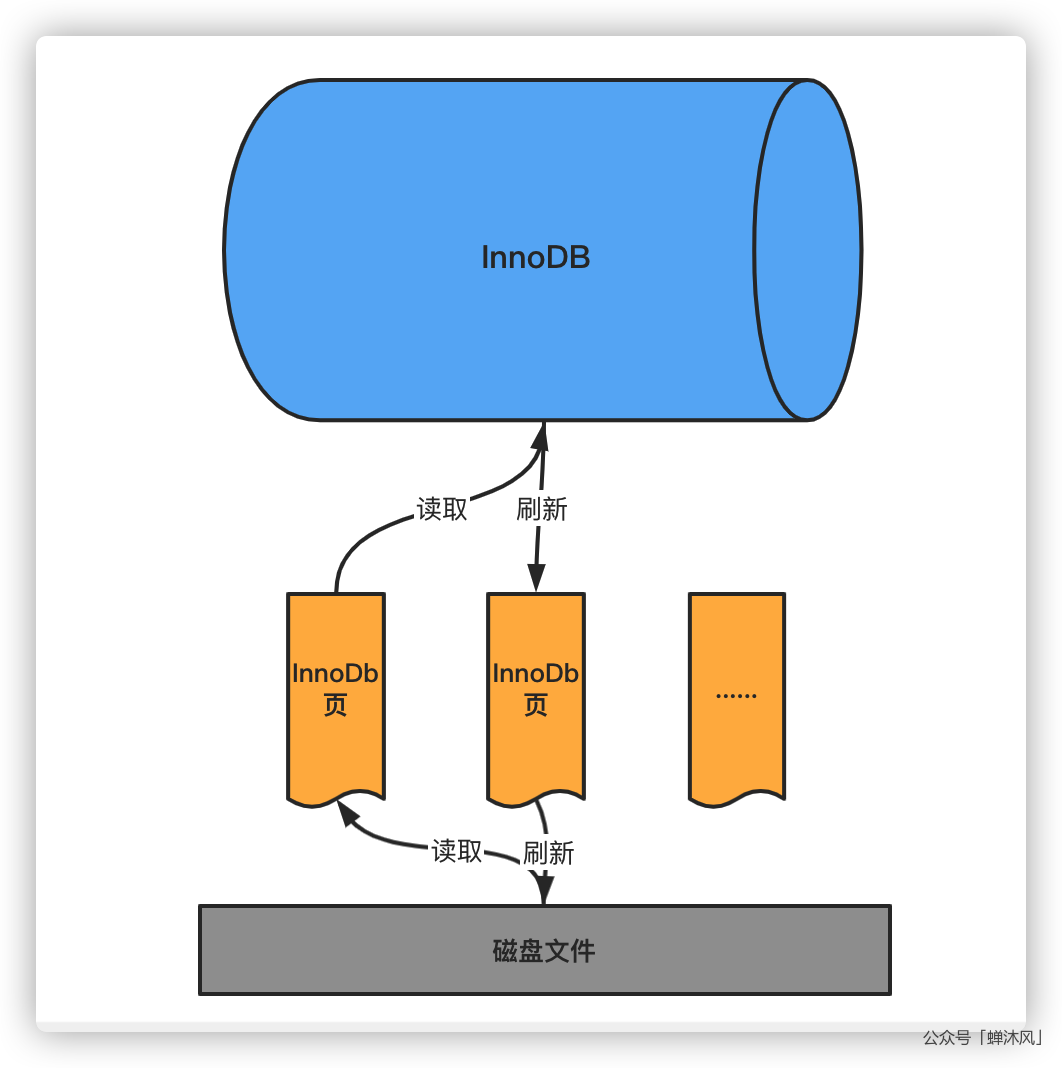
对于InnoDB存储引擎而言,所有的数据(存储用户数据的索引、各种元数据、系统数据)都是以页的形式进行存储的。
InnoDB页的种类很多,比如存放Insert Buffer信息的页,存放undo日志信息的页等,不过我们今天不关注其他乱七八糟的页。这篇文章的主角是存放我们表中记录的页,姑且称之为数据页吧。
3. 数据页的结构
很显然,数据页也会有自己的格式表示,像行格式一样,我先列出两个我们用到的字段,其他的用到再说吧。
3.1 用户记录是如何存放的

我们实际存储的数据表记录会按照指定的行格式存储到图中的User Records部分,如果当前的数据页是新生成的,还没有任何记录的话,User Records部分其实并不会存在,而是从Free Space部分申请一块空间划分到User Records部分,当Free Space空间全部用完(或者剩余的空间已经不足以承载新数据)的时候,意味着当前数据页的空间被占满了,如果继续插入记录,就需要申请新的数据页了,示意图如下:
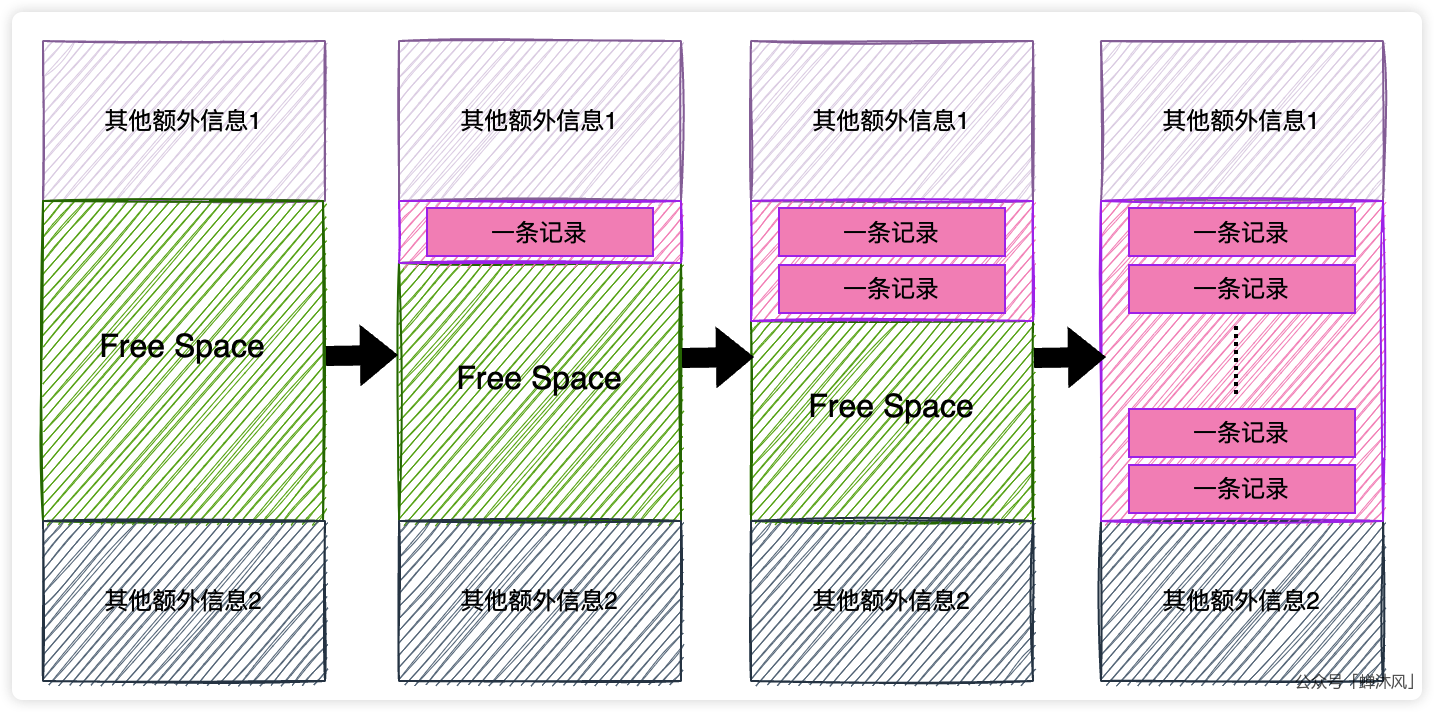
要注意的是,上图中的各条记录之间通过next_record字段串联成了一个单链表,只不过我没有在图中画出来罢了。
但是,只是串联起来就可以了吗?
如果让我们来设计串联的规则的话,我们肯定希望能够按照某种“大小关系”来确定串联的顺序,而不是单纯按照插入数据的顺序,毕竟我们是学过数据结构的人啊!
可是记录之间能比较大小吗?能啊,这篇文章的题目就是关于主键啊,我们可以按照主键的顺序,从小到大来串联当前数据页中的所有记录。事实上,MySQL的设计者也确实是这么设计的。
如果你足够叛逆,你可能会想,你不设置主键的话是不是MySQL就崩了啊?

当我们没有设置主键的时候,为了防止这种情况,InnoDB会优先选取一个Unique键作为主键,如果表中连Unique键也没有的话,就会自动为每一条记录添加一个叫做DB_ROW_ID的列作为默认主键,只不过这个主键我们看不到罢了。
下面我们补充一下行格式

再次强调
- 我画的字段的顺序并非在存储设备中实际存储的顺序
- 只有在InnoDB实在无法确定主键的情况下(创建时不指定主键,同时没有
Unique键),才会添加DB_ROW_ID列
3.2 番外:为什么推荐使用自增ID作为主键,而不推荐使用UUID?
说到这,顺便谈一谈为什么推荐使用自增ID作为主键,而不推荐使用UUID?
除了UUID主键索引占据大量空间的问题之外,在插入数据的资源开销上,自增ID也远小于UUID。由于数据页中的记录是按照主键从小到大进行串联的,自增ID决定了后来插入的记录一定会排列在上一条记录的后面,只需要简单添加next_record指针就可以了;如果当前数据页写满,那就放心地直接插入新的数据页中就可以了。
而UUID不同,它的大小顺序是不确定的,后来插入的记录有可能(而且概率相当大)插入到上一条记录之前(甚至是当前数据页之前),这就意味着需要遍历当前数据页的记录(或者先找到相关的数据页),然后找到自己的位置进行插入;如果当前数据页写满了,只能先找到适合自己位置的数据页,然后在数据页中遍历记录找到自己的合适位置进行插入。
因此使用UUID的方式插入记录花费的时间更长。
3.3 数据页自带的两条伪记录
实际上,InnoDB的设计者在InnoDB页中添加了两条伪记录,一条Infimum,一条Supremum。并且设计者规定,当前数据页的任何用户记录都比Infimum大,任何用户记录都比Supremum小。
因为是伪记录,所以需要和User Records中的内容区分开,所以把这两条伪记录放在了一个叫做Infimum+Supremum的部分,见下图:

最终在数据页中,用户记录的保存形式就成了这个样子:
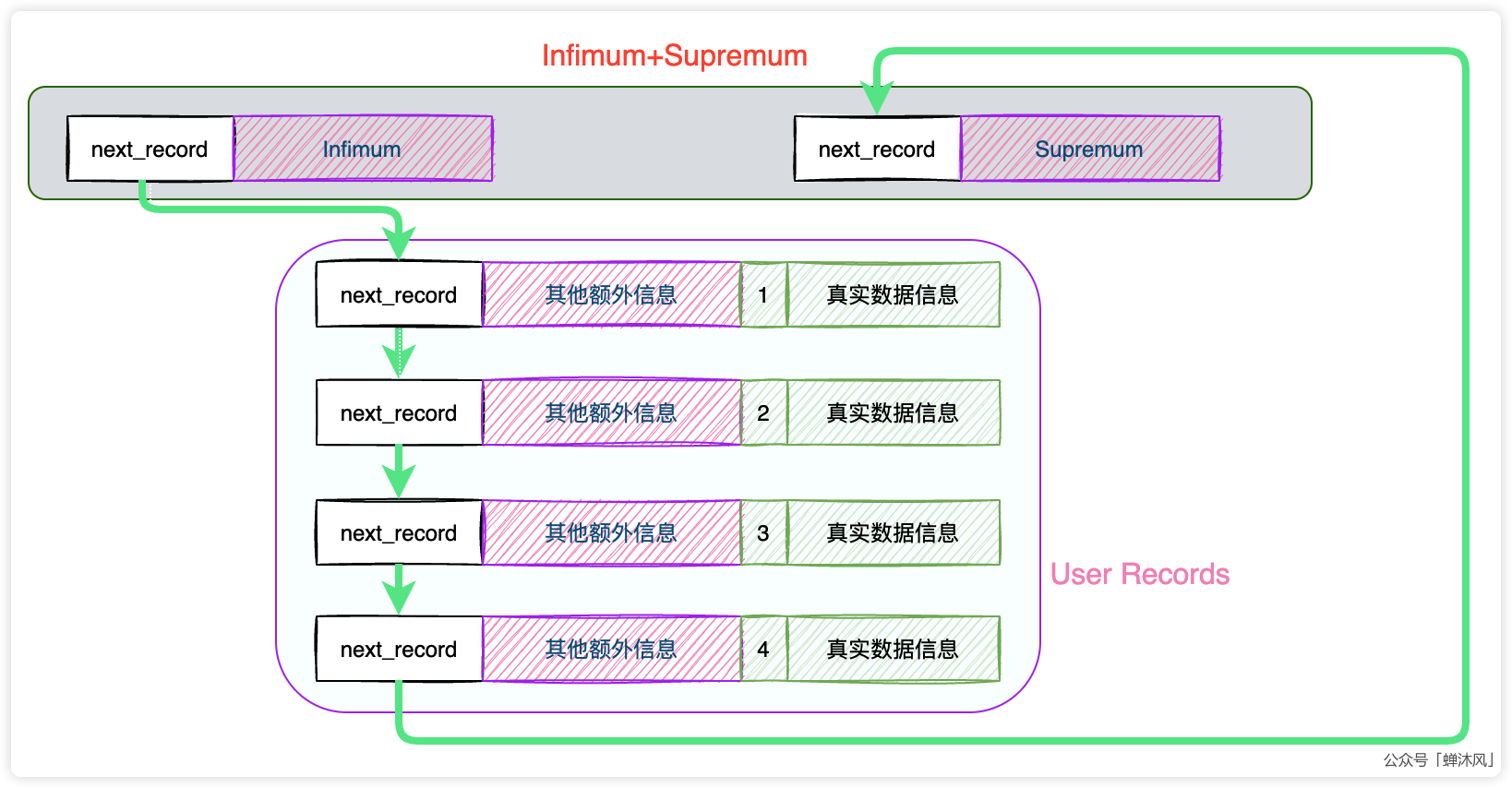
上图中我把真实数据信息中的主键id值画了出来,方便我们后续进行解释。
你可能不太理解InnoDB设计者为什么要无缘无故添加这两个字段,这俩货对我们的搜索工作看起来没有任何好处。
没错,这俩货不是方便我们在数据页中检索数据而添加的,他们发挥作用的战场是MySQL的LOCK_GAP记录锁。啥?不懂?没事儿,我就是提一嘴而已,对这篇文章没啥用,具体以后再说。。。
3.4 数据页中主键的高效查询方案
到目前为止,我们已经知道了在一个数据页中,用户记录是按照主键由小到大的顺序串联而成的单向链表。接下来我们要解决的就是如何在一个数据页中根据主键值搜索数据了。
如果我们执行下面这条查询语句
SELECT * FROM row_format_table WHERE id = 4;
最简单的办法就是遍历当前页面的所有记录,从Infimum记录开始沿着单向链表进行搜索,直到找到id为4的记录为止。记录数量少的时候还好说,这要是有成千上万条,那谁能受的了。
所以InnoDb设计者想出了一种绝妙的搜索方法,把数据页中的所有记录(包括伪记录)分成若干个小组,每个小组选出组内最大的一条记录作为“小组长”,接着把所有小组长的地址拿出来,编成目录。
这就好比我们去学校找人,我们只知道他是几年级的(确定数据页),然后再问问每个班主任有没有这个人(数据页中的小组),而不是上来就直接遍历整个年级的所有人。
为了使这种方案最大程度上发挥它的检索效率(不能随便分组,毕竟一个数据页分成一个组或者每条记录独占一个分组跟遍历也没什么区别),所以InnoDB的设计者规定了如下分组方案:
Infimum伪记录单独分成一个组Supremum伪记录所在分组的记录条数只能在1~8条之间- 其余分组的记录条数只能在4~8条之间
规则是这样,可是InnoDB怎么确定每个组内有多少个组员呢?设计者又想了一个办法,给“小组长”添加一个属性,记录这个组内一共有多少个组员(包括自己)。所以我们再扩充一下行格式:

小组长的n_owned值是组员的个数(包括自己),组员的n_owned值就是0。
接下来我们向表中多添加几条数据,看看分组到底是什么回事儿?需要注意的是,由于我们已经在表中指定了主键id,因此DB_ROW_ID这个参数不会再画出来了。
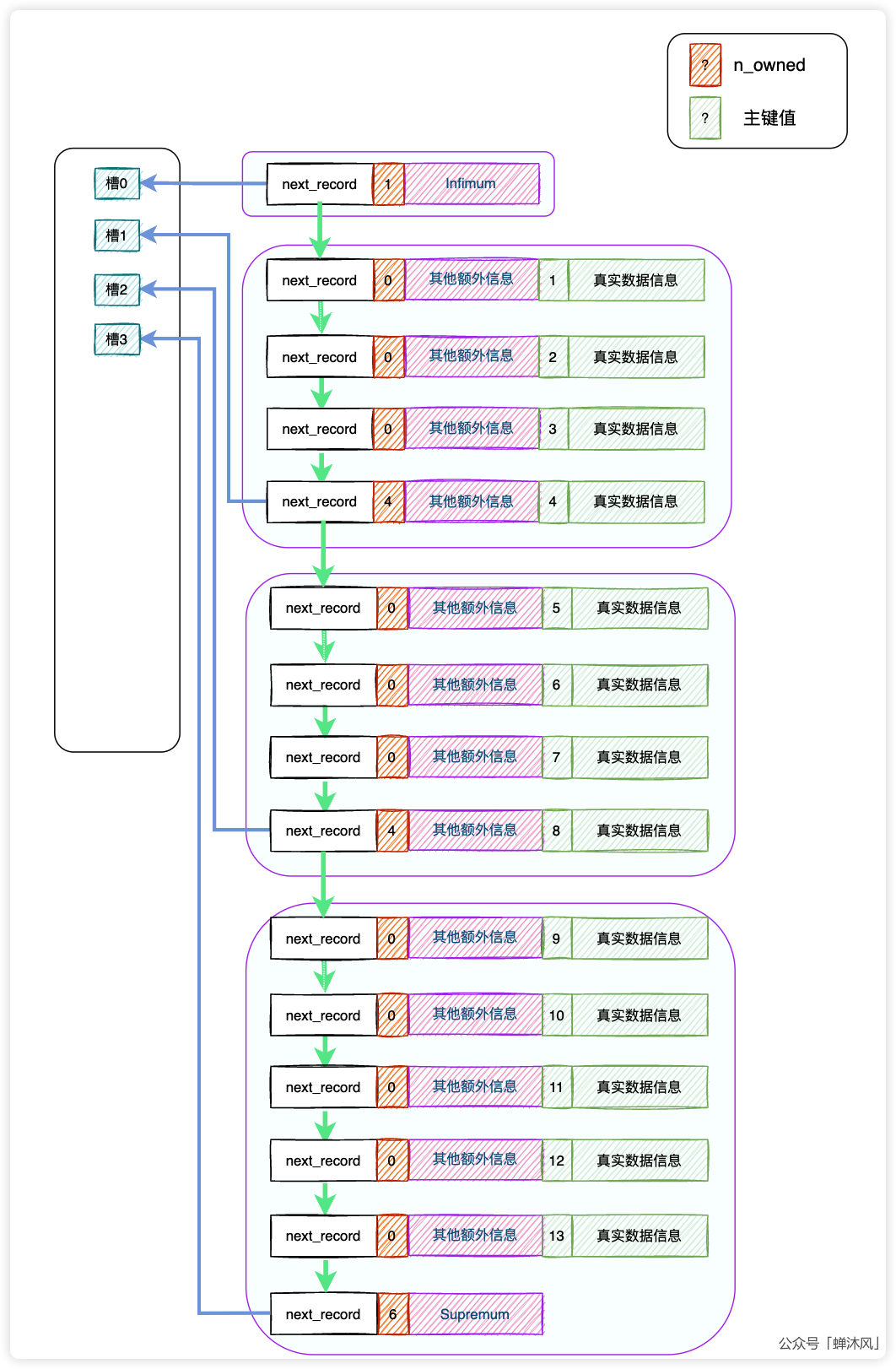
上图中的所有记录(包括伪记录)分成了4个小组,每个小组的“组长”被单独提拔,单独编制成“目录”,InnoDB官方称之为「槽」。槽在物理空间中是连续的,意味着通过一个槽可以很轻松地找到它的上一个和下一个,这一点非常重要。
槽的编号从0开始,我们查找数据的时候先找到对应的槽,然后再到小组中进行遍历即可,因为一个小组内的记录数量并不多,遍历的性能损耗可以忽略。而且每个槽代表的“组长”的主键值也是从小到大进行排列的,所以我们可以用二分法进行槽的快速查找。
图中包含4个槽,分别是0、1、2、3,二分法查找之前,最低的槽low=0,最高的槽high=3。现在我们再来看看在这个数据页中,我们查询id为7的记录,过程是怎样的。
- 使用二分法,计算中间槽的位置,
(0+3)/2=1,查看槽1对应的“组长”的主键值为4,因为4<7,所以设置low=1,high保持不变; - 再次使用二分法,计算中间槽的位置,
(1+3)/2=2,查看槽2对应的“组长”的主键值为8,因为8>7,所以设置high=2,low保持不变; - 现在
high=2,low=1,两者相差1,已经没有必要继续进行二分了,可以确定我们的记录就在槽2中,并且我们也能知道槽2对应的“组长”的主键是8,但是记录之间是单向链表,我们无法向前遍历。上文提到过,我们可以通过槽2找到槽1,进而找到它的“组长”,然后沿着“组长”向下遍历直到找到主键为7的记录就可以了。
说到这里,我们已经非常清楚在一个数据页中是如何根据主键进行搜索的。但是对于我们这篇文章的主题——MySQL的主键查询为什么这么快,只能算是回答了一半,毕竟在数据页中进行搜索的前提是你得先找到数据页啊。这就是每次面试必问的MySQL索引的知识了,下一篇文章再介绍吧。
4. 重要!数据页的其他字段
最后再补充几个知识点,文章中有两个问题我并没有讲
- 槽是怎样被存储的?
- 二分查找的时候,怎么知道目前有几个槽呢?
先回答第1个问题,我们上文介绍过数据页的结构,其实并不完整,下面我们再引入一个字段Page Directory,槽就是保存在了这个字段信息里。

Page Directory翻译成中文就是「页目录」,这么一来是不是更加深了你对槽这种目录的理解呢?
至于第2个问题,其实也是关于数据页结构的,之前没有一下子全画出来,因为我觉得需要的时候再加上更有助于记忆。
接下来我把所有之后会用到的数据页的结构都给大家画出来(很简单,别害怕),暂时没用的就屏蔽掉了,之后用到再说吧。

FIL_PAGE_OFFSET
InnoDB页的页号,相当于这个页的身份证
FIL_PAGE_PREV,FIL_PAGE_NEXT
看图你就明白了吧,每个页之间都是双向链表
FIL_PAGE_TYPE
InnoDB页的种类很多,比如我们这篇文章讲的数据页,还有其他的比如存放Insert Buffer信息的页,存放undo日志信息的页等,这个字段就是用来标识页面的类型的
PAGE_N_DIR_SLOTS
这个字段保存的就是槽的个数了,二分法就是根据这个字段的值来确定high的值
PAGE_LAST_INSERT
当前页面最后插入记录的位置,当有新记录插入的时候,直接读取这个数据,将新记录放到相应位置就可以了
PAGE_N_RECS
该页中记录的数量(不包括最小和最大记录)
5. 推荐阅读
这篇文章是索引的前夜,下期索引见!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)