使用阿里canal实现mysql与Elasticsearch增量同步
一、背景介绍
最近在做一个地理信息相关的项目,需要维护大量的地址描述数据,同时需要提供对数据检索的功能,准备采用Elasticsearch(6.7)实现。那么问题就来了,地址数据需要同时在MySQL和ES中维护,如果通过代码层面实现会增加代码量也不易维护,权衡之下决定使用阿里的Canal中间件来实现,留念备查。
Canal主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,工作原理是伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议,MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal ),canal 解析 binary log 对象(原始为 byte 流)。同时支持客户端数据落地的适配功能,目前支持关系型数据库的数据同步、HBase的数据同步和ElasticSearch多表数据同步。
二、环境准备
1、MySQL数据库安装;
2、Elasticsearch安装;
3、Canal Server安装及配置,参考https://github.com/alibaba/canal/wiki/QuickStart;
4、Canal Client Adapter安装,参考https://github.com/alibaba/canal/wiki/ClientAdapter;
三、Canal Server配置instance
1、在canal server安装目录下找到/conf/canal.properties,在canal.destinations配置项中增加一个instance,我这里配置的是es-address-original
1 ################################################# 2 ######### destinations ############# 3 ################################################# 4 canal.destinations = es-address-original
2、在/conf目录下创建es-address-original文件夹,并创建instance.properties文件,大家可以直接复制conf目录下的example目录进行修改,主要配置参数如下,其它参考自行参考官方文档
# MySQL数据库连接信息 canal.instance.master.address=192.168.x.x:3306 canal.instance.dbUsername=canal canal.instance.dbPassword=canal canal.instance.connectionCharset = UTF-8 # mysql 数据解析关注的表,Perl正则表达式 # 多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\) # 常见例子: # 1. 所有表:.* or .*\\..* # 2. canal schema下所有表: canal\\..* # 3. canal下的以canal打头的表:canal\\.canal.* # 4. canal schema下的一张表:canal\\.test1 # 5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔) canal.instance.filter.regex=address-platform\\.address_original
四、Canal Adapter配置
client-adapter分为适配器和启动器两部分, 适配器为多个fat jar, 每个适配器会将自己所需的依赖打成一个包, 以SPI的方式让启动器动态加载, 目前所有支持的适配器都放置在plugin目录下
1、在canal adapter的conf目录下找到application.yml配置文件(根据官方介绍启动器为SpringBoot项目)
server: port: 8081 spring: jackson: date-format: yyyy-MM-dd HH:mm:ss time-zone: GMT+8 default-property-inclusion: non_null canal.conf: mode: tcp # 客户端模式 tcp or kafka or rocketMQ canalServerHost: 127.0.0.1:11111 # canal server address # zookeeperHosts: slave1:2181 # mqServers: 127.0.0.1:9092 #or rocketmq # flatMessage: true batchSize: 500 # 每次获取数据的批大小,单位为K syncBatchSize: 1000 # 每次同步的批数量 retries: 0 # 重试次数,-1为无限重试 timeout: # 同步超时时间,单位为毫秒 accessKey: secretKey: srcDataSources: # 源数据库 defaultDS: url: jdbc:mysql://192.168.0.201:3306/address-platform?useUnicode=true username: root password: 123456 canalAdapters: - instance: es-address-original # canal instance Name or mq topic name对应canal server中配置的instance名称 groups: - groupId: g1 outerAdapters: - key: addressOriginalKey name: es hosts: 192.168.x.x:9200 # 127.0.0.1:9200 for rest mode properties: mode: rest # transport or rest # # security.auth: test:123456 # only used for rest mode cluster.name: elasticsearch # ES集群名称
2、/conf/es下新增配置文件,文件名随意,配置内容如下
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值 outerAdapterKey: addressOriginalKey # 对应application.yml中es配置的key destination: es-address-original # cannal的instance或者MQ的topic groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据 esMapping: _index: address_original # es 的索引名称 _type: _doc # es 的type名称, es7下无需配置此项 _id: id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配 upsert: true # pk: id sql: "select a.ID as id, a.ADDRESS as address, a.SERIAL_NO as serial_no from address_original a" # sql映射,注意区分表字段和索引字段大小写 # objFields: # _labels: array:; # etlCondition: "where a.c_time>={}" # etl 的条件参数 commitBatch: 3000 # 提交批大小
3、创建ES索引信息,通过postman请求ES服务器http://192.168.x.x:9200/address_original,address_original是索引的名称,请求方式为PUT,参数类型为raw(json)
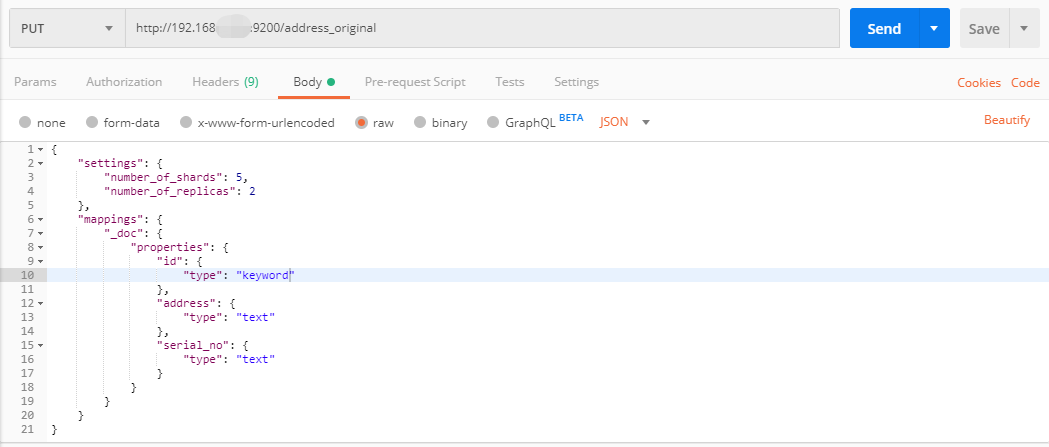
4、这里有几个坑注意一下:
1)canal适配器会通过GET http://192.168.x.x:9200/address_original/_mapping的方式读取es mapping,如果创建索引的时候没有配置mappings信息,会报Not found the mapping info of index异常;
2)测试的时候表字段名是大写,es索引字段名称小写,抛了空指针异常没有具体的异常描述,后来将/canal adapter/conf/es目录中的配置文件sql配置项采用别名统一小写后解决,这里推测数据库表与索引映射名称区分大小写的,后面再看看源码求证一下;
五、运行测试
1、在MySQL数据库address_original表中维护数据(增删改);
2、观察canal adapter日志;
六、运行结果
索引文档结果会根据数据库操作同步更新


 浙公网安备 33010602011771号
浙公网安备 33010602011771号