Python函数的进阶
1. 今日内容
1.1 函数的参数
*的魔性用法
函数形参最终顺序
1.2名称空间
全局名称空间,局部名称空间,内置名称空间
取值顺序与加载顺序
作用域
内置函数:globals() locals()
1.3 高阶函数(函数的嵌套)
1.4关键字:global nonlocal
2. 内容详细
2.1 函数的参数
昨天我们从形参角度,讲了两种参数,一个是位置参数,位置参数主要是实参与形参从左至右一一对应,一个是默认值参数,默认值参数,如果实参不传参,则形参使用默认参数。那么无论是位置参数,还是默认参数,函数调用时传入多少实参,我必须写等数量的形参去对应接收, 如果不这样,那么就会报错:
def eat(a,b,c,):
print('我请你吃:',a,b,c)
eat('蒸羊羔','蒸熊掌','蒸鹿尾儿','烧花鸭') # 报错
如果我们在传参数的时候不很清楚有哪些的时候,或者说给一个函数传了很多实参,我们就要对应写很多形参,这样很麻烦,怎么办?,我们可以考虑使用动态参数也叫万能参数
2.11 形参的第三种:动态参数
动态参数分为两种:动态接受位置参数 *args,动态接收关键字参数**kwargs.
动态接收位置参数:*args
我们按照上面的例子继续写,如果我请你吃的内容很多,但是我又不想用多个参数接收,那么我就可以使用动态参数*args
def eat(*args):
print('我请你吃:',args)
eat('蒸羊羔儿','蒸熊掌','蒸鹿尾儿','烧花鸭','烧雏鸡','烧子鹅')
# 运行结果:
#我请你吃: ('蒸羊羔儿', '蒸熊掌', '蒸鹿尾儿', '烧花鸭', '烧雏鸡', '烧子鹅')
解释一下上面参数的意义:首先来说args,args就是一个普通的形参,但是如果你在args前面加一个,那么就拥有了特殊的意义:在python中除了表示乘号,他是有魔法的。+args,这样设置形参,那么这个形参会将实参所有的位置参数接收,放置在一个元组中,并将这个元组赋值给args这个形参,这里起到魔法效果的是 * 而不是args,a也可以达到刚才效果,但是我们PEP8规范中规定就使用args,约定俗成的。
练习:传入函数中数量不定的int型数据,函数计算所有数的和并返回。
def my_max(*args):
n = 0
for i in args:
n += i
return n
**动态接收关键字参数: kwargs
实参角度有位置参数和关键字参数两种,python中既然有*args可以接受所有的位置参数那么肯定也有一种参数接受所有的关键字参数,那么这个就是kwargs,同理这个是具有魔法用法的,kwargs约定俗成使用作为形参。举例说明:**kwargs,是接受所有的关键字参数然后将其转换成一个字典赋值给kwargs这个形参。
def func(**kwargs):
print(kwargs) # {'name': '太白金星', 'sex': '男'}
func(name='太白金星',sex='男')
我们看一下动态参数的完成写法:
def func(*args,**kwargs):
print(args) # ('蒸羊羔儿', '蒸熊掌', '蒸鹿尾儿')
print(kwargs) # {'name': '太白金星', 'sex': '男'}
func('蒸羊羔儿', '蒸熊掌', '蒸鹿尾儿',name='太白金星',sex='男')
如果一个参数设置了动态参数,那么他可以接受所有的位置参数,以及关键字参数,这样就会大大提升函数拓展性,针对于实参参数较多的情况下,解决了一一对应的麻烦。
2.12 * 的魔性用法
刚才我们研究了动态参数,其实有的同学对于魔法用法 * 比较感兴趣,那么那的魔性用法不止这么一点用法,我们继续研究:
函数中分为打散和聚合。
函数外可以处理剩余的元素。
函数的打散和聚合
聚合
刚才我们研究了,在函数定义时,如果我只定义了一个形参称为args,那么这一个形参只能接受几个实参? 是不是只能当做一个位置参数对待?它只能接受一个参数:
def eat(args):
print('我请你吃:',args) # 我请你吃: 蒸羊羔儿
eat('蒸羊羔儿')
但是如果我给其前面加一个* 那么args可以接受多个实参,并且返回一个元组,对吧? (**kwargs也是同理将多个关键字参数转化成一个字典返回)所以在函数的定义时: *起到的是聚合的作用。
打散
此时不着急给大家讲这个打散,而是出一个小题:你如何将三个数据(这三个数据都是可迭代对象类型)s1 = 'alex',l1 = [1, 2, 3, 4], tu1 = ('武sir', '太白', '女神',)的每一元素传给动态参数*args?(就是args最终得到的是 ('a','l','e','x', 1, 2, 3, 4,'武sir', '太白', '女神',)?有人说这还不简单么?我直接传给他们不就行了?
s1 = 'alex'
l1 = [1, 2, 3, 4]
tu1 = ('武sir', '太白', '女神',)
def func(*args):
print(args) # ('alex', [1, 2, 3, 4], ('武sir', '太白', '女神'))
func(s1,l1,tu1)
这样肯定是不行,他会将这个三个数据类型当成三个位置参数传给args,没有实现我的要求。
好像你除了直接写,没有别的什么办法,那么这里就得用到我们的魔法用法 :*
s1 = 'alex'
l1 = [1, 2, 3, 4]
tu1 = ('武sir', '太白', '女神',)
def func(*args):
print(args) # ('a', 'l', 'e', 'x', 1, 2, 3, 4, '武sir', '太白', '女神')
func(*s1,*l1,*tu1)
你看此时是函数的执行时,我将你位置参数的实参(可迭代类型)前面加上,相当于将这些实参给拆解成一个一个的组成元素当成位置参数,然后传给args,这时候这个好像取到的是打散的作用。所以在函数的执行时:,**起到的是打散的作用。
dic1 = {'name': '太白', 'age': 18}
dic2 = {'hobby': '喝茶', 'sex': '男'}
def func(**kwargs):
print(kwargs) # {'name': '太白', 'age': 18, 'hobby': '喝茶', 'sex': '男'}
func(**dic1,**dic2)
*处理剩下的元素
*除了在函数中可以这样打散,聚合外,函数外还可以灵活的运用:
# 之前讲过的分别赋值
a,b = (1,2)
print(a, b) # 1 2
# 其实还可以这么用:
a,*b = (1, 2, 3, 4,)
print(a, b) # 1 [2, 3, 4]
*rest,a,b = range(5)
print(rest, a, b) # [0, 1, 2] 3 4
print([1, 2, *[3, 4, 5]]) # [1, 2, 3, 4, 5]
2.13 形参的顺序
到目前为止,从形参的角度我们讲了位置参数,默认值参数,动态参数*args,**kwargs,还差一种参数,需要讲完形参顺序之后,引出。先不着急,我们先看看已经讲的这些形参他的排列顺序是如何的呢?
首先,位置参数,与默认参数他两个的顺序我们昨天已经确定了,位置参数必须在前面,即 :位置参数,默认参数。
那么动态参数*args,**kwargs放在哪里呢?
动态参数*args,肯定不能放在位置参数前面,这样我的位置参数的参数就接收不到具体的实参了:
# 这样位置参数a,b始终接收不到实参了,因为args全部接受完了
def func(*args,a,b,sex='男'):
print(args)
print(a,b)
func(1, 2, 3, 4, 5)
那么动态参数必须在位置参数后面,他可以在默认参数后面么?
# 这样也不行,我的实参的第三个参数始终都会将sex覆盖掉,这样失去了默认参数的意义。
def func(a,b,sex='男',*args,):
print(args) # (4, 5)
print(sex) # 3
print(a,b) # 1 2
func(1, 2, 3, 4, 5)
所以*args一定要在位置参数与默认值参数中间:位置参数,*args,默认参数。
那么我的kwargs放在哪里?kwargs可以放在默认参数前面么?
# 直接报错:因为**kwargs是接受所有的关键字参数,如果你想改变默认参数sex,你永远也改变不了,因为
# 它会先被**kwargs接受。
def func(a,b,*args,**kwargs,sex='男',):
print(args) # (4, 5)
print(sex) # 3
print(a,b) # 1 2
print(kwargs)
func(1, 2, 3, 4, 5)
所以截止到此:所有形参的顺序为:位置参数,*args,默认参数,kwargs。**
2.14 形参的第四种参数:仅限关键字参数
仅限关键字参数是python3x更新的新特性,他的位置要放在*args后面,kwargs前面(如果有kwargs),也就是默认参数的位置,它与默认参数的前后顺序无所谓,它只接受关键字传的参数:
# 这样传参是错误的,因为仅限关键字参数c只接受关键字参数
def func(a,b,*args,c):
print(a,b) # 1 2
print(args) # (4, 5)
# func(1, 2, 3, 4, 5)
# 这样就正确了:
def func(a,b,*args,c):
print(a,b) # 1 2
print(args) # (3, 4)
print(5)
func(1, 2, 3, 4, c=5)
这个仅限关键字参数从名字定义就可以看出他只能通过关键字参数传参,其实可以把它当成不设置默认值的默认参数而且必须要传参数,不传就报错。
所以形参角度的所有形参的最终顺序为:位置参数,*args,默认参数,仅限关键字参数,kwargs。**
课间考一道题:
def foo(a,b,*args,c,sex=None,**kwargs):
print(a,b)
print(c)
print(sex)
print(args)
print(kwargs)
# foo(1,2,3,4,c=6)
# foo(1,2,sex='男',name='alex',hobby='old_woman')
# foo(1,2,3,4,name='alex',sex='男')
# foo(1,2,c=18)
# foo(2, 3, [1, 2, 3],c=13,hobby='喝茶')
# foo(*[1, 2, 3, 4],**{'name':'太白','c':12,'sex':'女'})
2.2 名称空间,作用域
2.21 名称空间:
接下来我们讲的内容,理论性的偏多,就是从空间角度,内存级别去研究python。首先我们看看什么是全局名称空间:
在python解释器开始执行之后, 就会在内存中开辟一个空间, 每当遇到一个变量的时候, 就把变量名和值之间的关系记录下来, 但是当遇到函数定义的时候, 解释器只是把函数名读入内存, 表示这个函数存在了, 至于函数内部的变量和逻辑, 解释器是不关心的. 也就是说一开始的时候函数只是加载进来, 仅此而已, 只有当函数被调用和访问的时候, 解释器才会根据函数内部声明的变量来进行开辟变量的内部空间. 随着函数执行完毕, 这些函数内部变量占用的空间也会随着函数执行完毕而被清空.
我们首先回忆一下Python代码运行的时候遇到函数是怎么做的,从Python解释器开始执行之后,就在内存中开辟里一个空间,每当遇到一个变量的时候,就把变量名和值之间对应的关系记录下来,但是当遇到函数定义的时候,解释器只是象征性的将函数名读如内存,表示知道这个函数存在了,至于函数内部的变量和逻辑,解释器根本不关心。
等执行到函数调用的时候,Python解释器会再开辟一块内存来储存这个函数里面的内容,这个时候,才关注函数里面有哪些变量,而函数中的变量回储存在新开辟出来的内存中,函数中的变量只能在函数内部使用,并且会随着函数执行完毕,这块内存中的所有内容也会被清空。
我们给这个‘存放名字与值的关系’的空间起了一个名字-------命名空间。
代码在运行伊始,创建的存储“变量名与值的关系”的空间叫做全局命名空间;
在函数的运行中开辟的临时的空间叫做局部命名空间也叫做临时名称空间。
现在我们知道了,py文件中,存放变量与值的关系的一个空间叫做全局名称空间,而当执行一个函数时,内存中会临时开辟一个空间,临时存放函数中的变量与值的关系,这个叫做临时名称空间,或者局部名称空间。
其实python还有一个空间叫做内置名称空间:内置名称空间存放的就是一些内置函数等拿来即用的特殊的变量:input,print,list等等,所以,我们通过画图捋一下:
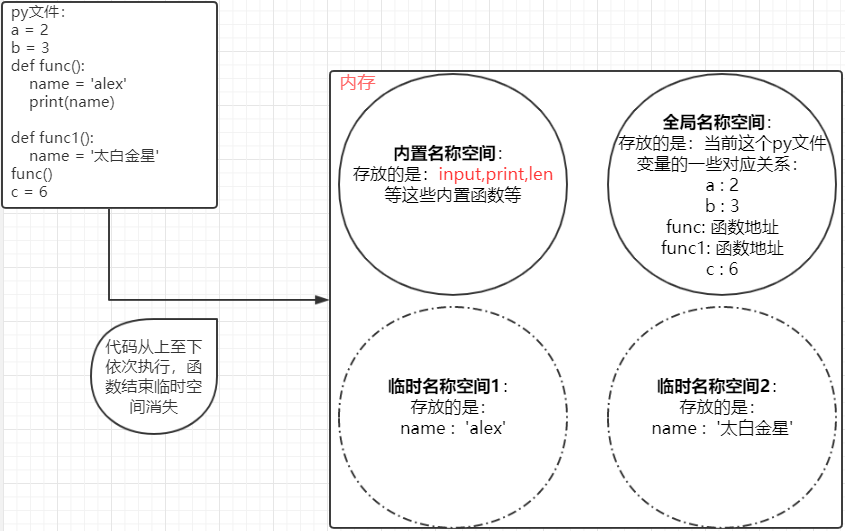
那么这就是python中经常提到的三个空间。
总结:
\1. 全局命名空间--> 我们直接在py文件中, 函数外声明的变量都属于全局命名空间
\2. 局部命名空间--> 在函数中声明的变量会放在局部命名空间
\3. 内置命名空间--> 存放python解释器为我们提供的名字, list, tuple, str, int这些都是内置命名空间
2.22 加载顺序:
所谓的加载顺序,就是这三个空间加载到内存的先后顺序,也就是这个三个空间在内存中创建的先后顺序,你想想他们能是同时创建么?肯定不是的,那么谁先谁后呢?我们捋顺一下:在启动python解释器之后,即使没有创建任何的变量或者函数,还是会有一些函数直接可以用的比如abs(-1),max(1,3)等等,在启动Python解释器的时候,就已经导入到内存当中供我们使用,所以肯定是先加载内置名称空间,然后就开始从文件的最上面向下一行一行执行,此时如果遇到了初始化变量,就会创建全局名称空间,将这些对应关系存放进去,然后遇到了函数执行时,在内存中临时开辟一个空间,加载函数中的一些变量等等。所以这三个空间的加载顺序为:内置命名空间(程序运行伊始加载)->全局命名空间(程序运行中:从上到下加载)->局部命名空间(程序运行中:调用时才加载。
2.23 取值顺序:
取值顺序就是引用一个变量,先从哪一个空间开始引用。这个有一个关键点:从哪个空间开始引用这个变量。我们分别举例说明:
# 如果你在全局名称空间引用一个变量,先从全局名称空间引用,全局名# 称空间如果没有,才会向内置名称空间引用。
input = 666
print(input) # 666
# 如果你在局部名称空间引用一个变量,先从局部名称空间引用,
# 局部名称空间如果没有,才会向全局名称空间引用,全局名称空间在没有,就会向内置名称空间引用。
input = 666
print(input) # 666
input = 666
def func():
input = 111
print(input) # 111
func()
所以空间的取值顺序与加载顺序是相反的,取值顺序满足的就近原则,从小范围到大范围一层一层的逐步引用。
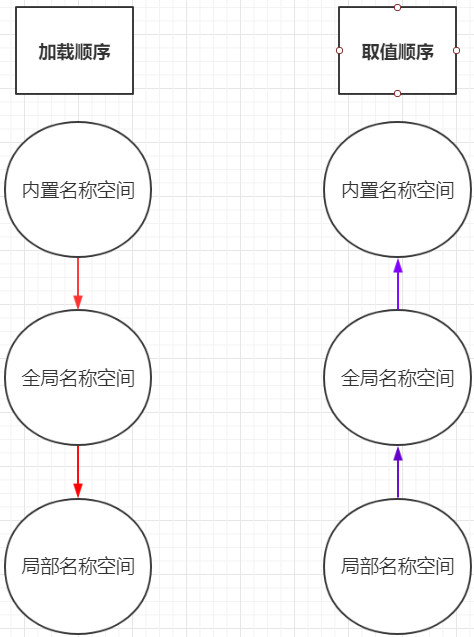
2.24 作用域
作用域就是作用范围, 按照生效范围来看分为全局作用域和局部作用域
全局作用域: 包含内置命名空间和全局命名空间. 在整个文件的任何位置都可以使用(遵循 从上到下逐⾏执行).
局部作用域: 在函数内部可以使用.
作⽤域命名空间:
1. 全局作用域: 全局命名空间 + 内置命名空间
2. 局部作⽤域: 局部命名空间
2.25 内置函数globals(),locals()
这两个内置函数放在这里讲是在合适不过的,他们就直接可以反映作用域的内容,有助于我们理解作用域的范围。
globals(): 以字典的形式返回全局作用域所有的变量对应关系。
locals(): 以字典的形式返回当前作用域的变量的对应关系。
这里一个是全局作用域,一个是当前作用域,一定要分清楚,接下来,我们用代码验证:
# 在全局作用域下打印,则他们获取的都是全局作用域的所有的内容。
a = 2
b = 3
print(globals())
print(locals())
'''
{'__name__': '__main__', '__doc__': None, '__package__': None,
'__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001806E50C0B8>,
'__spec__': None, '__annotations__': {},
'__builtins__': <module 'builtins' (built-in)>,
'__file__': 'D:/lnh.python/py project/teaching_show/day09~day15/function.py',
'__cached__': None, 'a': 2, 'b': 3}
'''
# 在局部作用域中打印。
a = 2
b = 3
def foo():
c = 3
print(globals()) # 和上面一样,还是全局作用域的内容
print(locals()) # {'c': 3}
foo()
2.3 高阶函数(函数的嵌套)
其实我们见到了嵌套这个词不陌生,之前我们讲过列表的嵌套,列表的嵌套就是一个列表中还有列表,可能那个列表中还有列表......那么顾名思义,函数的嵌套,就是一个函数中,还有函数。
想要玩明白函数的嵌套,关键点:只要遇见了函数名+()就是函数的调用. 如果没有就不是函数的调用,吃透这一点就算明白了。那么我们举例练习:找同学依次说出下面代码的执行顺序
# 例1:
def func1():
print('in func1')
print(3)
def func2():
print('in func2')
print(4)
func1()
print(1)
func2()
print(2)
# 例2:
def func1():
print('in func1')
print(3)
def func2():
print('in func2')
func1()
print(4)
print(1)
func2()
print(2)
# 例3:
def fun2():
print(2)
def fun3():
print(6)
print(4)
fun3()
print(8)
print(3)
fun2()
print(5)
2.4 关键字:global、nonlocal
global
讲这个关键字之前,先给大家看一个现象:
a = 1
def func():
print(a)
func()
a = 1
def func():
a += 1 # 报错
func()
局部作用域对全局作用域的变量(此变量只能是不可变的数据类型)只能进行引用,而不能进行改变,只要改变就会报错,但是有些时候,我们程序中会遇到局部作用域去改变全局作用域的一些变量的需求,这怎么做呢?这就得用到关键字global:
global第一个功能:在局部作用域中可以更改全局作用域的变量。
count = 1
def search():
global count
count = 2
search()
print(count)
利用global在局部作用域也可以声明一个全局变量。
def func():
global a
a = 3
func()
print(a)
所以global关键字有两个作用:
1,声明一个全局变量。
2,在局部作用域想要对全局作用域的全局变量进行修改时,需要用到 global(限于字符串,数字)。
nonlocal
nonlocal是python3x新加的功能,与global用法差不多,就是在局部作用域如果想对父级作用域的变量进行改变时,需要用到nonlocal,当然这个用的不是很多,了解即可。
def add_b():
b = 42
def do_global():
b = 10
print(b)
def dd_nonlocal():
nonlocal b
b = b + 20
print(b)
dd_nonlocal()
print(b)
do_global()
print(b)
add_b()
nonlocal关键字举例
nonlocal的总结:
1,不能更改全局变量。
2,在局部作用域中,对父级作用域(或者更外层作用域非全局作用域)的变量进行引用和修改,并且引用的哪层,从那层及以下此变量全部发生改变。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号