【学习笔记】二分图
$$ \Huge{\textbf{二 分 图}} $$$$ \large {\textbf{Bipartite graph}} $$
1. 什么是二分图?
二分,二分答案或二分搜索,但是,二分图此二分非彼二分。
若一张图的节点由两个集合组成,且两个集合内部没有边,那么这个图称之为二分图(Bipartite graph),就像:
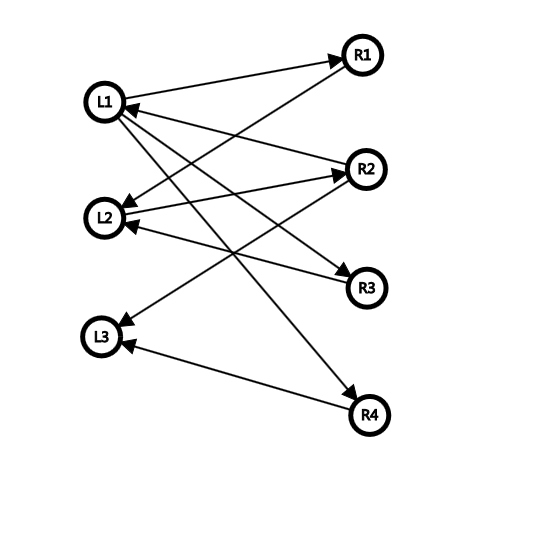
就是。
2. 二分图有什么用?
二分图有一些性质:
- 将两个集合中的点分别染色,则每一条边的端点一定不同色(不在同一集合,根据定义推)。
- 不存在长度为奇数的环(每条边都联通不同的集合,走回来必定需要偶数次)
3. 怎么判断二分图?
直接枚举两个集合肯定不行,利用性质,以随便一个顶点开始遍历全图,对经过的顶点进行交替染色(例如 2 和 5 之间有条边,2是黑色,那么 5 是白色),若没有出现颜色冲突(没有长度为奇数的环),则为二分图。
4. 应用
4.1 二分图最大匹配
例题 4.1.1 [USACO4.2] 完美的牛栏The Perfect Stall
农夫约翰上个星期刚刚建好了他的新牛棚,他使用了最新的挤奶技术。不幸的是,由于工程问题,每个牛栏都不一样。第一个星期,农夫约翰随便地让奶牛们进入牛栏,但是问题很快地显露出来:每头奶牛都只愿意在她们喜欢的那些牛栏中产奶。上个星期,农夫约翰刚刚收集到了奶牛们的爱好的信息(每头奶牛喜欢在哪些牛栏产奶)。一个牛栏只能容纳一头奶牛,当然,一头奶牛只能在一个牛栏中产奶。
给出奶牛们的爱好的信息,计算最大分配方案。
4.1.2 解决方案
转换题意:
给定一张二分图,要求选出一些边,使得这些边没有公共顶点,且边的数量最大。
这个是一个裸的二分图最大匹配,使用匈牙利算法。
匈牙利算法中有一个重要的增广路算法。
增广路指的是:路径的两个端点没有在当前增广遍历的点,且路径中已枚举的边与未枚举的边交错出现。
那又有什么用呢?显然,一条增广路中,未枚举的边一定比已枚举的边要多一条,而且一条除起点与终点之外都枚举过!
那么取反这条增广路,则答案 $+1$,直到再也找不到新的增广路。
由于每个点都要枚举一次,时间复杂度 $O(nm)$,($n$为奶牛数,$m$为牛栏数)。
4.1.3 代码实现:
bool road[maxn];
int link[maxn]; // 记录已得到的增广路的起点
bool map[maxn][maxn];// 邻接矩阵
bool find(int u) {
for(int i = 1; i <= m; i++) {
if(map[u][i] && !road[i]) {
road[i] = 1;
if(link[i] == 0 || find(link[i])) {
link[i] = u;
return 1;
}
}
}
return 0;
}这是使用复古的邻接矩阵实现的。
5 相关结论
(摘自 OI-Wiki)
5.1 König 定理(二分图最小点覆盖)
5.1.1 最小点覆盖:选最少的点,满足每条边至少有一个端点被选。
二分图中,最小点覆盖 $=$ 最大匹配。
5.1.2 证明:
将二分图点集分成左右两个集合,使得所有边的两个端点都不在一个集合。
考虑如下构造:从左侧未匹配的节点出发,按照匈牙利算法中增广路的方式走,即先走一条未匹配边,再走一条匹配边。由于已经求出了最大匹配,所以这样的增广路一定以匹配边结束。在所有经过这样「增广路」的节点上打标记。则最后构造的集合是:所有左侧未打标记的节点和所有右侧打了标记的节点。
首先,易证这个集合的大小等于最大匹配。打了标记的节点一定都是匹配边上的点,一条匹配的边两侧一定都有标记(在增广路上)或都没有标记,所以两个节点中必然有一个被选中。
其次,这个集合是一个点覆盖。一条匹配边一定有一个点被选中,而一条未匹配的边一定是增广路的一部分,而右侧端点也一定被选中。
同时,不存在更小的点覆盖。为了覆盖最大匹配的所有边,至少要有最大匹配边数的点数。
5.2 二分图最大独立集
5.2.1 最大独立集:选最多的点,满足两两之间没有边相连。
5.2.2 证明:
因为在最小点覆盖中,任意一条边都被至少选了一个顶点,所以对于其点集的补集,任意一条边都被至多选了一个顶点,所以不存在边连接两个点集中的点,且该点集最大。因此二分图中,最大独立集 $=$ 总点数 $-$ 最小点覆盖。
6. 优化
6.1 图存储优化
6.1.1 链式前向星
在 4.1.3 中,我们使用了邻接矩阵来存储图,然而大家都知道,这种方式及其耗空间,例如在:
例题 6.1.1.1 [SCOI2010] 连续攻击游戏
lxhgww 最近迷上了一款游戏,在游戏里,他拥有很多的装备,每种装备都有 $2$ 个属性,这些属性的值用 $[1,10000]$ 之间的数表示。当他使用某种装备时,他只能使用该装备的某一个属性。并且每种装备最多只能使用一次。游戏进行到最后,lxhgww 遇到了终极 boss,这个终极 boss 很奇怪,攻击他的装备所使用的属性值必须从 $1$ 开始连续递增地攻击,才能对 boss 产生伤害。也就是说一开始的时候,lxhgww 只能使用某个属性值为 $1$ 的装备攻击 boss,然后只能使用某个属性值为 $2$ 的装备攻击 boss,然后只能使用某个属性值为 $3$ 的装备攻击 boss……以此类推。现在 lxhgww 想知道他最多能连续攻击 boss 多少次?
$N\le 10^{6}$
显然,使用邻接矩阵空间一定会炸:
这时使用链式前向星才能避免如上惨祸。
6.1.1.2 代码实现
bool road[maxn];
int link[maxn<<1],head[maxn<<1],tot;
struct node {
int to, next, w;
} p[maxn];
void push(int id , int pid) {
p[++tot].next = head[id], p[tot].to = pid, head[id] = tot;
}
bool find(int u) {
int pt = head[u], to;
while (pt) {
to = p[pt].to;
if (!road[to]) {
road[to] = 1;
if (!link[to] || find(link[to])) return link[to] = u, 1;
}
pt = p[pt].next;
}
return 0;
}6.2 标记优化
6.2.1 标记数组
在每次调用 find 函数之前,我们需要对标记函数 road 进行清空,但是,在其中有一些根本没有用到的位置,清空的时候浪费时间,那么我们只需要记录一下使用过的位置,不就省下了这些时间吗?
6.2.1.1 代码实现
还是以 6.1.1.1 为例给出代码:
#include<bits/stdc++.h>
using namespace std;
const int maxn = 1e6 + 5, maxp = 2e6 + 5;
long long n, m, e;
bool road[maxn];
int link[maxn], head[maxn], tot;
vector<int>id;
struct node {
int to, next, w;
} p[maxp];
inline void push(int id , int pid) {
p[++tot].next = head[id], p[tot].to = pid, head[id] = tot;
}
inline bool find(int u) {
int pt = head[u], to;
while (pt) {
to = p[pt].to;
if (!road[to]) {
road[to] = 1;
id.push_back(to);//记录使用
if (!link[to] || find(link[to])) return link[to] = u, 1;
}
pt = p[pt].next;
}
return 0;
}
int main() {
scanf("%d",&n);
int u, v;
for(int i = 1; i <= n; i++) scanf("%d%d",&u,&v), push(u, i), push(v, i);
for(int i = 1; i <= 10000; i++) {
for(int j = 0; j < id.size(); j++)road[id[j]] = 0;//标记清空
id.clear();
if(!find(i)) return printf("%d",i - 1), 0;
}
puts("10000");
}
6.2.2 时间戳优化
然鹅,6.2.1 中的方法还是有点费时间,能不能更进一步呢?
定义一个时间戳 $ti$ ,若 $road_i \not = ti$ 则视为 $road_i = 0$。
6.2.2.1 代码实现
int road[maxn];
int link[maxn];
struct node {
bool map[maxn];
} p[maxn];
inline void push(int id , int pid) {
p[id].map[pid] = 1;
}
inline bool find(int u) {
for(int i = 1; i <= m; i++) {
if(p[u].map[i] && road[i] != ti[0]) {
road[i] = ti[0];
if(link[i] == 0 || find(link[i])) return link[i] = u, 1;
}
}
return 0;
}7. 注释
无注释。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现