201871030104-常祺 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
| 课程班级博客链接 | 班级博客 |
| 这个作业要求链接 | 作业要求 |
| 我的课程学习目标 | 体验软件项目开发中的两人合作,练习结对编程(Pair programming) |
| 这个作业在哪些方面帮助我实现学习目标 | 1.通过阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念 2.通过软件项目合作开发,体会到了结对编程的真正益处 3.通过开发D{0-1}KP 实例数据集算法实验平台,学习到了编程在软件工程里的运用 |
| 结对方学号-姓名 | 余宝鹏—201871030134 |
| 结对方本次博客作业链接 | https://www.cnblogs.com/ybp7/p/14655340.html |
| 本项目Github的仓库链接地址 | https://github.com/Y7-ybp/D-0-1-KP |
任务1:阅读《现代软件工程—构建之法》第3-4章内容,理解并掌握代码风格规范、代码设计规范、代码复审、结对编程概念
-
代码风格规范:代码风格并不会影响程序的运行,但一段好的代码风格,能让人阅读起来特别舒服。在企业合作中代码格式规范是十分重要的。
-
代码设计规范:代码设计规范可以分为架构设计、类的设计、函数的设计、Log的设计以及竞态关系的设计(多线程的设计)等等,通过这些设计,可以使代码更加规范,标准。
-
代码复审:代码审查是任何正式开发过程中的必要环节。但大多数开发者不知道的是,代码审查分为很多种类型。根据你项目和团队架构的不同,每一种代码审查类型都有它特有的优缺点。我们可以在一个很高的层面可以将代码审查归为两大类:正式的代码审查(formal code review)和轻量级的代码审查(light weight code review)。
- 正式的代码审查:正式的代码审查是基于正式的开发流程。其中最流行的实践是范根检查法(Fagan inspection)。它为试图寻找代码的缺陷提供了一种非常结构化的流程,并且,它还可以用于发现规范(specifications)中的或者设计中的缺陷。范根检查法由6个步骤组成:计划(Planning),概述(Overview),准备(Preparation),召开检查会议(Inspection Meeting),重做(Rework),和追查(Follow-up)。基本的思想是:预先制定好每一个步骤所需要达到的输出要求。接下来,当进行到某个过程时,你检查其现在的输出,并与之前制定的理想输出要求做比较。然后,你由此来决定,是否进入下一个步骤,或者仍需在当前步骤继续工作。
- 轻量级的代码审查:如今,轻量级的代码审查在开发团队中很常用。可以将轻量级的代码审查细分为如下不同的子类
-
结对编程:结对编程(英语:Pair programming)是一种敏捷软件开发的方法,两个程序员在一个计算机上共同工作。一个人输入代码,而另一个人审查他输入的每一行代码。输入代码的人称作驾驶员,审查代码的人称作观察员(或导航员)。两个程序员经常互换角色。在结对编程中,观察员同时考虑工作的战略性方向,提出改进的意见,或将来可能出现的问题以便处理。这样使得驾驶者可以集中全部注意力在完成当前任务的“战术”方面。观察员当作安全网和指南。结对编程对开发程序有很多好处。比如增加纪律性,写出更好的代码等。
任务2:两两自由结对,对结对方《实验二 软件工程个人项目》的项目成果进行评价
(1)对项目博文作业进行阅读并进行评论,评论要点包括:博文结构、博文内容、博文结构与PSP中“任务内容”列的关系、PSP中“计划共完成需要的时间”与“实际完成需要的时间”两列数据的差异化分析与原因探究,将以上评论内容发布到博客评论区。
- 结对方博客作业链接
https://www.cnblogs.com/ybp7/p/14655340.html - 结对方GitHub项目仓库链接
https://github.com/Y7-ybp/D-0-1-KP - 符合(1)要求的评论
![]()

(2)克隆结对方项目源码到本地机器,阅读并测试运行代码,参照《现代软件工程—构建之法》4.4.3节核查表复审同伴项目代码并记录。
-
克隆结对方项目源码到本地机器
![]()
-
阅读并测试运行代码
![]()
复审同伴项目代码核查表
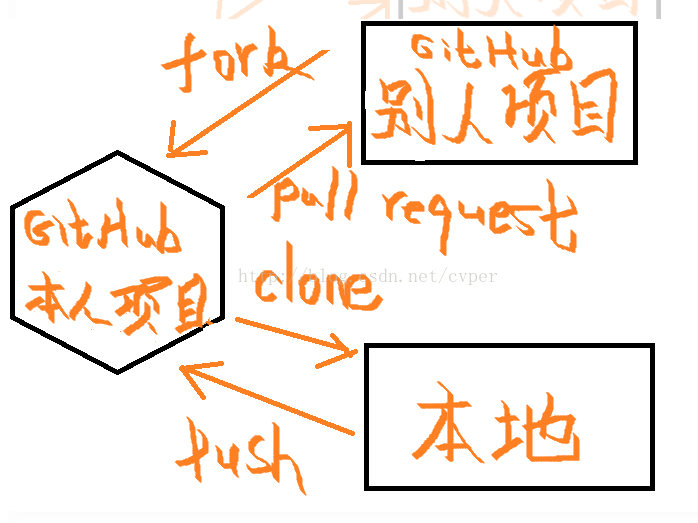
依据复审结果尝试利用GitHub的Fork、Clone、Push、Pull request、Merge pull request等操作对同伴个人项目仓库的源码进行合作修改。
| 操作 | 解释 |
|---|---|
| Fork | 从别人发布的项目上复制一个过来,相当于一个分支;项目复制到自己的个GitHub中,于是本地就有了一个仓库,假设名字为A |
| Clone | 从自己的GitHub上把fork过来的复制到本地,这样本地就有了一个项目A1 |
| Push | 当你在A1中进行修改进行开发后,最后同步到你的GitHub上的仓库 中 |
| Pull request | 你把自己GitHub中的已经修改的内容申请同步到最初那个开发者的项目中 |
简单图示说明如下:
代码复审的核查表
项目开发者:常祺
项目复审者:余宝鹏
概要部分
代码符合需求和规格说明么?
代码符合部分需求,部分功能未能实现;缺少代码规格说明。
代码设计是否考虑周全?
设计过程中实现了部分功能,考虑周全但是未能全部实现其需求。
代码可读性如何?
代码可读性良好,注释较为充分。
代码容易维护么?
代码容易维护,实现代码比较简单,维护较为便利。
代码的每一行都执行并检查过了吗?
代码的每一行进行了检查并且顺利执行。
设计规范部分
设计是否遵从已知的设计模式或项目中常用的模式?
设计遵从软件项目中常用的PSP,设计过程严格按其执行。
有没有硬编码或字符串/数字等存在?
没有。
代码有没有依赖于某一平台,是否会影响将来的移植(如Win32到Win64)?
不依赖于某一平台,不影响将来的移植。
开发者新写的代码能否用已有的Library/SDK/Framework中的功能实现?在本项目中是否存在类似的功能可以调用而不用全部重新实现?
部分代码可以用已有的Library/SDK/Framework中的功能实现,在本项目中存在类似的功能可以调用而不用全部重新实现。
代码规范部分
修改的部分符合代码标准和风格么?
符合,在修改代码的过程中严格按照代码标准和风格修改。
具体代码部分
有没有对错误进行处理?对于调用的外部函数,是否检查了返回值或处理了异常?
在审查过程中,对错误代码进行了处理,对于调用的异常函数,也对其进行了调试。
参数传递有无错误,字符串的长度是字节的长度还是字符(可能是单/双字节)的长度,是以0开始计数还是以1开始计数?
参数传递没有错误。
数据结构中有没有用不到的元素?
数据结构中没有用不到的元素。
效能
代码的效能(Performance)如何?最坏的情况是怎样的?
代码实现了少部分的功能,但是实现部分效能良好。
代码中,特别是循环中是否有明显可优化的部分(C++中反复创建类,C#中string的操作是否能用String Builder来优化)?
在审查中,发现了循环里可优化的部分并将其进行了优化。
对于系统和网络的调用是否会超时?如何处理?
在实验过程中未出现超时情况。
可读性
代码可读性如何?有没有足够的注释?
代码可读性良好,注释较为充分。
可测试性
代码是否需要更新或创建新的单元测试?针对特定领域的开发(如数据库、网页、多线程等),可以整理专门的核查表。
在今后的学习过程中,需要继续实现未实现的功能,补充代码。
任务3:采用两人结对编程方式,设计开发一款D{0-1}KP 实例数据集算法实验平台,使之具有以下功能
(1)平台基础功能:实验二 任务3;
(2)D{0-1}KP 实例数据集需存储在数据库;
(3)平台可动态嵌入任何一个有效的D{0-1}KP 实例求解算法,并保存算法实验日志数据;
(4)人机交互界面要求为GUI界面(WEB页面、APP页面都可);
(5)查阅资料,设计遗传算法求解D{0-1}KP,并利用此算法测试要求(3);
(6)附加功能:除(1)-(5)外的任意有效平台功能实现。
-
软件功能要求
- 算法要求:动态规划算法、回溯算法
- 程序要求:查阅相关资料,设计一个采用动态规划算法、回溯算法求解D{0-1}背包问题的程序
- 技术要求:需要掌握动态规划算法和回溯算法,要对0-1背包问题熟练掌握,要学会数据可视化技术以及python的切片,保存数据到文本等操作
- 语言要求:项目未规定语言,所以在解决过程中可使用学过的编程语言。项目要求对数据进行读取以及数据可视化,故初步设想使用python语言实现。
-
软件需求分析
- 1.读取文件的数据并处理数据:在读取文件的时候有去除掉多余的数据,并将读出的结果分别存在多个数组Array List的对象中;然后将这些Array List对象进行切割并输出在另一个文件中
- 2.生成散点图:将文件中的点对读出来后,用java的swing来画出散点图
- 3.动态规划:动态规划法是一种通用的算法设计技术用来求解多阶段决策最优化问题。其设计思想如下:
- 划分子问题:将原有的问题划分为若干个个子问题
- 确定动态规划函数,将子问题之间的重叠关系找到子问题满足递推关系式即动态规划函数,这是关键
- 填写表格:设计表格,以自底向上的方式计算各个子问题的解并填表,实现动态规划过程
- 4.回溯法: 回溯法在包含问题的所有可能解的解空间树中,从根节点出发,按照深度优先的策略进行搜素,对于解空间树的某个结点,如果该结点满足问题的约束条件,则进入该子树进行搜素,否则将以该结点为根节点的子树进行搜素
- 5.对程序进行调试
-
软件功能设计
- 1.可正确读入实验数据文件的有效D{0-1}KP数据;
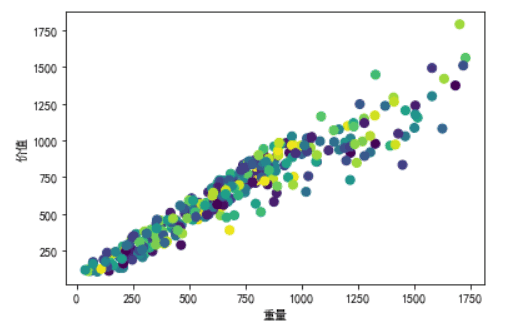
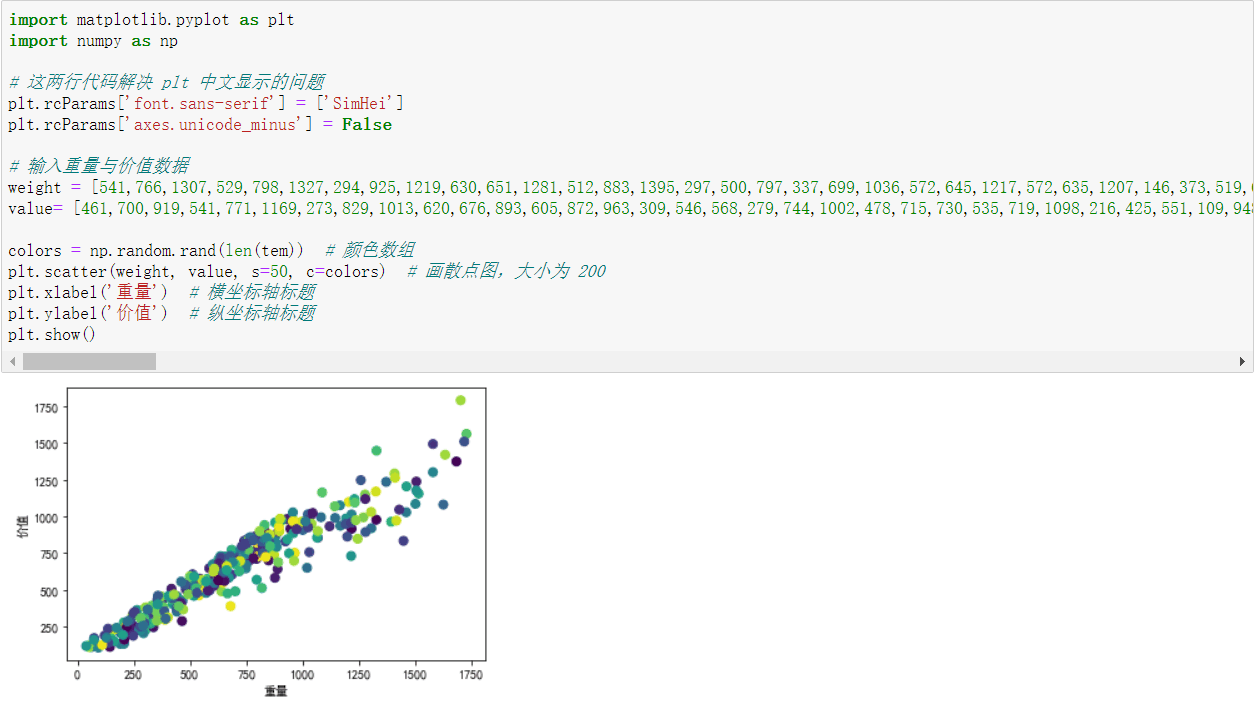
- 2.能够绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图;
- 3.能够对一组D{0-1}KP 数据按项集第三项的价值:重量比进行非递增排序;
- 4.用户能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间(以秒为单位);
- 5.任意一组D{0-1}KP数据的最优解、求解时间和解向量可保存为txt文件或导出 EXCEL文件。
-
程序运行
-
读取文件
public class read { public static void main(String arg[]) { try { String encoding = "UTF-8"; // 字符编码GBK,GB2312(可解决中文乱码问题 ) File file = new File("D:\\shuju\\111.txt"); if (file.isFile() && file.exists()) { InputStreamReader read = new InputStreamReader(new FileInputStream(file), encoding); BufferedReader bufferedReader = new BufferedReader(read); String lineTXT = null; String allNumString = ""; int[] array = null; while ((lineTXT = bufferedReader.readLine()) != null) { // 读出的每一行 System.out.println(lineTXT.toString().trim()); allNumString += lineTXT+","; } if(allNumString != null && !"".equals(allNumString)) { String[] numbers = allNumString.split(","); array = new int[numbers.length]; for (int i = 0; i < numbers.length; i++) { array[i] = Integer.parseInt(numbers[i]); } } read.close(); } else { System.out.println("找不到指定的文件!"); } } catch (Exception e) { System.out.println("读取文件内容操作出错"); e.printStackTrace(); } } } -
重量-价值散点图
![]()
-
GUI界面
![]()
-
遗传算法
##评估函数 # x(i)取值为1表示被选中,取值为0表示未被选中 # w(i)表示各个分量的重量,v(i)表示各个分量的价值,w表示最大承受重量 def fitness(C,N,n,W,V,w): S = []##用于存储被选中的下标 F = []## 用于存放当前该个体的最大价值 for i in range(N): s = [] h = 0 # 重量 f = 0 # 价值 for j in range(n): if C[i][j]==1: if h+W[j]<=w: h=h+W[j] f = f+V[j] s.append(j) S.append(s) F.append(f) return S,F##适应值函数,B位返回的种族的基因下标,y为返回的最大值 def best_x(F,S,N): y = 0 x = 0 B = [0]*N for i in range(N): if y<F[i]: x = i y = F[x] B = S[x] return B,y
-
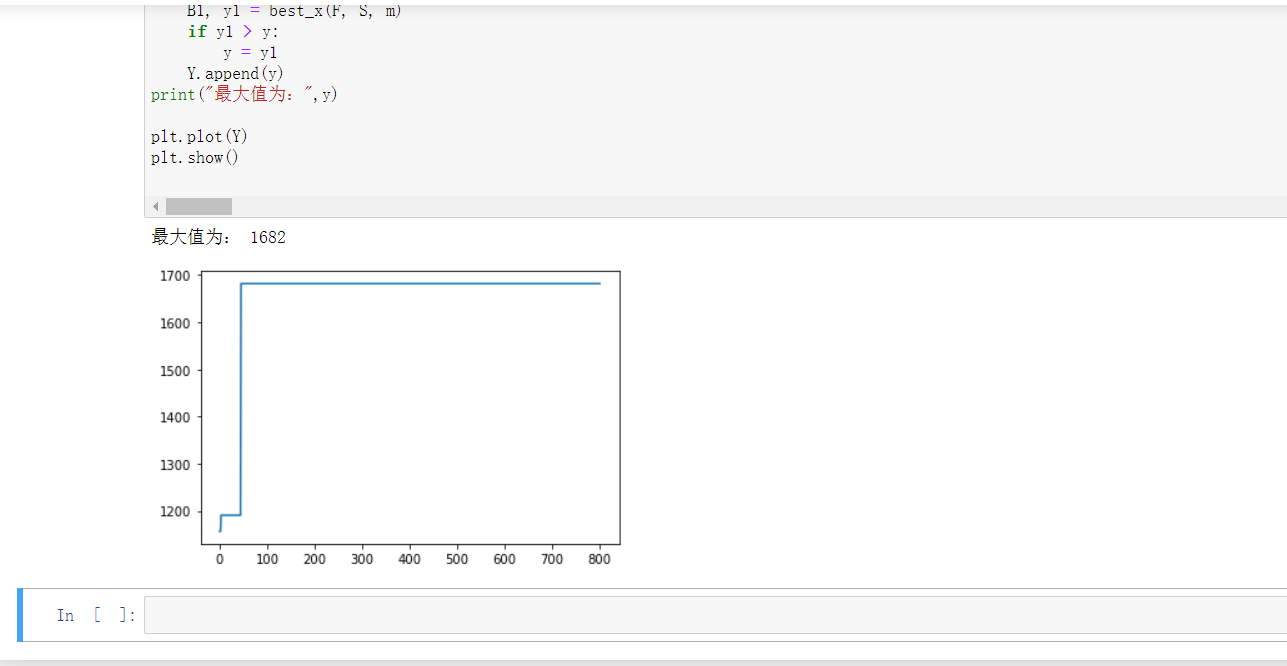
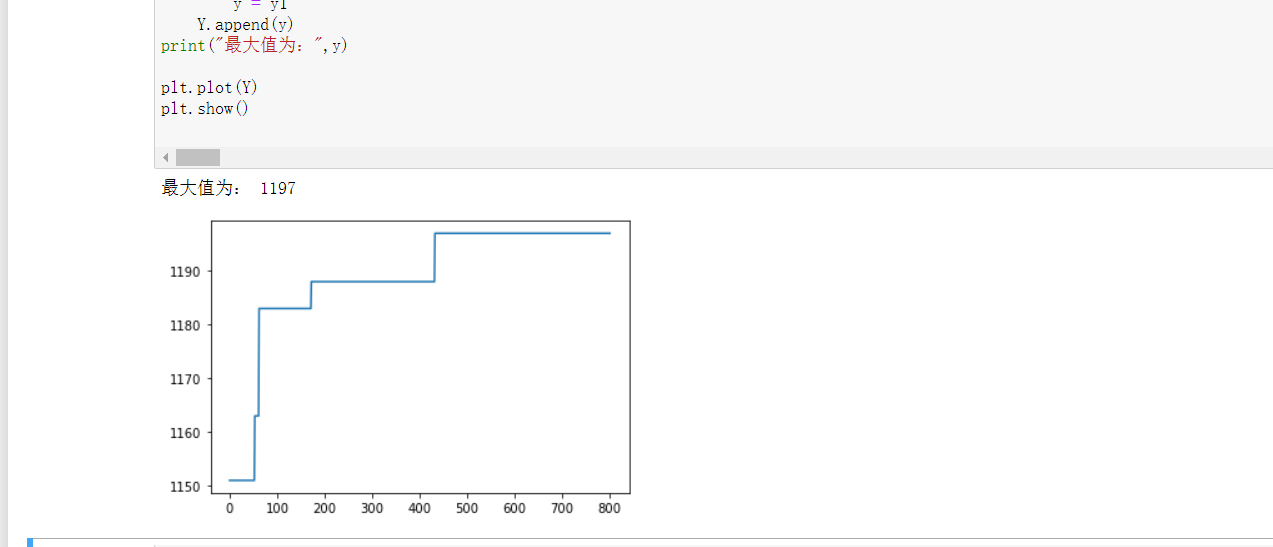
- 数据库的代码:
# connect_db:连接数据库,并操作数据库
import pymysql
class OperationMysql:
数据库SQL相关操作
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost","testuser","test123","TESTDB" )
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
cursor.execute("SELECT VERSION()")
"""
def __init__(self):
# 创建一个连接数据库的对象
self.conn = pymysql.connect(
host='127.0.0.1', # 连接的数据库服务器主机名
port=3306, # 数据库端口号
user='test', # 数据库登录用户名
passwd='111111',
db='test', # 数据库名称
charset='utf8', # 连接编码
cursorclass=pymysql.cursors.DictCursor
)
# 使用cursor()方法创建一个游标对象,用于操作数据库
self.cur = self.conn.cursor()
# 查询一条数据
def search_one(self, sql):
self.cur.execute(sql)
result = self.cur.fetchone() # 使用 fetchone()方法获取单条数据.只显示一行结果
# result = self.cur.fetchall() # 显示所有结果
return result
# 更新SQL
def updata_one(self, sql):
try:
self.cur.execute(sql) # 执行sql
self.conn.commit() # 增删改操作完数据库后,需要执行提交操作
except:
# 发生错误时回滚
self.conn.rollback()
self.conn.close() # 记得关闭数据库连接
# 插入SQL
def insert_one(self, sql):
try:
self.cur.execute(sql) # 执行sql
self.conn.commit() # 增删改操作完数据库后,需要执行提交操作
except:
# 发生错误时回滚
self.conn.rollback()
self.conn.close()
# 删除sql
def delete_one(self, sql):
try:
self.cur.execute(sql) # 执行sql
self.conn.commit() # 增删改操作完数据库后,需要执行提交操作
except:
# 发生错误时回滚
self.conn.rollback()
self.conn.close()
if __name__ == '__main__':
op_mysql = OperationMysql()
res = op_mysql.search_one("SELECT * from odi_order WHERE order_no='12222'")
print(res)
-
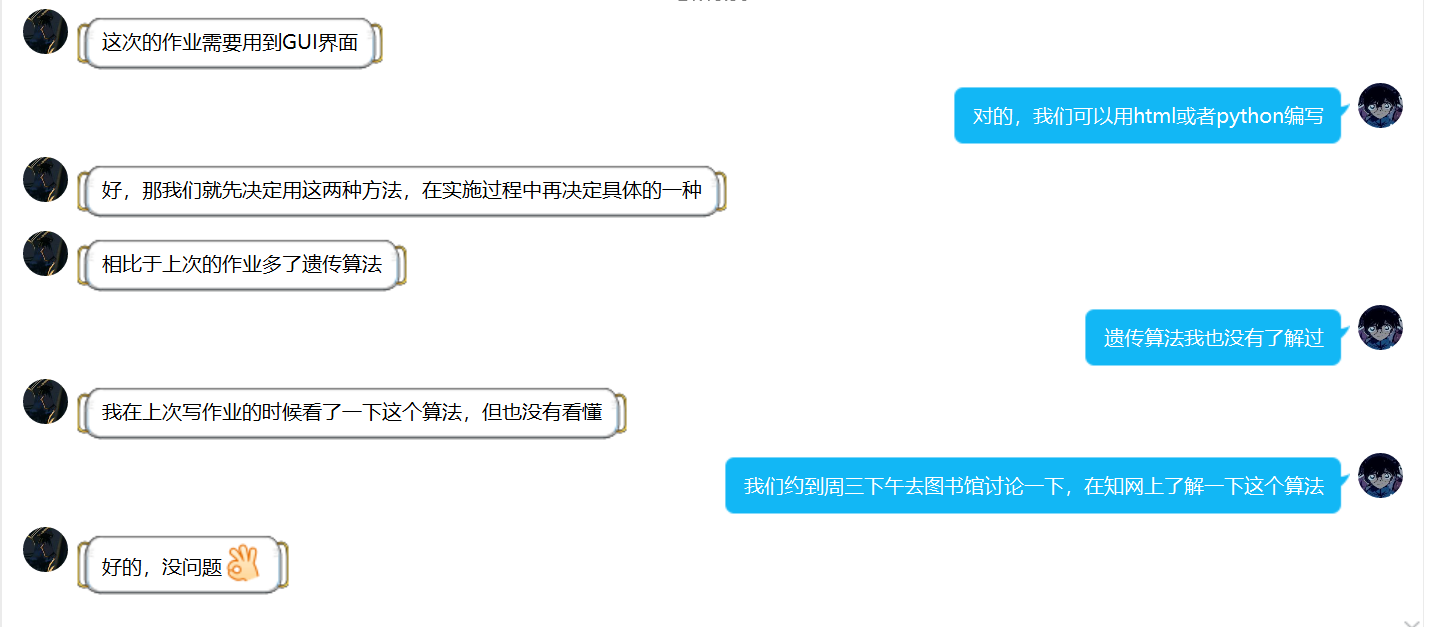
结对过程描述
![]()
- 在软件开发初期,我们互相分配了任务,计划了此次开发的一些事宜,讨论了界面的编写;
- 在软件开发过程中,我们对于困难问题进行了讨论,对于《现代软件工程—构建之法》的第3-4章内容进行了阅读和理解;
- 在软件开发结束阶段,我们对于软件进行了再次检验,并且表达了对彼此的感谢以及鼓励。
![]()
-
PSP展示
PSP2.1 任务内容 计划共完成需要的时间(min) 实际完成需要的时间(min) Planning 计划 15 13 Estimate 估计这个任务需要多少时间,并规划大致工作步骤 15 13 Development 开发 235 277 Analysis 需求分析(包括学习新技术) 50 60 Design Spec 生成设计文档 25 30 Design Review 设计复审(和同事审核设计文档) 10 15 Coding Standard 代码规范(为目前的开发制定合适的规范) 10 10 Design 具体设计 30 35 Coding 具体编码 60 70 Code Review 代码复审 20 22 Test 测试(自我测试,修改代码,提交修改) 30 35 Reporting 报告 40 34 Test Report 测试报告 15 12 Size Measurement 计算工作量 10 12 Postmortem & Process Improvement Plan 事后总结,并提出过程改进计划 15 10 -
小结感受
- 通过本次软件工程结对项目,我对于“合作”有了真正的认识。在软件开发过程中,我们各司其职,分工明确,这样使得我们软件开发的过程顺利推进,这也恰巧说明了两人合作能够带来1+1>2的效果。
- 在结对编程的过程中,我们双方也在互相学习。结对编程的过程就是一个自我认识以及学习的过程;
- 在实验过程中,我们也遇到了很多困难。比如代码出现bug很难调试过来,有些算法原理比较难。但我们彼此鼓励,通过查找资料,请教别人最终也将其解决;
- 在遗传算法这一部分,我们遇到了很大的困难。因为这个算法对于我们来说是一个全新的算法,我们通过查找资料,阅读文献慢慢地了解了它的算法思想,然后我们对于代码进行了研究,最终成功解决这一任务;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号