Python 多线程
实现多线程
直接调用
from threading import Thread
import time
def func(n):
# 子线程要做的事情
time.sleep(1)
print(n)
for i in range(10):
t = Thread(target=func,args=(i,))# 实例化线程,并且传递参数
t.start()# 启动线程
继承
from threading import Thread
import time
class MyThread(Thread):
def __init__(self, arg):
super().__init__()
self.arg = arg
def run(self):
time.sleep(1)
print(self.arg)
for i in range(10):
t = MyThread(i)
t.start()
多线程的一些方法
显示当前线程信息
from threading import Thread,current_thread
def func(n):
print(n,current_thread())
if __name__ == '__main__':
print(current_thread())# 显示当前线程的基本信息,包括名字和线程id
Thread(target=func,args=(1,)).start()
获取线程ID
from threading import Thread,get_ident
def func(n):
print(n,get_ident())
if __name__ == '__main__':
print(get_ident())# 显示当前线程的线程id
Thread(target=func,args=(1,)).start()
获取当前活跃线程数
from threading import Thread,active_count,current_thread
import time
def func(n):
time.sleep(0.5)# 加入0.5s的等待时间是为了能够保证线程活跃
print(n,current_thread())
if __name__ == '__main__':
print(current_thread())
for i in range(10):
Thread(target=func,args=(i,)).start()
print("当前活跃线程数",active_count())
# 显示当前活跃的线程
# 结果为 11
# 因为除了10个子线程外还有主线程
获取全部线程对象
from threading import Thread,active_count,current_thread,enumerate
import time
def func(n):
time.sleep(0.5)# 加入0.5s的等待时间是为了能够保证线程活跃
print(n,current_thread())
if __name__ == '__main__':
print(current_thread())
for i in range(10):
Thread(target=func,args=(i,)).start()
print("当前活跃线程数",active_count())
print(enumerate())
# 结果:[<_MainThread(MainThread, started 30196)>, <Thread(Thread-1, started 31648)>, <Thread(Thread-2, started 30472)>, <Thread(Thread-3, started 31392)>, <Thread(Thread-4, started 15660)>, <Thread(Thread-5, started 18228)>, <Thread(Thread-6, started 15860)>, <Thread(Thread-7, started 30044)>, <Thread(Thread-8, started 27632)>, <Thread(Thread-9, started 7008)>, <Thread(Thread-10, started 1144)>]
# 返回的是一个包含所有线程对象的列表
守护线程
- 守护线程会等待所有子线程结束后才结束,这和守护进程不同
from threading import Thread
import time
def func1():
while True:
print("*"*10)
time.sleep(1)
def func2():
print("子进程2")
time.sleep(5)
print("子进程2结束")
if __name__ == '__main__':
t1 = Thread(target=func1)
t1.daemon = True #设置t1为守护线程
t1.start()
t2 = Thread(target=func2)
t2.start()
print("主进程结束")
锁
锁的作用
- 保证数据的安全性
当没有锁的时候会出现的数据安全问题
from threading import Thread
import time
def func():
global n
temp = n
time.sleep(0.2)
n = temp - 1
if __name__ == '__main__':
n = 10
t_list = []
for i in range(10):
t = Thread(target=func)
t.start()
t_list.append(t)
for t in t_list:t.join()
print(n)
在上面这个例子中,程序运行的结果应该是0但是实际的运行结果却是9
造成这种结果的原因是因为这十个线程同时取得了temp=10,然后同时对每个线程取得的temp减一,因此每个线程得到的n的结果都是9,所以最后得到的结果n=9
为了解决这种因为多个线程同时操作一个数据造成的数据不安全的问题引入了锁这个概念
互斥锁
对上一个例子进行修改完善
from threading import Thread,Lock
import time
l = Lock() # 定义一个锁
def func():
global n
l.acquire()# 取得钥匙
temp = n
time.sleep(0.2)
n = temp - 1
l.release()# 还钥匙
if __name__ == '__main__':
n = 10
t_list = []
for i in range(10):
t = Thread(target=func)
t.start()
t_list.append(t)
for t in t_list:t.join()
print(n)
死锁问题
虽然互斥锁会解决数据安全的问题,但是互斥锁会出现死锁问题
一组数据需要两把钥匙才能得到,在程序执行时可能会出现两个线程分别得到了一把钥匙,然后这两个线程都想得到另一把钥匙,但是又不想放弃手里的钥匙,因此两个线程都无法得到数据,这就是死锁问题
死锁问题示例
from threading import Thread,Lock
import time
l1 = Lock()
l2 = Lock()
def eat1(s):
l1.acquire()
print("%s拿到了叉子"%s)
l2.acquire()
print("%s拿到了面"%s)
print("%s吃面"%s)
l2.release()
l1.release()
def eat2(s):
l2.acquire()
print("%s拿到了面"%s)
time.sleep(1)
l1.acquire()
print("%s拿到了叉子"%s)
print("%s吃面" % s)
l2.release()
l1.release()
Thread(target=eat1,args=("a",)).start()
Thread(target=eat2,args=("b",)).start()
Thread(target=eat1,args=("c",)).start()
Thread(target=eat2,args=("d",)).start()
结果
a拿到了叉子
a拿到了面
a吃面
b拿到了面
c拿到了叉子
递归锁
递归锁可以很好的解决死锁问题
递归锁可以理解为一个钥匙串,这个钥匙串是一体的,要拿其中一把钥匙就需要把整个钥匙串拿走,因此就不会出现不同进程分别拿走钥匙的一部分而造成的死锁问题的现象
递归锁解决死锁问题
from threading import Thread,RLock
import time
l1 = l2 = RLock() # 一个钥匙串上的两把钥匙
def eat1(s):
l1.acquire()
print("%s拿到了叉子"%s)
l2.acquire()
print("%s拿到了面"%s)
print("%s吃面"%s)
l2.release()
l1.release()
def eat2(s):
l2.acquire()
print("%s拿到了面"%s)
time.sleep(1)
l1.acquire()
print("%s拿到了叉子"%s)
print("%s吃面" % s)
l2.release()
l1.release()
Thread(target=eat1,args=("a",)).start()
Thread(target=eat2,args=("b",)).start()
Thread(target=eat1,args=("c",)).start()
Thread(target=eat2,args=("d",)).start()
结果
a拿到了叉子
a拿到了面
a吃面
b拿到了面
b拿到了叉子
b吃面
c拿到了叉子
c拿到了面
c吃面
d拿到了面
d拿到了叉子
d吃面
信号量
假如一个酒吧只有4把椅子,则每次只能有4个人在酒吧里喝酒,只有其中有人走出酒吧才会有空余的位置来让其他人进来喝酒
信号量就相当于酒吧门口的服务员,如果人满了他会让后来的人等待,如果有一个人出来,他就会放一个人进去
同样的信号量也可以理解为锁,只不过这把锁有多把钥匙,每来一个人拿走一把钥匙,当所有钥匙都被拿走后,后来的人就只能等待前面的人归还钥匙
信号量示例
from threading import Thread,Semaphore
import time,random
sem = Semaphore(4)
def func(i):
sem.acquire()# 拿到椅子
print(str(i)+"进入酒吧")
time.sleep(random.randint(1,3))# 随机在酒吧内待1-3秒
sem.release()# 归还椅子
print(str(i)+"走出酒吧")
if __name__ == '__main__':
for i in range(10):
Thread(target=func,args=(i,)).start()
结果
0进入酒吧
1进入酒吧
2进入酒吧
3进入酒吧
3走出酒吧
4进入酒吧
1走出酒吧
5进入酒吧
2走出酒吧
6进入酒吧
4走出酒吧
7进入酒吧
0走出酒吧
8进入酒吧
5走出酒吧
9进入酒吧
8走出酒吧
9走出酒吧
6走出酒吧
7走出酒吧
事件
事件有两种状态True和False,这两种状态用来控制wait()方法是否阻塞,False为阻塞,True为通行
set()方法将事件的状态设置为True
clear()方法将事件的状态设置为False
事件的默认状态为False
数据库连接模型
from threading import Thread,Event
import time,random
def connet_db(e):
time.sleep(random.randint(1,5))
e.set()
pass
def check_web(e):
count = 0
while count < 3:
e.wait(1)# 设置超时时间
if e.is_set() == True:
print("连接数据库成功")
break
else:
count += 1
print("第%s次连接失败"% count)
else:
raise TimeoutError("数据库连接超时")
pass
if __name__ == '__main__':
e = Event()
Thread(target=connet_db,args=(e,)).start()
Thread(target=check_web,args=(e,)).start()
红路灯模型
from threading import Thread,Event
import time,random
def light(e):
while True:
e.set()
print("绿灯")
time.sleep(3)
e.clear()
print("红灯")
time.sleep(3)
def car(e,c):
e.wait()
print("车%s通过"%c)
if __name__ == '__main__':
e = Event()
l = Thread(target=light,args=(e,))
l.daemon = True
l.start()
for i in range(20):
t = Thread(target=car,args=(e,i))
t.start()
time.sleep(random.random())
定时器
下面的例子可以实现定时开启一个线程,可以利用这个功能来实现定时同步时间之类的功能
定时器开启的线程是异步的
import threading,time
def func1(n):
'''
:param n:执行次数
:return:
'''
if n<=0:
return
t = threading.Timer(5, func1, (n-1,))
t.start()
print('当前线程数为{}'.format(threading.activeCount()))
print(n)
print('Do something')
time.sleep(10)
print(t.getName(),"执行完毕")
func1(5)
条件
from threading import Thread,Condition
import time
con = Condition()
num = 0
# 生产者
def fun1():
# 锁定线程
global num
while True:
con.acquire()
print("开始添加!!!")
num += 1
print("火锅里面鱼丸个数:%s" % str(num))
time.sleep(1)
if num >= 5:
print("火锅里面里面鱼丸数量已经到达5个,无法添加了!")
# 唤醒等待的线程
con.notify() # 唤醒小伙伴开吃啦
# 等待通知
con.wait()
# 释放锁
con.release()
# 消费者
def fun2():
global num
while True:
con.acquire()
print("开始吃啦!!!")
num -= 1
print("火锅里面剩余鱼丸数量:%s" % str(num))
time.sleep(2)
if num <= 0:
print("锅底没货了,赶紧加鱼丸吧!")
con.notify() # 唤醒其它线程
# 等待通知
con.wait()
con.release()
p = Thread(target=fun1)
c = Thread(target=fun2)
p.start()
c.start()
队列
- 队列自带了数据锁,无须自行保证数据安全问题
- 查看队列的使用方法: Python queue
线程池
from concurrent.futures.thread import ThreadPoolExecutor
import time
# 在pycharm中 from concurrent.futures import ThreadPoolExecutor 没有提示
# 查看源码发现from concurrent.futures import ThreadPoolExecutor只是调用了from concurrent.futures.thread import ThreadPoolExecutor这条语句
# 所以直接调用from concurrent.futures.thread import ThreadPoolExecutor
def func(n):
n = n*n
time.sleep(1)
return n
def call_back(m):
print("回调函数:",m.result())
if __name__ == '__main__':
t_pool = ThreadPoolExecutor(max_workers=5)# 最大为CPU个数的5倍
t_l = []
for i in range(10):
# t_pool.map(func,1) # 只执行线程不返回结果
t = t_pool.submit(func, i)
t_l.append(t)
#t.add_done_callback(call_back)# 添加回调函数
#t_pool.shutdown() # 线程池不再接收任务,等待所有结果计算完,相当于close + join
for t in t_l:print("***",t.result())# 没有shutdown的话,打印结果是异步的,并且结果是顺序的
多进程与多线程的效率对比
from multiprocessing import Process
from threading import Thread
import time
def func(i):
i + 1
if __name__ == '__main__':
start = time.time()
t_list = []
for i in range(100):
t = Thread(target=func,args=(i,))
t.start()
t_list.append(t)
for t in t_list:t.join()
end = time.time()
t1 = end - start
p_list = []
start = time.time()
for i in range(100):
p = Process(target=func,args=(i,))
p.start()
p_list.append(p)
for p in p_list:p.join()
end = time.time()
t2 = end - start
print("多线程时间:", t1)
print("多进程时间:", t2)
我的电脑上的结果
多线程时间: 0.01994609832763672
多进程时间: 2.7516415119171143
特点
- 全局变量在多个线程之间共享
- 每个线程都有直接的数据栈,各个线程之间的数据不共享
- 开启一个线程消耗的资源远小于开启一个进程
- 每个进程内至少含有一个线程
- 线程是系统调度的最小单位
- 进程是内存分配的最小单位
- 真正被CPU执行的是线程
全局解释器锁(GIL)
数据安全性问题
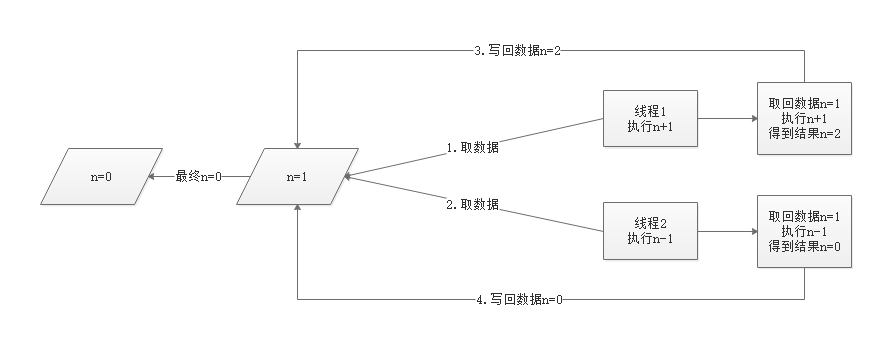
当两个线程同时取一个数据时就会出现上图中的问题,得到错误的执行结果
全局解释器锁是什么
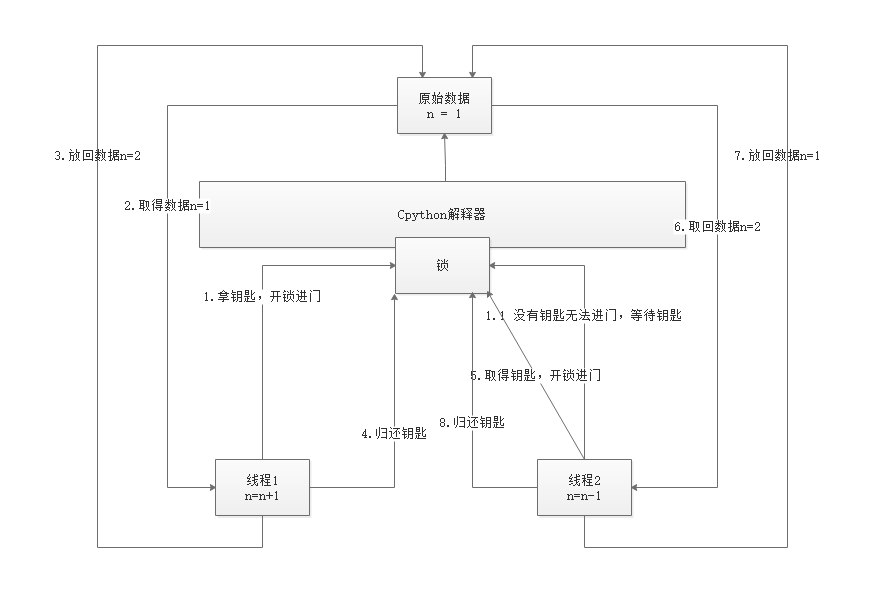
为了解决数据安全性问题,CPython解释器设置了锁,这个锁在同一时间只允许一个线程通过
这个锁就是全局解释器锁(GIL)
全局解释器锁会造成的问题
- 同一时间只允许一个线程通过,降低了执行效率,这也就是为什么说Python多线程形同虚设的原因
- 全局解释器锁锁的是线程而不是数据
- 这个问题仅存在于CPython解释器中,JPython中就没有
- 到目前为止,全局解释器锁还没有更好的替代品
既然有全局解释器锁的限制那python的多线程就没用了吗?
程序可以分为高CPU类和高IO类
- 高CUP:连续的大量的计算的程序,例如阿尔法GO这种在下棋是需要连续大量的计算才能得到结果的程序,此类程序时间损耗在CPU计算上,全局解释器锁对这一类程序限制较大,此类程序在python中可以使用多进程来解决
- 高IO: 连续进行文件读取,网页访问,数据库读写等操作的程序,例如爬虫,web请求处理,数据库存取等,此类程序时间损耗在文件的存取上,全局解释器锁对这一类程序限制较小

 浙公网安备 33010602011771号
浙公网安备 33010602011771号