

【数据结构】数组、稀疏矩阵的操作、广义表
数组
数组:按一定格式排列起来的,具有相同类型的数据元素的集合
一维数组:若线性表中的数据元素为非结构的简单元素,则称为一维数组
二维数组:若一维数组中的数据元素又是一维数组结构,则称为二维数组
数组基本操作:一般来说,只有存取和修改这两种操作
数组一般采用顺序存储结构
二维数组的两种顺序存储方式
- 以行序为主序(C语言、Java、PASCAL)

- 以列序为主序(FORTRAN)
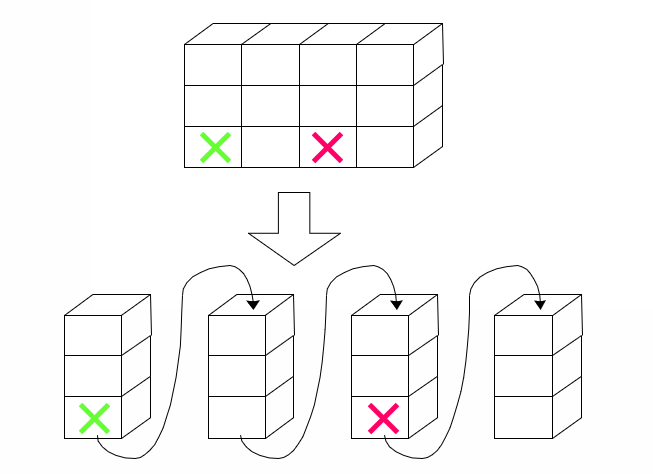
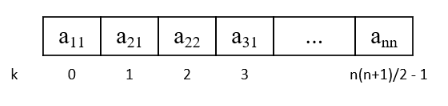
地址计算:
对于一维数组,有
其中
a 为数组的首地址
i 为一维数组的下标
l 为数组中每个元素的大小
对于二维数组(行序优先),有
其中
a 为数组的首地址
n 为数组中每行的元素个数
l 为数组中每个元素的大小
对于三维数组(页、行、列的存放方式),有
其中
a 为数组的首地址
l 为数组中每个元素的大小
矩阵
矩阵:一个由

矩阵的常规存储:将矩阵描述为一个二维数组
不适宜常规存储的矩阵的特点:
- 有很多值相同的元素,且呈某种规律分布
- 零元素多
矩阵的压缩存储:为多个相同的非零元素只分配一个存储空间,对零元素不分配空间
特殊矩阵的压缩存储
什么是压缩存储?
若多个数据元素的值都相同,则只分配一个元素值的存储空间,且零元素不占存储空间
特殊矩阵有哪些?
对称矩阵、对角矩阵、三角矩阵、稀疏矩阵等
对称矩阵

特点
在
存储方法
只存储下(上)三角(包括主对角线)的数据元素
对称矩阵的存储结构:
上下三角中的元素数均为:
可以以行序为主序,将元素存放在一个一维数组中
三角矩阵
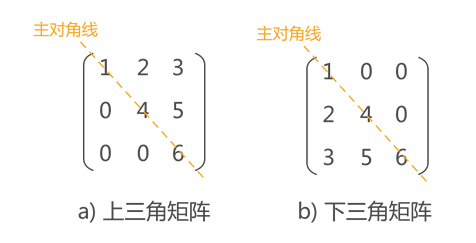
特点
对角线以下(以上)的数据元素全部为常数 c
存储方法
重复的数据元素只占用一个存储空间,共占用
对角矩阵
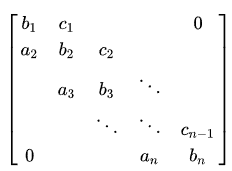
特点
在
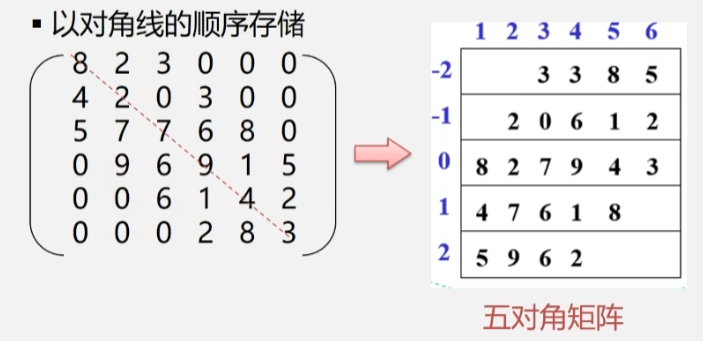
常见的有三对角矩阵、五对角矩阵、七对角矩阵

存储方法
稀疏矩阵
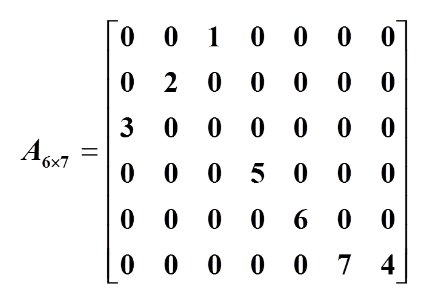
特点
矩阵中非零元素的个数较少(一般小于5%)
存储方法
存各非零元的值、行列位置和矩阵的行列数
存储结构
- 顺序存储结构:三元组表
- 链式存储结构:十字链表
表示方式
三元组表
#define MAXSIZE 100 typedef struct TupNode { int row; int col; int data; }Triple; typedef struct TSMatrix { Triple data[MAXSIZE + 1]; int row_size; int col_size; int non_zero_num; }TSMatrix;
Triple:
定义三元组的类型,row 表示数据所在的行号,col 表示数据所在的列号,data 记录矩阵相应位置上的值
TSMatrix(Triple Sparse Matrix):
定义三元组顺序表用来表示稀疏矩阵,表中包括一个三元组数组,该数组每个元素是三元组,还包括了所表示的稀疏矩阵的行与列的大小以及稀疏矩阵中非零元素的个数。
Triple data[MAXSIZE + 1]:三元组数组
row_size:稀疏矩阵行的大小
col_size:稀疏矩阵列的大小
non_zero_num:稀疏矩阵中非零元素的个数
三元组数组的0号位空间可用可不用,如果用的话,一种就是正常的存储矩阵数据,另一种就是用0号位来记录稀疏矩阵行与列的大小和稀疏矩阵中非零元素的个数,如果不用的话,就从数组的1号位开始存储数据。以下代码都是基于不使用数组中的0号位空间
三元组表的优点:便于进行按行序处理的矩阵运算
缺点:若按行序存取某一行中的非零元,则需要从头开始查找
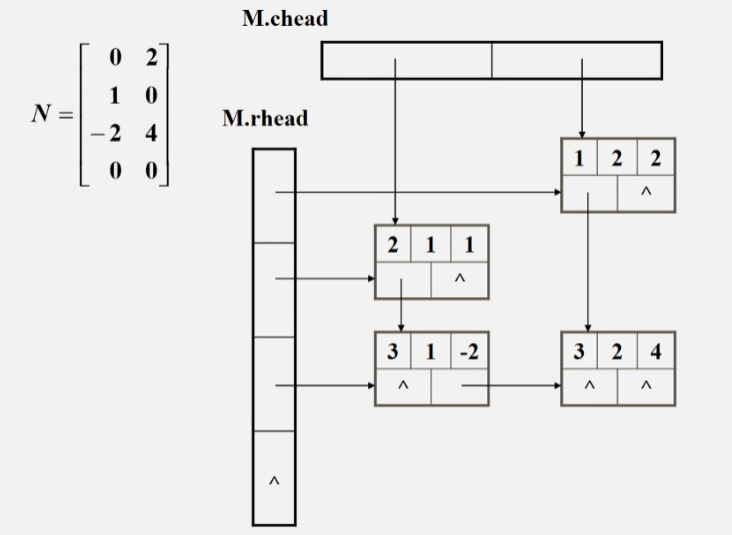
十字链表
typedef struct OLNode { int row, col; int value; struct OLnode* down, * right; }OLNode; typedef struct CrossList { int row_size, col_size; int non_zero_num; OLNode* rhead, * chead; }CrossList;
OLNode:表示矩阵中的每一个非零元
down:用于链接同一列中的下一个非零元素
right:用于链接同一行中的下一个非零元素
CrossList:表示矩阵
rhead:行链表的头指针
chead:列链表的头指针
rhead 和 chead 是一个指针数组的首元素,注意,这里的数组只是形式上的,实际上是由其 down 或 right 指针不断链接而成的一个链表
矩阵的转置
对于一个
矩阵的值的位置发生了改变,原先的行号变成了列号,原先的列号变成了行号

实现思路
三元组顺序表 A 和 B,A 表示转置前的三元组顺序表,B 表示转置后的三元组顺序表,都以行序为主序
- 思路1(先赋值后排序)
-
对于 A 中的每一个三元组,将其行的值赋给 B 中对应三元组中的列,列的值赋给行,数据不变
-
将 B 中的三元组按行序重新排列
- 思路2(先排序后赋值)
对于 A 中的每一个三元组,按照列序,将其行的值赋给 B 中对应三元组中的列,列的值赋给行,数据不变
例如:假设有如下稀疏矩阵 A 和及其转置后的矩阵 B
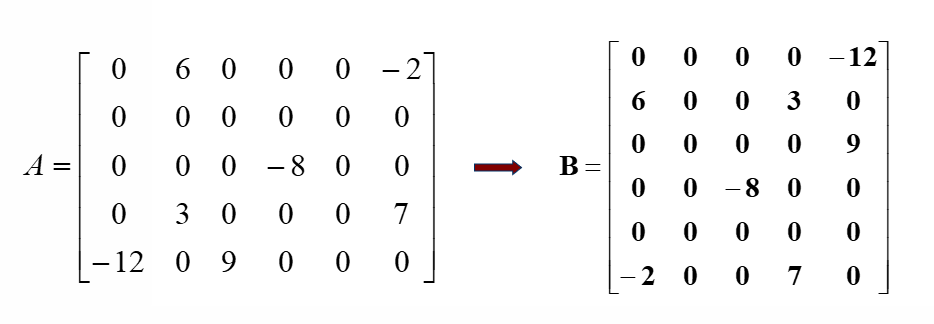
则 A 的三元组表为

思路1的过程为
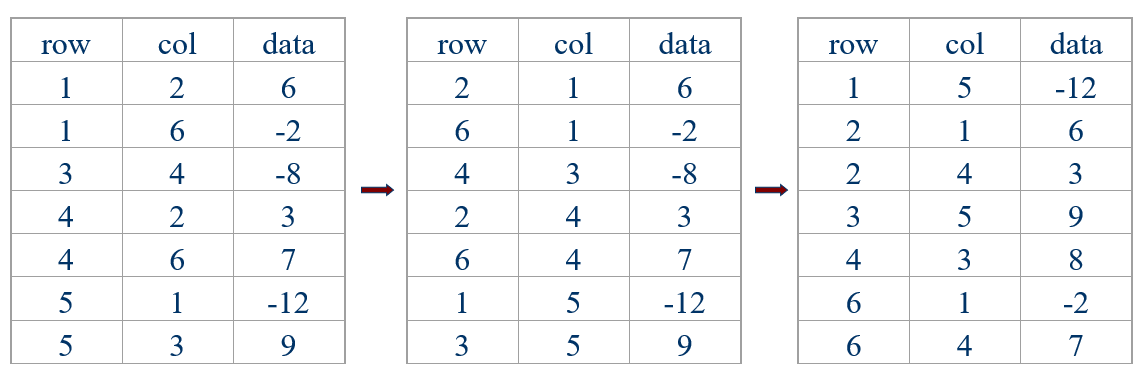
在排序时,只需要关注 row 的大小即可
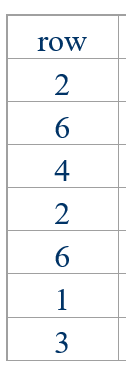
思路2的过程为,按表 A 中的列号,从小到大,依次赋值给表 B,当列号(转置前)相同时,由于转置前的行号是按序的,所以转置后的列号也是按序的
代码实现
思路1
void trans_1(TSMatrix* A, TSMatrix* B) { int i = 0; int j = 0; B->row_size = A->col_size; B->col_size = A->row_size; B->non_zero_num = A->non_zero_num; for (i = 1; i <= A->non_zero_num; i++) { B->data[i].row = A->data[i].col; B->data[i].col = A->data[i].row; B->data[i].data = A->data[i].data; } for (i = 1; i <= B->non_zero_num - 1; i++) { for (j = 1; j <= B->non_zero_num - i; j++) { if (B->data[j].row > B->data[j + 1].row) { swap_TupNode(&(B->data[j]), &(B->data[j + 1])); } } } } void swap_TupNode(TupNode* a, TupNode* b) { TupNode temp; temp.row = a->row; temp.col = a->col; temp.data = a->data; a->row = b->row; a->col = b->col; a->data = b->data; b->row = temp.row; b->col = temp.col; b->data = temp.data; }
当要按行序进行排序时,需要采用有稳定性的排序方法
以上代码中使用的是冒泡排序
for (i = 1; i <= B->non_zero_num - 1; i++) { for (j = 1; j <= B->non_zero_num - i; j++) { if (B->data[j].row > B->data[j + 1].row) { swap_TupNode(&(B->data[j]), &(B->data[j + 1])); } } }
思路2
void trans_2(TSMatrix* A, TSMatrix* B) { int i = 0; int j = 0; int k = 1; B->row_size = A->col_size; B->col_size = A->row_size; B->non_zero_num = A->non_zero_num; for (i = 1; i <= A->col_size; i++) //按原矩阵的列号开始遍历 { for (j = 1; j <= A->non_zero_num; j++) //遍历原矩阵中所有的三元组 { if (A->data[j].col == i) //从列号为1的三元组开始,逐个赋值给转置后的矩阵 { B->data[k].row = A->data[j].col; B->data[k].col = A->data[j].row; B->data[k].data = A->data[j].data; k++; } } } }
时间复杂度
设有
对于思路1的代码
一般情况下, 算法的时间复杂度为
对于思路2的代码
一般情况下,算法的时间复杂度为
所以,矩阵转置算法的时间复杂度为
当 t 和
处于同一数量级的意思是,t 随 m、n 的增大而增大
矩阵的快速转置
实现思路
矩阵的快速转置算法只需要遍历一次原矩阵的三元组表,即可得出转置后矩阵的三元组表
思路如下:
创建数组 number,大小为 B.rowSize+1,不使用数组0号位的空间,记录转置后的矩阵中每行非零元素的个数,即转置前的矩阵中每列非零元素的个数
创建数组 position,大小为B.rowSize+1,不使用数组0号位的空间,记录转置后的矩阵中每行第一个非零元素在表中的位置
两个数组首元素都可以置为0
遍历原矩阵的三元组表,根据三元组的列值与 position 数组,赋值给转置后三元组表中相应位置的三元组,然后更新 position 数组
例如:
假设有如下三元组表及其转置后的三元组表
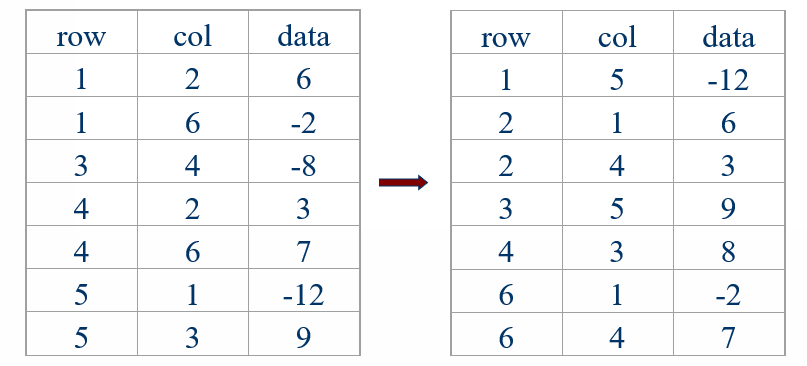
则其 number 和 position 数组为
| i | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| number[i] | 0 | 1 | 2 | 1 | 1 | 0 | 2 |
| position[i] | 0 | 1 | 2 | 4 | 5 | 6 | 6 |
当遍历到第一个三元组时,col 值为2,查找 position 数组,此时 position[2] == 2,于是将第一个三元组的值赋给转置后的三元组表中的2号位,position[2] 的值更新为3
以此类推
代码实现
void quick_trans(TSMatrix* A, TSMatrix* B) { int number[MAXSIZE + 1] = { 0 }; int position[MAXSIZE + 1] = { 0 }; int i = 0; int j = 0; B->row_size = A->col_size; B->col_size = A->row_size; B->non_zero_num = A->non_zero_num; for (i = 1; i <= A->non_zero_num; i++) { int col = A->data[i].col; number[col]++; } position[1] = 1; for (i = 2; i <= A->col_size; i++) { position[i] = position[i - 1] + number[i - 1]; } for (i = 1; i <= A->non_zero_num; i++) { int col = A->data[i].col; int index = position[col]; B->data[index].row = A->data[i].col; B->data[index].col = A->data[i].row; B->data[index].data = A->data[i].data; position[col]++; } }
时间复杂度
设有
则矩阵的快速转置算法的时间复杂度为
矩阵的乘法
理论基础
矩阵 A 为2*3矩阵
矩阵 B 为3*2矩阵
矩阵 C 为结果矩阵
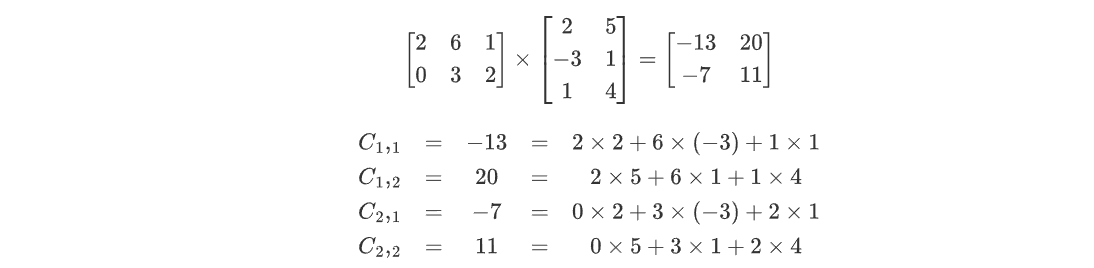
计算过程:A 的逐行各元素乘 B 的逐列各元素
- 矩阵的部分性质
-
A 的列数等于 B 的行数时才可以相乘
-
A 中列数为 n 的元素,只能和 B 中行数为 n 的元素相乘
-
A 中某元素 a 和 B 中某元素 b 相乘时,得到的结果只存于 C 中行数和 a 相同,列数和 b 相同的位置
-
C 的行数等于 A 的行数,C 的列数等于 B 的列数
代码实现
void Mult(TSMatrix* A, TSMatrix* B, TSMatrix* C) { int i = 0; int j = 0; int k = 1; int index = 1; for (i = 1; i <= A->row_size; i++) { for (j = 1; j <= B->col_size; j++) { int sum = 0; for (k = 1; k <= A->col_size; k++) { sum = sum + get_value(A, i, k) * get_value(B, k, j); } if (sum != 0) { C->data[index].row = i; C->data[index].col = j; C->data[index].data = sum; index++; } } } C->row_size = A->row_size; C->col_size = B->col_size; C->non_zero_num = index - 1; } int get_value(TSMatrix* M, int i, int j) { int k = 1; for (k = 1; k <= M->non_zero_num; k++) { if (M->data[k].row == i && M->data[k].col == j) { return M->data[k].data; } } return 0; }
广义表
广义表是由零个或多个元素组成的有限序列,其中每个元素或者是原子,或者是一个广义表
广义表通常记作 GL = (a1, a2, a3, ... ,an)
其中,GL 为表名,n 为表的长度, 每一个 ai 为表的元素
一般用大写字母表示广义表,小写字母表示原子
表头:若 GL 非空(n >= 1),则其第一个元素 a1 就是表头,表头既可以是原子,也可以是子表
表尾:除表头之外其他元素组成的表



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具