

【数据结构】串的表示与模式匹配算法
串
串是内容受限的线性表(栈和队列是操作受限的线性表)
串(string)是零个或多个任意字符组成的有限序列
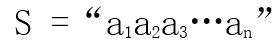
S:串名
a1a2a3 ... an:串值
n:串长
当 n = 0 时,表示空串,空串用
子串:一个串中任意个连续字符组成的子序列(含空串)
例如“abc”的子串有
“”、“a”、“b”、"c"、"ab"、"bc"、"ac"、"abc"
真子串是指不包含自身的所有子串
主串:包含子串的串
字符位置:字符在序列中的序号(从1开始)
子串位置:子串第一个字符在主串中的位置
空格串:由一个或多个空格组成的串(与空串不同)
例:字符串a、b、c、d
a = "BEI",长度为3
b = "JING",长度为4
c = "BEIJING",长度为7
d = "BEI JING",长度为8
c 的子串为 a、b
d 的子串为 a、b
a 在 c 中的位置是1,a 在 d 中的位置是1
b 在 c 中的位置是4,b 在 d 中的位置是5
串相等:当且仅当两个串的长度相等并且各个对应位置上的字符都相同时,这两个串才相等
表示
顺序存储结构
#define MAXLEN 255 typedef struct String { char data[MAXLEN + 1]; int length; }String;
不使用数组中的0号下标以方便操作
length:串的当前长度
链式存储结构
#define CHUNKSIZE 80 typedef struct Chunk { char data[CHUNKSIZE]; struct Chunk* next; }Chunk; typedef struct ChunkLinkString { Chunk* head; Chunk* tail; int curlen; }String;
head:串的头指针
tail:串的尾指针
curlen:串的当前长度
模式匹配
确定某子串(模式串)在主串中第一次出现的位置
两种模式匹配算法
- BF算法(Brute Force)
- KMP算法(由D.E.Knuth、J.H.Morris、V.R.Pratt共同提出)
BF算法
从主串的第一个字符开始,依次和子串各个字符逐个比较,如果比较过程中出现不相等的字符,则从主串的第二个字符开始重新比较,以此类推,如果某次比较完成后主串和子串的每个字符全部相等,则返回本次比较时开始的位置,即子串在主串中的位置
假设主串长度 A,子串长度 B,则每次比较的起始位置的范围为1到 A-B+1,每次比较的次数的范围为 1 到 B
参考实现方式1
S 和 T 都为非空串
int BF_1(String* S, String* T) { int i = 1; int j = 1; int S_length = S->length; int T_length = T->length; int position = 1; int flag = 0; while (position <= S_length - T_length + 1) { flag = 0; for (j = 1; j <= T_length; j++) { if (S->data[i] != T->data[j]) { flag = 1; position++; i = position; break; } i++; } if (flag == 0) { return position; } } return 0; }
i:表示每次比较时,字符在主串中的位置
j:表示每次比较时,字符在子串中的位置
position:记录主串中每次比较的起始位置
flag:用来判断每次比较是否有不相等的情况,如果有,flag为1,匹配失败,如果没有,flag 为0,匹配成功
if (S->data[i] != T->data[j]) { flag = 1; position++; i = position; break; }
如果字符不相等,则要更新 position 的值,让 position 值加1
参考实现方式2
返回0表示匹配失败
int BF_2(String* S, String* T) { int i = 1; int j = 1; while (i <= S->length && j <= T->length) { if (S->data[i] == T->data[j]) { i++; j++; } else { i = i - j + 2; j = 1; } } if (j >= T->length) { return i - T->length; } else { return 0; } }
i 是比较时字符在主串中的位置
j 是比较时字符在子串中的位置
if (S->data[i] == T->data[j]) { i++; j++; } else { i = i - j + 2; j = 1; }
不断比较,如果相等,则继续比较,如果不相等,则 i 的值更新为下一次比较时的起始位置
例如:

当 i == 6,j == 4时,发现不匹配,则 i 的值需要更新变为4,即 i-j+2,j 的值更新变为1
当每个字符都匹配时,此时 j 的值为子串长度+1
if (j >= T->length) { return i - T->length; } else { return 0; }
这里写成 if (j == T->length + 1) 也可以
时间复杂度
设主串长度为 n,子串长度为 m,则最坏情况是
主串前面的 n - m 个位置都一直匹配到子串的最后一位,最后 m 位也各比较了1次
于是比较的总次数为:
若 m << n
则算法的时间复杂度为
KMP算法
前言
当发现某个字符不匹配时,按照BF算法,需要从头开始重新比较
例如:

指向主串中待比较的字符的箭头称为主串指针
指向子串中待比较的字符的箭头称为子串指针
此时,由于字符不匹配,主串指针需要回退,指向主串中的5号位置,子串指针需要指向子串中的1号位置,继续逐个进行比较

然而,注意到当字符匹配失败时,有一个信息是BF算法中没有用到,那就是匹配失败前的每个字符是相等的

KMP算法就利用了这个信息,使得主串指针可以不断向前而不回退,算法的时间复杂度降为
思路
概念介绍
串的前后缀:假设串 S = AB,则 A 为串 S 的前缀,B 为串 S 的后缀,其中 A 和 B 都不能为空串
例如:串 S = "code",则
串 S 的前缀为:"c"、"co"、"cod"
串 S 的后缀为:"o"、"od"、"ode"
过程模拟
KMP算法的核心就在于找出子串的最大公共前后缀,其具体的实现过程为:
当某个字符匹配失败时,在子串中,寻找该字符前所构成的串中的最大公共前后缀,然后将子串指针指向最大前缀的下一位置,主串指针保持不变,继续进行比较
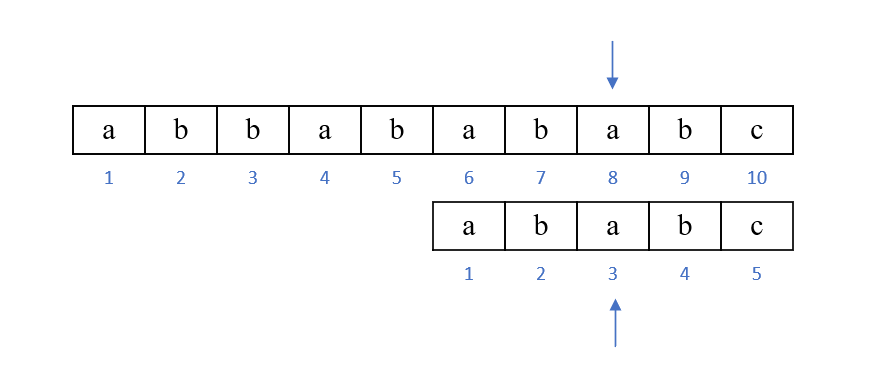
例如:

此时主串中8号位置的字符与子串中5号位置的字符匹配失败,观察到子串中5号位置前的最大公共前后缀为"ab"(最大公共前后缀显然不包括自身,即本例中的"abab"),于是子串指针指向最大前缀的下一位置,即子串中的3号位置,主串指针不变,如图所示
证明正确性
为什么模式串只需要移动到最大前缀的下一位置然后继续匹配就可以呢?在此前的位置进行匹配就一定不会成功吗?
假设有如下主串和模式串
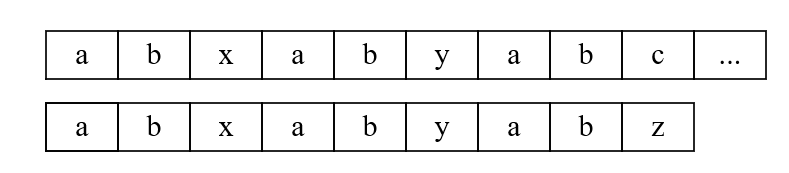
主串中'c'和模式串中'z'匹配失败,模式串中'z'前的最大公共前后缀为"ab",此时下一步的正确做法如下

如果在前面的位置进行匹配,如:

那么此时只有当主串中的'y'等于子串中的'x'时,匹配可以继续
然而,若'y' == 'x'
则模式串中的'z'前的最大公共前后缀为”abxab“
和原先条件相矛盾
个人非常粗糙的浅显的解释
next数组
为了求出模式串的最大公共前后缀,需要用一个数组来记录这些信息,这就是 next 数组,next 数组中各个数字的含义是:当该字符匹配失败时,子串指针需要跳到子串中的第 x 个位置重新进行匹配,其中 x 为 next 数组中的值,x 的大小是子串指针前所有字符构成的子串的最大公共前后缀的长度加1
例如:

假设在子串的第4个位置,即字符 b 时匹配失败,此时子串指针前的子串为"aba",其最大公共前后缀的长度为1,于是子串指针需要跳到子串中的第2个位置进行重新匹配
假设在子串的第5个位置,即字符 c 时匹配失败,此时子串指针前的子串为"abab",其最大公共前后缀的长度为2,于是子串指针需要跳到子串中的第3个位置进行重新匹配
这里的数组是省略了0号位的空间的
求解next
假设有模式串"ababac",则其 next 数组如下

当 j == 1 时,规定 next[j] = 0,在之前举的例子中,其值为1,从写代码的角度来看,规定为0会更方便操作
注意到:
- next[j] 的值每次最多加1
- 模式串中最后一位字符不产生任何影响,无论它是什么,结果都一样
在求解 next 数组的过程中,在已经知道之前的最大公共前后缀是什么之后,只要比较下一字符是否相等即可
例如:
假设 j == 3,3号位前的子串为"ab",比较1号位和2号位的字符,不相等,无最大公共前后缀,next[3] = 1
j == 4 时,4号位前的子串为"aba",比较1号位和3号位的字符,相等,最大公共前后缀长度为1,next[4] = 2
j == 5 时,5号位前的子串为"abab",在 j == 4时,我们已经知道1号位等于3号位了,此时只需要比较2号位和4号位即可,发现相等,于是最大公共前后缀长度为2,next[5] = 3
j == 6 时,6号位前的子串为"ababa",同理,此时比较3号位和5号位的字符,相等,于是 next[6] = 4
如果比较时字符不相等,该如何处理?
例如:
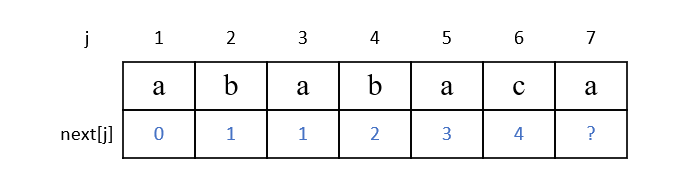
j == 7 时,7号位前的子串为"ababac",比较4号位和6号位的字符,发现不相等,此时 next[7] 的值该是多少呢?
在处理这样的情况时,仍然需要用到最大公共前后缀这一特点

假设现在有一模式串的长度为17,已知 next[16] == 8,即1到7号所构成的子串和9到15号构成子串相等,此时需要比较8号位和16号位的字符,假设其不相等,则比较 next[8] 号位置的字符和16号位的字符
假设 next[8] == 3,说明1到2号所构成的子串和6到7号构成子串相等,又由于1到7号所构成的子串和9到15号构成子串相等,于是推出1到2号所构成的子串和14到15号构成的子串相等,如图所示

红框和蓝框代表相等的串
如若还不等,则比较 next[3] 号位置的字符和16号位的字符,原理同上
next实现
void get_next(String* T, int next[]) { int i = 1; next[1] = 0; int j = 0; while (i < T->length) { if (j == 0 || T->data[i] == T->data[j]) { i++; j++; next[i] = j; } else { j = next[j]; } } }
i:一个不断向前的变量,用于指向最大公共后缀的下一字符
j:一个会回退的变量,用于指向最大公共前缀的下一字符
其中
while (i < T->length)
小于号而不是小于等于,因为模式串中最后一个字符对 next 数组的值没有影响
if (j == 0 || T->data[i] == T->data[j])
j == 0 是和 next[1] = 0 相配合的,个人认为此处代码极为精妙
KMP实现
int KMP(String* S, String* T, int next[]) { int i = 1; int j = 1; while (i <= S->length && j <= T->length) { if (j == 0 || S->data[i] == T->data[j]) { i++; j++; } else { j = next[j]; } } if (j == T->length + 1) { return i - T->length; } else { return 0; } }
i:主串指针
j:子串指针
注意,在定义串时,是舍弃了0号位空间的
所以有
while (i <= S->length && j <= T->length)
其中是小于等于而不是小于
因为用结构体表示串时,是舍弃了数组中0号位的空间的


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具