

202103226-1 编程作业01
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/zswxy/computer-science-class1-2018/homework/11877 |
| 这个作业的目标 | 实现软件工程中的流程,通过项目的实现来深入了解软件工程 |
| 作业正文 | 如何实现能够满足一些词频统计的需求 |
| 其他参考文献 | 构建之法 |
1.Github项目地址
2.psp表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| • Estimate | • 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 900 | 975 |
| • Analysis | • 需求分析 (包括学习新技术) | 120 | 360 |
| • Design Spec | • 生成设计文档 | 120 | 30 |
| • Design Review | • 设计复审 | 90 | 20 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| • Design | • 具体设计 | 60 | 40 |
| • Coding | • 具体编码 | 240 | 300 |
| • Code Review | • 代码复审 | 120 | 15 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 260 | 115 |
| • Test Repor | • 测试报告 | 120 | 60 |
| • Size Measurement | • 计算工作量 | 20 | 30 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 120 | 25 |
| 合计 | 1210 | 1100 |
3.解答思路
先把任务主要分成了读写文件、统计行数、统计字符数量、统计单词数量和统计频率这个几个部分。最开始想的是一行一行地读取文件同时记录行的数量,然后再把接收的每一行拼接成一个大的字符串去统计字符数量那些的。然后在实际做的过程中发现做出来的效果和题目的要求不相符合,如果要这样做恐怕会比较麻烦,于是把读入的全部加入到字符串中再去判断。在统计词频的过程中原本想的是用两个数组分别记录下单词和词频,写的过程中感觉很麻烦,后来在找资料的过程中发现之前学过的map可以很好地实现想法就直接用上了。下面是具体的需求实现:
First:命令行运行程序
在以往java学习没有尝试过cmd运行程序。不过想到以前C++课上老师特意提到过args数组的用法是用来传递外部参数,又想到java main函数也有args参数,由此试验,果不其然。针对命令:java WordCount input.txt output.txt args[0] == input.txt args[1] == output.txt。
Second:怎么去分割单词和计算有效行数
首先想到的技术是正则表达式,正则在字符匹配方面较为简单。之后花了点时间重新复习正则表达式,确实有其可行之处(具体实现见下文)。
Third:排除非法单词
同样可用正则解决
Forth:单词频数统计
想的是用map,具体优化方法暂时未想到。
Fifth:单元测试的概念和怎么去实现
对于我来说,单元测试是全新的概念,单从字面理解的话:一个单元一个单元地测试代码 (单元可以是一个函数)。通过查阅邹欣老师的博客才有了进一步了解。并查阅资料得知可以借助IDEA采用JUnit框架完成测试。
4.代码规范链接
5.模块接口的设计与实现过程
1、getWordList函数
算法的关键和独到之处是用正则表达式分割单词,匹配合法单词。
思路是一行一行读取文件,使用正则表达式,以分割符来分割出单词,把合法的单词放入单词列表。
() private static final Pattern pattern = Pattern.compile("[a-zA-Z]{4}[a-zA-Z0-9]*"); BufferedReader br = new BufferedReader(new FileReader(inputFile)); String line = null; //一行一行读取文件 while((line = br.readLine()) != null){ //分割符:空格,非字母数字符号,以分割符来分割出单词 String[] words = line.split("[^a-zA-Z0-9]"); //单词:至少以4个英文字母开头 for (String word : words){ if (word.length() >= 4) { //正则表达式判断单词是否合法 if (pattern.matcher(word).matches()){ //统一转小写 wordList.add(word.toLowerCase()); } } } } ()
2、countWordFrequency函数
() public ArrayList countWordFrequency(String inputFile) { List<String> wordList = getWordList(inputFile); //key 单词 value 出现次数 Map<String, Integer> words = new TreeMap<String,Integer>(); //如果有这个单词 count ++ for (String word : wordList){ if (words.containsKey(word)) words.put(word,words.get(word)+1); else { //如果map里没有这个单词,添加进去,count=1 words.put(word, 1); } } //按值进行排序,sortMap是自定义的用来按value排序的函数 ArrayList<Map.Entry<String,Integer>> list = sortMap(words); return list; } ()
3、其他函数
其他函数的编写都参照解题思路中的描述。
countWords函数
() List<String> wordList = getWordList(inputFile); //单词列表的长度 int count = wordList.size(); ()
countChars函数
() BufferedReader br = new BufferedReader(new FileReader(inputFile)); while ((br.read()) != -1) count++; ()
countLines函数
() BufferedReader br = new BufferedReader(new FileReader(inputFile)); String line = ""; while((line = br.readLine()) != null){ //判断是否为空白行 if (!(line.trim().isEmpty())) count++; } ()
6.性能改进
BufferedReader和BufferedWriter通过缓存机制增强了读取和存储数据的效率。
- 使用正则表达式的预编译功能,可以有效加快正则匹配速度。
- 即Pattern要定义为static final静态变量,以避免执行多次预编译。
性能测试
性能改进后程序执行速度有所提升,以下为测试的数据量以及花费的时间:
3000个单词(3 0000个字符) 约200ms
3 0000个单词(30 0000个字符) 约600ms
30 0000个单词(300 0000个字符) 约2s
300 0000个单词(3000 0000个字符) 约13s
7.单元测试
用4个函数分别测试4个功能,另外1个函数测试大量数据。
单元测试4个功能都使用了10个测试用例,均通过了测试。是因为写法都差不多,所以以下的代码只列出第1个测试样例。
1、testCountWords
() /*测试有几个单词*/ @Test public void testCountWords(){ Lib lib = new Lib("input.txt","output.txt"); Assert.assertEquals(5,lib.countWords("input1.txt")); } ()
2、testCountChars
() /*测试有几个字符*/ @Test public void testCountChars() { Lib lib = new Lib("input.txt","output.txt"); Assert.assertEquals(88,lib.countChars("input1.txt")); } ()
3、testCountWordFrequency
因为这里输出的结果比较复杂,所以不使用Assert.assertEquals,而是直接打印出来观察是否正确。
() /*测试词频统计*/ @Test public void testCountWordFrequency(){ Lib lib = new Lib("input.txt","output.txt"); System.out.println("input1.txt"); lib.printWords(lib.countWordFrequency("input1.txt")); } ()
4、testCountLines
() /*测试有几行*/ @Test public void testCountLines(){ Lib lib = new Lib("input.txt","output.txt"); Assert.assertEquals(4,lib.countLines("input1.txt")); } ()
5、大量数据
() /*测试大量数据*/ @Test public void TestMassiveData() { try { BufferedWriter bw = new BufferedWriter(new FileWriter("massinput.txt")); //(共30个有效字符、3个单词) * n for (int i=0; i<1000000;i++) bw.write("aabbccDDEfg,hijlmn123 \nINPUT\r\n"); bw.close(); Lib lib = new Lib("massinput.txt","massoutput.txt"); //计算 lib.startCount(); //输出 lib.outputResult(); } catch (IOException e) { e.printStackTrace(); } } ()
测试数据
1、普通的数字、空格、字母组成的文件
One1 t2wo thrEe3 FOUR4
5fiVe 6six seV7en eigh88t
ninE999 ten10 1111
file123 123file
2、有其他ascii码作分隔符,包括回车
onee,twoo:three3 FOUR4
FIve!sixx(Seven*eigh88t
nine999\tenn
3、有空白行(空格,tab,回车\r\n,以及它们的组合)
1111
aaaa
4、合法单词判断
onee,ee two...ooo three[e]e fourrrr fiveeee
5、大量数据
6、空白文档
7、只含空行
8、同一个单词大小写
abCdEFg abcdefg Bcdefg ABCDEFG bCDEfG
9、频率相同的单词,优先输出字典序靠前的单词
windows95,windows98,windows2000
abcdi abcdf abcdg abcde
abcd1 abcd12 abcd11 abcd10
10、文章末尾换行
11、超过10个单词
abcd efgh ijkl mnop qrst uvwx yzzz
apple banana chicken donuts eges
file goal high image join banana chicken
chicken donuts eges
file goal high image join banana chicken
测试覆盖率
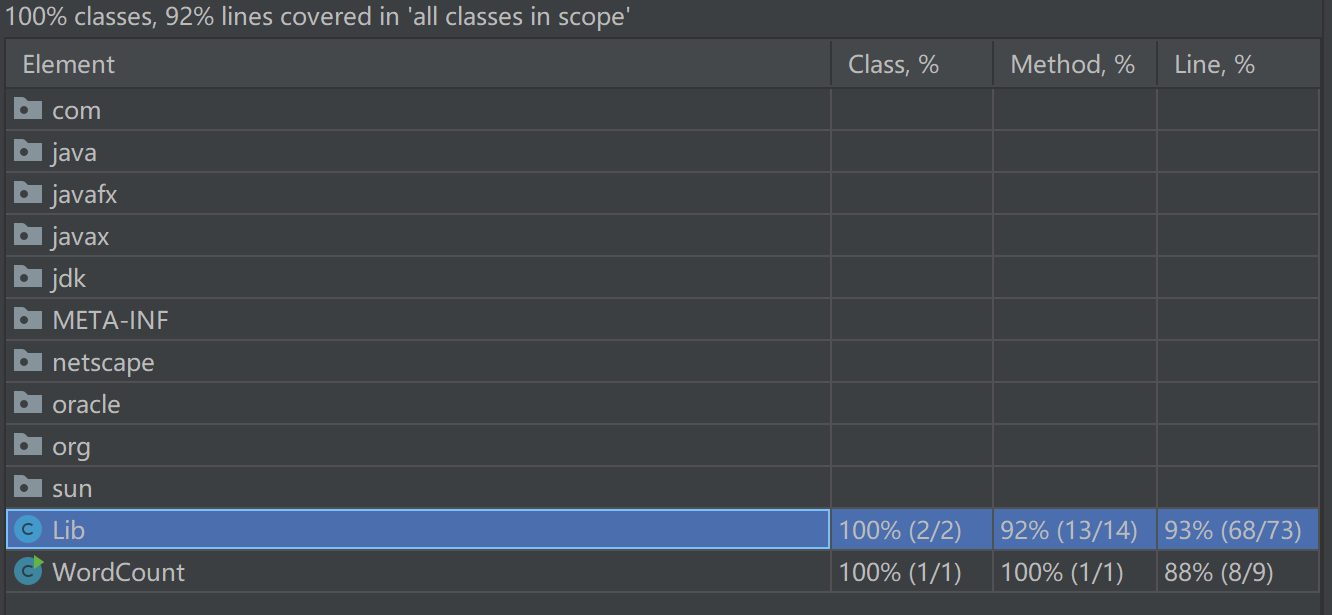
优化:没有覆盖到的语句都是catch语句、空行、注释行,应该不需要优化了。
8.异常处理说明
- 使用输入输出流、文件流时,必须try catch处理异常,否则编译不通过。
- main函数中判断了args数组的length
当传入参数不足时:

当传入的要读的文件不存在时:

当要写入的文件不存在时,会自动创建文件。
当程序运行成功时:

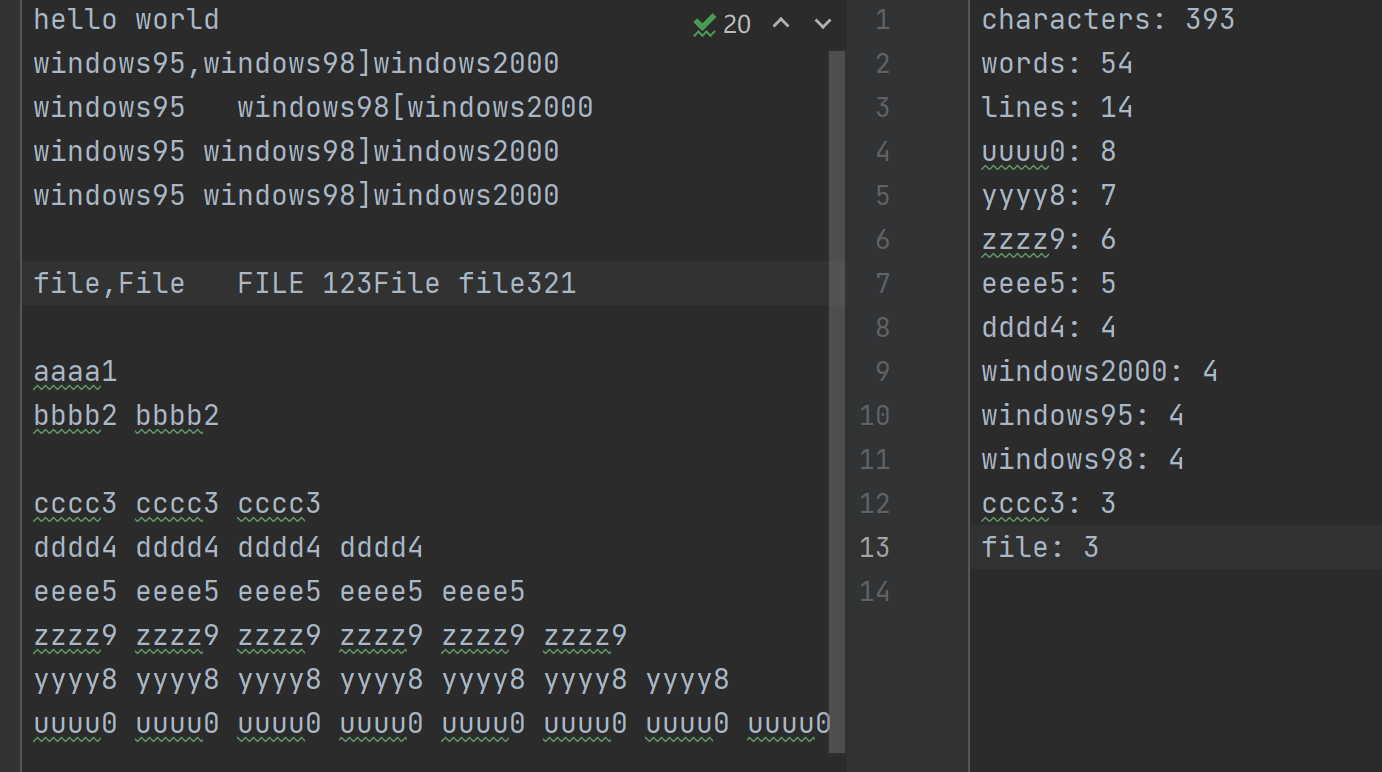
if (args.length >= 2) {//略 } else System.out.println("错误,请输入两个文件的名字");
9.心路历程与收获
在这次的项目中,我复习了如何用github管理代码,也学到了不少新知识。我知道了原来不同的语言有不同的代码规范,并且制定了自己的Java代码规范。我也接触到了PSP表格这种估计开发时间的方法,在项目开发的过程中开始有意识地估计和记录各项工作的时间。我还学会了编写构建之法中提到的单元测试,我想单元测试对于复杂的项目是很重要的。在完成词频统计程序的开发的过程中,我学会了简单使用正则表达式,复习巩固了一些Java的知识,也锻炼了思考的能力。
对于我来说,这次的作业难在接触到的新东西比较多,有需要学习的新知识,会遇到一些问题,文档的写作也和以往的作业比较不同,希望经过这一次的练习,我能在以后的作业中做得更快更好。

