Flink 配置 任务提交 内存管理
flink-conf.yaml 如下:
jobmanager.rpc.address: hadoop106 --jobManager 的IP地址 jobmanager.rpc.port: 6123 --jobManager 的端口,默认为6123 jobmanager.heap.mb: 1024M --jobManager 的JVM heap大小 taskmanager.heap.mb: 1024M rest.port: 8081 --taskManager的jvm heap大小设置 taskmanager.numberOfTaskSlots:1 --taskManager中taskSlots个数,最好设置成work节点的CPU个数相等 parallelism.default :1 --并行计算数 fs.default-scheme --文件系统来源 fs.hdfs.hadoopconf: --hdfs置文件路径 jobmanager.web.port -- jobmanager的页面监控端口
slaves
hadoop106
hadoop107
hadoop108master
hadoop106:8081
内存管理配置
Flink默认上分配taskmanager.heap.mb配置值得70%留它管理,内存的管理让flinK批量处理效果很高;并且flink不会出现OutMemoryException的问题,因为flink知道预留多少内存来执行程序;如果flink运行的程序所需要的内存超过了它所管理的内存,Flink就可以利用磁盘;总而言之,flink的内存管理提高了鲁棒性和系统的速度;下面就介绍管理内存的配置文件:
taskmanager.memory.fraction --管理内存的百分比,默认0.7 taskmanager.memory.size --taskManager 具体管理内存的大小; --此配置重写taskmanager.memory.fraction的配置 taskmanager.memory.segment-size --内存管理器所使用的内存缓冲区的大小和网络堆栈字节 taskmanager.memory.preallocate --taskmanager是否启动时管理所有的内存
- 使用 flink 命令行 直接向 yarn 提交任务
bin/flink run ./examples/batch/WordCount.jar 常用参数: -p 程序默认并行度 下面的参数仅可用于 -m yarn-cluster 模式 -yjm JobManager可用内存,单位兆 -ynm YARN程序的名称 -yq 查询YARN可用的资源 -yqu 指定YARN队列是哪一个 -ys 每个 TaskMananger 会有多少个 Slot(静态,资源浪费,1.11废弃) -ytm 每个TM所在的Container可申请多少内存,单位兆 -yD 动态指定Flink参数
-yD fs.overwrite-files=true 覆盖文件 -yd 分离模式(后台运行,不指定-yd, 终端关闭后,提交的页面打不开)8088页面看作业 -
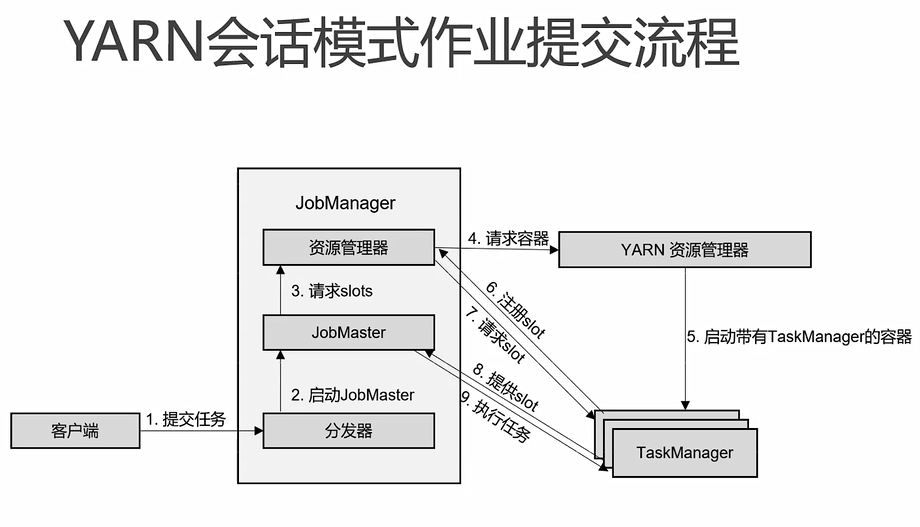
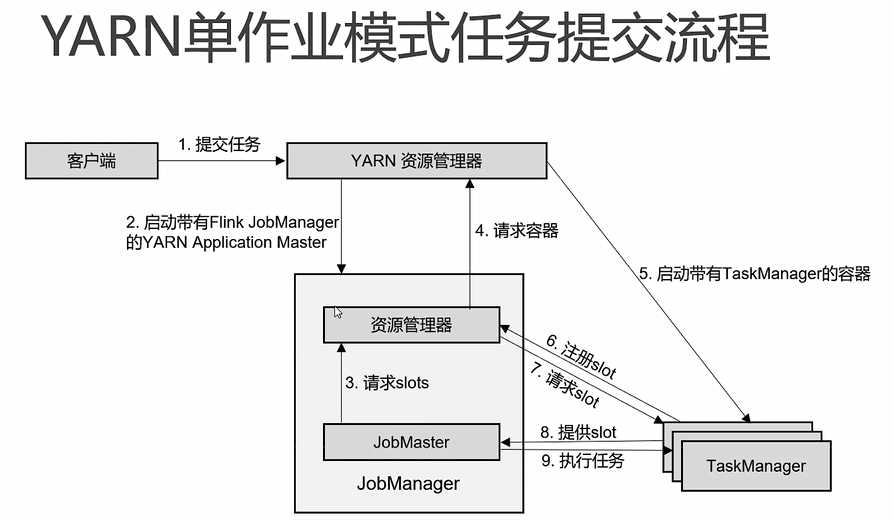
批处理模式: -Dexecution.runtime-mode=BATCH 部署模式: 集群模式: bin/start-cluster.sh yarn 会话模式: (先启集群后提交,资源0,动态分配) bin/yarnsession.sh -nm name yarn 单作业模式: 早期: -m yarn-cluster 现在:-t yarn-pre-job -c com.ali.WordCount(类名)
-
并行度:·每个operator 可能包含多个子任务(operator subtask), 在不同的线程、不同的物理机或不同的容器中,独立执行。 其子任务(subtask)的个数,称为并行度(parallelism)。
1 启动 flink
bin/start-cluster.sh
2 web页面查看
hadoop106:8081
3 运行 WordCount.jar
bin/flink run ./examples/batch/WordCount.jar -m yarn-cluster -Dexecution.runtime-mode=BATCH --input /opt/module/word.txt --output /opt/module/result.txt
4.运行 SocketWindowWordCount 实例
nc -l 9000 /bin/flink run ./examples/streaming/SocketWindowWordCount.jar --port 9000

 浙公网安备 33010602011771号
浙公网安备 33010602011771号